本篇主要包括三个部分:
1.浏览器怎么工作?
2.特别的,浏览器内核引擎如何工作?
3.怎么优化?
简介
浏览器可以被认为是使用最广泛的软件,本文将介绍浏览器的工 作原理,我们将看到,从你在地址栏输入google.com到你看到google主页过程中都发生了什么。
将讨论的浏览器
今天,有五种主流浏览器——IE、Firefox、Safari、Chrome及Opera。
本文将基于一些开源浏览器的例子——Firefox、 Chrome及Safari,Safari是部分开源的。
根据W3C(World Wide Web Consortium 万维网联盟)的浏览器统计数据,当前(2011年5月),Firefox、Safari及Chrome的市场占有率综合已接近60%。(原文为2009年10月,数据没有太大变化)因此,可以说开源浏览器已经占据了浏览器市场的半壁江山。
浏览器的主要功能
浏览器的主要功能是将用户选择得web资源呈现出来,它需要从服务器请求资源,并将其显示在浏览器窗口中,资源的格式通常是HTML,也包括PDF、image及其他格式。用户用URI(Uniform Resource Identifier 统一资源标识符)来指定所请求资源的位置,在网络一章有更多讨论。
HTML和CSS规范中规定了浏览器解释html文档的方式,由 W3C组织对这些规范进行维护,W3C是负责制定web标准的组织。
HTML规范的最新版本是HTML4(http://www.w3.org/TR/html401/),HTML5还在制定中(译注:两年前),最新的CSS规范版本是2(http://www.w3.org/TR/CSS2),CSS3也还正在制定中(译注:同样两年前)。
这些年来,浏览器厂商纷纷开发自己的扩展,对规范的遵循并不完善,这为web开发者带来了严重的兼容性问题。
但是,浏览器的用户界面则差不多,常见的用户界面元素包括:
· 用来输入URI的地址栏
· 前进、后退按钮
· 书签选项
· 用于刷新及暂停当前加载文档的刷新、暂停按钮
· 用于到达主页的主页按钮
奇怪的是,并没有哪个正式公布的规范对用户界面做出规定,这些是多年来各浏览器厂商之间相互模仿和不断改进得结果。
HTML5并没有规定浏览器必须具有的UI元素,但列出了一些常用元素,包括地址栏、状态栏及工具栏。还有一些浏览器有自己专有得功能,比如Firefox得下载管理。更多相关内容将在后面讨论用户界面时介绍。
浏览器的主要构成High Level Structure
浏览器的主要组件包括:
1. 用户界面- 包括地址栏、后退/前进按钮、书签目录等,也就是你所看到的除了用来显示你所请求页面的主窗口之外的其他部分
2. 浏览器引擎- 用来查询及操作渲染引擎的接口
3. 渲染引擎- 用来显示请求的内容,例如,如果请求内容为html,它负责解析html及css,并将解析后的结果显示出来
4. 网络- 用来完成网络调用,例如http请求,它具有平台无关的接口,可以在不同平台上工作
5. UI 后端- 用来绘制类似组合选择框及对话框等基本组件,具有不特定于某个平台的通用接口,底层使用操作系统的用户接口
6. JS解释器- 用来解释执行JS代码
7. 数据存储- 属于持久层,浏览器需要在硬盘中保存类似cookie的各种数据,HTML5定义了web database技术,这是一种轻量级完整的客户端存储技术
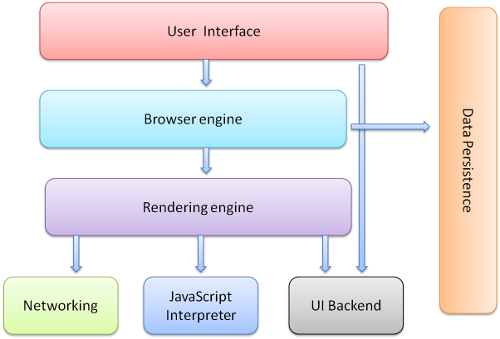
图1:浏览器主要组件
需要注意的是,不同于大部分浏览器,Chrome为每个Tab分配了各自的渲染引擎实例,每个Tab就是一个独立的进程。
对于构成浏览器的这些组件,后面会逐一详细讨论。
组件间的通信 Communication between the components
Firefox和Chrome都开发了一个特殊的通信结构,后面将有专门的一章进行讨论。
渲染引擎 The rendering engine
渲染引擎的职责就是渲染,即在浏览器窗口中显示所请求的内容。
默认情况下,渲染引擎可以显示html、xml文档及图片,它也可以借助插件(一种浏览器扩展)显示其他类型数据,例如使用PDF阅读器插件,可以显示PDF格式,将由专门一章讲解插件及扩展,这里只讨论渲染引擎最主要的用途——显示应用了CSS之后的html及图片。
渲染引擎 Rendering engines
本文所讨论得浏览器——Firefox、Chrome和Safari是基于两种渲染引擎构建的,Firefox使用Geoko——Mozilla自主研发的渲染引擎,Safari和Chrome都使用webkit。
Webkit是一款开源渲染引擎,它本来是为linux平台研发的,后来由Apple移植到Mac及Windows上,相关内容请参考http://webkit.org。
主流程 The main flow
渲染引擎首先通过网络获得所请求文档的内容,通常以8K分块的方式完成。
下面是渲染引擎在取得内容之后的基本流程:
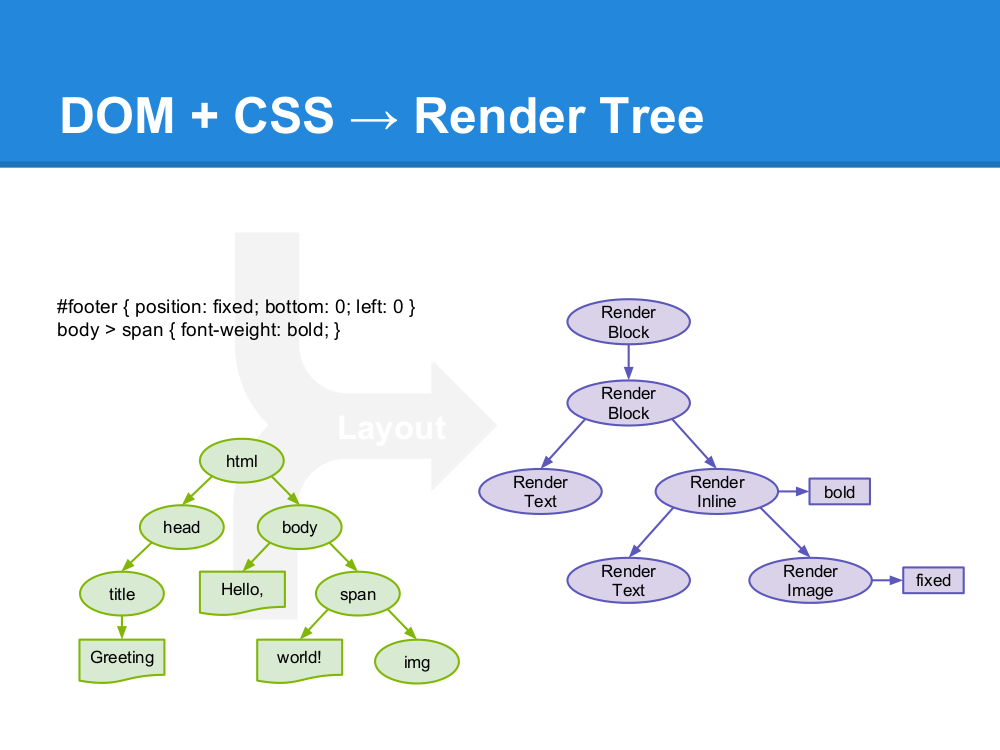
解析html以构建dom树->构建render树->布局render树->绘制render树

图2:渲染引擎基本流程
渲染引擎开始解析html,并将标签转化为内容树中的dom节点。接着,它解析外部CSS文件及style标签中的样式信息。这些样式信息以及html中的可见性指令将被用来构建另一棵树——render树。
Render树由一些包含有颜色和大小等属性的矩形组成,它们将被按照正确的顺序显示到屏幕上。
Render树构建好了之后,将会执行布局过程,它将确定每个节点在屏幕上的确切坐标。再下一步就是绘制,即遍历render树,并使用UI后端层绘制每个节点。
值得注意的是,这个过程是逐步完成的,为了更好的用户体验,渲染引擎将会尽可能早的将内容呈现到屏幕上,并不会等到所有的html都解析完成之后再去构建和布局render树。它是解析完一部分内容就显示一部分内容,同时,可能还在通过网络下载其余内容。
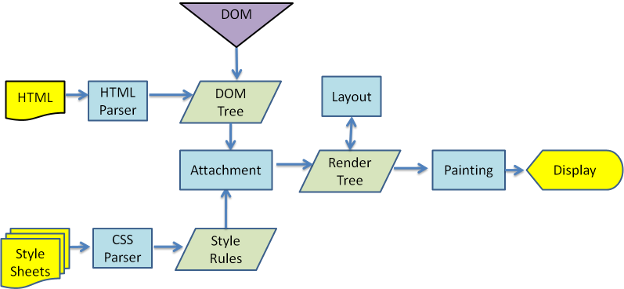
图3:webkit主流程
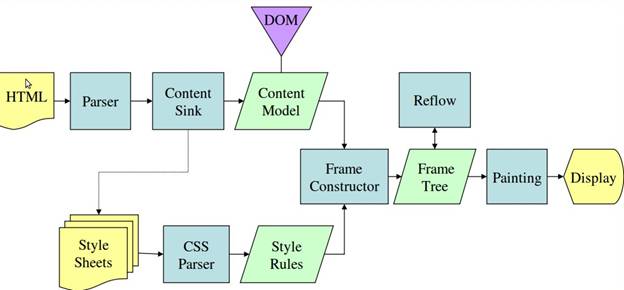
图4:Mozilla的Geoko 渲染引擎主流程
从图3和4中可以看出,尽管webkit和Gecko使用的术语稍有不同,他们的主要流程基本相同。Gecko称可见的格式化元素组成的树为frame树,每个元素都是一个frame,webkit则使用render树这个名词来命名由渲染对象组成的树。Webkit中元素的定位称为布局,而Gecko中称为回流。Webkit称利用dom节点及样式信息去构建render树的过程为attachment,Gecko在html和dom树之间附加了一层,这层称为内容接收器,相当制造dom元素的工厂。下面将讨论流程中的各个阶段。
解析 Parsing-general
既然解析是渲染引擎中一个非常重要的过程,我们将稍微深入的研究它。首先简要介绍一下解析。
解析一个文档即将其转换为具有一定意义的结构——编码可以理解和使用的东西。解析的结果通常是表达文档结构的节点树,称为解析树或语法树。
例如,解析“2+3-1”这个表达式,可能返回这样一棵树。
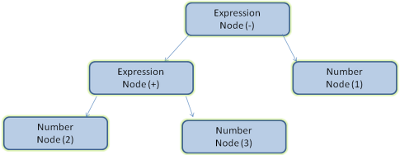
图5:数学表达式树节点
文法 Grammars
解析基于文档依据的语法规则——文档的语言或格式。每种可被解析的格式必须具有由词汇及语法规则组成的特定的文法,称为上下文无关文法。人类语言不具有这一特性,因此不能被一般的解析技术所解析。
解析器-词法分析器 Parser-Lexer combination
解析可以分为两个子过程——语法分析及词法分析
词法分析就是将输入分解为符号,符号是语言的词汇表——基本有效单元的集合。对于人类语言来说,它相当于我们字典中出现的所有单词。
语法分析指对语言应用语法规则。
解析器一般将工作分配给两个组件——词法分析器(有时也叫分词器)负责将输入分解为合法的符号,解析器则根据语言的语法规则分析文档结构,从而构建解析树,词法分析器知道怎么跳过空白和换行之类的无关字符。
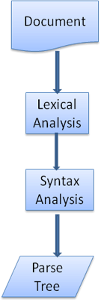
图6:从源文档到解析树
解析过程是迭代的,解析器从词法分析器处取道一个新的符号,并试着用这个符号匹配一条语法规则,如果匹配了一条规则,这个符号对应的节点将被添加到解析树上,然后解析器请求另一个符号。如果没有匹配到规则,解析器将在内部保存该符号,并从词法分析器取下一个符号,直到所有内部保存的符号能够匹配一项语法规则。如果最终没有找到匹配的规则,解析器将抛出一个异常,这意味着文档无效或是包含语法错误。
转换 Translation
很多时候,解析树并不是最终结果。解析一般在转换中使用——将输入文档转换为另一种格式。编译就是个例子,编译器在将一段源码编译为机器码的时候,先将源码解析为解析树,然后将该树转换为一个机器码文档。
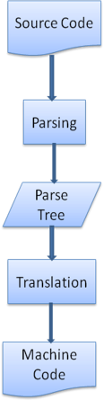
图7:编译流程
解析实例 Parsing example
图5中,我们从一个数学表达式构建了一个解析树,这里定义一个简单的数学语言来看下解析过程。
词汇表:我们的语言包括整数、加号及减号。
语法:
1. 该语言的语法基本单元包括表达式、term及操作符
2. 该语言可以包括多个表达式
3. 一个表达式定义为两个term通过一个操作符连接
4. 操作符可以是加号或减号
5. term可以是一个整数或一个表达式
现在来分析一下“2+3-1”这个输入
第一个匹配规则的子字符串是“2”,根据规则5,它是一个term,第二个匹配的是“2+3”,它符合第2条规则——一个操作符连接两个term,下一次匹配发生在输入的结束处。“2+3-1”是一个表达式,因为我们已经知道“2+3”是一个term,所以我们有了一个term紧跟着一个操作符及另一个term。“2++”将不会匹配任何规则,因此是一个无效输入。
词汇表及语法的定义
词汇表通常利用正则表达式来定义。
例如上面的语言可以定义为:
INTEGER:0|[1-9][0-9]*
PLUS:+
MINUS:-
正如看到的,这里用正则表达式定义整数。
语法通常用BNF格式定义,我们的语言可以定义为:
expression := term operation term
operation := PLUS | MINUS
term := INTEGER | expression
