






Generation in lexicographic order[edit]
There are many ways to systematically generate all permutations of a given sequence.[47] One classical algorithm, which is both simple and flexible, is based on finding the next permutation in lexicographic ordering, if it exists. It can handle repeated values, for which case it generates the distinct multiset permutations each once. Even for ordinary permutations it is significantly more efficient than generating values for the Lehmer code in lexicographic order (possibly using the factorial number system) and converting those to permutations. To use it, one starts by sorting the sequence in (weakly) increasing order (which gives its lexicographically minimal permutation), and then repeats advancing to the next permutation as long as one is found. The method goes back to Narayana Pandita in 14th century India, and has been frequently rediscovered ever since.[48]
The following algorithm generates the next permutation lexicographically after a given permutation. It changes the given permutation in-place.
- Find the largest index k such that a[k] < a[k + 1]. If no such index exists, the permutation is the last permutation.
- Find the largest index l greater than k such that a[k] < a[l].
- Swap the value of a[k] with that of a[l].
- Reverse the sequence from a[k + 1] up to and including the final element a[n].
For example, given the sequence [1, 2, 3, 4] (which is in increasing order), and given that the index is zero-based, the steps are as follows:
- Index k = 2, because 3 is placed at an index that satisfies condition of being the largest index that is still less than a[k + 1] which is 4.
- Index l = 3, because 4 is the only value in the sequence that is greater than 3 in order to satisfy the condition a[k] < a[l].
- The values of a[2] and a[3] are swapped to form the new sequence [1,2,4,3].
- The sequence after k-index a[2] to the final element is reversed. Because only one value lies after this index (the 3), the sequence remains unchanged in this instance. Thus the lexicographic successor of the initial state is permuted: [1,2,4,3].
Following this algorithm, the next lexicographic permutation will be [1,3,2,4], and the 24th permutation will be [4,3,2,1] at which point a[k] < a[k + 1] does not exist, indicating that this is the last permutation.
Lexicographical order
|
| This article may require cleanup to meet Wikipedia's quality standards. The specific problem is: randomly ordered mix of example sections and other sections like generalizations (April 2015) |

