







文章目录
一、序列类型定义
1.特性
(1)序列是具有先后关系的一组元素。序列的序号,就是那个正向递增序号和反向递减序号
(2)序列是一维元素向量,元素类型可以不同
(3)序列类型是一种基类,衍生类型为:
- 字符串类型
str - 元组类型
tuple - 列表类型
list
2.共有的6个操作符
(1)x in s:如果x是序列s的元素,返回True,否则返回False
(2)x not in s:如果x是序列s的元素,返回True,否则返回False
(3)s+t:连接两个序列s和t
(4)s*n或n*s:将序列s复制n次
(5)s[i]:索引,返回s中的第i个元素,i是序列的序号
(6)s[i:j]或s[i:j:k]:切片,返回序列s中第i到j以k为步长的元素子序列
3.共有的5个函数
(1)len(s):返回序列s的长度
# 字符串str
s = 'hello123'
print(len(s))
# 8
# 列表list
lt = [123, 'xyz', 'zara']
print(len(lt))
# 3
# 元组tuple
t=(1,2,3)
print(len(t))
# 3
(2)min(s[, key=func]):返回序列s的最小元素,s中元素需要可按照func来比较
x = ['21', '1234', '9']
# 默认按照它的str类型,比较ascii
print(min(x))
# 1234
# 按照长度
print(min(x, key=len))
# 9
# 按照转换成int的大小
print(min(x, key=int))
# 9
(3)max(s[, key=func]):返回序列s的最大元素,s中元素需要可按照func来比较
x = ['21', '1234', '9']
# 默认按照它的str类型,比较ascii
print(max(x))
# 9
# 按照长度
print(max(x, key=len))
# 1234
# 按照转换成int的大小
print(max(x, key=int))
# 1234
(4)s.index(x)或s.index(x,i,j):返回序列s从i开始到j位置中第一次出现元素x的位置
(5)s.count(x):返回序列s中出现x的总次数
二、字符串类型str
python的字符串为Unicode编码
1.字符串类型的表示
- (1)单行字符串
单引号、双引号随便用
s1='hello'
s2="hello"
c1="6"
c2='6'
- (2)多行字符串
一对三单引号'''或一对三双引号"""
不加续行符\就会自带换行
# 不加续行符\就会自带换行
x='''1
2'''
print(x)
'''
1
2
'''
y="""3
4"""
print(y)
'''
3
4
'''
# 加续行符\
z='''5\
6'''
print(z)
'''
56
'''
- (3)字符串在其他类型中的表示
字符串表示在其他类型中都是''的形式。
s = "hello"
ls = [s]
print(ls)
'''
['hello']
'''
2.字符串引号的表示问题
- (1)在字符串中表示双引号或单引号:
print("这里有个单引号(")")
# error
print('这里有个双引号(")')
# 这里有个双引号(")
print("这里有个单引号(')")
# 这里有个单引号(')
- (2)在字符串中表示双引号和单引号:
print('''这里既有单引号(')又有双引号(")''')
# 这里既有单引号(')又有双引号(")
3.转义符\和ascii
(1)转义符
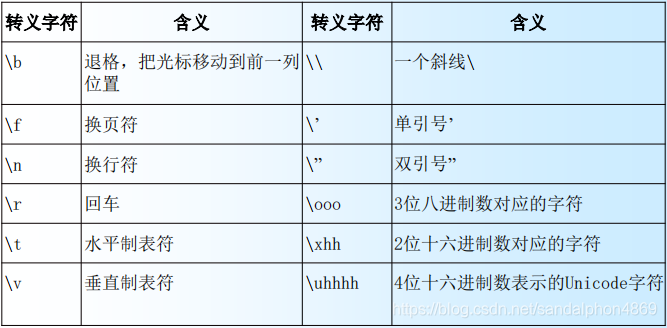
- 转义字符
\
>>> print('Hello\nWorld') #包含转义字符的字符串
Hello
World
>>> print("这里有个双引号(\")")
这里有个双引号(")
>>> print('\101') #三位八进制数对应的字符
A
>>> print('\x41') #两位十六进制数对应的字符
A
>>> print('我是\u5f20\u4e09') #四位十六进制数表示Unicode字符
我是张三
- 原始字符串
r或R
字符串界定符前面加字母r或R表示原始字符串,其中的特殊字符不进行转义,但字符串的最后一个字符不能是\。原始字符串主要用于正则表达式、文件路径或者URL的场合。
>>> path = 'C:\Windows\notepad.exe'
>>> print(path) #字符\n被转义为换行符
C:\Windows
otepad.exe
>>> path = r'C:\Windows\notepad.exe' #原始字符串,任何字符都不转义
>>> print(path)
C:\Windows\notepad.exe
(2)ascii
ord():以int返回单个字符的序数或Unicode码,参数str类型的字符chr():以str返回某序数对应的字符,参数int类型的整数
# 返回ascii
n = ord("A")
print(n)
print(type(n))
'''
65
<class 'int'>
'''
# 返回字符
n = chr(65)
print(n)
print(type(n))
'''
A
<class 'str'>
'''
4.字符串的序号
- (1)正向递增序号:
第一个是0
a b c
0 1 2
- (2)反向递减序号:
-1即倒数第1个
a b c
-3 -2 -1
5.[]的使用
使用[]获取字符串中一个或多个字符:
(1)索引:返回字符串中单个字符:<字符串>[M]
(2)切片:返回字符串中一段字符子串:<字符串>[M:N],从M开始读取,但不到N。
- 去掉最后一个字符:
<字符串>[0:-1] - 从头到尾:
<字符串>[0:]或者<字符串>[:] - 取尾:
<字符串>[-3:]:最后三个字符。
(3)步长切片:<字符串>[M:N:K],根据步长K对字符串切片。如:"零一二三四五六七八九十"[1:8:2]的结果为"一三五七"
- 倒序:
"零一二三四五六七八九十"[::-1]的结果为"十九八七六五四三二一零"。 - 取尾后倒序:
<字符串>[-3::-1]:最后三个字符,倒着。
6.eval()函数
eval()函数去掉参数最外侧引导并执行余下语句的函数:
(1)格式:eval(<字符串或字符串变量>)
(2)
print(eval("1+2"))
# 3
a=eval(input())+2
print(a)
# 3
# eval()将输入的3(被认为是字符串类型)转化为int类型
# 去掉eval()出错,要么int(input())
7.字符串格式化
同C/C++的格式化输出一样:
- 格式化一个:
'%.3f' % 3.1237 - 格式化多个:
"%d:%c" % (65,65)
注意:这种转化的结果还是字符串str类型
a = '%.3f' % 3.1237
print(a)
print(type(a))
'''
3.124
<class 'str'>
'''
8.字符串操作符
操作符:
(1)x+y:连接两个字符串x和y
(2)n*x或x*n:复制n次字符串x
(3)x in s:如果x是s的子串,返回True,否则返回False
9.字符串处理函数
函数:
(1)len(x):返回字符串x的长度
PS:不可以用__len__。