如果一个语言的文法是上下文无关的,则它可以用正则解析器来解析。对上下文无关文法的一个直观的定义是,该文法可以用BNF来完整的表达。可查看http://en.wikipedia.org/wiki/Context-free_grammar。
解析器类型 Types of parsers
有两种基本的解析器——自顶向下解析及自底向上解析。比较直观的解释是,自顶向下解析,查看语法的最高层结构并试着匹配其中一个;自底向上解析则从输入开始,逐步将其转换为语法规则,从底层规则开始直到匹配高层规则。
来看一下这两种解析器如何解析上面的例子:
自顶向下解析器从最高层规则开始——它先识别出“2+3“,将其视为一个表达式,然后识别出”2+3-1“为一个表达式(识别表达式的过程中匹配了其他规则,但出发点是最高层规则)。
自底向上解析会扫描输入直到匹配了一条规则,然后用该规则取代匹配的输入,直到解析完所有输入。部分匹配的表达式被放置在解析堆栈中。
| Stack | Input |
| | 2 + 3 – 1 |
| term | + 3 - 1 |
| term operation | 3 – 1 |
| expression | - 1 |
| expression operation | 1 |
| expression | |
自底向上解析器称为shift reduce 解析器,因为输入向右移动(想象一个指针首先指向输入开始处,并向右移动),并逐渐简化为语法规则。
自动化解析 Generating parsers automatically
解析器生成器这个工具可以自动生成解析器,只需要指定语言的文法——词汇表及语法规则,它就可以生成一个解析器。创建一个解析器需要对解析有深入的理解,而且手动的创建一个由较好性能的解析器并不容易,所以解析生成器很有用。Webkit使用两个知名的解析生成器——用于创建语法分析器的Flex及创建解析器的Bison(你可能接触过Lex和Yacc)。Flex的输入是一个包含了符号定义的正则表达式,Bison的输入是用BNF格式表示的语法规则。
HTML解析器 HTML Parser
HTML解析器的工作是将html标识解析为解析树。
HTML文法定义 The HTML grammar definition
W3C组织制定规范定义了HTML的词汇表和语法。
非上下文无关文法 Not a context free grammar
正如在解析简介中提到的,上下文无关文法的语法可以用类似BNF的格式来定义。
不幸的是,所有的传统解析方式都不适用于html(当然我提出它们并不只是因为好玩,它们将用来解析css和js),html不能简单的用解析所需的上下文无关文法来定义。
Html 有一个正式的格式定义——DTD(Document Type Definition 文档类型定义)——但它并不是上下文无关文法,html更接近于xml,现在有很多可用的xml解析器,html有个xml的变体——xhtml,它们间的不同在于,html更宽容,它允许忽略一些特定标签,有时可以省略开始或结束标签。总的来说,它是一种soft语法,不像xml呆板、固执。
显然,这个看起来很小的差异却带来了很大的不同。一方面,这是html流行的原因——它的宽容使web开发人员的工作更加轻松,但另一方面,这也使很难去写一个格式化的文法。所以,html的解析并不简单,它既不能用传统的解析器解析,也不能用xml解析器解析。
HTML DTD
Html适用DTD格式进行定义,这一格式是用于定义SGML家族的语言,包括了对所有允许元素及它们的属性和层次关系的定义。正如前面提到的,html DTD并没有生成一种上下文无关文法。
DTD有一些变种,标准模式只遵守规范,而其他模式则包含了对浏览器过去所使用标签的支持,这么做是为了兼容以前内容。最新的标准DTD在http://www.w3.org/TR/html4/strict.dtd
DOM
输出的树,也就是解析树,是由DOM元素及属性节点组成的。DOM是文档对象模型的缩写,它是html文档的对象表示,作为html元素的外部接口供js等调用。
树的根是“document”对象。
DOM和标签基本是一一对应的关系,例如,如下的标签:
<html>
<body>
<p>
Hello DOM
</p>
<div><img src=”example.png” /></div>
</body>
</html>
将会被转换为下面的DOM树:
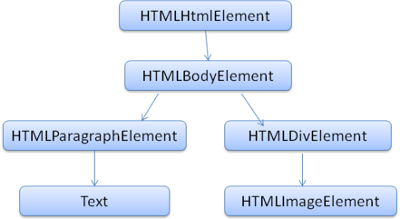
图8:示例标签对应的DOM树
和html一样,DOM的规范也是由W3C组织制定的。访问http://www.w3.org/DOM/DOMTR,这是使用文档的一般规范。一个模型描述一种特定的html元素,可以在http://www.w3.org/TR/2003/REC-DOM-Level-2-HTML-20030109/idl-definitions.htm 查看html定义。
这里所谓的树包含了DOM节点是说树是由实现了DOM接口的元素构建而成的,浏览器使用已被浏览器内部使用的其他属性的具体实现。
解析算法 The parsing algorithm
正如前面章节中讨论的,hmtl不能被一般的自顶向下或自底向上的解析器所解析。
原因是:
1. 这门语言本身的宽容特性
2. 浏览器对一些常见的非法html有容错机制
3. 解析过程是往复的,通常源码不会在解析过程中发生改变,但在html中,脚本标签包含的“document.write ”可能添加标签,这说明在解析过程中实际上修改了输入
不能使用正则解析技术,浏览器为html定制了专属的解析器。
Html5规范中描述了这个解析算法,算法包括两个阶段——符号化及构建树。
符号化是词法分析的过程,将输入解析为符号,html的符号包括开始标签、结束标签、属性名及属性值。
符号识别器识别出符号后,将其传递给树构建器,并读取下一个字符,以识别下一个符号,这样直到处理完所有输入。
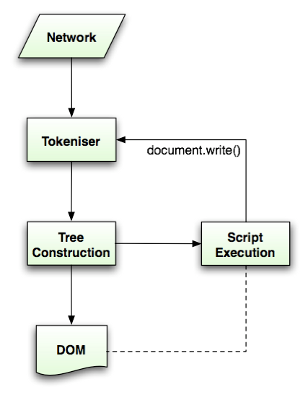
图9:HTML解析流程
符号识别算法 The tokenization algorithm
算法输出html符号,该算法用状态机表示。每次读取输入流中的一个或多个字符,并根据这些字符转移到下一个状态,当前的符号状态及构建树状态共同影响结果,这意味着,读取同样的字符,可能因为当前状态的不同,得到不同的结果以进入下一个正确的状态。
这个算法很复杂,这里用一个简单的例子来解释这个原理。
基本示例——符号化下面的html:
<html>
<body>
Hello world
</body>
</html>
初始状态为“Data State”,当遇到“<”字符,状态变为“Tag open state”,读取一个a-z的字符将产生一个开始标签符号,状态相应变为“Tag name state”,一直保持这个状态直到读取到“>”,每个字符都附加到这个符号名上,例子中创建的是一个html符号。
当读取到“>”,当前的符号就完成了,此时,状态回到“Data state”,“<body>”重复这一处理过程。到这里,html和body标签都识别出来了。现在,回到“Data state”,读取“Hello world”中的字符“H”将创建并识别出一个字符符号,这里会为“Hello world”中的每个字符生成一个字符符号。
这样直到遇到“</body>”中的“<”。现在,又回到了“Tag open state”,读取下一个字符“/”将创建一个闭合标签符号,并且状态转移到“Tag name state”,还是保持这一状态,直到遇到“>”。然后,产生一个新的标签符号并回到“Data state”。后面的“</html>”将和“</body>”一样处理。
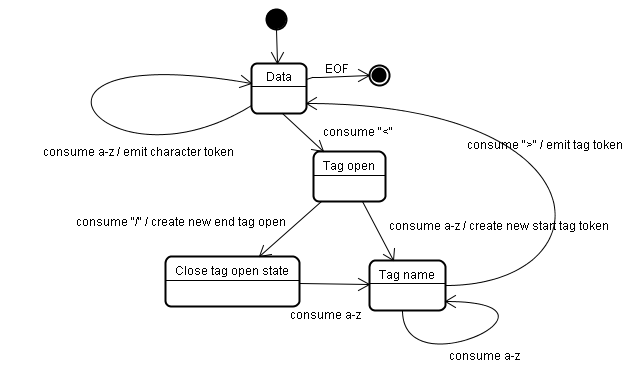
图10:符号化示例输入
树的构建算法 Tree construction algorithm
在树的构建阶段,将修改以Document为根的DOM树,将元素附加到树上。每个由符号识别器识别生成的节点将会被树构造器进行处理,规范中定义了每个符号相对应的Dom元素,对应的Dom元素将会被创建。这些元素除了会被添加到Dom树上,还将被添加到开放元素堆栈中。这个堆栈用来纠正嵌套的未匹配和未闭合标签,这个算法也是用状态机来描述,所有的状态采用插入模式。
来看一下示例中树的创建过程:
<html>
<body>
Hello world
</body>
</html>
构建树这一阶段的输入是符号识别阶段生成的符号序列。
首先是“initial mode”,接收到html符号后将转换为“before html”模式,在这个模式中对这个符号进行再处理。此时,创建了一个HTMLHtmlElement元素,并将其附加到根Document对象上。
状态此时变为“before head”,接收到body符号时,即使这里没有head符号,也将自动创建一个HTMLHeadElement元素并附加到树上。
现在,转到“in head”模式,然后是“after head”。到这里,body符号会被再次处理,将创建一个HTMLBodyElement并插入到树中,同时,转移到“in body”模式。
然后,接收到字符串“Hello world”的字符符号,第一个字符将导致创建并插入一个text节点,其他字符将附加到该节点。
接收到body结束符号时,转移到“after body”模式,接着接收到html结束符号,这个符号意味着转移到了“after after body”模式,当接收到文件结束符时,整个解析过程结束。

图11:示例html树的构建过程
解析结束时的处理 Action when the parsing is finished
在这个阶段,浏览器将文档标记为可交互的,并开始解析处于延时模式中的脚本——这些脚本在文档解析后执行。
文档状态将被设置为完成,同时触发一个load事件。
Html5规范中有符号化及构建树的完整算法(http://www.w3.org/TR/html5/syntax.html#html-parser)。
浏览器容错 Browsers error tolerance
你从来不会在一个html页面上看到“无效语法”这样的错误,浏览器修复了无效内容并继续工作。
以下面这段html为例:
<html>
<mytag>
</mytag>
<div>
<p>
</div>
Really lousy HTML
</p>
</html>
这段html违反了很多规则(mytag不是合法的标签,p及div错误的嵌套等等),但是浏览器仍然可以没有任何怨言的继续显示,它在解析的过程中修复了html作者的错误。
