







 本文全面解析算法测试的关键步骤,包括模型评估、鲁棒性测试、模型安全及响应速度等,并介绍了业务测试、白盒测试和模型监控等内容。
本文全面解析算法测试的关键步骤,包括模型评估、鲁棒性测试、模型安全及响应速度等,并介绍了业务测试、白盒测试和模型监控等内容。
目录
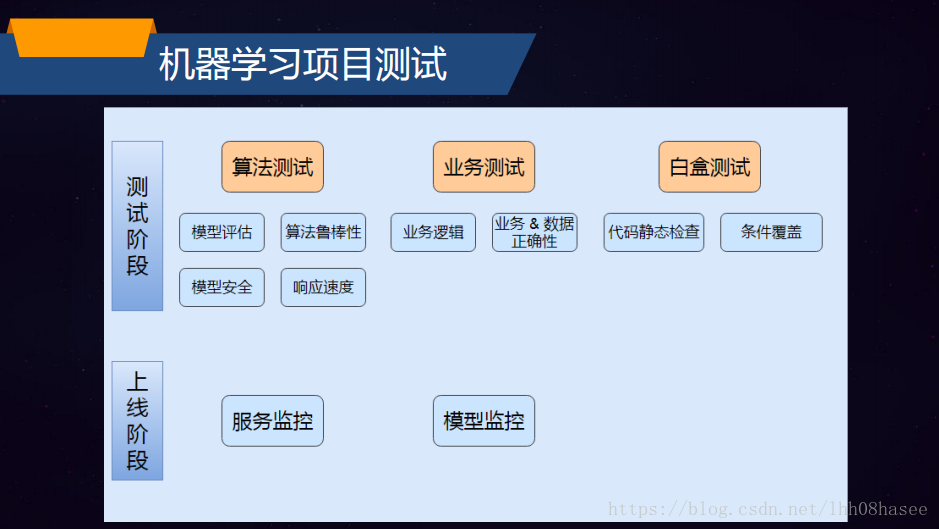
一、算法测试
1、模型评估
如何评估模型?可以通过泛化能力。泛化能力指的是学习方法对未知数据的预测能力。就好比运动员平时都是在训练场进行训练,而评估运动员的真实实力要看在大赛中的表现。 我们实际希望的,是在新样本上能表现得很好的学习器,为了达到这个目的,应该从训练样本中尽可能推演出适用于所有潜在样本的“普通规律”,这样才能在遇到新样本时做出正确的预测,泛化能力比较好。 当学习器把训练样本学得“太好”了的时候,很可能已经把训练样本自身的一些特点当作了所有潜在样本都会具有的一般性质,这样就会导致泛化性能下降。这种现象在机器学习中称为“过拟合“,与之相对是“欠拟合”指的是对训练样本的一般性质尚未学习。 有多种因素可能导致过拟合,其中最常见的情况是由于学习能力过于强大,以至于把训练样本所包含的不太一般的特性都学到了,而欠拟合则通常是由于学习能力低下而造成的。
如何看泛化能力的好坏呢? 通过泛化误差。 先解释下各种名词 ,从数据中分析得到模型的过程称为“训练”,用于“训练”的数据称为“训练数据”。其中每个样本称为一个“训练样本”,训练样本组成的集合称为“训练集”,测试样本组成的集合称为“测试集”。 模型在训练集上的误差通常称为 “训练误差” 或 “经验误差”,在测试集上的误差通常称为“测试误差”,而在新样本上的误差称为 “泛化误差” 。机器学习的目的是得到泛化误差小的学习器。然而,在实际应用中,新样本是未知的,所以 以测试集上的“测试误差”作为泛化误差的近似。使用一个“测试集”来测试学习器对新样本的判别能力。需要注意的是,测试样本尽量不在训练集中出现、未在训练过程中使用过。
performance measure是衡量模型的泛化能力的评价标准。
- 准确率(accuracy)
- 精确率(precision)==查准率、召回率( recall)==查全率,F1值 ,ROC与AUC —分类算法评价指标 F1值 是精确率和召回率的调和均值
- MSE(均方误差),RMSE(均方根误差),MAE(平均绝对误差)、R-Squared(拟合度) —-回归算法评价指标
都是评估模型好坏的指标,相互之间有一定关系,只是侧重点会不同。
1)准确率(accuracy)
对于给定的测试数据集,分类器正确分类的样本数与总样本数之比,是最常见也是最基本的评价算法性能指标。 有些场景下,只看这一个指标是不够的。比如 : 在二分类中,当正反比例不平衡的情况下,尤其是当我们对少数的分类更感兴趣的时时候,准确率评价基本就没什么参考价值。 举个例子:有个100条样本数据的测试集,其中80个正例,20个反例。那如果模型把所有样本都预测为正例,那模型的准确率至少都是80%。当模型遇到新样本时,它都区分不出一个反例。这种模型也就没用了。
2)精确率和召回率
精确率是针对我们预测结果而言的,它表示的是预测为正的样本中有多少是真正的正样本。 而召回率是针对我们原来的样本而言的,它表示的是样本中的正例有多少被预测正确了。 一般来说,精确率高时,召回率往偏低,而精确率低时,召回率偏高。 只有在一些简单的任务中才可能使精确率和召回率都很高。
精确率和召回率 实例 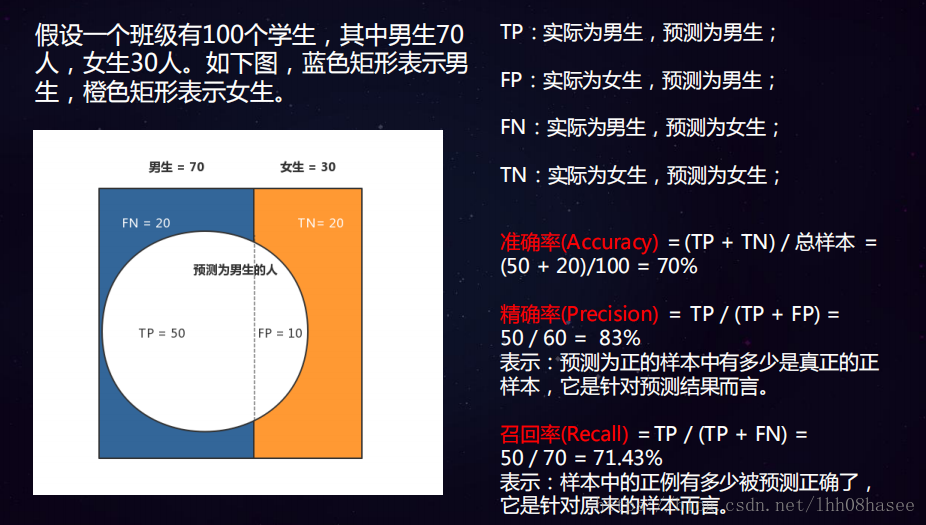
3)评价指标跑出来看又怎么评判呢?
这里运行得出的准确率是0.96,好还是不好呢,是否可以测试通过。要1.0准确率才测试通过吗?
看实际项目的应用场景、目前的技术水平、产品经理的需求定义,测试人员把各指标值反馈出来,在测试报告中体现出来。
