






参考链接:JULY大神的置顶《从头到尾彻底理解KMP》
1、原始暴力破解法解决字符串匹配问题。
暴力解决,就是逐字在原字符串s中匹配p的字符,若匹配失败,s的指针倒退(j-1)个单位。好麻烦。。。
int ViolentMatch(char* s, char* p)
{
int sLen = strlen(s);
int pLen = strlen(p);
int i = 0;
int j = 0;
while (i < sLen && j < pLen)
{
if (s[i] == p[j])
{
//①如果当前字符匹配成功(即S[i] == P[j]),则i++,j++
i++;
j++;
}
else
{
//②如果失配(即S[i]! = P[j]),令i = i - (j - 1),j = 0
i = i - j + 1;
j = 0;
}
}
//匹配成功,返回模式串p在文本串s中的位置,否则返回-1
if (j == pLen)
return i - j;
else
return -1;
} - 假设现在文本串S匹配到 i 位置,模式串P匹配到 j 位置
- 如果j = -1,或者当前字符匹配成功(即S[i] == P[j]),都令i++,j++,继续匹配下一个字符;
- 如果j != -1,且当前字符匹配失败(即S[i] != P[j]),则令 i 不变,j = next[j]。此举意味着失配时,模式串P相对于文本串S向右移动了j - next [j] 位。
- 换言之,当匹配失败时,模式串向右移动的位数为:失配字符所在位置 - 失配字符对应的next 值(next 数组的求解会在下文的3.3.3节中详细阐述),即移动的实际位数为:j - next[j],且此值大于等于1.
#include<iostream>
using namespace std;
/*
我的KMP算法实现
*/
void donex(int * next,string des)
{
int len=des.size();
next[0]=-1;
int k=-1;
int j=0;
while(j<len-1)
{
if(k==-1 || des[j]==des[k])
{
j++;
k++;
while(des[j]==des[k])k=next[k];
next[j]=k;
}
else
k=next[k];
}
}
int KMPcmp(string a,string des)
{
int a_len=a.size();
int des_len=des.size();
int *next=new int[des_len];
donex(next,des);
int i,j;
i=j=0;
while(i<a_len && j<des_len)
{
if(a[i]==des[j] || j==-1 )
{
++i;
++j;
}
else if(j!=-1 && a[i]!=des[j])//可换成else{}
{
j=next[j];
}
}
if(j==des_len)
return i-j+1;//首先匹配出来的字母在a的第i-j+1位,第一位以0为计数则是i-j !
else return -1;
}
int main()
{
string a;
string des;
getline(cin,a);
cin>>des;
int weizhi;
weizhi=KMPcmp(a,des);
if (weizhi>0)
cout<<"要找的位置在第 "<<weizhi<<" 位!"<<endl;
else
cout<<"所找的目的字符串在原串中不存在!\n";
return 0;
}其中的关键在于理解next[j] 这个偏移数组!
3.3 解释
3.3.1 寻找最长前缀后缀

失配时,模式串向右移动的位数为:已匹配字符数 - 失配字符的上一位字符所对应的最大长度值
下面,咱们就结合之前的《最大长度表》和上述结论,进行字符串的匹配。如果给定文本串“BBC ABCDAB ABCDABCDABDE”,和模式串“ABCDABD”,现在要拿模式串去跟文本串匹配,如下图所示:

- 1. 因为模式串中的字符A跟文本串中的字符B、B、C、空格一开始就不匹配,所以不必考虑结论,直接将模式串不断的右移一位即可,直到模式串中的字符A跟文本串的第5个字符A匹配成功:

- 2. 继续往后匹配,当模式串最后一个字符D跟文本串匹配时失配,显而易见,模式串需要向右移动。但向右移动多少位呢?因为此时已经匹配的字符数为6个(ABCDAB),然后根据《最大长度表》可得失配字符D的上一位字符B对应的长度值为2,所以根据之前的结论,可知需要向右移动6 - 2 = 4 位。