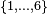 (and the corresponding
(and the corresponding
In mathematics, the lexicographic or lexicographical order (also known as lexical order, dictionary order, alphabetical order or lexicographic(al) product) is a generalization of the way the alphabetical order of words is based on the alphabetical order of their component letters.
Contents
[hide]Definition[edit]
Given two partially ordered sets A and B, the lexicographical order on the Cartesian product A × B is defined as
- ( a, b) ≤ ( a′, b′) if and only if a < a′ or ( a = a′ and b ≤ b′).
The result is a partial order. If A and B are each totally ordered, then the result is a total order as well. The lexicographical order of two totally ordered sets is thus a linear extension of their product order.
More generally, one can define the lexicographic order on the Cartesian product of n ordered sets, on the Cartesian product of a countably infinite family of ordered sets, and on the union of such sets.
Motivation and uses[edit]
The name of the lexicographic order comes from its generalizing the order given to words in a dictionary or encyclopedia: a sequence of letters (that is, a word)
- a 1 a 2 ... a k
appears in a dictionary before a sequence
- b 1 b 2 ... b k
if and only if at the first i where ai and bi differ, ai comes before bi in the alphabet.
That comparison assumes both sequences are the same length. To ensure they are the same length, the shorter sequence is usually padded at the end with enough "blanks" (a special symbol that is treated as coming before any other symbol). This also allows ordering of phrases. For the purpose of dictionaries, etc., padding with blank spaces is always done. See alphabetical order.
For example, the word "Thomas" appears before "Thompson" in dictionaries because the letter 'a' comes before the letter 'p' in the alphabet. The 5th letter is the first that is different in the two words; the first 4 letters are "Thom" in both. Because it is the first difference, the 5th letter is the most significant difference (for an alphabetical ordering).
A lexicographical ordering may not coincide with conventional alphabetical ordering. For example, the numerical order of Unicode codepoints does not always correspond to traditional alphabetic orderings of the characters, which vary from language to language. So the lexicographic ordering induced by codepoint value sorts strings in an unambiguous canonical order, but it does not necessarily "alphabetize" them in the conventional sense.
An important property of the lexicographical order is that it preserves well-orders of finite products; in particular, if A and B are well-ordered sets, then the product set A × B with the lexicographical order is also well-ordered.[1] The lexicographical order also preserves the Noetherian property; the lexicographical product of two (or any finite number of) Noetherian relations is again Noetherian.[2]
An important exploitation of lexicographical ordering is expressed in the ISO 8601 date formatting scheme, which expresses a date as YYYY-MM-DD. This date ordering lends itself to straightforward computerized sorting of dates such that the sorting algorithm does not need to treat the numeric parts of the date string any differently from a string of non-numeric characters, and the dates will be sorted into chronological order. Note, however, that for this to work, there must always be four digits for the year, two for the month, and two for the day, so for example single-digit days must be padded with a zero yielding '01', '02', ..., '09'.
Another generalization of lexical ordering occurs in social choice theory (the theory of elections). Consider an election in which there are 4 candidates A, B, C and D, each voter expresses a top-to-bottom ordering of the candidates, and the voters' orderings are as follows:
| 18% | 17% | 33% | 32% |
|---|---|---|---|
| A | B | C | D |
| B | A | D | B |
| C | C | A | A |
| D | D | B | C |
The MinMax voting method is a simple Condorcet method that counts the votes as in a round-robin tournament (all possible pairings of candidates) and judges each candidate according to its largest "pairwise" defeat. The winner is the candidate whose largest "pairwise defeat" is the smallest. In the example:
- The largest defeat of A is by D: 65% (33%+32%) rank D over A.
- The largest defeat of B is by D: 65% (33%+32%) rank D over B.
- The largest defeat of C is by A (or B): 67% (18%+17%+32%) rank A over C (and B over C).
- The largest defeat of D is by C: 68% (18%+17%+33%) rank C over D.
MinMax declares a tie between A and B since the largest defeats for both are the same size, 65%. This is like saying "Thomas" and "Thompson" should be at the same position in an alphabetical order because they have the same first letter. However, if the defeats are compared lexically, we have the MinLexMax method. With MinLexMax, because the largest defeats of A and B are the same size, their next largest defeats are then compared:
- A's next largest defeat is: none.
- B's next largest defeat is by A: 51% (18%+33%) rank A over B.
Since B's next largest defeat is larger than A's next largest defeat, MinLexMax elects A. This makes more sense than the MinMax tie since a majority rank A over B. A finishes ahead of B given MinLexMax for the same reason that Thomas is ahead of Thompson in an alphabetical order.
Another usage of the minlexmax principle in social choice theory can be found in the Ranked Pairs voting method. Although Ranked Pairs is usually defined by a procedure that efficiently constructs the order of finish, the result of that procedure is equivalent to finding which of all possible orders of finish is best according to a minlexmax comparison. In this case, any two possible orders of finish can be lexically compared by looking at the majorities on which the two orders disagree, to see which of the two orders reverses the largest of those majorities; that order is the worse of the two. (The majorities on which the two orders agree are irrelevant in the same way that "Thom" is irrelevant when alphabetically comparing Thomas and Thompson. Thomas and Thompson are compared using the first letter on which they disagree, similar to how Ranked Pairs compares two orders of finish using the largest majority on which they disagree.) In the example above, the Ranked Pairs order of finish is ABCD (which elects A). ABCD affirms the majorities who rank A over B, A over C, B over C and C over D, and reverses the majorities who rank D over A and D over B. The largest majority reversed in ABCD is 65%. The only other ordering that doesn't reverse a larger majority is BACD, which also reverses 65%. ABCD is a better order of finish than BACD because the set of majorities on which ABCD and BACD disagree is {the majority who rank A over B} and BACD reverses the largest majority in this set. (Similar calculations would show that ABCD is better than any other order of finish.)
Note that the MinLexMax method is not equivalent to Ranked Pairs, even though both use a minlexmax principle. Ranked Pairs satisfies the Independence of Clone Alternatives criterion, the Smith criterion (also known as the Top Cycle criterion) and the Condorcet Loser criterion and other criteria failed by MinLexMax.
Here is an example that shows MinLexMax and Ranked Pairs are not equivalent: Suppose there are four candidates A,B,C,D and suppose the six pairwise majorities are:
- 56% rank A over B
- 55% rank B over C
- 54% rank C over A
- 53% rank A over D
- 52% rank B over D
- 51% rank C over D
MinLexMax (and MinMax) elect D. This violates the Condorcet Loser criterion because majorities rank all three of the other candidates over D. The Ranked Pairs order of finish is ABCD, which has D in last place (and A is the Ranked Pairs winner). All other possible orders of finish are worse than ABCD on Ranked Pairs' minlexmax comparison. For instance, suppose we compare ABCD with DABC. The majorities on which ABCD and DABC disagree are the three majorities that rank A over D, B over D, and C over D. The largest of these three is the 53% who rank A over D, and that majority is reversed by DABC, which means DABC is worse than ABCD. Suppose we compare ABCD with the MinLexMax order of finish DACB. The majorities on which ABCD and DACB disagree are the five majorities that rank B over C, C over A, A over D, B over D, and C over D. The largest of these five is the 55% who rank B over C, which is reversed by DACB, which means DACB is worse than ABCD.
Case of multiple products[edit]
Suppose

