







什么是Apache Ignite?
Ignite是一个以内存为中心的分布式数据库、缓存和处理平台,可以在PB级数据中,以内存级的速度进行事务性、分析性以及流式负载的处理。
上述引用了Ignite的官方介绍,通俗来讲,Ignite就是一个内存数据库,它包括了很多特性,它既是一个分布式缓存,也是一个分布式数据库,同时也支持一定程度的ACID事务。
关键字:固化内存、并置处理
固化内存
Ignite的固化内存组件不仅仅将内存作为一个缓存层,还视为一个全功能的存储层。这意味着可以按需将持久化打开或者关闭。如果持久化关闭,那么Ignite就可以作为一个分布式的内存数据库或者内存数据网格,这完全取决于使用SQL和键-值API的喜好。如果持久化打开,那么Ignite就成为一个分布式的,可水平扩展的数据库,它会保证完整的数据一致性以及集群故障的可恢复能力。
并置处理
Ignite是一个分布式系统,因此,有能力将数据和数据以及数据和计算进行并置就变得非常重要,这会避免分布式数据噪声。当执行分布式SQL关联时数据的并置就变得非常的重要。Ignite还支持将用户的逻辑(函数,lambda等)直接发到数据所在的节点然后在本地进行数据的运算。
Ingite和Spark有什么区别?
Ignite 是一个基于内存的计算系统,也就是把内存做为主要的存储设备。Spark 则是在处理时使用内存。相比之下,Ingite的索引更快,提取时间减少,避免了序列/反序列等优点,使前者这种内存优先的方法更快。
Ignite提供了一个Spark RDD抽象的实现,他可以容易地在内存中跨越多个Spark作业共享状态,在跨越不同Spark作业、工作节点或者应用时,IgniteRDD为内存中的相同数据提供了一个共享的、可变的视图,而原生的SparkRDD无法在Spark作业或者应用之间进行共享。
1. 获得真正的可扩展的内存级性能,避免数据源和Spark工作节点和应用之间的数据移动
2. 提升DataFrame和SQL的性能
3. 在Spark作业之间更容易地共享状态和数据
如何使用Ingite?
启动Ingite集群
从官网下载zip格式压缩包
解压到系统中的一个安装文件夹,如apache-ignite-fabric-2.6.0-bin
配置IGNITE_HOME环境变量
linux执行命令:
bin/ignite.sh此时将启动Ingite,当最后输出下面信息时,则说明启动成功:
[20:47:15] Ignite node started OK (id=60d15c51)
[20:47:15] Topology snapshot [ver=1, servers=1, clients=0, CPUs=4, offheap=3.2GB, heap=3.5GB]使用maven启动
<dependency>
<groupId>org.apache.ignite</groupId>
<artifactId>ignite-core</artifactId>
<version>${ignite.version}</version>
</dependency>
<dependency>
<groupId>org.apache.ignite</groupId>
<artifactId>ignite-spring</artifactId>
<version>${ignite.version}</version>
</dependency>
<dependency>
<groupId>org.apache.ignite</groupId>
<artifactId>ignite-indexing</artifactId>
<version>${ignite.version}</version>
</dependency>目前ignite最新版本为2.6
Ingite集群知识
Ignite具有非常先进的集群能力,包括逻辑集群组和自动发现。
Ignite节点之间会自动发现对方,这有助于必要时扩展集群,而不需要重启整个集群。开发者可以利用Ignite的混合云支持,允许公有云(比如AWS)和私有云之间建立连接,向他们提供两者的好处。
Ingite有两种发现机制,分别是TCP/IP和Zookeeper。总的来说对于小集群,使用默认的TCP/IP发现方式,对于成百上千的大集群,则建议使用Zookeeper。
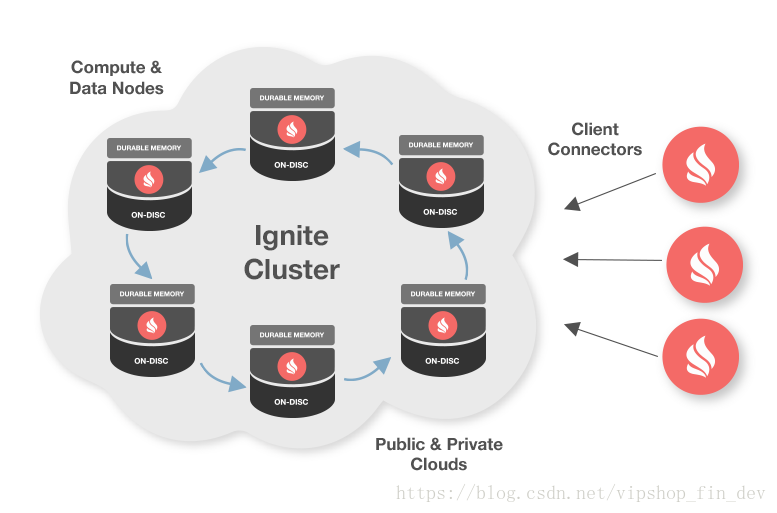
作为关系型数据库使用
创建表
可以通过控制台和jdbc两种方式执行sql语句,支持H2的语法。
控制台
1. 执行ignite.sh启动集群
2. 启动sqlline
sqlline.sh --color=true --verbose=true -u jdbc:ignite:thin://127.0.0.1/执行脚本 用!sql +sql 语句即可
!sql CREATE TABLE City (id LONG PRIMARY KEY, name VARCHAR) WITH "template=replicated";
!sql CREATE TABLE Person (id LONG, name VARCHAR, city_id LONG, PRIMARY KEY (id, city_id)) WITH "backups=1, affinityKey=city_id";
