







今天就来聊聊InnoDB是如何保证redo log与binlog两份日志之间的逻辑一致。
一、区别redolog和binlog
1、对比
| redolog | binlog | |
| 日志作用 | 保护脏数据 | 数据库备份恢复使用 |
| 引擎支持 | 只适合InnoDB引擎 | 所有引擎 |
| 日志格式 | 物理日志 | 逻辑日志,SQL语句 |
| 提交方式 | 快速提交 | 提交时一次性写入 |
| 保存形式 | 会被循环覆盖 | 长期保存 |
2、redolog记录的是对于每个页的修改
数据页地址、行地址、操作类型(I/D)、数据
e.g:一个update修改100行,至少产生200行redo日志,所以DML产生的redo可能很大:
100、2、D
100、2、I、'value'
……
实际就是update table set ……100(数据页地址) 2(行地址)
3、binlog只是记录DML、DDL、DCL,不记录SELECT
通过参数设置控制binlog的记录模式:
1、语句模式
e.g:delete from t1 where id<=1000;
2、行模式
delete from t1 where id=1;
delete from t1 where id=2;
……
delete from t1 where id=1000;
4、图解redolog、binlog机制
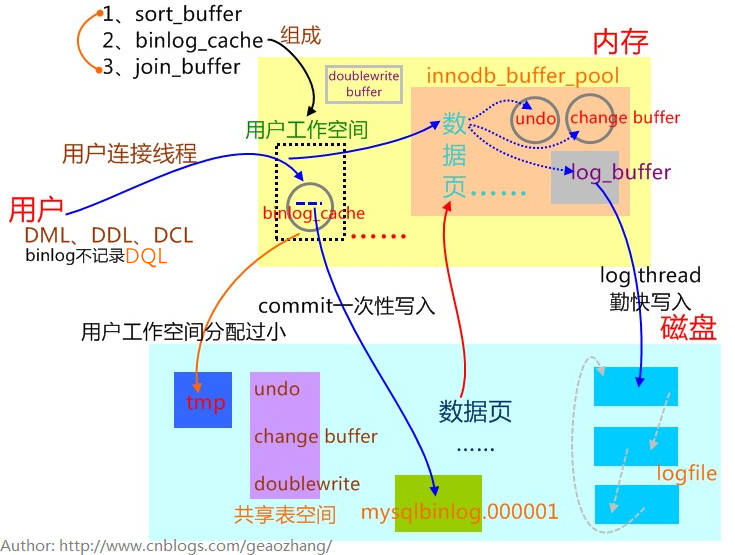
注意:
在oracle里面虽然redolog也是循环覆盖的,但是在循环覆盖之前,数据库会将redo拷贝出来做个归档,所以oracle里可以用redolog做数据恢复。
5、两阶段提交
redo log(重做日志)让InnoDB存储引擎拥有了崩溃恢复能力。
binlog(归档日志)保证了MySQL集群架构的数据一致性。
虽然它们都属于持久化的保证,但是侧重点不同。
在执行更新语句过程,会记录redo log与binlog两块日志,以基本的事务为单位,redo log在事务执行过程中可以不断写入,而binlog只有在提交事务时才写入,所以redo log与binlog的写入时机不一样。
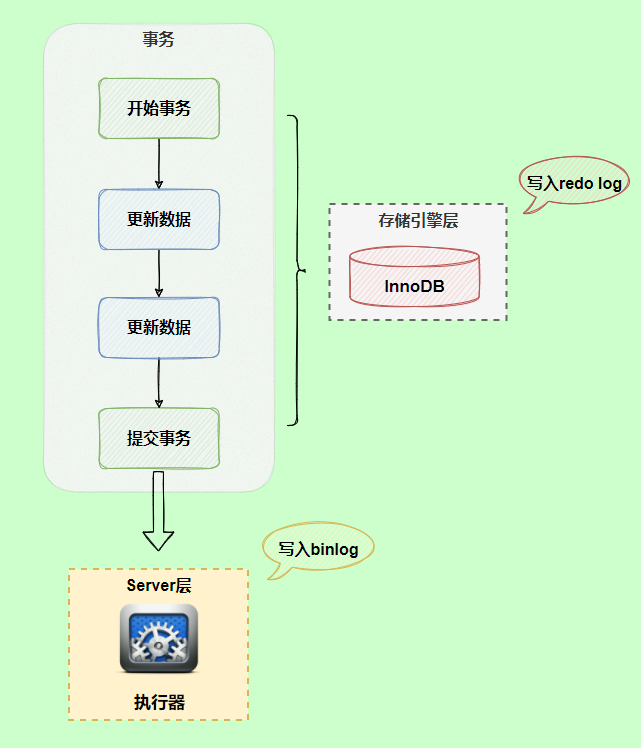
回到正题,redo log与binlog两份日志之间的逻辑不一致,会出现什么问题?