is an n-tuple of sets, with respective total orderings
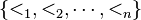
The dictionary ordering
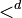
of

is then
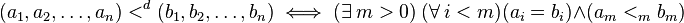
That is, if one of the terms
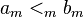
and all the preceding terms are equal.
Informally,
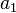
represents the first letter,
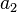
the second and so on when looking up a word in a dictionary, hence the name.
This could be more elegantly stated by recursively defining the ordering of any set
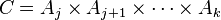
represented by
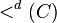
This will satisfy


where 
To put it more simply, compare the first terms. If they are equal, compare the second terms – and so on. The relationship between the first corresponding terms that are not equal determines the relationship between the entire elements.
Unlike the finite case, an infinite product of well-orders is not necessarily well-ordered by its lexicographical order. For instance, the set of countably infinite binary sequences (by definition, the set of functions from non-negative integers to {0, 1}, also known as the Cantor space {0, 1}ω) is not well-ordered; the subset of sequences that have precisely one 1 (i.e. { 100000..., 010000..., 001000..., ... }) does not have a least element under the lexicographical order induced by 0 < 1 because 100000... > 010000... > 001000... > ... is an infinite descending chain.[1] Similarly, the infinite lexicographic product is not Noetherian either because 011111... < 101111... < 110111 ... < ... is an infinite ascending chain.
Groups and vector spaces[edit]
If the component sets are ordered groups then the result is a non-Archimedean group, because e.g. n(0,1) < (1,0) for all n.
If the component sets are ordered vector spaces over R (in particular just R), then the result is also an ordered vector space.
Generalizations[edit]
Ordering of sequences of various lengths[edit]
Given a partially ordered set A, the above considerations allow to define naturally a lexicographical partial order 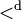 over the free monoid A* formed by the set of all finite sequences of elements in A, with sequence concatenation as the monoid operation, as follows:
over the free monoid A* formed by the set of all finite sequences of elements in A, with sequence concatenation as the monoid operation, as follows:
-
 if
if
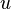 is a prefix of
is a prefix of  , or
, or and
and 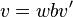 , where
, where 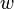 is the longest common prefix of and ,
is the longest common prefix of and ,  and
and  are members of A such that
are members of A such that  , and
, and 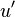 and
and 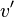 are members of A*.
are members of A*.
If < is a total order on A, then so is the lexicographic order <d on A*. If A is a finite and totally ordered alphabet, A* is the set of all words over A, and we retrieve the notion of dictionary ordering used in lexicography that gave its name to the lexicographic orderings. However, in general this is not a well-order, even though it is on the alphabet A; for instance, if A = {a, b}, the language {anb | n ≥ 0} has no least element: ... <d aab <d ab <d b. A well-order for strings, based on the lexicographical order, is the shortlex order; it is however not Noetherian.[2]
The shortlex order can actually be defined as a lexicographic product of two orders:
- the ordering of strings by length, and
- the (naturally disjoint) union of orders of finite string of every size with some (usually lexicographic) order.[2]
Similarly it is also possible to compare a finite and an infinite string, or two infinite strings.
Comparing strings of different lengths can also be modeled as comparing strings of infinite length by right-padding finite strings with a special value that is less than any element of the alphabet.
This ordering is the ordering usually used to order character strings, including in dictionaries and indexes.
Quasi-lexicographic order[edit]
The quasi-lexicographic order on the free monoid A∗ over an ordered alphabet A orders strings firstly by length, so that the empty string comes first, and then within strings of fixed length n, by lexicographic order on An.[3]
Another generalization[edit]
Consider the set of functions f from a well-ordered set X to a totally ordered set Y. For two such functions f and g, the order is determined by the values for the smallest x such that f(x) ≠ g(x).
If Y is also well-ordered and X is finite, then the resulting order is a well-order. As already shown above, if X is infinite this is in general not the case.
If X is infinite and Y has more than one element, then the resulting set YX is not a countable set, see also cardinal exponentiation.
Alternatively, consider the functions f from an inversely well-ordered X to a well-ordered Y with minimum 0, restricted to those that are non-zero at only a finite subset of X. The result is well-ordered. Correspondingly we can also consider a well-ordered X and apply lexicographical order where a higher x is a more significant position. This corresponds to exponentiation of ordinal numbers YX. If X and Y are countable then the resulting set is also countable.
Example: Monomials[edit]
In algebra it is traditional to order terms in a polynomial, by ordering the monomials in the indeterminates. Such matters are typically left implicit in discussion between humans, but must of course be dealt with exactly in computer algebra, for example for testing the equality of polynomials.
More specifically, the definition of Gröbner bases and their computation are heavily based on the choice of an ordering of the monomials. To define such an ordering, one identifies every monomial (for example 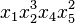 ) with its vector of exponents (here [1,3,0,1,2]), and one chooses an ordering on these vectors of integers. This ordering must satisfy some further conditions to be admissible for Gröbner bases; see monomial order for details and the admissibility conditions.
) with its vector of exponents (here [1,3,0,1,2]), and one chooses an ordering on these vectors of integers. This ordering must satisfy some further conditions to be admissible for Gröbner bases; see monomial order for details and the admissibility conditions.
One of these admissible orders is the lexicographical order. Another one is the total degree order, which consists in comparing first the total degrees, and then resolving the conflicts by using the lexicographical order. More generally, every admissible order may be defined as the lexicographical order on the values of a set of n linear forms with real coefficients applied to the vector of exponents (here n is the number of variables).[4]
Decimal fractions[edit]
For decimal fractions from the decimal point, a < b applies equivalently for the numerical order and the lexicographic order on the digital representations, provided that strings with a recurring decimal 9 like .399999... and strings with trailing zeros are omitted. With these restrictions, there is an order-preserving bijection between the numbers and the strings.
Colexicographic order[edit]