浏览器都具有错误处理的能力,但是,另人惊讶的是,这并不是html最新规范的内容,就像书签及前进后退按钮一样,它只是浏览器长期发展的结果。一些比较知名的非法html结构,在许多站点中出现过,浏览器都试着以一种和其他浏览器一致的方式去修复。
Html5规范定义了这方面的需求,webkit在html解析类开始部分的注释中做了很好的总结。
解析器将符号化的输入解析为文档并创建文档,但不幸的是,我们必须处理很多没有很好格式化的html文档,至少要小心下面几种错误情况。
1. 在未闭合的标签中添加明确禁止的元素。这种情况下,应该先将前一标签闭合
2. 不能直接添加元素。有些人在写文档的时候会忘了中间一些标签(或者中间标签是可选的),比如HTML HEAD BODY TR TD LI等
3. 想在一个行内元素中添加块状元素。关闭所有的行内元素,直到下一个更高的块状元素
4. 如果这些都不行,就闭合当前标签直到可以添加该元素。
下面来看一些webkit容错的例子:
</br>替代<br>
一些网站使用</br>替代<br>,为了兼容IE和Firefox,webkit将其看作<br>。
代码:
if (t->isCloseTag(brTag) && m_document->inCompatMode()) {
reportError(MalformedBRError);
t->beginTag = true;
}
Note-这里的错误处理在内部进行,用户看不到。
迷路的表格
这指一个表格嵌套在另一个表格中,但不在它的某个单元格内。
比如下面这个例子:
<table>
<table>
<tr><td>inner table</td></tr>
</table>
<tr><td>outer table</td></tr>
</table>
webkit将会将嵌套的表格变为两个兄弟表格:
<table>
<tr><td>outer table</td></tr>
</table>
<table>
<tr><td>inner table</td></tr>
</table>
代码:
if (m_inStrayTableContent && localName == tableTag)
popBlock(tableTag);
webkit使用堆栈存放当前的元素内容,它将从外部表格的堆栈中弹出内部的表格,则它们变为了兄弟表格。
嵌套的表单元素
用户将一个表单嵌套到另一个表单中,则第二个表单将被忽略。
代码:
if (!m_currentFormElement) {
m_currentFormElement = new HTMLFormElement(formTag, m_document);
}
太深的标签继承
www.liceo.edu.mx是一个由嵌套层次的站点的例子,最多只允许20个相同类型的标签嵌套,多出来的将被忽略。
代码:
bool HTMLParser::allowNestedRedundantTag(const AtomicString& tagName)
{
unsigned i = 0;
for (HTMLStackElem* curr = m_blockStack;
i < cMaxRedundantTagDepth && curr && curr->tagName == tagName;
curr = curr->next, i++) { }
return i != cMaxRedundantTagDepth;
}
放错了地方的html、body闭合标签
又一次不言自明。
支持不完整的html。我们从来不闭合body,因为一些愚蠢的网页总是在还未真正结束时就闭合它。我们依赖调用end方法去执行关闭的处理。
代码:
if (t->tagName == htmlTag || t->tagName == bodyTag )
return;
所以,web开发者要小心了,除非你想成为webkit容错代码的范例,否则还是写格式良好的html吧。
CSS解析 CSS parsing
还记得简介中提到的解析的概念吗,不同于html,css属于上下文无关文法,可以用前面所描述的解析器来解析。Css规范定义了css的词法及语法文法。
看一些例子:
每个符号都由正则表达式定义了词法文法(词汇表):
comment ///*[^*]*/*+([^/*][^*]*/*+)*//
num [0-9]+|[0-9]*"."[0-9]+
nonascii [/200-/377]
nmstart [_a-z]|{nonascii}|{escape}
nmchar [_a-z0-9-]|{nonascii}|{escape}
name {nmchar}+
ident {nmstart}{nmchar}*
“ident”是识别器的缩写,相当于一个class名,“name”是一个元素id(用“#”引用)。
语法用BNF进行描述:
ruleset
: selector [ ',' S* selector ]*
'{' S* declaration [ ';' S* declaration ]* '}' S*
;
selector
: simple_selector [ combinator selector | S+ [ combinator selector ] ]
;
simple_selector
: element_name [ HASH | class | attrib | pseudo ]*
| [ HASH | class | attrib | pseudo ]+
;
class
: '.' IDENT
;
element_name
: IDENT | '*'
;
attrib
: '[' S* IDENT S* [ [ '=' | INCLUDES | DASHMATCH ] S*
[ IDENT | STRING ] S* ] ']'
;
pseudo
: ':' [ IDENT | FUNCTION S* [IDENT S*] ')' ]
;
说明:一个规则集合有这样的结构
div.error , a.error {
color:red;
font-weight:bold;
}
div.error和a.error时选择器,大括号中的内容包含了这条规则集合中的规则,这个结构在下面的定义中正式的定义了:
ruleset
: selector [ ',' S* selector ]*
'{' S* declaration [ ';' S* declaration ]* '}' S*
;
这说明,一个规则集合具有一个或是可选个数的多个选择器,这些选择器以逗号和空格(S表示空格)进行分隔。每个规则集合包含大括号及大括号中的一条或多条以分号隔开的声明。声明和选择器在后面进行定义。
Webkit CSS 解析器 Webkit CSS parser
Webkit使用Flex和Bison解析生成器从CSS语法文件中自动生成解析器。回忆一下解析器的介绍,Bison创建一个自底向上的解析器,Firefox使用自顶向下解析器。它们都是将每个css文件解析为样式表对象,每个对象包含css规则,css规则对象包含选择器和声明对象,以及其他一些符合css语法的对象。
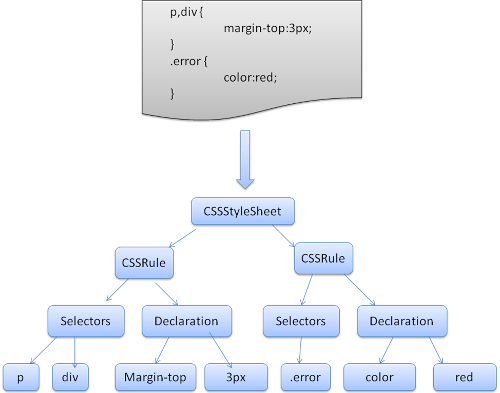
图12:解析css
脚本解析 Parsing scripts
本章将介绍Javascript。
处理脚本及样式表的顺序 The order of processing scripts and style sheets
脚本
web的模式是同步的,开发者希望解析到一个script标签时立即解析执行脚本,并阻塞文档的解析直到脚本执行完。如果脚本是外引的,则网络必须先请求到这个资源——这个过程也是同步的,会阻塞文档的解析直到资源被请求到。这个模式保持了很多年,并且在html4及html5中都特别指定了。开发者可以将脚本标识为defer,以使其不阻塞文档解析,并在文档解析结束后执行。Html5增加了标记脚本为异步的选项,以使脚本的解析执行使用另一个线程。
预解析 Speculative parsing
Webkit和Firefox都做了这个优化,当执行脚本时,另一个线程解析剩下的文档,并加载后面需要通过网络加载的资源。这种方式可以使资源并行加载从而使整体速度更快。需要注意的是,预解析并不改变Dom树,它将这个工作留给主解析过程,自己只解析外部资源的引用,比如外部脚本、样式表及图片。
样式表 Style sheets
样式表采用另一种不同的模式。理论上,既然样式表不改变Dom树,也就没有必要停下文档的解析等待它们,然而,存在一个问题,脚本可能在文档的解析过程中请求样式信息,如果样式还没有加载和解析,脚本将得到错误的值,显然这将会导致很多问题,这看起来是个边缘情况,但确实很常见。Firefox在存在样式表还在加载和解析时阻塞所有的脚本,而chrome只在当脚本试图访问某些可能被未加载的样式表所影响的特定的样式属性时才阻塞这些脚本。
渲染树的构造 Render tree construction
当Dom树构建完成时,浏览器开始构建另一棵树——渲染树。渲染树由元素显示序列中的可见元素组成,它是文档的可视化表示,构建这棵树是为了以正确的顺序绘制文档内容。
Firefox将渲染树中的元素称为frames,webkit则用renderer或渲染对象来描述这些元素。
一个渲染对象直到怎么布局及绘制自己及它的children。
RenderObject是Webkit的渲染对象基类,它的定义如下:
class RenderObject{
virtual void layout();
virtual void paint(PaintInfo);
virtual void rect repaintRect();
Node* node; //the DOM node
RenderStyle* style; // the computed style
RenderLayer* containgLayer; //the containing z-index layer
}
每个渲染对象用一个和该节点的css盒模型相对应的矩形区域来表示,正如css2所描述的那样,它包含诸如宽、高和位置之类的几何信息。盒模型的类型受该节点相关的display样式属性的影响(参考样式计算章节)。下面的webkit代码说明了如何根据display属性决定某个节点创建何种类型的渲染对象。
RenderObject* RenderObject::createObject(Node* node, RenderStyle* style)
{
Document* doc = node->document();
RenderArena* arena = doc->renderArena();
...