我们以update语句为例,假设id=2的记录,字段c值是0,把字段c值更新成1,SQL语句为update T set c=1 where id=2。
假设执行过程中写完redo log日志后,binlog日志写期间发生了异常,会出现什么情况呢?

由于binlog没写完就异常,这时候binlog里面没有对应的修改记录。因此,之后用binlog日志恢复数据时,就会少这一次更新,恢复出来的这一行c值是0,而原库因为redo log日志恢复,这一行c值是1,最终数据不一致。
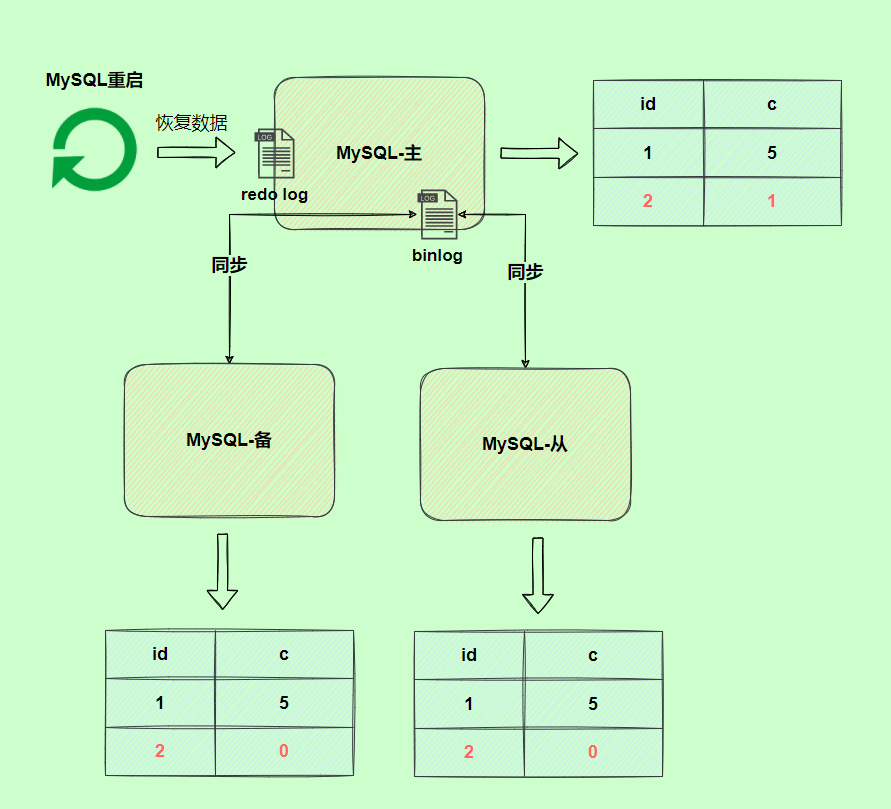
为了解决两份日志之间的逻辑一致问题,InnoDB存储引擎使用两阶段提交方案。
原理很简单,将redo log的写入拆成了两个步骤prepare和commit,这就是两阶段提交。

使用两阶段提交后,写入binlog时发生异常也不会有影响,因为MySQL根据redo log日志恢复数据时,发现redo log还处于prepare阶段,并且没有对应binlog日志,就会回滚该事务。
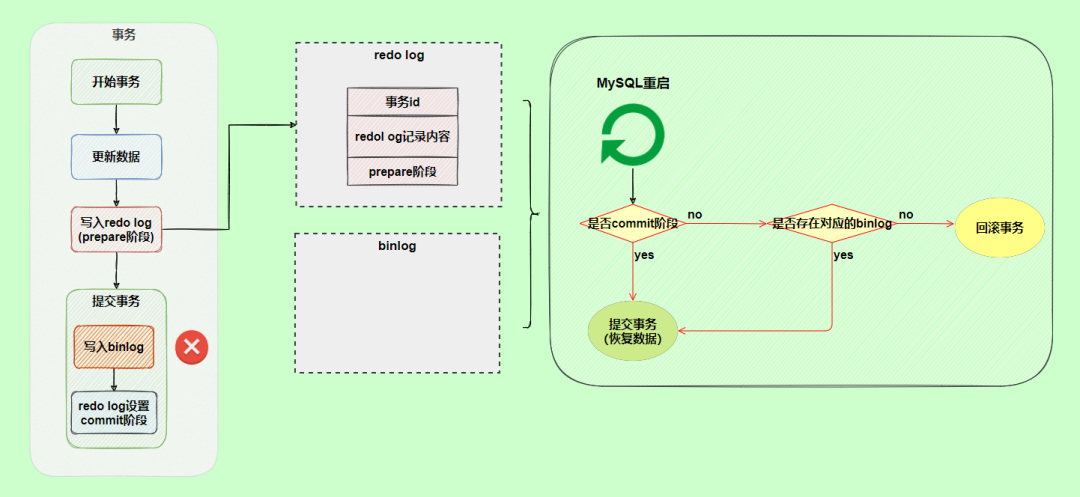
再看一个场景,redo log设置commit阶段发生异常,那会不会回滚事务呢?

并不会回滚事务,它会执行上图框住的逻辑,虽然redo log是处于prepare阶段,但是能通过事务id找到对应的binlog日志,所以MySQL认为是完整的,就会提交事务恢复数据。
二、开启binlog及相关关注点
1、开启binlog
mysql> show variables like 'log_bin';
+---------------+-------+
| Variable_name | Value |
+---------------+-------+
| log_bin | OFF | #默认是关闭的
+---------------+-------+
mysql> set @@global.log_bin=on;
ERROR 1238 (HY000): Variable 'log_bin' is a read only variable修改配置文件/etc/my.cnf,在[mysqld]下添加:
