







Linux网络协议栈之数据包处理过程
1前言
本来是想翻译《The journey of a packet through the linux 2.4 network stack》这篇文章的。但在查阅相关的资料时,发现需要补充一些技术细节,才使得我这种菜鸟理解更加深刻,所以综合了上面两篇文档,在加上自己的裁减和罗嗦,就有了下面的文字。我不知道这是否侵犯了作者权益。如果有的话,请告知,我会及时删除这篇拼凑起来的文档。
引用作者Harald Welte的话:我毫无疑问不是内核导师级人物,也许此文档的信息是错误的。所以不要对此期望太高了,我也感激你们的批评和指正。
这篇文档是基于x86体系结构和转发IP分组的。
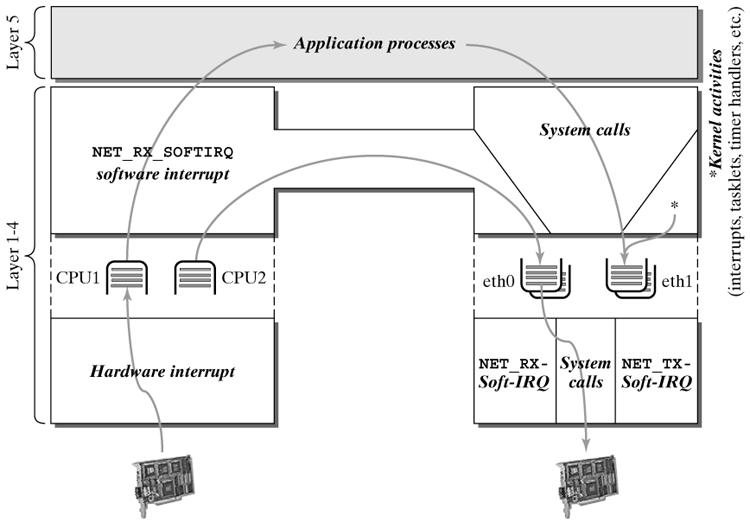
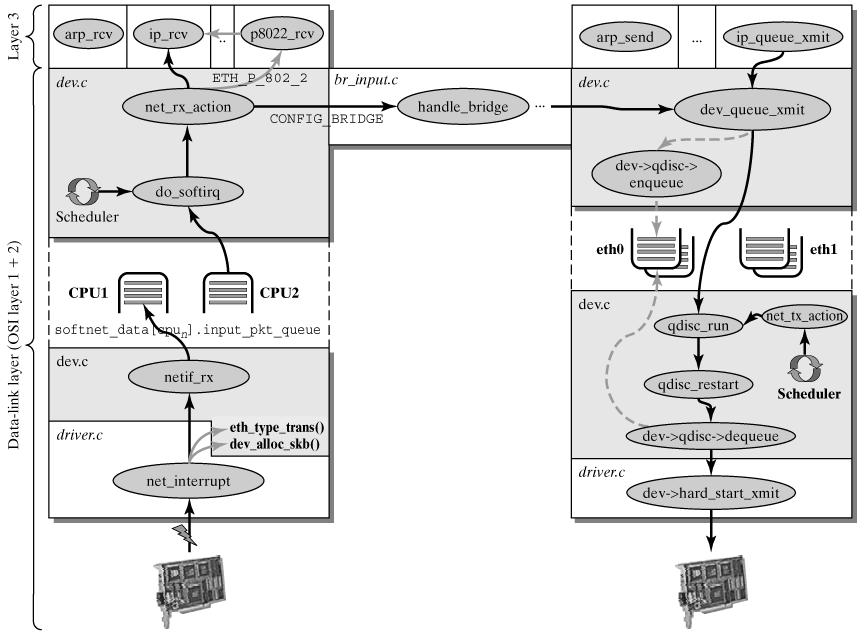
数据包在Linux内核链路层路径
2 接收分组
2.1 接收中断
如果网卡收到一个和自己MAC地址匹配或链路层广播的以太网帧,它就会产生一个中断。此网卡的驱动程序会处理此中断:
- 从DMA/PIO或其他得到分组数据,写到内存里去;
- 接着,会分配一个新的套接字缓冲区skb,并调用与协议无关的、网络设备均支持的通用网络接收处理函数netif_rx(skb)。netif_rx()函数让内核准备进一步处理skb。
- 然后,skb会进入到达队列以便CPU处理(对于多核CPU而言,每个CPU维护一个队列)。如果FIFO队列已满,就会丢弃此分组。在skb排队后,调用__cpu_raise_softirq()标记NET_RX_SOFTIRQ软中断,等待CPU执行。
- 至此,netif_rx()函数调用结束,返回调用者状况信息(成功还是失败等)。此时,中断上下文进程完成任务,数据分组继续被上层协议栈处理。
2.2 softirq 和 bottom half
内核2.4以后,整个协议栈不再使用bottom half(下半文,没找到好的翻译),而是被软中断softirq取代。软中断softirq优势明显,可以同时在多个CPU上执行;而bottom half一次只能在一个CPU上执行,即在多个CPU执行时严格保持串行。
中断服务程序往往都是在CPU关中断的条件下执行的,以避免中断嵌套而使控制复杂化。但是CPU关中断的时间不能太长,否则容易丢失中断信号。为此,Linux将中断服务程序一分为二,各称作“Top Half”和“Bottom Half”。前者通常对时间要求较为严格,必须在中断请求发生后立即或至少在一定的时间限制内完成。因此为了保证这种处理能原子地完成,Top Half通常是在CPU关中断的条件下执行的。具体地说,Top Half的范围包括:从在IDT中登记的中断入口函数一直到驱动程序注册在中断服务队列中的ISR。而Bottom Half则是Top Half根据需要来调度执行的,这些操作允许延迟到稍后执行,它的时间要求并不严格,因此它通常是在CPU开中断的条件下执行的,比如网络底层操作就是这样,由于某些原因,中断并没有立刻响应,而是先记录下来,等到可以处理这些中断的时候就一块处理了。但是,Linux的这种Bottom Half(以下简称BH)机制有两个缺点,也即:(1)在任意一时刻,系统只能有一个CPU可以执行Bottom Half代码,以防止两个或多个CPU同时来执行Bottom Half函数而相互干扰。因此BH代码的执行是严格“串行化”的。(2)BH函数不允许嵌套。这两个缺点在单CPU系统中是无关紧要的,但在SMP系统中却是非常致命的。因为BH机制的严格串行化执行显然没有充分利用SMP系统的多CPU特点。为此,Linux2.4内核在BH机制的基础上进行了扩展,这就是所谓的“软中断请求”(softirq)机制。Linux的softirq机制是与SMP紧密不可分的。为此,整个softirq机制的设计与实现中自始自终都贯彻了一个思想:“谁触发,谁执行”(Who marks,Who runs),也即触发软中断的那个CPU负责执行它所触发的软中断,而且每个CPU都由它自己的软中断触发与控制机制。这个设计思想也使得softirq 机制充分利用了SMP系统的性能和特点。
2.3 NET_RX_SOFTIRQ 网络接收软中断
这两篇文档描述的各不相同,侧重不一。在这里,只好取重避轻。
这一阶段会根据协议的不同来处理数据分组。CPU开始处理软中断do_softirq(),,接着net_rx_action()处理前面标记的NET_RX_SOFTIRQ,把出对列的skb送入相应列表处理(根据协议不同到不同的列表)。比如,IP分组交给ip_rcv()处理,ARP分组交给arp_rcv()处理等。
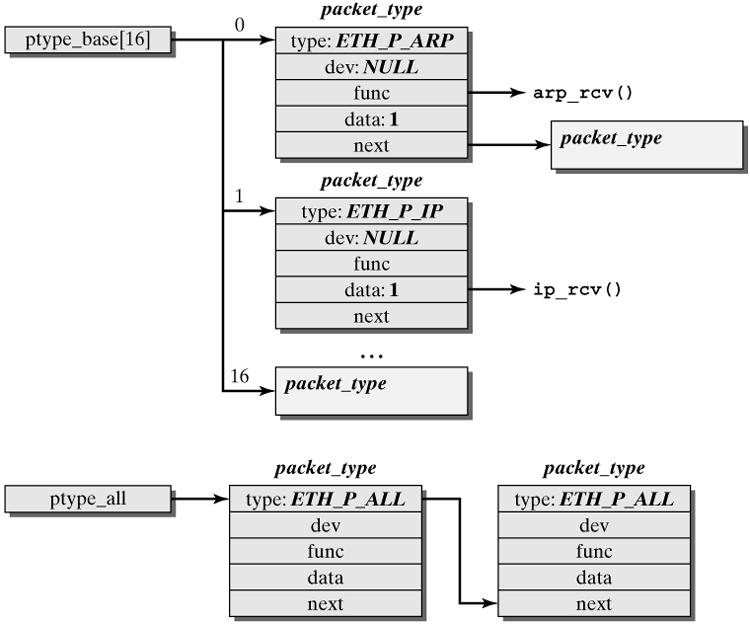
2.4 处理IPv4分组
下面以IPv4为例,讲解IPv4分组在高层的处理。
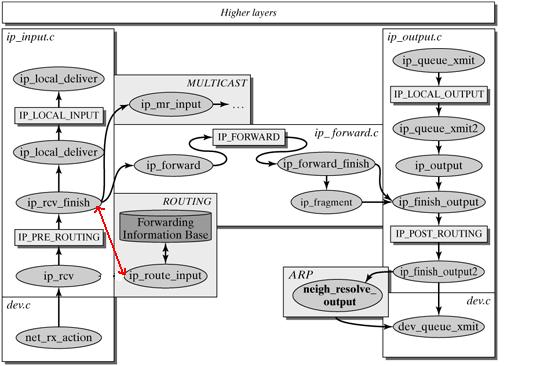
linux内核协议栈之网络层
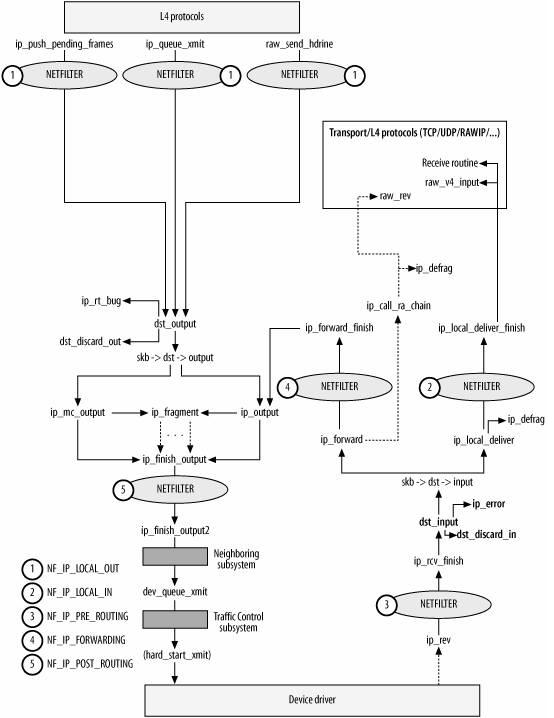
以上两个图都是一个意思,可以对比着看。
ip_rcv()函数验证IP分组,比如目的地址是否本机地址,校验和是否正确等。若正确,则交给netfilter的NF_IP_PRE_ROUTING钩子(关于netfilter细节可以参考Hacking the Linux Kernel Network Stack);否则,丢弃。
到了ip_rcv_finish()函数,数据包就要根据skb结构的目的或路由信息各奔东西了。
- 判断数据包的去向,ip_local_deliver() 处理到本机的数据分组、ip_forward() 处理需要转发的数据分组、ip_mr_input() 转发组播数据包。如果是转发的数据包,还需要找出出口设备和下一跳。
-
分析和处理IP选项。(并不是处理所有的IP选项)。
具体来说,从skb->nh(IP头,由netif_receive_skb初始化)结构得到IP地址:struct net_device *dev = skb->dev; struct iphdr *iph = skb->nh.iph;