!sql CREATE INDEX idx_city_name ON City (name);
!sql CREATE INDEX idx_person_name ON Person (name);jdbc
// 注册JDBC driver.
Class.forName("org.apache.ignite.IgniteJdbcThinDriver");
// 打开 JDBC connection.
Connection conn = DriverManager.getConnection("jdbc:ignite:thin://127.0.0.1/");
// 创建表
try (Statement stmt = conn.createStatement()) {
// 创建基于复制模式的City表
stmt.executeUpdate("CREATE TABLE City (" +
" id LONG PRIMARY KEY, name VARCHAR) " +
" WITH \"template=replicated\"");
// 创建基于分片模式,备份数为1的Person表
stmt.executeUpdate("CREATE TABLE Person (" +
" id LONG, name VARCHAR, city_id LONG, " +
" PRIMARY KEY (id, city_id)) " +
" WITH \"backups=1, affinityKey=city_id\"");
// 创建City表的索引
stmt.executeUpdate("CREATE INDEX idx_city_name ON City (name)");
// 创建Person表的索引
stmt.executeUpdate("CREATE INDEX idx_person_name ON Person (name)");插入数据
控制台
!sql INSERT INTO City (id, name) VALUES (1, 'Forest Hill');
!sql INSERT INTO City (id, name) VALUES (2, 'Denver');
!sql INSERT INTO City (id, name) VALUES (3, 'St. Petersburg');
!sql INSERT INTO Person (id, name, city_id) VALUES (1, 'John Doe', 3);
!sql INSERT INTO Person (id, name, city_id) VALUES (2, 'Jane Roe', 2);
!sql INSERT INTO Person (id, name, city_id) VALUES (3, 'Mary Major', 1);
!sql INSERT INTO Person (id, name, city_id) VALUES (4, 'Richard Miles', 2); jdbc
Class.forName("org.apache.ignite.IgniteJdbcThinDriver");
Connection conn = DriverManager.getConnection("jdbc:ignite:thin://127.0.0.1/");
try (PreparedStatement stmt =
conn.prepareStatement("INSERT INTO City (id, name) VALUES (?, ?)")) {
stmt.setLong(1, 1L);
stmt.setString(2, "Forest Hill");
stmt.executeUpdate();
stmt.setLong(1, 2L);
stmt.setString(2, "Denver");
stmt.executeUpdate();
stmt.setLong(1, 3L);
stmt.setString(2, "St. Petersburg");
stmt.executeUpdate();
}
try (PreparedStatement stmt =
conn.prepareStatement("INSERT INTO Person (id, name, city_id) VALUES (?, ?, ?)")) {
stmt.setLong(1, 1L);
stmt.setString(2, "John Doe");
stmt.setLong(3, 3L);
stmt.executeUpdate();
stmt.setLong(1, 2L);
stmt.setString(2, "Jane Roe");
stmt.setLong(3, 2L);
stmt.executeUpdate();
stmt.setLong(1, 3L);
stmt.setString(2, "Mary Major");
stmt.setLong(3, 1L);
stmt.executeUpdate();
stmt.setLong(1, 4L);
stmt.setString(2, "Richard Miles");
stmt.setLong(3, 2L);