比如说无人驾驶,如果它的准确率是96%,大家会不会去坐无人驾驶的汽车呢?反正我是不敢的,这是在用生命来测试算法。 我们来看下2016年的新闻 ,百度自动驾驶负责人王劲 2016年9月 ,去年的这个时候,我们的图象识别,识别汽车这一项,刚好也是89%。我们认为这个89%,要达到97%的准确率,需要花的时间,会远远超过5年。而人类要实现无人驾驶,主要靠摄像头来实现安全的保障的话,我们认为要多少呢?我们认为起码这个安全性的保障,要达到99.9999%,所以这个是一个非常非常远的一条路。我们认为不是5年,10年能够达得到的。 一般的人工智能系统,如搜索、翻译等可允许犯错,而无人驾驶系统与生命相关,模型性能要求很高。
2、鲁棒性 (robustness)
鲁棒性也就是所说健壮性,简单来说就是在模型在一些异常数据情况下是否也可以比较好的效果。 也就是我们在最开始讲人工智能三个特征中的 处理不确定性的能力。 比如人脸识别,对于模糊的图片,人带眼镜,头发遮挡,光照不足等情况下的模型表现情况。 算法鲁棒性的要求简单来说就是 “好的时候”要好,“坏的时候”不能太坏。 在AlphaGo 和李世石对决中,李世石是赢了一盘的。李世石九段下出了“神之一手” Deepmind 团队透露:错误发生在第79手,但AlphaGo直到第87手才发觉,这期间它始终认为自己仍然领先。这里点出了一个关键问题:鲁棒性。人类犯错:水平从九段降到八段。机器犯错:水平从九段降到业余。
测试方法就是用尽可能多的异常数据来覆盖进行测试。
3、模型安全
攻击方法有:试探性攻击、对抗性攻击两种。
- 试探性攻击:攻击者的目的通常是通过一定的方法窃取模型,或是通过某种手段恢复一部分训练机器学习模型所用的数据来推断用户的某些敏感信息。 主要分为模型窃取和训练数据窃取
- 对抗性攻击:对数据源进行细微修改,让人感知不到,但机器学习模型接受该数据后做出错误的判断。 比如图中的雪山,原本的预测准确率为94%,加上噪声图片后,就有99.99%的概率识别为了狗。
目前模型安全还是比较难的领域,像构造对抗性样本,这里就简单介绍下一下。
4、响应速度
响应速度是指从数据输入到模型预测输出结果的所需的时间。对算法运行时间的评价。
测试方法:
time.time() / time.clock()
time命令
time python test.py
定义装饰器timethis,将装饰器放在函数定义之前
这里只是简单看下模型运行所需的时间。并没有涉及大数据集群,分布式下的算法性能。
二、业务测试
包括业务逻辑测试,业务 & 数据正确性测试。主要关注业务代码是否符合需求,逻辑是否正确,业务异常处理等情况。可以让产品经理提供业务的流程图,对整体业务流程有清晰的了解。业务测试大家肯定都非常熟悉了,都是相通的,这里不花时间介绍啦。
三、白盒测试
白盒测试方法有很多,这里以只说下代码静态检查。 先让算法工程师将代码的逻辑给测试人员讲解,通过讲解理清思路。 然后测试做代码静态检查,看是否会有基本的bug。 工具的话使用pylint来做代码分析。
四、模型监控
服务监控大家应该都知道,这里就不介绍了。只说下模型监控。 项目发布到线上后,模型在线上持续运行,需要以固定间隔检测项目模型的实时表现,可以是每隔半个月或者一个月,通过性能指标对模型进行评估。对各指标设置对应阀值,当低于阀值触发报警。如果模型随着数据的演化而性能下降,说明模型已经无法拟合当前的数据了,就需要用新数据训练得到新的模型。机器学习算法项目的测试就介绍到这里。
五、算法测试学习入门
机器学习理论和实战书籍视频推荐,给有兴趣学习机器学习的同学。 

















 2018
2018

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