而skb->dst或许包含了数据分组到达目的地的路由信息,如果没有,则需要查找路由,如果最后结果显示目的地不可达,那么就丢弃该数据包:
if (skb->dst == NULL) {
if (ip_route_input(skb, iph->daddr, iph->saddr, iph->tos, dev))
goto drop;
}
ip_rcv_finish()函数最后执行dst_input,决定数据包的下一步的处理。
2.4.1 转发数据包
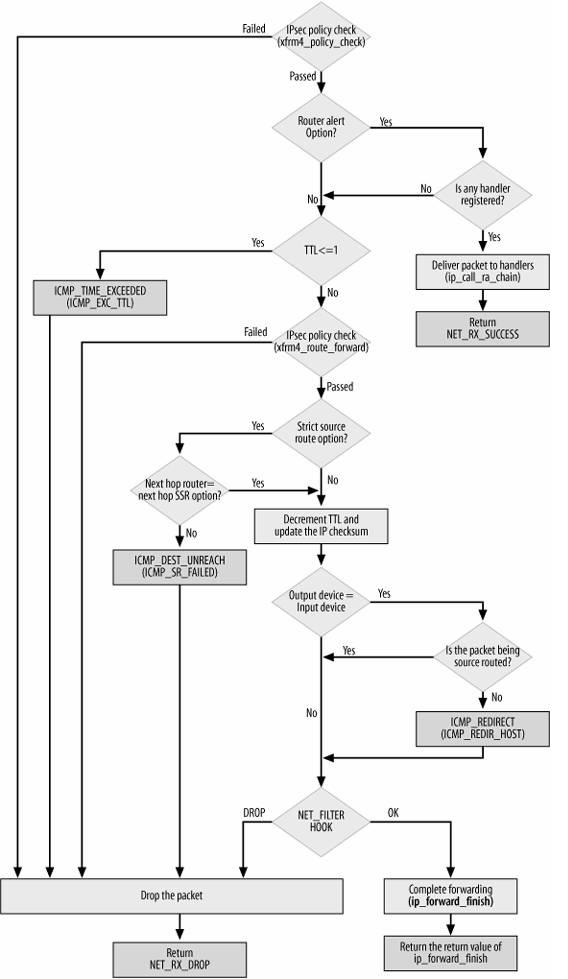
转发数据包主要包括一下步骤:
- l 处理IP头选项。如果需要的话,会记录本地IP地址和时间戳;
- l 确认分组可以被转发;
- l 将TTL减一,如果TTL为0,则丢弃分组;
- l 根据MTU大小和路由信息,对数据分组进行分片,如果需要的话;
- l 将数据分组送往外出设备。
如果由于某种原因,数据分组不能被转发,那么就回应ICMP消息来说明不能转发的原因。在对转发的分组进行各种检查无误后,执行ip_forward_finish,准备发送。然后执行dst_output(skb)。无论是转发的分组,还是本地产生的分组,都要经过dst_output(skb)到达目的主机。IP头在此时已经完成就绪。dst_output(skb)函数要执行虚函数output(单播的话为ip_output,多播为ip_mc_output)。最后,ip_finish_output进入邻居子系统。
下图是转发数据包的流程图:
2.4.1 本地处理
int ip_local_deliver(struct sk_buff *skb)
{
if (skb->nh.iph->frag_off & htons(IP_MF|IP_OFFSET)) {
skb = ip_defrag(skb, IP_DEFRAG_LOCAL_DELIVER);
if (!skb)
return 0;
}
return NF_HOOK(PF_INET, NF_IP_LOCAL_IN, skb, skb->dev, NULL,
ip_local_deliver_finish);
}
最后执行ip_local_deliver_finish。
以下属ip_local_deliver_finish函数流程图:
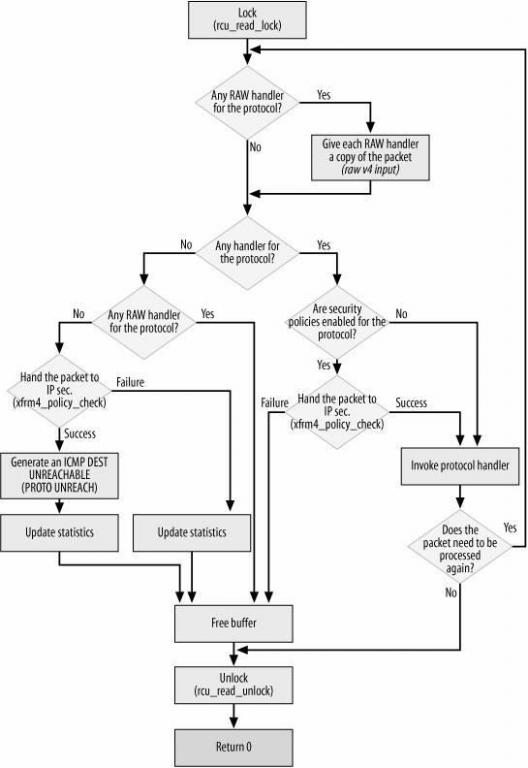
在L4协议中,TCP和UDP是运行在内核空间的,而RAW则可以运行在用户空间中。
TCP处理见下图:
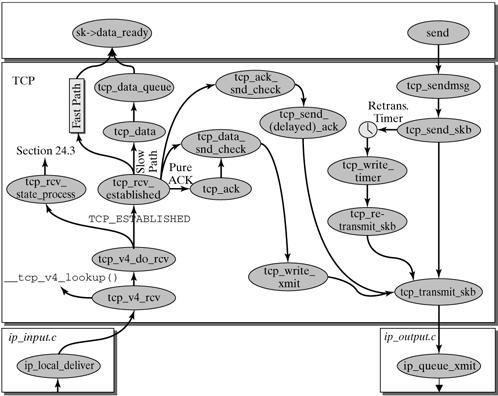
UDP处理略。
数据分组的发送:
ip_queue_xmit检查socket结构体中是否含有路由信息,如果没有则执行ip_route_output_flow查找,并存储到sk数据结构中。如果找不到,则丢弃数据包。
至此,数据分组的接受和处理工作就告一段落了,至于于此相对的数据分组的发送,我就贴个图吧,具体细节可参考The Linux® Networking Architecture: Design and Implementation of Network Protocols in the Linux Kernel Prentice Hall August 01, 2004
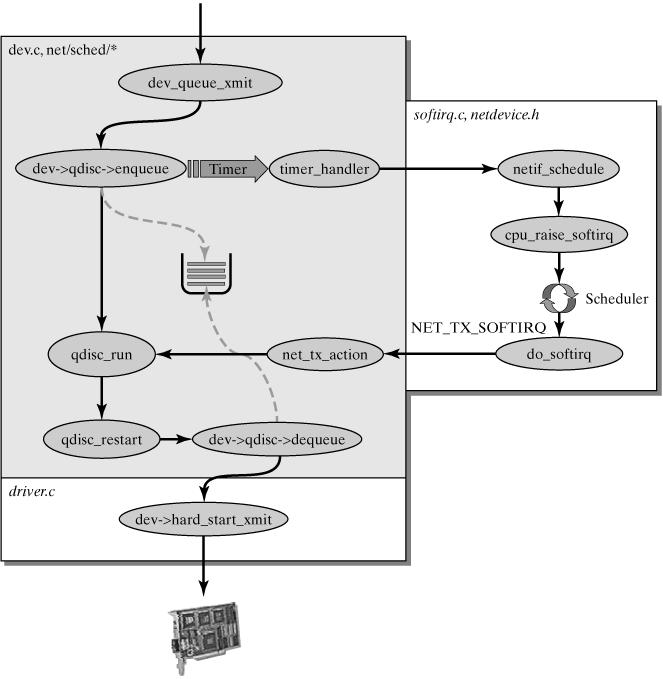
dev_queue_xmit()处理发送分组
附一张Linux 2.4 核的netfilter框架下分组的走向图:
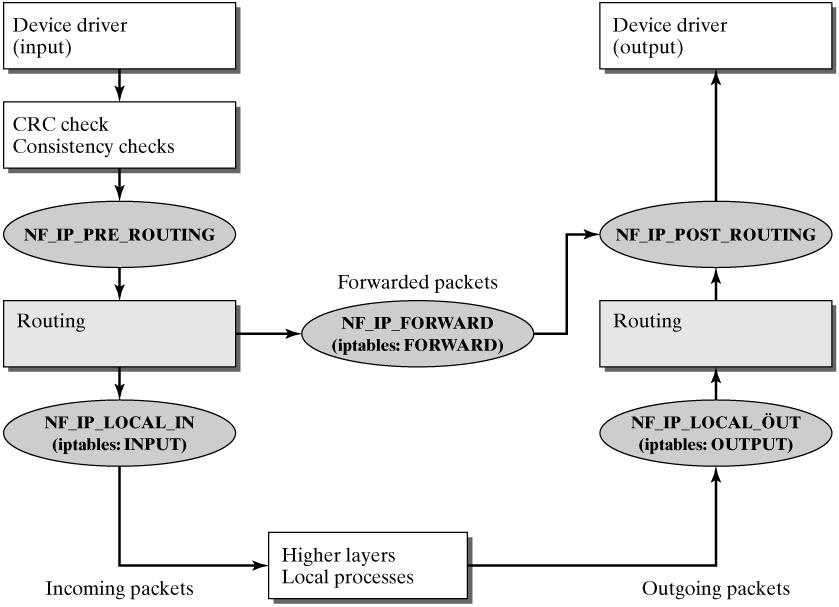
来自链接:
http://ftp.gnumonks.org/pub/doc/packet-journey-2.4.html
http://m.linuxjournal.com/article/4852
这篇文档描述了网络分组在linux内核2.4协议栈的处理过程。
内核的路由部分是是网络中重要部分,目前在Linux内核中默认的路由查找算法使用的是Hash查找,所以你会看到很多的数据结构是XXX_hash什么之类(例如fn_hash)。Linux内核从2.1开始就支持基于策略的路由,那么什么是基于策略的路由呢?我们一般的最基本的路由转发是考虑IP包的目的地址,但是有些时候不仅仅是这些,还有例如IP协议,传输端口等之类的考虑因素,所以采用所谓基于策略的路由。
或许这样理解更好,Linux默认有三种策略路由:本地路由,主路由和默认路由,那么与之对应的就是三张路由表:本地路由表,主路由表和默认路由表。
那么我们需要理解是什么呢?当然是路由怎么转的过程。在这之前,先看看所涉及数据结构有哪些。
介绍下面之前我们首先需要知道内核常用的结构之间的操作手法。说道这里不得不先说一下内核的链表结构。
内核的链表结构主要是用来表示连接关系的
- struct hlist_head {
- struct hlist_node *first;
- };
- struct hlist_node {
- struct hlist_node *next, **pprev; // 看这个你就知道,内核链表一般是双向链表(其实还是循环链表)
- };
struct hlist_head {
struct hlist_node *first;
};
struct hlist_node {
struct hlist_node *next, **pprev; // 看这个你就知道,内核链表一般是双向链表(其实还是循环链表)
};
那么下面的很多结构之间的链接都是通过这样的链表的!但是就算我通过一个结构找到另一个结构的链表字段的时候,怎么确定结构真正的首地址呢?其实我们都不用担心,内核采取container_of这个宏定义来处理的!
- #define container_of(ptr, type, member) ({ \
- const typeof( ((type *)0)->member ) *__mptr = (ptr); \
- (type *)( (char *)__mptr - offsetof(type,member) );})
#define container_of(ptr, type, member) ({ \