server-id=1
log-bin=mysql-bin重启MySQL,即可……binlog的启动大概会为mysql增加1%的负载,因此在绝大多数情况下,binlog都不会成为mysql的性能瓶颈,所以一般都是会开启binlog的。
2、binlog的存放
mysql> show variables like 'log_bin%';
+---------------------------------+-------------------------+
| Variable_name | Value |
+---------------------------------+-------------------------+
| log_bin | ON |
| log_bin_basename | /mydata/mysql-bin | #binlog文件,注意:每次重启会生成一个新的binlog文件
| log_bin_index | /mydata/mysql-bin.index | #二进制的索引文件,记录使用的binlog文件名3、如何手工切换binlog
1、重启数据库,每次重启都会新切binlog
2、mysql> flush logs;
4、查看binlog日志文件
[root@localhost mydata]# mysqlbinlog -vv mysql-bin.000001
/*!50530 SET @@SESSION.PSEUDO_SLAVE_MODE=1*/;
/*!50003 SET @OLD_COMPLETION_TYPE=@@COMPLETION_TYPE,COMPLETION_TYPE=0*/;
DELIMITER /*!*/;
# at 4
#170707 8:14:29 server id 1 end_log_pos 123 CRC32 0xf307168d Start: binlog v 4, server v 5.7.14-log created 170707 8:14:29 at startup