stmt.executeUpdate();
}查询数据
控制台
!sql SELECT p.name, c.name FROM Person p, City c WHERE p.city_id = c.id;jdbc
Class.forName("org.apache.ignite.IgniteJdbcThinDriver");
Connection conn = DriverManager.getConnection("jdbc:ignite:thin://127.0.0.1/");
// 使用标准的sql获取数据
try (Statement stmt = conn.createStatement()) {
try (ResultSet rs =
stmt.executeQuery("SELECT p.name, c.name " +
" FROM Person p, City c " +
" WHERE p.city_id = c.id")) {
while (rs.next())
System.out.println(rs.getString(1) + ", " + rs.getString(2));
}
}输出结果
Mary Major, Forest Hill
Jane Roe, Denver
Richard Miles, Denver
John Doe, St. Petersburg作为并置处理引擎
try (Ignite ignite = Ignition.start()) {
Collection<IgniteCallable<Integer>> calls = new ArrayList<>();
// 将这句字符串按照空格分组,并将任务分派到各个节点中计算
for (final String word : "Count characters using callable".split(" "))
calls.add(word::length);
// 分派
Collection<Integer> res = ignite.compute().call(calls);
// 将各个节点统计后的结果汇总
int sum = res.stream().mapToInt(Integer::intValue).sum();
System.out.println("Total number of characters is '" + sum + "'.");
}输出
Total number of characters is '28'.作为Data Grid(数据网格)应用
键值对存放及读取
try (Ignite ignite = Ignition.start()) {
IgniteCache<Integer, String> cache = ignite.getOrCreateCache("myCacheName");
// Store keys in cache (values will end up on different cache nodes).
for (int i = 0; i < 10; i++)
cache.put(i, Integer.toString(i));
for (int i = 0; i < 10; i++)
System.out.println("Got [key=" + i + ", val=" + cache.get(i) + ']');
}原子操作
// Put-if-absent which returns previous value.
Integer oldVal = cache.getAndPutIfAbsent("Hello", 11);
// Put-if-absent which returns boolean success flag.
boolean success = cache.putIfAbsent("World", 22);
// Replace-if-exists operation (opposite of getAndPutIfAbsent), returns previous value.
oldVal = cache.getAndReplace("Hello", 11);
// Replace-if-exists operation (opposite of putIfAbsent), returns boolean success flag.
success = cache.replace("World", 22);
// Replace-if-matches operation.
success = cache.replace("World", 2, 22);
// Remove-if-matches operation.
success = cache.remove("Hello", 1);事务支持
try (Transaction tx = ignite.transactions().txStart()) {
Integer hello = cache.get("Hello");
if (hello == 1)
cache.put("Hello", 11);
cache.put("World", 22);
tx.commit();
}分布式锁
// Lock cache key "Hello".