const typeof( ((type *)0)->member ) *__mptr = (ptr); \
(type *)( (char *)__mptr - offsetof(type,member) );})
很简单,其实就是通过偏移来做的,很easy、
- struct fib_table {
- struct hlist_node tb_hlist;// hash节点(通过ipv4的hlist_head可以得到属于自己的路由信息表FIB,这个就是链接字段)
- u32 tb_id; // 标识符(例如:本地路由,主路由,默认路由)
- unsigned tb_stamp; // 时间戳
- int tb_default;// 路由信息结构队列序号
- int (*tb_lookup)(struct fib_table *tb,conststruct flowi *flp,struct fib_result *res);// 查找函数
- int (*tb_insert)(struct fib_table *, struct fib_config *);// 插入函数
- int (*tb_delete)(struct fib_table *,struct fib_config *);// 删除路由函数
- int (*tb_dump)(struct fib_table *table, struct sk_buff *skb,
- struct netlink_callback *cb); // 用于路由转发
- int (*tb_flush)(struct fib_table *table); // 移除路由信息结构
- void (*tb_select_default)(struct fib_table *table, // 设置默认路由
- const struct flowi *flp,struct fib_result *res);
- unsigned char tb_data[0]; // 注意这个特殊字段,标识结构的结尾,分配fib_table同时分配fn_hash结构
- }; // 也就是fib_table之后就是fn_hash结构
struct fib_table {
struct hlist_node tb_hlist;// hash节点(通过ipv4的hlist_head可以得到属于自己的路由信息表FIB,这个就是链接字段)
u32 tb_id; // 标识符(例如:本地路由,主路由,默认路由)
unsigned tb_stamp; // 时间戳
int tb_default;// 路由信息结构队列序号
int (*tb_lookup)(struct fib_table *tb, const struct flowi *flp, struct fib_result *res);// 查找函数
int (*tb_insert)(struct fib_table *, struct fib_config *);// 插入函数
int (*tb_delete)(struct fib_table *, struct fib_config *);// 删除路由函数
int (*tb_dump)(struct fib_table *table, struct sk_buff *skb,
struct netlink_callback *cb); // 用于路由转发
int (*tb_flush)(struct fib_table *table); // 移除路由信息结构
void (*tb_select_default)(struct fib_table *table, // 设置默认路由
const struct flowi *flp, struct fib_result *res);
unsigned char tb_data[0]; // 注意这个特殊字段,标识结构的结尾,分配fib_table同时分配fn_hash结构
}; // 也就是fib_table之后就是fn_hash结构
// 先介绍一下“路由区”定义:fn_zone,举个例子,子网掩码长度相同的认为是相同的路由区(ok)
- struct fn_hash { // 路由区结构体的数组( 包含所有的额路由区的情况 )
- struct fn_zone *fn_zones[33];// 路由区分成33份,why?仔细想想,子网掩码长度是1~32,0长度掩码代表网关,那么加起来就是33,即:fn_zone[0]的掩码是0.0.0.0,fn_zone[1]是10000000.00000000.00000000.0000000这一类 等等
- struct fn_zone *fn_zone_list;// 指向第一个活动的路由区
- };
struct fn_hash { // 路由区结构体的数组( 包含所有的额路由区的情况 )
struct fn_zone *fn_zones[33];// 路由区分成33份,why?仔细想想,子网掩码长度是1~32,0长度掩码代表网关,那么加起来就是33,即:fn_zone[0]的掩码是0.0.0.0,fn_zone[1]是10000000.00000000.00000000.0000000这一类 等等
struct fn_zone *fn_zone_list;// 指向第一个活动的路由区
};
- struct fn_zone { // 路由区结构体(所有的子网长度相等的被分在同一个路由区)
- struct fn_zone *fz_next; // 指向下一个不为空的路由区结构,那么所有的路由区就能链接起来
- struct hlist_head *fz_hash; // 有一个hash数组,<span style="font-family: Arial, Helvetica, sans-serif;">用来hash得到一个hlist_head,是很多的fib_node通过自己的字段连接在这个队列中,那么通过这个fz_hahs字段可以找到fib_node所在的队列的头hlist_head,进而找到对应的fib_node ( 注意:上面说的hash数组的长度是fz_divisor长度)</span>