RenderObject* o = 0;
switch (style->display()) {
case NONE:
break;
case INLINE:
o = new (arena) RenderInline(node);
break;
case BLOCK:
o = new (arena) RenderBlock(node);
break;
case INLINE_BLOCK:
o = new (arena) RenderBlock(node);
break;
case LIST_ITEM:
o = new (arena) RenderListItem(node);
break;
...
}
return o;
}
元素的类型也需要考虑,例如,表单控件和表格带有特殊的框架。
在webkit中,如果一个元素想创建一个特殊的渲染对象,它需要复写“createRenderer”方法,使渲染对象指向不包含几何信息的样式对象。
渲染树和Dom树的关系 The render tree relation to the DOM tree
渲染对象和Dom元素相对应,但这种对应关系不是一对一的,不可见的Dom元素不会被插入渲染树,例如head元素。另外,display属性为none的元素也不会在渲染树中出现(visibility属性为hidden的元素将出现在渲染树中)。
还有一些Dom元素对应几个可见对象,它们一般是一些具有复杂结构的元素,无法用一个矩形来描述。例如,select元素有三个渲染对象——一个显示区域、一个下拉列表及一个按钮。同样,当文本因为宽度不够而折行时,新行将作为额外的渲染元素被添加。另一个多个渲染对象的例子是不规范的html,根据css规范,一个行内元素只能仅包含行内元素或仅包含块状元素,在存在混合内容时,将会创建匿名的块状渲染对象包裹住行内元素。
一些渲染对象和所对应的Dom节点不在树上相同的位置,例如,浮动和绝对定位的元素在文本流之外,在两棵树上的位置不同,渲染树上标识出真实的结构,并用一个占位结构标识出它们原来的位置。
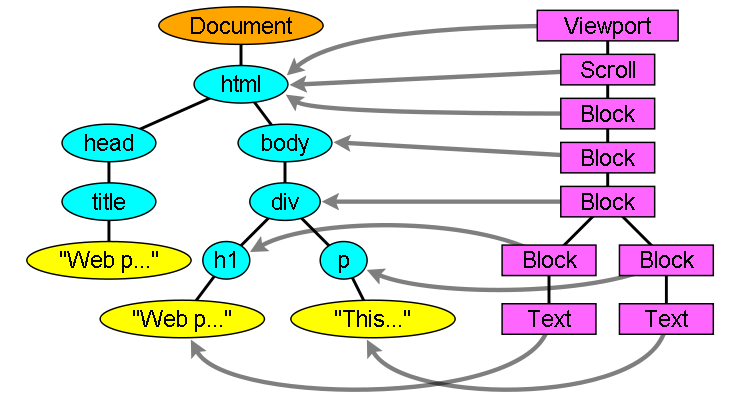
图12:渲染树及对应的Dom树
创建树的流程 The flow of constructing the tree
Firefox中,表述为一个监听Dom更新的监听器,将frame的创建委派给Frame Constructor,这个构建器计算样式(参看样式计算)并创建一个frame。
Webkit中,计算样式并生成渲染对象的过程称为attachment,每个Dom节点有一个attach方法,attachment的过程是同步的,调用新节点的attach方法将节点插入到Dom树中。
处理html和body标签将构建渲染树的根,这个根渲染对象对应被css规范称为containing block的元素——包含了其他所有块元素的顶级块元素。它的大小就是viewport——浏览器窗口的显示区域,Firefox称它为viewPortFrame,webkit称为RenderView,这个就是文档所指向的渲染对象,树中其他的部分都将作为一个插入的Dom节点被创建。
样式计算 Style Computation
创建渲染树需要计算出每个渲染对象的可视属性,这可以通过计算每个元素的样式属性得到。
样式包括各种来源的样式表,行内样式元素及html中的可视化属性(例如bgcolor),可视化属性转化为css样式属性。
样式表来源于浏览器默认样式表,及页面作者和用户提供的样式表——有些样式是浏览器用户提供的(浏览器允许用户定义喜欢的样式,例如,在Firefox中,可以通过在Firefox Profile目录下放置样式表实现)。
计算样式的一些困难:
1. 样式数据是非常大的结构,保存大量的样式属性会带来内存问题
2. 如果不进行优化,找到每个元素匹配的规则会导致性能问题,为每个元素查找匹配的规则都需要遍历整个规则表,这个过程有很大的工作量。选择符可能有复杂的结构,匹配过程如果沿着一条开始看似正确,后来却被证明是无用的路径,则必须去尝试另一条路径。
例如,下面这个复杂选择符
div div div div{…}
这意味着规则应用到三个div的后代div元素,选择树上一条特定的路径去检查,这可能需要遍历节点树,最后却发现它只是两个div的后代,并不使用该规则,然后则需要沿着另一条路径去尝试
3. 应用规则涉及非常复杂的级联,它们定义了规则的层次
我们来看一下浏览器如何处理这些问题:
共享样式数据
webkit节点引用样式对象(渲染样式),某些情况下,这些对象可以被节点间共享,这些节点需要是兄弟或是表兄弟节点,并且:
1. 这些元素必须处于相同的鼠标状态(比如不能一个处于hover,而另一个不是)
2. 不能有元素具有id
3. 标签名必须匹配
4. class属性必须匹配
5. 对应的属性必须相同
6. 链接状态必须匹配
7. 焦点状态必须匹配
8. 不能有元素被属性选择器影响
9. 元素不能有行内样式属性
10. 不能有生效的兄弟选择器,webcore在任何兄弟选择器相遇时只是简单的抛出一个全局转换,并且在它们显示时使整个文档的样式共享失效,这些包括+选择器和类似:first-child和:last-child这样的选择器。
Firefox规则树 Firefox rule tree
Firefox用两个树用来简化样式计算-规则树和样式上下文树,webkit也有样式对象,但它们并没有存储在类似样式上下文树这样的树中,只是由Dom节点指向其相关的样式。
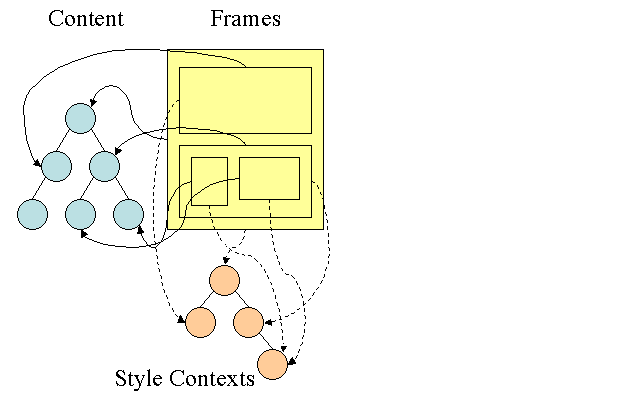
图14:Firefox样式上下文树
样式上下文包含最终值,这些值是通过以正确顺序应用所有匹配的规则,并将它们由逻辑值转换为具体的值,例如,如果逻辑值为屏幕的百分比,则通过计算将其转化为绝对单位。样式树的使用确实很巧妙,它使得在节点中共享的这些值不需要被多次计算,同时也节省了存储空间。
所有匹配的规则都存储在规则树中,一条路径中的底层节点拥有最高的优先级,这棵树包含了所找到的所有规则匹配的路径(译注:可以取巧理解为每条路径对应一个节点,路径上包含了该节点所匹配的所有规则)。规则树并不是一开始就为所有节点进行计算,而是在某个节点需要计算样式时,才进行相应的计算并将计算后的路径添加到树中。
我们将树上的路径看成辞典中的单词,假如已经计算出了如下的规则树:

假如需要为内容树中的另一个节点匹配规则,现在知道匹配的规则(以正确的顺序)为B-E-I,因为我们已经计算出了路径A-B-E-I-L,所以树上已经存在了这条路径,剩下的工作就很少了。
现在来看一下树如何保存。
结构化
样式上下文按结构划分,这些结构包括类似border或color这样的特定分类的样式信息。一个结构中的所有特性不是继承的就是非继承的,对继承的特性,除非元素自身有定义,否则就从它的parent继承。非继承的特性(称为reset特性)如果没有定义,则使用默认的值。
样式上下文树缓存完整的结构(包括计算后的值),这样,如果底层节点没有为一个结构提供定义,则使用上层节点缓存的结构。
使用规则树计算样式上下文
当为一个特定的元素计算样式时,首先计算出规则树中的一条路径,或是使用已经存在的一条,然后使用路径中的规则去填充新的样式上下文,从样式的底层节点开始,它具有最高优先级(通常是最特定的选择器),遍历规则树,直到填满结构。如果在那个规则节点没有定义所需的结构规则,则沿着路径向上,直到找到该结构规则。
如果最终没有找到该结构的任何规则定义,那么如果这个结构是继承型的,则找到其在内容树中的parent的结构,这种情况下,我们也成功的共享了结构;如果这个结构是reset型的,则使用默认的值。
如果特定的节点添加了值,那么需要做一些额外的计算以将其转换为实际值,然后在树上的节点缓存该值,使它的children可以使用。
当一个元素和它的一个兄弟元素指向同一个树节点时,完整的样式上下文可以被它们共享。
来看一个例子:假设有下面这段html
<html>
<body>
<div class="err" id="div1">
<p>this is a
<span class="big"> big error </span>
this is also a
<span class="big"> very big error</span>
error
</p>
</div>
<div class="err" id="div2">another error</div>
</body>
</html>
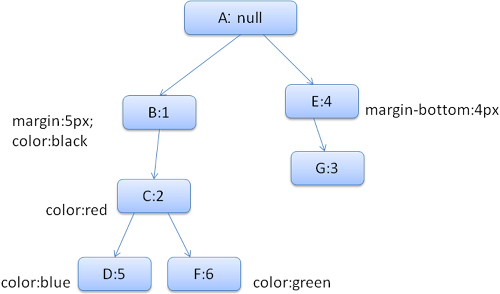
以及下面这些规则
1. div {margin:5px;color:black}
2. .err {color:red}
3. .big {margin-top:3px}
4. div span {margin-bottom:4px}
5. #div1 {color:blue}
6. #div2 {color:green}
简化下问题,我们只填充两个结构——color和margin,color结构只包含一个成员-颜色,margin结构包含四边。
生成的规则树如下(节点名:指向的规则)
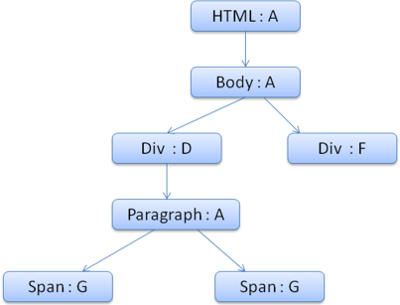
上下文树如下(节点名:指向的规则节点)
假设我们解析html,遇到第二个div标签,我们需要为这个节点创建样式上下文,并填充它的样式结构。