- 3. 模式串向右移动4位后,发现C处再度失配,因为此时已经匹配了2个字符(AB),且上一位字符B对应的最大长度值为0,所以向右移动:2 - 0 =2 位。

- 4. A与空格失配,向右移动1 位。
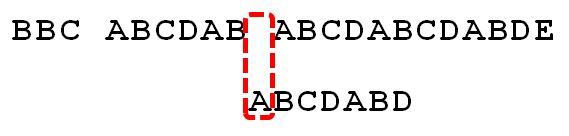
- 5. 继续比较,发现D与C 失配,故向右移动的位数为:已匹配的字符数6减去上一位字符B对应的最大长度2,即向右移动6 - 2 = 4 位。

- 6. 经历第5步后,发现匹配成功,过程结束。
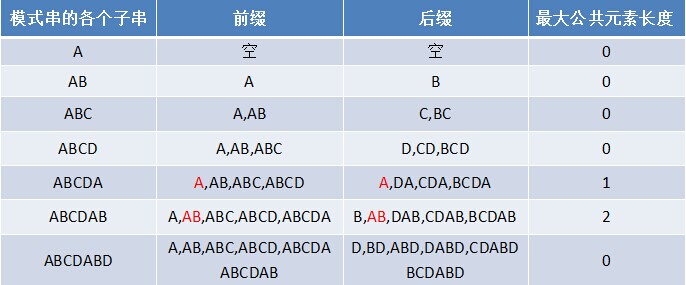
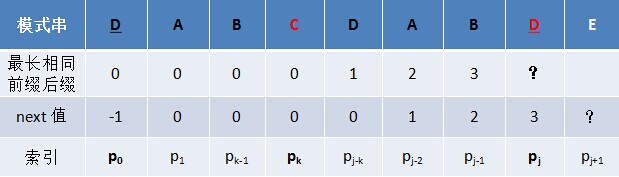
通过上述匹配过程可以看出,问题的关键就是寻找模式串中最大长度的相同前缀和后缀,找到了模式串中每个字符之前的前缀和后缀公共部分的最大长度后,便可基于此匹配。而这个最大长度便正是next 数组要表达的含义。

对于P的前j+1个序列字符:
- 若p[k] == p[j],则next[j + 1 ] = next [j] + 1 = k + 1;
- 若p[k ] ≠ p[j],如果此时p[ next[k] ] == p[j ],则next[ j + 1 ] = next[k] + 1,否则继续递归前缀索引k = next[k],而后重复此过程。 相当于在字符p[j+1]之前不存在长度为k+1的前缀"p0 p1, …, pk-1 pk"跟后缀“pj-k pj-k+1, …, pj-1 pj"相等,那么是否可能存在另一个值t+1 < k+1,使得长度更小的前缀 “p0 p1, …, pt-1 pt” 等于长度更小的后缀 “pj-t pj-t+1, …, pj-1 pj” 呢?如果存在,那么这个t+1 便是next[ j+1]的值,此相当于利用已经求得的next 数组(next [0, ..., k, ..., j])进行P串前缀跟P串后缀的匹配。
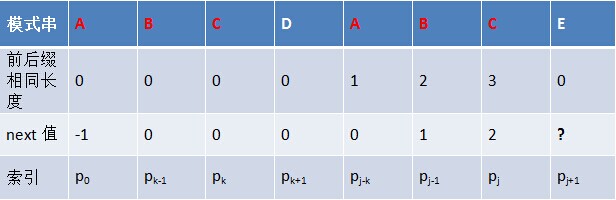
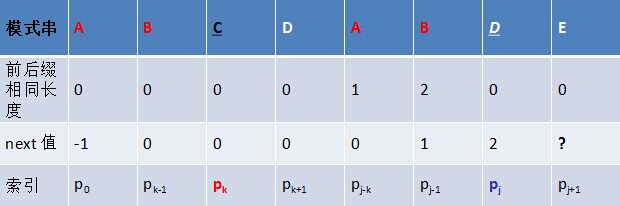
模式串的后缀:AB DE
模式串的前缀:AB C
前缀右移两位: ABC
void GetNext(char* p,int next[])
{
int pLen = strlen(p);
next[0] = -1;
int k = -1;
int j = 0;
while (j < pLen - 1)
{
//p[k]表示前缀,p[j]表示后缀
if (k == -1 || p[j] == p[k])
{
++k;
++j;
next[j] = k;
}
else
{
k = next[k];
}
}
} 一般学习者对于问题的把握到这里就停止了,但是真正的学习者,不会停止思考。。。
比如,如果用之前的next 数组方法求模式串“abab”的next 数组,可得其next 数组为-1 0 0 1(0 0 1 2整体右移一位,初值赋为-1),当它跟下图中的文本串去匹配的时候,发现b跟c失配,于是模式串右移j - next[j] = 3 - 1 =2位。