- int fz_nent; // 包含的路由节总数
- int fz_divisor; // hash头数量(上面说了)
- u32 fz_hashmask; // 确定hash头的掩码
- #define FZ_HASHMASK(fz) ((fz)->fz_hashmask)
- int fz_order; // 子网掩码位数
- __be32 fz_mask; // 子网掩码
- #define FZ_MASK(fz) ((fz)->fz_mask) // 获取子网掩码的宏定义
- };
struct fn_zone { // 路由区结构体(所有的子网长度相等的被分在同一个路由区)
struct fn_zone *fz_next; // 指向下一个不为空的路由区结构,那么所有的路由区就能链接起来
struct hlist_head *fz_hash; // 有一个hash数组,<span style="font-family:Arial, Helvetica, sans-serif;">用来hash得到一个hlist_head,是很多的fib_node通过自己的字段连接在这个队列中,那么通过这个fz_hahs字段可以找到fib_node所在的队列的头hlist_head,进而找到对应的fib_node ( 注意:上面说的hash数组的长度是fz_divisor长度)</span>
int fz_nent; // 包含的路由节总数
int fz_divisor; // hash头数量(上面说了)
u32 fz_hashmask; // 确定hash头的掩码
#define FZ_HASHMASK(fz) ((fz)->fz_hashmask)
int fz_order; // 子网掩码位数
__be32 fz_mask; // 子网掩码
#define FZ_MASK(fz) ((fz)->fz_mask) // 获取子网掩码的宏定义
};
- struct fib_node { // 路由节点结构体( 子网相等的路由被分在一起 )
- struct hlist_node fn_hash;// 链接到hash表节点( 注意到我们上面所说的fn_zone中的fz_hash了吗?fz_hash哈希之后得到的结果就是fib_node的这个字段,所以这个字段同样仅仅是作为链接作用而已 )
- struct list_head fn_alias;// 别名?其实更好的理解是这样的:虽然现在所有的路由都是同一个子网了,但是路由之间还会有其他的信息不同例如tos,路由类型,等等。所以依然存在不同的路由,所以这些都是通过fn_alias来区分。
- __be32 fn_key; // 路由别名队列:即这个node下面所有的具体路由(不同的fn_alias的)都在这个队列中
- struct fib_alias fn_embedded_alias;// 分配路由节点的时候同时也分配一个路由别名,所以称为嵌入式的~
- };
struct fib_node { // 路由节点结构体( 子网相等的路由被分在一起 )
struct hlist_node fn_hash; // 链接到hash表节点( 注意到我们上面所说的fn_zone中的fz_hash了吗?fz_hash哈希之后得到的结果就是fib_node的这个字段,所以这个字段同样仅仅是作为链接作用而已 )
struct list_head fn_alias;// 别名?其实更好的理解是这样的:虽然现在所有的路由都是同一个子网了,但是路由之间还会有其他的信息不同例如tos,路由类型,等等。所以依然存在不同的路由,所以这些都是通过fn_alias来区分。
__be32 fn_key; // 路由别名队列:即这个node下面所有的具体路由(不同的fn_alias的)都在这个队列中
struct fib_alias fn_embedded_alias; // 分配路由节点的时候同时也分配一个路由别名,所以称为嵌入式的~
};
- struct fib_alias { // 路由别名结构,这个结构基本就是最后一次路由筛选了
- struct list_head fa_list; // 这个是用于链接到fib_node节点中的,看上面的结构体的第二个字段的类型你就懂了~~~~~~
- struct fib_info *fa_info;// 这是很重要的字段:顾名思义,就是具体怎么处置这个数据包的操作等
- u8 fa_tos; // 服务类型TOS
- u8 fa_type; // 路由类型
- u8 fa_scope; // 路由范围
- u8 fa_state; // 路由状态
- #ifdef CONFIG_IP_FIB_TRIE
- struct rcu_head rcu;
- #endif
- };
struct fib_alias { // 路由别名结构,这个结构基本就是最后一次路由筛选了
struct list_head fa_list; // 这个是用于链接到fib_node节点中的,看上面的结构体的第二个字段的类型你就懂了~~~~~~
struct fib_info *fa_info; // 这是很重要的字段:顾名思义,就是具体怎么处置这个数据包的操作等
u8 fa_tos; // 服务类型TOS
u8 fa_type; // 路由类型
u8 fa_scope; // 路由范围
u8 fa_state; // 路由状态
#ifdef CONFIG_IP_FIB_TRIE
struct rcu_head rcu;
#endif
};
- struct fib_info { // 具体怎么路由这个数据包的信息
- struct hlist_node fib_hash; // 链接到fib_info_hash队列
- struct hlist_node fib_lhash; // 链接到fib_hash_laddrhash队列
- struct net *fib_net; // 所属网络空间
- int fib_treeref; // 路由信息结构使用计数器
- atomic_t fib_clntref; // 释放路由信息结构(fib)计数器
- int fib_dead; // 标志路由被删除了