我们进行规则匹配,找到这个div匹配的规则为1、2、6,我们发现规则树上已经存在了一条我们可以使用的路径1、2,我们只需为规则6新增一个节点添加到下面(就是规则树中的F)。
然后创建一个样式上下文并将其放到上下文树中,新的样式上下文将指向规则树中的节点F。
现在我们需要填充这个样式上下文,先从填充margin结构开始,既然最后一个规则节点没有添加margin结构,沿着路径向上,直到找到缓存的前面插入节点计算出的结构,我们发现B是最近的指定margin值的节点。因为已经有了color结构的定义,所以不能使用缓存的结构,既然color只有一个属性,也就不需要沿着路径向上填充其他属性。计算出最终值(将字符串转换为RGB等),并缓存计算后的结构。
第二个span元素更简单,进行规则匹配后发现它指向规则G,和前一个span一样,既然有兄弟节点指向同一个节点,就可以共享完整的样式上下文,只需指向前一个span的上下文。
因为结构中包含继承自parent的规则,上下文树做了缓存(color特性是继承来的,但Firefox将其视为reset并在规则树中缓存)。
例如,如果我们为一个paragraph的文字添加规则:
p {font-family:Verdana;font size:10px;font-weight:bold}
那么这个p在内容树中的子节点div,会共享和它parent一样的font结构,这种情况发生在没有为这个div指定font规则时。
Webkit中,并没有规则树,匹配的声明会被遍历四次,先是应用非important的高优先级属性(之所以先应用这些属性,是因为其他的依赖于它们-比如display),其次是高优先级important的,接着是一般优先级非important的,最后是一般优先级important的规则。这样,出现多次的属性将被按照正确的级联顺序进行处理,最后一个生效。
总结一下,共享样式对象(结构中完整或部分内容)解决了问题1和3,Firefox的规则树帮助以正确的顺序应用规则。
对规则进行处理以简化匹配过程
样式规则有几个来源:
· 外部样式表或style标签内的css规则
· 行内样式属性
· html可视化属性(映射为相应的样式规则)
后面两个很容易匹配到元素,因为它们所拥有的样式属性和html属性可以将元素作为key进行映射。
就像前面问题2所提到的,css的规则匹配可能很狡猾,为了解决这个问题,可以先对规则进行处理,以使其更容易被访问。
解析完样式表之后,规则会根据选择符添加一些hash映射,映射可以是根据id、class、标签名或是任何不属于这些分类的综合映射。如果选择符为id,规则将被添加到id映射,如果是class,则被添加到class映射,等等。
这个处理是匹配规则更容易,不需要查看每个声明,我们能从映射中找到一个元素的相关规则,这个优化使在进行规则匹配时减少了95+%的工作量。
来看下面的样式规则:
p.error {color:red}
#messageDiv {height:50px}
div {margin:5px}
第一条规则将被插入class映射,第二条插入id映射,第三条是标签映射。
下面这个html片段:
<p class="error">an error occurred </p>
<div id=" messageDiv">this is a message</div>
我们首先找到p元素对应的规则,class映射将包含一个“error”的key,找到p.error的规则,div在id映射和标签映射中都有相关的规则,剩下的工作就是找出这些由key对应的规则中哪些确实是正确匹配的。
例如,如果div的规则是
table div {margin:5px}
这也是标签映射产生的,因为key是最右边的选择符,但它并不匹配这里的div元素,因为这里的div没有table祖先。
Webkit和Firefox都会做这个处理。
以正确的级联顺序应用规则
样式对象拥有对应所有可见属性的属性,如果特性没有被任何匹配的规则所定义,那么一些特性可以从parent的样式对象中继承,另外一些使用默认值。
这个问题的产生是因为存在不止一处的定义,这里用级联顺序解决这个问题。
样式表的级联顺序
一个样式属性的声明可能在几个样式表中出现,或是在一个样式表中出现多次,因此,应用规则的顺序至关重要,这个顺序就是级联顺序。根据css2的规范,级联顺序为(从低到高):
1. 浏览器声明
2. 用户声明
3. 作者的一般声明
4. 作者的important声明
5. 用户important声明
浏览器声明是最不重要的,用户只有在声明被标记为important时才会覆盖作者的声明。具有同等级别的声明将根据specifity以及它们被定义时的顺序进行排序。Html可视化属性将被转换为匹配的css声明,它们被视为最低优先级的作者规则。
Specifity
Css2规范中定义的选择符specifity如下:
· 如果声明来自style属性,而不是一个选择器的规则,则计1,否则计0(=a)
· 计算选择器中id属性的数量(=b)
· 计算选择器中class及伪类的数量(=c)
· 计算选择器中元素名及伪元素的数量(=d)
连接a-b-c-d四个数量(用一个大基数的计算系统)将得到specifity。这里使用的基数由分类中最高的基数定义。例如,如果a为14,可以使用16进制。不同情况下,a为17时,则需要使用阿拉伯数字17作为基数,这种情况可能在这个选择符时发生html body div div …(选择符中有17个标签,一般不太可能)。
一些例子:
* {} /* a=0 b=0 c=0 d=0 -> specificity = 0,0,0,0 */
li {} /* a=0 b=0 c=0 d=1 -> specificity = 0,0,0,1 */
li:first-line {} /* a=0 b=0 c=0 d=2 -> specificity = 0,0,0,2 */
ul li {} /* a=0 b=0 c=0 d=2 -> specificity = 0,0,0,2 */
ul ol+li {} /* a=0 b=0 c=0 d=3 -> specificity = 0,0,0,3 */
h1 + *[rel=up]{} /* a=0 b=0 c=1 d=1 -> specificity = 0,0,1,1 */
ul ol li.red {} /* a=0 b=0 c=1 d=3 -> specificity = 0,0,1,3 */
li.red.level {} /* a=0 b=0 c=2 d=1 -> specificity = 0,0,2,1 */
#x34y {} /* a=0 b=1 c=0 d=0 -> specificity = 0,1,0,0 */
style="" /* a=1 b=0 c=0 d=0 -> specificity = 1,0,0,0 */
规则排序
规则匹配后,需要根据级联顺序对规则进行排序,webkit先将小列表用冒泡排序,再将它们合并为一个大列表,webkit通过为规则复写“>”操作来执行排序:
static bool operator >(CSSRuleData& r1, CSSRuleData& r2)
{
int spec1 = r1.selector()->specificity();
int spec2 = r2.selector()->specificity();
return (spec1 == spec2) : r1.position() > r2.position() : spec1 > spec2;
}
逐步处理 Gradual process
webkit使用一个标志位标识所有顶层样式表都已加载,如果在attch时样式没有完全加载,则放置占位符,并在文档中标记,一旦样式表完成加载就重新进行计算。
布局 Layout
当渲染对象被创建并添加到树中,它们并没有位置和大小,计算这些值的过程称为layout或reflow。
Html使用基于流的布局模型,意味着大部分时间,可以以单一的途径进行几何计算。流中靠后的元素并不会影响前面元素的几何特性,所以布局可以在文档中从右向左、自上而下的进行。也存在一些例外,比如html tables。
坐标系统相对于根frame,使用top和left坐标。
布局是一个递归的过程,由根渲染对象开始,它对应html文档元素,布局继续递归的通过一些或所有的frame层级,为每个需要几何信息的渲染对象进行计算。
根渲染对象的位置是0,0,它的大小是viewport-浏览器窗口的可见部分。
所有的渲染对象都有一个layout或reflow方法,每个渲染对象调用需要布局的children的layout方法。
Dirty bit 系统
为了不因为每个小变化都全部重新布局,浏览器使用一个dirty bit系统,一个渲染对象发生了变化或是被添加了,就标记它及它的children为dirty-需要layout。存在两个标识-dirty及children are dirty,children are dirty说明即使这个渲染对象可能没问题,但它至少有一个child需要layout。
全局和增量 layout
当layout在整棵渲染树触发时,称为全局layout,这可能在下面这些情况下发生:
1. 一个全局的样式改变影响所有的渲染对象,比如字号的改变
2. 窗口resize
