一. 构造词向量特征
1.1 原始数据编码转换
import pandas as pd
import csv
data_path = r'data\user_tag_query.10W.TRAIN'
csvfile = open(data_path + '-1w.csv', 'w')
writer = csv.writer(csvfile)
writer.writerow(['ID', 'age', 'Gender', 'Education', 'QueryList'])
with open(data_path, 'r', encoding = 'gb18030', errors = 'ignore') as f:
lines = f.readlines()
for line in lines[0: 10000]:
try:
line.strip()
data = line.split('\t')
writedata = [data[0], data[1], data[2], data[3]]
querystr = ''
data[-1] = data[-1][:-1]
for d in data[4:]:
try:
cur_str = d.encode('utf8')
cur_str = cur_str.decode('utf8')
querystr += cur_str + '\t'
except:
continue
querystr = querystr[:-1]
writedata.append(querystr)
writer.writerow(writedata)
except:
continue
data_path = r'data\user_tag_query.10W.TEST'
csvfile = open(data_path + '-1w.csv', 'w')
writer = csv.writer(csvfile)
writer.writerow(['ID', 'age', 'Gender', 'Education', 'QueryList'])
with open(data_path, 'r', encoding = 'gb18030', errors = 'ignore') as f:
lines = f.readlines()
for line in lines[0: 10000]:
try:
line.strip()
data = line.split('\t')
writedata = [data[0], data[1], data[2], data[3]]
querystr = ''
data[-1] = data[-1][:-1]
for d in data[4:]:
try:
cur_str = d.encode('utf8')
cur_str = cur_str.decode('utf8')
querystr += cur_str + '\t'
except:
continue
querystr = querystr[:-1]
writedata.append(querystr)
writer.writerow(writedata)
except:
continue
trainname = r'data\user_tag_query.10W.TRAIN-1w.csv'
testname = r'data\user_tag_query.10W.TEST-1w.csv'
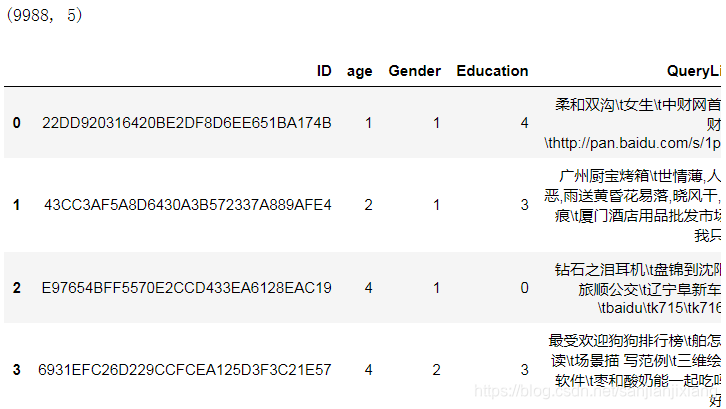
data = pd.read_csv(trainname, encoding = 'gbk')
print(data.shape)
data.head()
1.2 生成对应的数据表
data.age.to_csv(r'data\train_age.csv', index = False)
data.Gender.to_csv(r'data\train_gender.csv', index = False








 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 4088
4088











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