# Warning: this binlog is either in use or was not closed properly.
ROLLBACK/*!*/;
BINLOG '
…………三、关注binlog相关参数
mysql> show variables like '%bin%';1、binlog_cache_size
//设置binlog cache(默认32K),每个线程单独分配内存空间
所有未提交的二进制日志文件会被记录到用户工作空间的binlog cache中,等该事务提交时直接将缓冲区中的binlog写入二进制日志文件里
mysql> show global status like 'Binlog_cache_disk_use';
+-----------------------+-------+
| Variable_name | Value |
+-----------------------+-------+
| Binlog_cache_disk_use | 0 |
+-----------------------+-------+判断binlog_cache_size是否设置过小的依据,如果Binlog_cache_disk_use>0(次数),说明事务未提交,binlog在用户工作空间存放不下,需要借用tmp目录。
2、log_bin
//设置名字前缀
--log-bin [=file_name]:设置此参数表示启用binlog功能,并指定路径名称,生产中都要开启binlog。
sql_log_bin:会话级别的binlog开关控制,默认是开启的,可以在当前会话级别动态修改临时关闭binlog(主从延迟优化),set session sql_log_bin=0;
3、sync_binlog
//同步binlog的方式
0:默认,提交同步到文件系统缓存
1:commit,通过fsync方式,直接写入disk的binlog文件中(最安全),与redo的双一模式。
>1:sync_binlog=N,如果N>1,在意外发生的时候,就表示会有N-1个dml没有被写入binlog中,有可能就会发生主从数据不一致的情况。
4、max_binlog_size
//binlog文件大小,默认1G
如果是row模式,需要增加binlog文件的大小,因为行模式产生的日志量相对较大。如果超过了该值,就会产生新的日志文件,后缀名+1,并且记录到.index文件里面。
5、binlog_format
//row、statement、mixed,设置binlog记录的模式:行模式、语句模式、mixed模式。动态参数,可以会话级别修改
6、--binlog-do-db、--binlog-ingore-db
//command-line format,表示需要写入或者忽略写入哪些库的日志,默认为空,表示可以将所有库的日志写入到二进制文件里面。
7、log-slave-updates
//启用从机服务器上的slave日志功能,使这台计算机可以用来构成一个镜像链(A->B->C) ,可以让从库上面产生二进制日志文件,在从库上再挂载一个从库。
8、binlog_rows_query_log_events
//便于定位执行过的SQL语句
9、expire_logs_days
//binlog过期清理时间,默认是0:不自动清除
binlog的删除策略,假设expire_logs_days=5,表示系统保留5天binlog,第六天到来时会删除第一天的binlog。
1、删除策略的风险:
1、删除会导致过高的io,从而导致业务出现性能抖动
2、主从延迟
2、解决:手工主动删除binlog
PURGE BINARY LOGS #同时删除binlog文件和binlog索引文件记录,如此说来用rm删除binlog和vim修改对应binlog索引文件记录,效果同purge。
Syntax:
PURGE { BINARY | MASTER } LOGS
{ TO 'log_name' | BEFORE datetime_expr }
mysql> PURGE BINARY LOGS TO 'mysql-bin.000003'; #删到3,也就是删了1、2。四、binlog_format有哪些
1、STATEMENT
每一条会修改数据的sql都会记录在binlog中。
优点:不需要记录每一行的变化,减少了binlog日志量,节约了IO,提高性能。只需要记录在 master 上所执行的语句的细节,以及执行语句时候的上下文的信息。
缺点:由于记录的只是执行语句,为了这些语句能在slave上正确运行,因此还必须记录每条语句在执行的时候的一些相关信息,以保证所有语句能在slave得到和在master端执行时候相同的结果。像一些特定函数功能,slave可与master上要保持一致会有很多相关问题(如sleep()函数,rand()函数等会出现问题warning)。
2、ROW
不记录sql语句上下文相关信息,仅保存哪条记录被修改,也就是说日志中会记录成每一行数据被修改的形式,然后在 slave 端再对相同的数据进行修改。
优点:binlog中可以不记录执行的sql语句的上下文相关的信息,仅需要记录那一条记录被修改成什么了。所以rowlevel的日志内容会非常清楚的记录下每一行数据修改的细节。而且不会出现某些特定情况下的存储过程,或function,以及trigger的调用和触发无法被正确复制的问题。
缺点:在 row 模式下,所有的执行的语句当记录到日志中的时候,都将以每行记录的修改来记录,这样可能会产生大量的日志内容。
3、MIXED