layout也可以是增量的,这样只有标志为dirty的渲染对象会重新布局(也将导致一些额外的布局)。增量 layout会在渲染对象dirty时异步触发,例如,当网络接收到新的内容并添加到Dom树后,新的渲染对象会添加到渲染树中。

图20:增量 layout
异步和同步layout
增量layout的过程是异步的,Firefox为增量layout生成了reflow队列,以及一个调度执行这些批处理命令。Webkit也有一个计时器用来执行增量layout-遍历树,为dirty状态的渲染对象重新布局。
另外,当脚本请求样式信息时,例如“offsetHeight”,会同步的触发增量布局。
全局的layout一般都是同步触发。
有些时候,layout会被作为一个初始layout之后的回调,比如滑动条的滑动。
优化
当一个layout因为resize或是渲染位置改变(并不是大小改变)而触发时,渲染对象的大小将会从缓存中读取,而不会重新计算。
一般情况下,如果只有子树发生改变,则layout并不从根开始。这种情况发生在,变化发生在元素自身并且不影响它周围元素,例如,将文本插入文本域(否则,每次击键都将触发从根开始的重排)。
layout过程
layout一般有下面这几个部分:
1. parent渲染对象决定它的宽度
2. parent渲染对象读取chilidren,并:
1. 放置child渲染对象(设置它的x和y)
2. 在需要时(它们当前为dirty或是处于全局layout或者其他原因)调用child渲染对象的layout,这将计算child的高度
3. parent渲染对象使用child渲染对象的累积高度,以及margin和padding的高度来设置自己的高度-这将被parent渲染对象的parent使用
4. 将dirty标识设置为false
Firefox使用一个“state”对象(nsHTMLReflowState)做为参数去布局(firefox称为reflow),state包含parent的宽度及其他内容。
Firefox布局的输出是一个“metrics”对象(nsHTMLReflowMetrics)。它包括渲染对象计算出的高度。
宽度计算
渲染对象的宽度使用容器的宽度、渲染对象样式中的宽度及margin、border进行计算。例如,下面这个div的宽度:
<div style="width:30%"/>
webkit中宽度的计算过程是(RenderBox类的calcWidth方法):
· 容器的宽度是容器的可用宽度和0中的最大值,这里的可用宽度为:contentWidth=clientWidth()-paddingLeft()-paddingRight(),clientWidth和clientHeight代表一个对象内部的不包括border和滑动条的大小
· 元素的宽度指样式属性width的值,它可以通过计算容器的百分比得到一个绝对值
· 加上水平方向上的border和padding
到这里是最佳宽度的计算过程,现在计算宽度的最大值和最小值,如果最佳宽度大于最大宽度则使用最大宽度,如果小于最小宽度则使用最小宽度。最后缓存这个值,当需要layout但宽度未改变时使用。
Line breaking
当一个渲染对象在布局过程中需要折行时,则暂停并告诉它的parent它需要折行,parent将创建额外的渲染对象并调用它们的layout。
绘制 Painting
绘制阶段,遍历渲染树并调用渲染对象的paint方法将它们的内容显示在屏幕上,绘制使用UI基础组件,这在UI的章节有更多的介绍。
全局和增量
和布局一样,绘制也可以是全局的-绘制完整的树-或增量的。在增量的绘制过程中,一些渲染对象以不影响整棵树的方式改变,改变的渲染对象使其在屏幕上的矩形区域失效,这将导致操作系统将其看作dirty区域,并产生一个paint事件,操作系统很巧妙的处理这个过程,并将多个区域合并为一个。Chrome中,这个过程更复杂些,因为渲染对象在不同的进程中,而不是在主进程中。Chrome在一定程度上模拟操作系统的行为,表现为监听事件并派发消息给渲染根,在树中查找到相关的渲染对象,重绘这个对象(往往还包括它的children)。
绘制顺序
css2定义了绘制过程的顺序-http://www.w3.org/TR/CSS21/zindex.html。这个就是元素压入堆栈的顺序,这个顺序影响着绘制,堆栈从后向前进行绘制。
一个块渲染对象的堆栈顺序是:
1. 背景色
2. 背景图
3. border
4. children
5. outline
Firefox显示列表
Firefox读取渲染树并为绘制的矩形创建一个显示列表,该列表以正确的绘制顺序包含这个矩形相关的渲染对象。
用这样的方法,可以使重绘时只需查找一次树,而不需要多次查找——绘制所有的背景、所有的图片、所有的border等等。
Firefox优化了这个过程,它不添加会被隐藏的元素,比如元素完全在其他不透明元素下面。
Webkit矩形存储
重绘前,webkit将旧的矩形保存为位图,然后只绘制新旧矩形的差集。
动态变化
浏览器总是试着以最小的动作响应一个变化,所以一个元素颜色的变化将只导致该元素的重绘,元素位置的变化将大致元素的布局和重绘,添加一个Dom节点,也会大致这个元素的布局和重绘。一些主要的变化,比如增加html元素的字号,将会导致缓存失效,从而引起整数的布局和重绘。
渲染引擎的线程
渲染引擎是单线程的,除了网络操作以外,几乎所有的事情都在单一的线程中处理,在Firefox和Safari中,这是浏览器的主线程,Chrome中这是tab的主线程。
网络操作由几个并行线程执行,并行连接的个数是受限的(通常是2-6个)。
事件循环
浏览器主线程是一个事件循环,它被设计为无限循环以保持执行过程的可用,等待事件(例如layout和paint事件)并执行它们。下面是Firefox的主要事件循环代码。
while (!mExiting)
NS_ProcessNextEvent(thread);
CSS2 可视模型 CSS2 visual module
画布 The Canvas
根据CSS2规范,术语canvas用来描述格式化的结构所渲染的空间——浏览器绘制内容的地方。画布对每个维度空间都是无限大的,但浏览器基于viewport的大小选择了一个初始宽度。
根据http://www.w3.org/TR/CSS2/zindex.html的定义,画布如果是包含在其他画布内则是透明的,否则浏览器会指定一个颜色。
CSS盒模型
CSS盒模型描述了矩形盒,这些矩形盒是为文档树中的元素生成的,并根据可视的格式化模型进行布局。每个box包括内容区域(如图片、文本等)及可选的四周padding、border和margin区域。
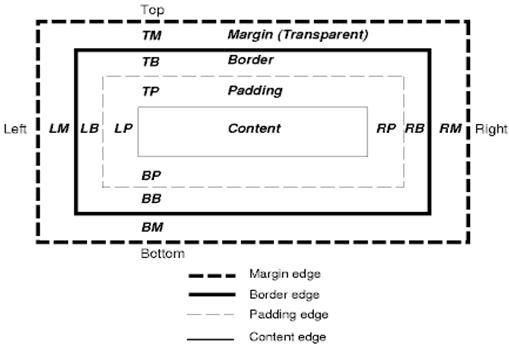
每个节点生成0-n个这样的box。
所有的元素都有一个display属性,用来决定它们生成box的类型,例如:
block-生成块状box
inline-生成一个或多个行内box
none-不生成box
默认的是inline,但浏览器样式表设置了其他默认值,例如,div元素默认为block。可以访问http://www.w3.org/TR/CSS2/sample.html查看更多的默认样式表示例。
定位策略 Position scheme
这里有三种策略:
1. normal-对象根据它在文档的中位置定位,这意味着它在渲染树和在Dom树中位置一致,并根据它的盒模型和大小进行布局
2. float-对象先像普通流一样布局,然后尽可能的向左或是向右移动
3. absolute-对象在渲染树中的位置和Dom树中位置无关
static和relative是normal,absolute和fixed属于absolute。
在static定位中,不定义位置而使用默认的位置。其他策略中,作者指定位置——top、bottom、left、right。
Box布局的方式由这几项决定:box的类型、box的大小、定位策略及扩展信息(比如图片大小和屏幕尺寸)。
Box类型
Block box:构成一个块,即在浏览器窗口上有自己的矩形
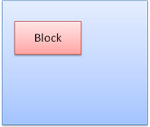
Inline box:并没有自己的块状区域,但包含在一个块状区域内

block一个挨着一个垂直格式化,inline则在水平方向上格式化。
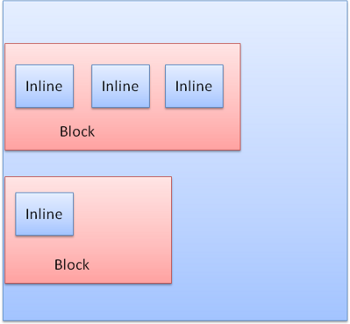
Inline盒模型放置在行内或是line box中,每行至少和最高的box一样高,当box以baseline对齐时——即一个元素的底部和另一个box上除底部以外的某点对齐,行高可以比最高的box高。当容器宽度不够时,行内元素将被放到多行中,这在一个p元素中经常发生。
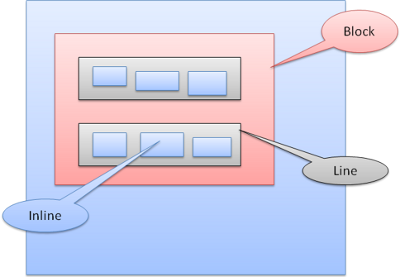
定位 Position
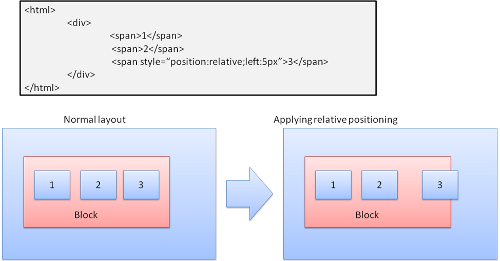
Relative
相对定位——先按照一般的定位,然后按所要求的差值移动。
Floats
一个浮动的box移动到一行的最左边或是最右边,其余的box围绕在它周围。下面这段html:
<p>
<img style="float:right" src="images/image.gif" width="100" height="100">Lorem ipsum dolor sit amet, consectetuer...