Lock lock = cache.lock("Hello");
lock.lock();
try {
cache.put("Hello", 11);
cache.put("World", 22);
}
finally {
lock.unlock();
} 部署远程微服务
Ignite的服务网格对于在集群中部署微服务非常有用,Ignite会处理和部署的服务有关的任务的生命周期,并且提供了在应用中调用服务的简单方式
下面的例子部署了一个Service,将从客户端传过来的信息进行打印
1.声明服务接口,扩展Ignite的service接口
import org.apache.ignite.services.Service;
public interface HelloService extends Service {
// 接受客户端的信息
String sayRepeat(String msg);
}2.实现服务接口,除了实现自己定义的接口外,也可以覆盖实现Ignite各个生命周期的工作
@Slf4j
public class HelloServiceImpl implements HelloService {
@Override
public String sayRepeat(String msg) {
log.info("I repeat your words : '{}'.", msg);
return msg;
}
@Override
public void cancel(ServiceContext serviceContext) {
log.info("{} cancel", serviceContext.name());
}
@Override
public void init(ServiceContext serviceContext) throws Exception {
log.info("{} init", serviceContext.name());
}
@Override
public void execute(ServiceContext serviceContext) throws Exception {
log.info("{} execute", serviceContext.name());
}
}3.部署服务sayHello,此时服务应用常驻在内存中
@Slf4j
public class IgniteServiceDemo {
public static void main(String[] args) {
IgniteServiceDemo demo = new IgniteServiceDemo();
demo.deploy();
}
private void deploy() {
String serviceName = "sayHello";
log.info("ready to start service {}", serviceName);
Ignite ignite = Ignition.start();
ignite.services().deployClusterSingleton(serviceName, new HelloServiceImpl());
log.info("service {} have bean started", serviceName);
}
}4.在另外一个应用中启动客户端,可通过控制台输入字符串,调用服务sayHello
@Slf4j
public class IgniteClientDemo {
public static void main(String[] args) {
IgniteClientDemo demo = new IgniteClientDemo();
demo.call();
}
private void call() {
String serviceName = "sayHello";
try (Ignite ignite = Ignition.start()){
HelloService helloService = ignite.services().serviceProxy(serviceName, HelloService.class, false);
log.info("Speaking,please.");
Scanner in = new Scanner(System.in);
while(in.hasNext()){
helloService.sayRepeat(in.next());
}
}
}
}5.结果
客户端输出
[INFO ] 22:41:16.860 [main] com.mumu.IgniteClientDemo - Speaking,please.
Hello!
My name is Ryan服务端输出
[INFO ] 22:41:05.481 [srvc-deploy-#43] c.mumu.service.impl.HelloServiceImpl - sayHello init
[INFO ] 22:41:05.481 [service-#46] c.mumu.service.impl.HelloServiceImpl - sayHello execute
[INFO ] 22:41:05.481 [main] com.mumu.IgniteServiceDemo - service sayHello have bean started
[22:41:16] Topology snapshot [ver=2, servers=2, clients=0, CPUs=4, offheap=6.4GB, heap=7.1GB]
[22:41:16] ^-- Node [id=610DAC7C-B087-405F-8549-8A7FE6012FD4, clusterState=ACTIVE]
[22:41:16] Data Regions Configured:
[22:41:16] ^-- default [initSize=256.0 MiB, maxSize=3.2 GiB, persistenceEnabled=false]
[INFO ] 22:41:23.086 [svc-#57] c.mumu.service.impl.HelloServiceImpl - I repeat your words : 'Hello!'.
[INFO ] 22:41:35.212 [svc-#59] c.mumu.service.impl.HelloServiceImpl - I repeat your words : 'My name is Ryan'.后记
上述的例子只是Apache Ignite各种特性及功能中的一部分,作为一个内存为核心的框架,它的应用场景极多,既可像Redis一样作为缓存,也可像关系型数据库那样执行sql语句,同时还能与Spark集成,增强spark的扩展性及速度,还能作为Hibernate和MyBatis的二级缓存,甚至还可以成为RPC框架提供微服务。而更可怕的是它具有分布式特性,可以根据应用规模水平扩展,并且还是运行在内存中,本身速度就占有很大的优势。
由于本人水平有限,加上Ignite属于比较新的开源项目,在国内外还处于发展阶段,很多特性仍在增加变化当中,最权威的介绍可参考官网:https://ignite.apache.org/
这篇文章对Ignite的特性描述得比较好,值得一读:https://www.zybuluo.com/liyuj/note/1179662
---------------------
转自: https://blog.csdn.net/vipshop_fin_dev/article/details/82563177














 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