 that have a complete 5-
that have a complete 5-
The colexicographic or colex order is a natural order structure of the Cartesian product of two or more ordered sets. Given two partially ordered sets A and B, the colexicographical order on the Cartesian product A × B is defined as
- ( a, b) ≤ ( a′, b′) if and only if b < b′ or ( b = b′ and a ≤ a′ ).
The result is a partial order. If A and B are totally ordered, then the result is a total order also.
More generally, one can define the colexicographic order on the Cartesian product of n ordered sets.
Suppose
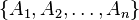
is an n-tuple of sets, with respective total orderings
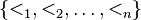
The colex ordering

of
is then


The following is an ordering on the 3-element subsets of  , based on the colex ordering of the triples obtained by writing the elements of each subset in ascending order:
, based on the colex ordering of the triples obtained by writing the elements of each subset in ascending order:
-
123 < 124 < 134 < 234 < 125 < 135 < 235 < 145 < 245 < 345 <
126 < 136 < 236 < 146 < 246 < 346 < 156 < 256 < 356 < 456
That is, one compares elements by reading from the right instead of from the left, so the right-most component is the most significant.
Colexicographical ordering is used in the Kruskal-Katona theorem.
Reverse lexicographic order[edit]
In the context of Gröbner bases, the reverse lexicographic ordering (sometime abbreviated "degrevlex", or "tdeg" in Maple) is a monomial order, which is widely used, as it is the monomial order that usually leads to the easiest computation. This is the colexicographic order on sequences of nonnegative integers of fixed length and fixed sum, with the integers ordered by the reverse of the natural order. Sequences of integers with different sums are compared by the values of their sums.
More precisely, given two different sequences (a1, ..., an) and (b1, ..., bn) of nonnegative integers, one has
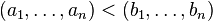
if an only if either

or


For sequences of length two, this order is the same as the order obtained by using the lexicographical order for sequences of same sum, but this is no longer true for longer sequences. For example,
- (1, 0, 1) < (0, 2, 0) for the reverse lexicographic order,
- (1, 0, 1) > (0, 2, 0) for the lexicographic order,
These two orders are the same for any other pair of sequences of length 3 and sum 2.
See also[edit]
- Collation
- Kleene–Brouwer order
- Lexicographic preferences
- Orders on the Cartesian product of totally ordered sets
- Lexicographic order on the Rn
- Lexicographic order topology on the unit square
- Long line (topology)
- Lyndon word
- Lexicographically minimal string rotation
 Lexicographic and colexicographic order
Lexicographic and colexicographic order- Star product, a different way of combining partial orders
References[edit]
- ^ Jump up to: a b Egbert Harzheim (2006). Ordered Sets. Springer. pp. 88–89. ISBN 978-0-387-24222-4.
- ^ Jump up to: a b c Franz Baader; Tobias Nipkow (1999). Term Rewriting and All That. Cambridge University Press. pp. 18–19. ISBN 978-0-521-77920-3.
- Jump up ^ Calude, Cristian (1994). Information and randomness. An algorithmic perspective. EATCS Monographs on Theoretical Computer Science. Springer-Verlag. p. 1. ISBN 3-540-57456-5. Zbl 0922.68073.
- Jump up ^ Weispfenning, Volker (May 1987), "Admissible Orders and Linear Forms", SIGSAM Bulletin (New York, NY, USA: ACM) 21 (2): 16–18, doi:10.1145/24554.24557.

















 1726
1726

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