</p>
将显示为:

Absolute和Fixed
这种情况下的布局完全不顾普通的文档流,元素不属于文档流的一部分,大小取决于容器。Fixed时,容器为viewport(可视区域)。
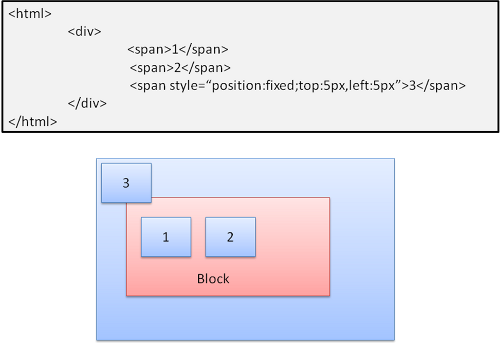
图17:fixed
注意-fixed即使在文档流滚动时也不会移动。
Layered representation
这个由CSS属性中的z-index指定,表示盒模型的第三个大小,即在z轴上的位置。Box分发到堆栈中(称为堆栈上下文),每个堆栈中靠后的元素将被较早绘制,栈顶靠前的元素离用户最近,当发生交叠时,将隐藏靠后的元素。堆栈根据z-index属性排序,拥有z-index属性的box形成了一个局部堆栈,viewport有外部堆栈,例如:
<STYLE type="text/css">
div {
position: absolute;
left: 2in;
top: 2in;
}
</STYLE>
<P>
<DIV
style="z-index: 3;background-color:red; width: 1in; height: 1in; ">
</DIV>
<DIV
style="z-index: 1;background-color:green;width: 2in; height: 2in;">
</DIV>
</p>
结果是:

虽然绿色div排在红色div后面,可能在正常流中也已经被绘制在后面,但z-index有更高优先级,所以在根box的堆栈中更靠前。
Posted by
Roger
on 2014 年 4 月 16 日
自从开始从事浏览器内核开发工作以来,已经写过不少跟渲染相关的文章。但是一直想写一篇像 How Browsers Work 类似,能够系统,完整地阐述浏览器的渲染引擎是如何工作的,它是如何对网页渲染性能进行优化的文章,却一直因为畏惧所需要花费的时间和精力,迟迟无法动笔。不管如何,现在终于鼓起勇气来写了,希望自己能够完成吧…
文章包括的主要内容如下 —
- 渲染基础 - DOM & RenderObject & RenderLayer
- WebView,绘制与混合,多线程渲染
- 硬件加速
- 分块渲染
- 图层混合加速
- 网页游戏渲染 - Canvas & WebGL
首先明确文中关于渲染的定义,浏览器内核引擎通常又被称为网页渲染引擎,但是这里的渲染实际上是一个泛指,广义的渲染,它包括了浏览器内核所有的主要工作 - 加载,解析,排版,绘制等等。而在本文里面的渲染,指的是跟绘制相关的部分,也就是浏览器是如何将排版后的结果最终显示在屏幕上的这一过程。如果读者希望先对浏览器内核引擎,特别是 WebKit 有一个大概的了解,How Browsers Work,How WebKit Work,WebKit for Developers 可以提供不错的入门指引。
其次,本文主要描述 WebKit 引擎的实现,不过因为 Blink 实际上从 WebKit 分支出来的时间并不长,两者在渲染整体架构上还是基本一致的,所以文中不会明确区分这两者。
最后,希望这篇文章能够给从事浏览器内核开发,特别是渲染引擎开发的开发者一个能够快速入门的指引,并给前端开发者优化网页渲染性能提供足够的知识和帮助。
因为文章后续还有可能会持续修订和补充,如果要查看最新的内容,请访问个人博客的原文:http://blog.csdn.net/rogeryi/article/details/23686609,如果有什么疏漏和错误,也欢迎读者来信指正(roger2yi@gmail.com)。
渲染基础 - DOM & RenderObject & RenderLayer
图片来自 GPU Accelerated Compositing in Chrome
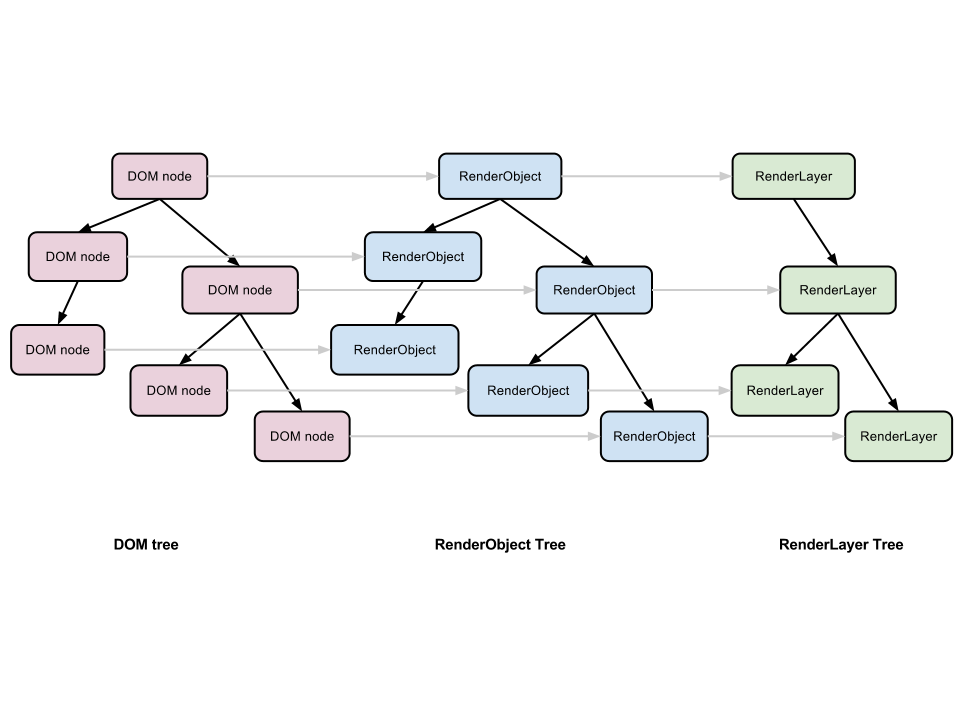
当浏览器通过网络或者本地文件系统加载一个 HTML 文件,并对它进行解析完毕后,内核就会生成它最重要的数据结构 - DOM 树。DOM 树上每一个节点都对应着网页里面的每一个元素,并且网页也可以通过 JavaScript 操作这棵 DOM 树,动态改变它的结构。但是 DOM 树本身并不能直接用于排版和渲染,内核还会生成另外一棵树 - Render 树,Render 树上的每一个节点 - RenderObject,跟 DOM 树上的节点几乎是一一对应的,当一个可见的 DOM 节点被添加到 DOM 树上时,内核就会为它生成对应的 RenderOject 添加到 Render 树上。
图片来自 How WebKit Work
Render 树是浏览器排版引擎的主要作业对象,排版引擎根据 DOM 树和 CSS 样式表的样式定义,按照预定的排版规则确定了 Render 树最后的结构,包括其中每一个 RenderObject 的大小和位置,而一棵经过排版的 Render 树,则是浏览器渲染引擎的主要输入,读者可以认为,Render 树是衔接浏览器排版引擎和渲染引擎之间的桥梁,它是排版引擎的输出,渲染引擎的输入。
图片来自 How WebKit Work
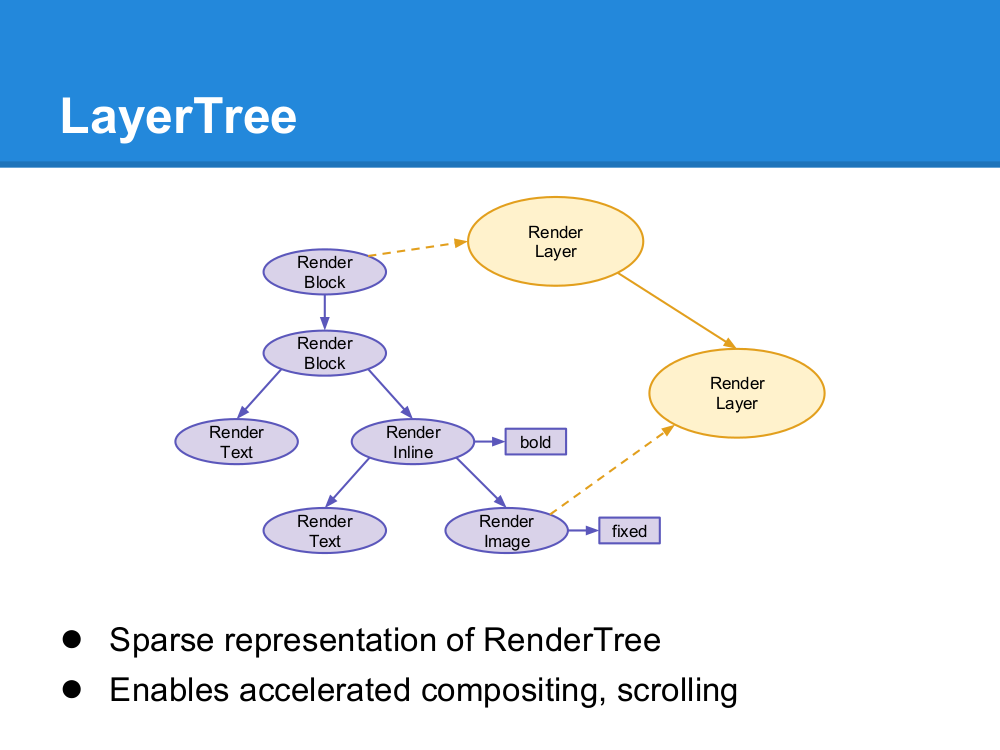
不过浏览器渲染引擎并不是直接使用 Render 树进行绘制,为了方便处理 Positioning(定位),Clipping(裁剪),Overflow-scroll(页內滚动),CSS Transform/Opacity/Animation/Filter,Mask or Reflection,Z-indexing(Z排序)等,浏览器需要生成另外一棵树 – Layer 树。渲染引擎会为一些特定的 RenderObject 生成对应的 RenderLayer,而这些特定的 RenderObject 跟对应的 RenderLayer 就是直属的关系,相应的,它们的子节点如果没有对应的 RenderLayer,就从属于父节点的 RenderLayer。最终,每一个 RenderObject 都会直接或者间接地从属于一个 RenderLayer。
RenderObject 生成 RenderLayer 的条件,来自 GPU Accelerated Compositing in Chrome – It’s the root object for the page – It has explicit CSS position properties (relative, absolute or a transform) – It is transparent – Has overflow, an alpha mask or reflection
– Has a CSS filter – Corresponds to < canvas> element that has a 3D (WebGL) context or an accelerated 2D context – Corresponds to a < video> element
浏览器渲染引擎遍历 Layer 树,访问每一个 RenderLayer,再遍历从属于这个 RenderLayer 的 RenderObject,将每一个 RenderObject 绘制出来。读者可以认为,Layer 树决定了网页绘制的层次顺序,而从属于 RenderLayer 的 RenderObject 决定了这个 Layer 的内容,所有的 RenderLayer 和 RenderObject 一起就决定了网页在屏幕上最终呈现出来的内容。
软件渲染模式下,浏览器绘制 RenderLayer 和 RenderObject 的顺序,来自 GPU Accelerated Compositing in Chrome
In the software path, the page is rendered by sequentially painting all the RenderLayers, from back to front. The RenderLayer hierarchy is traversed recursively starting from the root and the bulk of the work is done in RenderLayer::paintLayer() which performs the following basic steps (the list of steps is simplified here for clarity):
- Determines whether the layer intersects the damage rect for an early out.