- unsigned fib_flags; // 标识位
- int fib_protocol; // 安装路由协议
- __be32 fib_prefsrc; // 指定源IP,源地址和目的地址组成一个路由
- u32 fib_priority; // 路由优先级
- u32 fib_metrics[RTAX_MAX]; // 保存负载值(例如MTU,MSS)
- #define fib_mtu fib_metrics[RTAX_MTU-1] // MTU值
- #define fib_window fib_metrics[RTAX_WINDOW-1] // 窗口值
- #define fib_rtt fib_metrics[RTAX_RTT-1] // RTT值
- #define fib_advmss fib_metrics[RTAX_ADVMSS-1] // MSS值(对外公开的)
- int fib_nhs; // 倒数第二个字段即:跳转结构的数组个数
- #ifdef CONFIG_IP_ROUTE_MULTIPATH
- int fib_power; // 支持多路径时候使用
- #endif
- struct fib_nh fib_nh[0]; // 跳转结构(就是该怎么路由)
- #define fib_dev fib_nh[0].nh_dev
- };
struct fib_info { // 具体怎么路由这个数据包的信息
struct hlist_node fib_hash; // 链接到fib_info_hash队列
struct hlist_node fib_lhash; // 链接到fib_hash_laddrhash队列
struct net *fib_net; // 所属网络空间
int fib_treeref; // 路由信息结构使用计数器
atomic_t fib_clntref; // 释放路由信息结构(fib)计数器
int fib_dead; // 标志路由被删除了
unsigned fib_flags; // 标识位
int fib_protocol; // 安装路由协议
__be32 fib_prefsrc; // 指定源IP,源地址和目的地址组成一个路由
u32 fib_priority; // 路由优先级
u32 fib_metrics[RTAX_MAX]; // 保存负载值(例如MTU,MSS)
#define fib_mtu fib_metrics[RTAX_MTU-1] // MTU值
#define fib_window fib_metrics[RTAX_WINDOW-1] // 窗口值
#define fib_rtt fib_metrics[RTAX_RTT-1] // RTT值
#define fib_advmss fib_metrics[RTAX_ADVMSS-1] // MSS值(对外公开的)
int fib_nhs; // 倒数第二个字段即:跳转结构的数组个数
#ifdef CONFIG_IP_ROUTE_MULTIPATH
int fib_power; // 支持多路径时候使用
#endif
struct fib_nh fib_nh[0]; // 跳转结构(就是该怎么路由)
#define fib_dev fib_nh[0].nh_dev
};
对于上面的fib_nh[0],这样的操作手法在内核中也是常见的。代表会有这个字段的存在,但是具体是几个并不知道,因为可能是动态的,所以需要一个计数表示,也就是fib_power
OK,主要的数据结构已经介绍,后面的结构会边说边介绍,下面我们根据路由转发的顺序来梳理一下思路:
数据包的路由是通过函数ip_route_input来处理的,看这个函数:
- externint ip_route_input(struct sk_buff*, __be32 dst, __be32 src, u8 tos,struct net_device *devin);
extern int ip_route_input(struct sk_buff*, __be32 dst, __be32 src, u8 tos, struct net_device *devin);
参数有5个:
skb: IP包缓冲区,
dst: IP包的目的地址,
src: IP包源地址,
tos: 服务类型,
devin: 输入的网络设备。
怎么运行的呢?首先这个函数需要查路由缓存(cache),如果找到了那么它给skb->dst赋值并返回,如是没找到,它会调用ip_route_input_slow去查询路由数据库。
这里我们需要理解几个问题: 首先路由缓存到底是什么结构,怎么查找,这个我们马上就会说到。再次我们需要知道所谓路由就是最终找到这个路由条目,得到目的地址(吓一跳),然后赋值给skb->dst,然后通过skb->dst->input(skb)就可以进行操作。第三需要注意,这里的操作分成两类:第一类是投到本地,即数据是发到本机的,那么调用ip_local_deliver将数据包发送给上一层进行处理;第二类是转发,调用ip_forward函数进行处理,转发出去!最后注意:当路由缓冲找不到所需要的路由项,那么最终需要再次到fib中去查找,也就是完整的一个查找过程。
下面具体看看路由缓存问题:
首先是怎么建立这个缓存的呢?其实这个问题不需要特意来说,因为后面肯定会说到,为什么呢?缓存总是由不存在到存在的,当不存在的时候只能使用查询路由信息库来处理,但是同时需要注意:更新缓存cache、这个时候就是建立cache的时候。所以在后面说到的路由信息库查询和cache的建立是一样的,先不说这个,先直接看在cache中处理。
cache的结构定义为:
- staticstruct rt_hash_bucket *rt_hash_table;
static struct rt_hash_bucket *rt_hash_table;
rt_hash_table就是路由cache,它是rt_hash_bucket结构。
- struct rt_hash_bucket {
- struct rtable *chain;
- }
struct rt_hash_bucket {