右移2位后,b又跟c失配。事实上,因为在上一步的匹配中,已经得知p[3] = b,与s[3] = c失配,而右移两位之后,让p[ next[3] ] = p[1] = b 再跟s[3]匹配时,必然失配。问题出在哪呢?

问题出在不该出现p[j] = p[ next[j] ]。为什么呢?理由是:当p[j] != s[i] 时,下次匹配必然是p[ next [j]] 跟s[i]匹配,如果p[j] = p[ next[j] ],必然导致后一步匹配失败(因为p[j]已经跟s[i]失配,然后你还用跟p[j]等同的值p[next[j]]去跟s[i]匹配,很显然,必然失配),所以不能允许p[j] = p[ next[j ]]。如果出现了p[j] = p[ next[j] ]咋办呢?如果出现了,则需要再次递归,即令next[j] = next[ next[j] ]。
所以,咱们得修改下求next 数组的代码。void GetNextval(char* p, int next[])
{
int pLen = strlen(p);
next[0] = -1;
int k = -1;
int j = 0;
while (j < pLen - 1)
{
//p[k]表示前缀,p[j]表示后缀
if (k == -1 || p[j] == p[k])
{
++j;
++k;
//较之前next数组求法,改动在下面
while(p[j] == p[k])
k=next[k];
//因为不能出现p[j] = p[ next[j ]],所以当出现时需要继续递归,k = next[k] = next[next[k]]
next[j]=k;
}
else
{
k = next[k];
}
}
} 利用优化过后的next 数组求法,可知模式串“abab”的新next数组为:-1 0 -1 0。可能有些读者会问:原始next 数组是前缀后缀最长公共元素长度值右移一位, 然后初值赋为-1而得,那么优化后的next 数组如何快速心算出呢?实际上,只要求出了原始next 数组,便可以根据原始next 数组快速求出优化后的next 数组。还是以abab为例,如下表格所示:
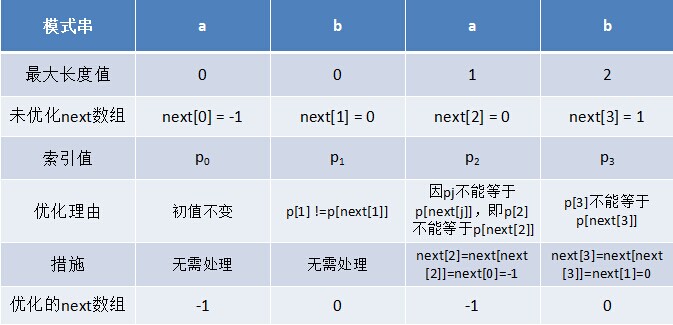
只要出现了p[next[j]] = p[j]的情况,则把next[j]的值再次递归。例如在求模式串“abab”的第2个a的next值时,如果是未优化的next值的话,第2个a对应的next值为0,相当于第2个a失配时,下一步匹配模式串会用p[0]处的a再次跟文本串匹配,必然失配。所以求第2个a的next值时,需要再次递归:next[2] = next[ next[2] ] = next[0] = -1(此后,根据优化后的新next值可知,第2个a失配时,执行“如果j = -1,或者当前字符匹配成功(即S[i] == P[j]),都令i++,j++,继续匹配下一个字符”),同理,第2个b对应的next值为0。
对于优化后的next数组可以发现一点:如果模式串的后缀跟前缀相同,那么它们的next值也是相同的,例如模式串abcabc,它的前缀后缀都是abc,其优化后的next数组为:-1 0 0 -1 0 0,前缀后缀abc的next值都为-1 0 0。
另JULY大神扩展了两个比KMP算法还要高效的匹配算法:














 122
122











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