是以上两种level的混合使用,一般的语句修改使用statment格式保存binlog,如一些函数,statement无法完成主从复制的操作,则采用row格式保存binlog,MySQL会根据执行的每一条具体的sql语句来区分对待记录的日志形式,也就是在Statement和Row之间选择一种;
新版本的MySQL中对row模式也被做了优化,并不是所有的修改都会以rowl来记录,像遇到表结构变更的时候就会以statement模式来记录。至于update或者delete等修改数据的语句,还是会记录所有行的变更。
五、binlog的使用
1、二进制日志两个最重要的使用场景
1、MySQL replication在master端开启binlog,master把它的二进制日志传递给slaves来达到master-slave数据一致的目的,也就是主从备份。
2、数据恢复,通过使用mysqlbinlog工具来使恢复数据
2、常用binlog日志操作命令
1、查看所有binlog日志列表
mysql> show master logs;
2、查看master状态,即最后(最新)一个binlog日志的编号名称,及其最后一个操作事件pos结束点(Position)值
mysql> show master status; //结合上述binlog文件,进行binlog生成速度监控
3、刷新log日志,自此刻开始产生一个新编号的binlog日志文件
mysql> flush logs; //注:每当mysqld服务重启时,会自动执行此命令,刷新binlog日志;在mysqldump备份数据时加 -F 选项也会刷新binlog日志;
4、重置(清空)所有binlog日志
mysql> reset master;
3、查看binlog日志内容
1、OS层面查看binlog文件
shell> mysqlbinlog -vv mysql-bin.000001
2、数据库层面show binlog events
mysql> show binlog events [IN 'log_name'] [FROM pos] [LIMIT [offset,] row_count];
选项解析:
1、in 'log_name':指定要查询的binlog文件名(不指定就是第一个binlog文件)
2、from pos:指定从哪个pos起始点开始查起(不指定就是从整个文件首个pos点开始算)
3、limit [offset,]:偏移量(不指定就是0)
4、row_count:查询总条数(不指定就是所有行)
mysql> show binlog events FROM 9451 limit 1\G;
*************************** 1. row ***************************
Log_name: mysql-bin.000001
Pos: 9451
Event_type: Query
Server_id: 1
End_log_pos: 9561
Info: use `db1`; create index i_n_a on t1(name,address)
1 row in set (0.00 sec)4、从binlog日志恢复语法
1、恢复语法格式:
# mysqlbinlog [选项] mysql-bin.0000xx | mysql -u用户名 -p密码 数据库名
2、常用选项:
--start-position=953 起始pos点
--stop-position=1437 结束pos点
--start-datetime="2017-6-8 13:18:54" 起始时间点
--stop-datetime="2017-6-8 13:21:53" 结束时间点
--database=TEST 指定只恢复TEST数据库(一台主机上往往有多个数据库,只限本地log日志)
3、不常用选项:
-u --user=name #Connect to the remote server as username.连接到远程主机的用户名
-p --password[=name] #Password to connect to remote server.连接到远程主机的密码
-h --host=name #Get the binlog from server.从远程主机上获取binlog日志
--read-from-remote-server #Read binary logs from a MySQL server.从某个MySQL服务器上读取binlog日志
使用小结:
实际是将读出的binlog日志内容,通过管道符传递给mysql命令。这些命令、文件尽量写成绝对路径;所谓恢复,就是让MySQL将保存在binlog日志中指定段落区间的SQL语句逐个重新执行一次而已。
1、redolog、binlog:双1(绝对安全)
1、innodb_flush_log_at_trx_commit=1
2、sync_binlog=1
2、innodb_support_xa=1:分布式事务,默认开启ON
1、保证binlog里面存在的事务一定在redo log里面存在
2、保证binlog里面事务顺序与redo log事务顺序一致性
3、commit,要么成功要么失败,防止出现主从不一致
所以在双一的情况下,也要配合开启innodb_support_xa,更安全。















 6559
6559











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