struct rtable *chain;
}注意chain是一个rtable结构,看下面:
- struct rtable
- {
- union
- {
- struct dst_entry dst; // 这是目的地址
- } u;
- /* Cache lookup keys */
- struct flowi fl; // 注意在cache中的查找主要是通过路由键值和下面的信息
- struct in_device *idev; // 设备
- int rt_genid; // 路由id
- unsigned rt_flags; // 标识
- __u16 rt_type; // 路由类型
- __be32 rt_dst; // 目的地址
- __be32 rt_src; // 源地址
- int rt_iif; // 入端口
- /* Info on neighbour */
- __be32 rt_gateway; // 网关
- /* Miscellaneous cached information */
- __be32 rt_spec_dst; /* RFC1122 specific destination */
- struct inet_peer *peer; /* long-living peer info */
- };
struct rtable
{
union
{
struct dst_entry dst; // 这是目的地址
} u;
/* Cache lookup keys */
struct flowi fl; // 注意在cache中的查找主要是通过路由键值和下面的信息
struct in_device *idev; // 设备
int rt_genid; // 路由id
unsigned rt_flags; // 标识
__u16 rt_type; // 路由类型
__be32 rt_dst; // 目的地址
__be32 rt_src; // 源地址
int rt_iif; // 入端口
/* Info on neighbour */
__be32 rt_gateway; // 网关
/* Miscellaneous cached information */
__be32 rt_spec_dst; /* RFC1122 specific destination */
struct inet_peer *peer; /* long-living peer info */
};
我们看一下查询的一小段代码:
- 2048 for (rth = rcu_dereference(rt_hash_table[hash].chain); rth;
- 2049 rth = rcu_dereference(rth->u.dst.rt_next)) {
- 2050 if (rth->fl.fl4_dst == daddr &&
- 2051 rth->fl.fl4_src == saddr &&
- 2052 rth->fl.iif == iif &&
- 2053 rth->fl.oif == 0 &&
- 2054 rth->fl.mark == skb->mark &&
- 2055 rth->fl.fl4_tos == tos &&
- 2056 rth->u.dst.dev->nd_net == net &&
- 2057 rth->rt_genid == atomic_read(&rt_genid)) {
- 2058 dst_use(&rth->u.dst, jiffies);
- 2059 RT_CACHE_STAT_INC(in_hit);
- 2060 rcu_read_unlock();
- 2061 skb->dst = (struct dst_entry*)rth;
- 2062 return 0;
- 2063 }
- 2064 RT_CACHE_STAT_INC(in_hlist_search);
- 2065 }
2048 for (rth = rcu_dereference(rt_hash_table[hash].chain); rth;
2049 rth = rcu_dereference(rth->u.dst.rt_next)) {
2050 if (rth->fl.fl4_dst == daddr &&
2051 rth->fl.fl4_src == saddr &&
2052 rth->fl.iif == iif &&
2053 rth->fl.oif == 0 &&
2054 rth->fl.mark == skb->mark &&
2055 rth->fl.fl4_tos == tos &&
2056 rth->u.dst.dev->nd_net == net &&
2057 rth->rt_genid == atomic_read(&rt_genid)) {
2058 dst_use(&rth->u.dst, jiffies);
2059 RT_CACHE_STAT_INC(in_hit);
2060 rcu_read_unlock();
2061 skb->dst = (struct dst_entry*)rth;
2062 return 0;
2063 }
2064 RT_CACHE_STAT_INC(in_hlist_search);
2065 }
所以很清晰的看到匹配的所有字段。下面看看我们构造一下在cache中查找的结构图:

首先通过hash找到这个队列首部的chain,然后在chain的队列中进行匹配,如果匹配到那么OK,否则进行完整的查询。
OK,假如现在在缓存cache中并没有找到,那么执行ip_route_input_slow函数进行完整查询。
我们知道Linux最多可以支持255张路由表,默认有三张路由表,即本地路由表,主路由表和默认路由表,三个优先级递减(数字越大优先级越小),也就是查询顺序递减。我们先需要知道怎么样得到这三张路由表先。三张路由表就是三个规则,所以需要看看下面的路由信息结构规则结构体。
表255: 本地路由表(local ) 本地接口地址,广播地址,已及NAT地址都放在这个表。该路由表由系统自动维护,管理员不能直接修改。