(2)str(x):转化为字符串,粗暴地直接在两端加个引号''
print(str(1234))
print(str((1,2,3,4)))
print(str([1,2,3,4]))
print(str({1,2,3,4}))
'''
1234
(1, 2, 3, 4)
[1, 2, 3, 4]
{1, 2, 3, 4}
'''
10.字符串处理方法
(1)方法:在编程中是一个专有名称,特指<a>.<b>()风格中的函数<b>()
(2)str.lower():返回字符串的副本,全部字符小写。
如,"AbcdEfgH".lower()的结果为"abcdefgh"
(3)str.upper():返回字符串的副本,全部字符大写
(4)str.split(sep=None):返回一个列表,由str根据sep被分隔的部分组成。
如,"A,B,C".split(",")的结果为['A','B','C']
(5)str.count(sub):返回子串sub在str中出现的次数
如"a apply a day".count("a")的结果为4
(6)str.replace(old,new):返回字符串的副本,所以old子串被替换为new。
如"python".replace(“n”,“n123”)的结果为"python123"。
注意:想要是副本,原字符串是不会改变的。而想要修改原字符串,则要line = line.replace('’', "'")
(7)str.center(width[,fillchar]):字符串str根据宽度width居中,fillchar可选。
如,"python".center(20,"=")的结果为'=======python======='
(8)str.strip(chars):从str中去掉在其左侧和右侧chars中列出的字符。
如"= python=".strip("=np")的结果为"ytho"
(9)str.join(iter):在iter变量除最后元素外每个元素后增加一个str。
如",".join("12345")的结果为"1,2,3,4,5"
(10)str.endswith("XXX"):判断字符串是否以XXX结尾,返回True/False
# 获取每个字符
str1 = "hello"
str1 = ' '.join(str1)
print(str1.split(' '))
# ['h', 'e', 'l', 'l', 'o']
11.字符串的合并
- 用
+号连接:字符串或变量都行。但是注意,连接的变量都是字符串类型 - 直接连接:两者只能是字符常量
# 字符串合并
>>> a = 'abc' + '123' # +生成新字符串
>>> x = '1234''abcd' # 直接连接
>>> x
'1234abcd'
>>> x = x + ',.;' # +
>>> x
'1234abcd,.;'
>>> x = x'efg' # 直接连接不允许这样连接字符串
SyntaxError: invalid syntax
# 注意
>>> a = 'b' + 2 # 不能直接连接int
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: can only concatenate str (not "int") to str
>>> a = 'b' + str(2) # 只能连接字符串
>>> a
'b2'
12. 比较字符串大小
# 只比较
>>> 'a' == 'b'
False
>>> 'a' != 'b'
True
>>> 'a' < 'b'
True
>>> 'a' <= 'b'
True
# 得到那个大的
>>> max('a','b')
'b'
>>> min('a','b')
'a'
>>> max('a','b','c')
'c'
>>> min('a','b','c')
'a'
13. 文件名的过滤字符
写入读取文件时,如果文件名包含非法字符,则会失败。
def get_filter_str(original_str):
char_set = "?*/\|.:><"
char_replace = " " # the first two maketrans arguments must have equal length
translation = str.maketrans(char_set, char_replace)
result_str = original_str.translate(translation)
return result_str














 1825
1825











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