表254: 主路由表(main ) 如果没有指明路由所属的表,所有的路由都默认都放在这个表里,一般来说,旧的路由工具(如route)所添加的路由都会加到这个表。一般是普通的路由。
表253: 默认路由表 (default ) 一般来说默认的路由都放在这张表。
表 0 :保留
看一下它们是怎么被初始化的:
- staticint fib_default_rules_init(struct fib_rules_ops *ops)
- {
- int err;
- err = fib_default_rule_add(ops, 0, RT_TABLE_LOCAL, FIB_RULE_PERMANENT); // 本地路由规则(本地路由表)
- if (err < 0)
- return err;
- err = fib_default_rule_add(ops, 0x7FFE, RT_TABLE_MAIN, 0); // 主路由规则(主路由表)
- if (err < 0)
- return err;
- err = fib_default_rule_add(ops, 0x7FFF, RT_TABLE_DEFAULT, 0); // 默认路由规则(默认路由表)
- if (err < 0)
- return err;
- return 0;
- }
static int fib_default_rules_init(struct fib_rules_ops *ops)
{
int err;
err = fib_default_rule_add(ops, 0, RT_TABLE_LOCAL, FIB_RULE_PERMANENT); // 本地路由规则(本地路由表)
if (err < 0)
return err;
err = fib_default_rule_add(ops, 0x7FFE, RT_TABLE_MAIN, 0); // 主路由规则(主路由表)
if (err < 0)
return err;
err = fib_default_rule_add(ops, 0x7FFF, RT_TABLE_DEFAULT, 0); // 默认路由规则(默认路由表)
if (err < 0)
return err;
return 0;
}
- // 本地规则local_rule
- staticstruct fib_rule local_rule = {
- r_next: &main_rule, //下一条规则是主规则
- r_clntref: ATOMIC_INIT(2),
- r_table: RT_TABLE_LOCAL, // 指向本地路由表
- r_action: RTN_UNICAST, // 动作是返回路由
- };
// 本地规则local_rule
static struct fib_rule local_rule = {
r_next: &main_rule, //下一条规则是主规则
r_clntref: ATOMIC_INIT(2),
r_table: RT_TABLE_LOCAL, // 指向本地路由表
r_action: RTN_UNICAST, // 动作是返回路由
};- // 主规则main_rule
- staticstruct fib_rule main_rule = {
- r_next: &default_rule, // 下一条规则是默认规则
- r_clntref: ATOMIC_INIT(2),
- r_preference: 0x7FFE, // 默认规则的优先级32766
- r_table: RT_TABLE_MAIN, // 指向主路由表
- r_action: RTN_UNICAST, // 动作是返回路由
- };
// 主规则main_rule
static struct fib_rule main_rule = {
r_next: &default_rule, // 下一条规则是默认规则
r_clntref: ATOMIC_INIT(2),
r_preference: 0x7FFE, // 默认规则的优先级32766
r_table: RT_TABLE_MAIN, // 指向主路由表
r_action: RTN_UNICAST, // 动作是返回路由
};- // 默认规则default rule
- staticstruct fib_rule default_rule = {
- r_clntref: ATOMIC_INIT(2),
- r_preference: 0x7FFF, // 默认规则的优先级32767
- r_table: RT_TABLE_DEFAULT, // 指默认路由表
- r_action: RTN_UNICAST, // 动作是返回路由
- };
// 默认规则default rule
static struct fib_rule default_rule = {
r_clntref: ATOMIC_INIT(2),
r_preference: 0x7FFF, // 默认规则的优先级32767
r_table: RT_TABLE_DEFAULT, // 指默认路由表
r_action: RTN_UNICAST, // 动作是返回路由
};注意:规则链的链头指向本地规则。
下面我们需要看看这个结构体:
- struct fib_rule // 规则结构体(在初始化的时候,会注册上面的三种规则,生成默认的三张表)
- {
- struct list_head list; // 用来链入路由规则函数队列中(fib_rules_ops,下面介绍)
- atomic_t refcnt; // 计数器
- int ifindex; // 网络设备id
- char ifname[IFNAMSIZ]; // 设备名称
- u32 mark; // 用于过滤作用
- u32 mark_mask; // 掩码
- u32 pref; // 优先级(例如上面代码中分别是0,0x7FEE,0x7FFF)
- u32 flags; // 标识位
- u32 table; // 路由函数表id(例如本地LOCAL,主路由MAIN...)
- u8 action; // 动作,即怎么去处理这个数据包
- u32 target;
- struct fib_rule * ctarget; // 当前规则
- struct rcu_head rcu;
- struct net * fr_net; // 网络空间结构指针
- };
struct fib_rule // 规则结构体(在初始化的时候,会注册上面的三种规则,生成默认的三张表)
{
struct list_head list; // 用来链入路由规则函数队列中(fib_rules_ops,下面介绍)
atomic_t refcnt; // 计数器
int ifindex; // 网络设备id
char ifname[IFNAMSIZ]; // 设备名称
u32 mark; // 用于过滤作用
u32 mark_mask; // 掩码
u32 pref; // 优先级(例如上面代码中分别是0,0x7FEE,0x7FFF)
u32 flags; // 标识位
u32 table; // 路由函数表id(例如本地LOCAL,主路由MAIN...)
u8 action; // 动作,即怎么去处理这个数据包
u32 target;
struct fib_rule * ctarget; // 当前规则
struct rcu_head rcu;
struct net * fr_net; // 网络空间结构指针
};
同时看一下rule的规则函数:
- struct fib_rules_ops
- {
- int family; // 协议族ID
- struct list_head list; // 用于链接到网络空间队列中
- int rule_size; // 规则结构大小
- int addr_size; // 地址大小
- int unresolved_rules;
- int nr_goto_rules;
- int (*action)(struct fib_rule *, // 动作函数指针
- struct flowi *, int,
- struct fib_lookup_arg *);
- int (*match)(struct fib_rule *, // 匹配函数指针
- struct flowi *,int);
- int (*configure)(struct fib_rule *, // 配置函数指针
- struct sk_buff *,
- struct nlmsghdr *,
- struct fib_rule_hdr *,
- struct nlattr **);
- int (*compare)(struct fib_rule *, // 对比函数指针
- struct fib_rule_hdr *,
- struct nlattr **);
- int (*fill)(struct fib_rule *, struct sk_buff *,
- struct nlmsghdr *, // 填写函数指针
- struct fib_rule_hdr *);
- u32 (*default_pref)(struct fib_rules_ops *ops); // 查找优先级函数指针
- size_t (*nlmsg_payload)(struct fib_rule *); // 统计负载数据能力函数指针
- /* Called after modifications to the rules set, must flush
- * the route cache if one exists. */
- void (*flush_cache)(void); // 修改规则之后刷新缓存函数指针
- int nlgroup; // 路由netlink组划分标识
- conststruct nla_policy *policy; // netlink属性优先级
- struct list_head rules_list; // 路由规则队列
- struct module *owner; //
- struct net *fro_net; // 网络空间结构指针
- };
struct fib_rules_ops
{
int family; // 协议族ID
struct list_head list; // 用于链接到网络空间队列中
int rule_size; // 规则结构大小
int addr_size; // 地址大小
int unresolved_rules;
int nr_goto_rules;
int (*action)(struct fib_rule *, // 动作函数指针
struct flowi *, int,
struct fib_lookup_arg *);
int (*match)(struct fib_rule *, // 匹配函数指针
struct flowi *, int);
int (*configure)(struct fib_rule *, // 配置函数指针
struct sk_buff *,
struct nlmsghdr *,
struct fib_rule_hdr *,
struct nlattr **);
int (*compare)(struct fib_rule *, // 对比函数指针
struct fib_rule_hdr *,
struct nlattr **);
int (*fill)(struct fib_rule *, struct sk_buff *,
struct nlmsghdr *, // 填写函数指针
struct fib_rule_hdr *);
u32 (*default_pref)(struct fib_rules_ops *ops); // 查找优先级函数指针
size_t (*nlmsg_payload)(struct fib_rule *); // 统计负载数据能力函数指针
/* Called after modifications to the rules set, must flush
* the route cache if one exists. */
void (*flush_cache)(void); // 修改规则之后刷新缓存函数指针
int nlgroup; // 路由netlink组划分标识
const struct nla_policy *policy; // netlink属性优先级
struct list_head rules_list; // 路由规则队列
struct module *owner; //
struct net *fro_net; // 网络空间结构指针
};
现在我们从宏观上应该有一个认识,当我们进入策略查找的时候,根据优先级,分别查找本地路由表->主路由表->默认路由表。
OK,我们需要看一下结构直接的关系:

ok,我们由规则找到了我们需要的三张表,三张表按照优先级的顺序进行查询,现在就以Local表为例进行下面具体的查询,看下图:

从图中我们可以看到四个等级查询:fib_table ---> fn_zone ---> fib_node ---> fib_info
> fib_table结构后面紧接着就是fn_hash数组,里面是33个数组元素,fn_hash[0]代表网关,fn_hash[1]代表子网掩码长度为一的情况... 为什么需要这样划分,因为我们知道,在匹配地址的时候遵循最长掩码优先原则,所以,精确度递减。 同时注意fn_zone_list指向第一个活动的路由区,将所有的路由区都链接在一起,从而提高查找的效率。fn_zone结构中最重要的就是fz_hash域了,它指向了一个hash table,这个hash table组织了这个区域下的所有路由项。( 一个fn_zone其实就是所有掩码长度相等的路由聚集在一起... )
> fn_zone路由区通过再次计算hash值,可以获得和自己相关的fib_node节点,fib_node节点是所有的子网相等的路由聚集在一起。
fn_key子网地址,也就是hash查找的关键字;fn_type表示路由类型,即到底要怎处理数据,例如:单播转发,本地,丢弃,NAT等等对于大多数情况,路由项都是单播转发类型的;fn_info就是保存下一跳的信息,它指向一个fib_info结构。
> 需要注意的是,一个fib_node对应着很多fib_info,因为即使是子网相等,也不一定是相等的路由,还有很多其他的因素。fib_info结构被组织成一个双向链表,表头为fib_info_list。下一跳的具体信息是fib_nh[]数组,它表示一个下一跳动作可以对应着多个物理的下一跳,这是linux支持的一个MULITPATH功能。
说到这来,大致的印象应该是有的,下面需要做的就是深入代码细节。
待续... 后面会介绍相关的代码...
事 实上e1000_open()函数调用了e1000_setup_rx_resources()函数为其环形缓冲区分配资源。e1000设备的接收方式是 一种缓冲方式,能显著的降低CPU接收数据造成的花费,接收数据之前,软件需要预先分配一个 DMA 缓冲区,一般对于传输而言,缓冲区最大为 8Kbyte 并且把物理地址链接在描述符的 DMA 地址描述单元,另外还有两个双字的单元表示对应的 DMA 缓冲区的接收状态。















 269
269

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