- Recursively paints the layers below this one by calling paintLayer() for the layers in the negZOrderList.
- Asks RenderObjects associated with this RenderLayer to paint themselves.
- This is done by recursing down the RenderObject tree starting with the RenderObject which created the layer. Traversal stops whenever a RenderObject associated with a different RenderLayer is found.
- Recursively paints the layers above this one by calling paintLayer() for the layers in the posZOrderList.
In this mode RenderObjects paint themselves into the destination bitmap by issuing draw calls into a single shared GraphicsContext (implemented in Chrome via Skia).
WebView,绘制与混合,多线程渲染
图片来自 [UC 浏览器 9.7 Android版],中间是一个 WebView,上方是标题栏和工具栏
浏览器本身并不能直接改变屏幕的像素输出,它需要通过系统本身的 GUI Toolkit。所以,一般来说浏览器会将一个要显示的网页包装成一个 UI 组件,通常叫做 WebView,然后通过将 WebView 放置于应用的 UI 界面上,从而将网页显示在屏幕上。
一些 GUI Toolkit,比如 Android,默认的情况下 UI 组件没有自己独立的位图缓存,构成 UI 界面的所有 UI 组件都直接绘制在当前的窗口缓存上,所以 WebView 每次绘制,就相当于将它在可见区域内的 RenderLayer/RenderObject 逐个绘制到窗口缓存上。上述的渲染方式有一个很严重的问题,用户拖动网页或者触发一个惯性滚动时,网页滑动的渲染性能会十分糟糕。这是因为即使网页只移动一个像素,整个 WebView 都需要重新绘制,而要绘制一个 WebView 大小的区域的 RenderLayer/RenderObject,耗时通常都比较长,对于一些复杂的桌面版网页,在移动设备上绘制一次的耗时有可能需要上百毫秒,而要达到60帧/每秒的流畅度,每一帧绘制的时间就不能超过16.7毫秒,所以在这种渲染模式下,要获得流畅的网页滑屏效果,显然是不可能的,而网页滑屏的流畅程度,又是用户对浏览器渲染性能的最直观和最重要的感受。
要提升网页滑屏的性能,一个简单的做法就是让 WebView 本身持有一块独立的缓存,而 WebView 的绘制就分成了两步 1) 根据需要更新内部缓存,将网页内容绘制到内部缓存里面 2) 将内部缓存拷贝到窗口缓存上。第一步我们通常称为绘制(Paint)或者光栅化(Rasterization),它将一些绘图指令转换成真正的像素颜色值,而第二步我们一般称为混合(Composite),它负责缓存的拷贝,同时还可能包括位移(Translation),缩放(Scale),旋转(Rotation),Alpha 混合等操作。咋一看,渲染变得比原来更复杂,还多了一步操作,但实际上,混合的耗时通常远远小于网页内容绘制的耗时,后者即使在移动设备上一般也就在几个毫秒以内,而大部分时候,在第一步里面,我们只需要绘制一块很小的区域而不需要绘制一个完整 WebView 大小的区域,这样就有效地减少了绘制这一步的开销。以网页滚动为例子,每次滚动实际上只需要绘制新进入 WebView 可见区域的部分,如果向上滚动了10个像素,我们需要绘制的区域大小就是10 x Width of WebView,比起原来需要绘制整个 WebView 大小区域的网页内容当然要快的多了。
进一步来说,浏览器还可以使用多线程的渲染架构,将网页内容绘制到缓存的操作放到另外一个独立的线程(绘制线程),而原来线程对 WebView 的绘制就只剩下缓存的拷贝(混合线程),绘制线程跟混合线程之间可以使用同步,部分同步,完全异步等作业模式,让浏览器可以在性能与效果之间根据需要进行选择,比如说异步模式下,当浏览器需要将 WebView 缓存拷贝到窗口缓存,但是需要更新的部分还没有来得及绘制时,浏览器可以在还未及时更新的部分绘制一个背景色或者空白,这样虽然渲染效果有所下降,但是保证了每一帧窗口更新的间隔都在理想的范围内。并且浏览器还可以为 WebView 创建一个更大的缓存,超过 WebView本身的大小,让我们可以缓存更多的网页内容,可以预先绘制不可见的区域,这样就可以有效减少异步模式下出现空白的状况,在性能和效果之间取得更好的平衡。
硬件加速
上述的渲染模式,无论是绘制还是混合,都是由 CPU 完成的,而没有使用到 GPU。绘制任务比较复杂,较难使用 GPU 来完成,并且对于各种复杂的图形/文本的绘制来说,使用 GPU 效率有时反而更低(并且系统资源的开销也较大),但是混合就不一样了,GPU 最擅长的就是并行处理多个像素的计算,所以 GPU 相对于 CPU,执行混合的速度要快的多,特别是存在缩放,旋转,Alpha 混合的时候,而且混合相对来说也比较简单,改成使用 GPU 来完成并不困难。
并且在多线程渲染模式下,因为绘制和混合分别处于不同的线程,绘制使用 CPU,混合使用 GPU,这样可以通过 CPU/GPU 之间的并发运行有效地提升浏览器整体的渲染性能。更何况,窗口的更新是由混合线程来负责的,混合的效率越高,窗口更新的间隔就越短,用户感受到 UI 界面变化的流畅度就越高,只要窗口更新的间隔能够始终保持在16.7毫秒以内,UI 界面就能够一直保持60帧/每秒的极致流畅度(因为一般来说,显示屏幕的刷新频率是60hz,所以60帧/秒已经是极限帧率,超过这个数值意义不大,而且 OS 的图形子系统本身就会强制限制 UI 界面的更新跟屏幕的刷新保持同步)。
所以对于现代浏览器来说,所谓硬件加速,就是使用 GPU 来进行混合,绘制仍然使用 CPU 来完成。
分块渲染
图片来自 [UC 浏览器 9.7 Android版],使用256×256大小的分块
网页的缓存通常都不是一大块,而是划分成一格一格的小块,通常为256×256或者512×512大小,这种渲染方式称为分块渲染(Tile Rendering)。使用分块渲染的主要原因是因为 –
- 所谓 GPU 混合,通常是使用 Open GL/ES 贴图来实现的,而这时的缓存其实就是纹理(GL Texture),而很多 GPU 对纹理的大小有限制,比如长/宽必须是2的幂次方,最大不能超过2048或者4096等,所以无法支持任意大小的缓存;
- 使用小块缓存,方便浏览器使用一个统一的缓存池来管理分配的缓存,这个缓存池一般会分配成百上千个缓存块供所有的 WebView 共用。所有打开的网页,需要缓存时都可以以缓存块为单位向缓存池申请,而当网页关闭或者不可见时,这些不需要的缓存块就可以被回收供其它网页使用;
总之固定大小的小块缓存,通过一个统一缓存池来管理的方式,比起每个 WebView 自己持有一大块缓存有很多优势。特别是更适合多线程 CPU/GPU 并发的渲染模型,所以基本上支持硬件加速的浏览器都会使用分块渲染的方式。
图层混合加速
图片来自 [UC 浏览器 9.7 Android版],可见区域内有4个 Layer 有自己的缓存 – 最底层的 Base Layer,上方的 Fixed 标题栏,中间的热点新闻栏,右下方的 Fixed 跳转按钮
图层混合加速(Accelerated Compositing)的渲染架构是 Apple 引入 WebKit 的,并在 Safari 上率先实现,而 Chrome/Android/Qt/GTK+ 等都陆续完成了自己的实现。如果熟悉 iOS 或者 Mac OS GUI 编程的读者对其应该不会感到陌生,它跟 iOS CoreAnimation 的 Layer Rendering 渲染架构基本类似,主要都是为了解决当 Layer 的内容频繁发生变化,或者当 Layer 触发一个2D/3D变换(2D/3D Transform )或者渐隐渐入动画,它的位移,缩放,旋转,透明度等属性不断发生变化时,在原有的渲染架构下,渲染性能低下的问题。
非混合加速的渲染架构,所有的 RenderLayer 都没有自己独立的缓存,它们都被绘制到同一个缓存里面(按照它们的先后顺序),所以只要这个 Layer 的内容发生变化,或者它的一些 CSS 样式属性比如 Transform/Opacity 发生变化,变化区域的缓存就需要重新生成,此时不但需要绘制变化的 Layer,跟变化区域(Damage Region)相交的其它 Layer 都需要被绘制,而前面已经说过,网页的绘制是十分耗时的。如果 Layer 偶尔发生变化,那还不要紧,但如果是一个 JavaScript 或者 CSS 动画在不断地驱使 Layer 发生变化,这个动画要达到60帧/每秒的流畅效果就基本不可能了。
而在混合加速的渲染架构下,一些 RenderLayer 会拥有自己独立的缓存,它们被称为混合图层(Compositing Layer),WebKit 会为这些 RenderLayer 创建对应的 GraphicsLayer,不同的浏览器需要提供自己的 GrphicsLayer 实现用于管理缓存的分配,释放,更新等等。拥有 GrphicsLayer 的 RenderLayer 会被绘制到自己的缓存里面,而没有 GrphicsLayer 的 RenderLayer 它们会向上追溯有 GrphicsLayer 的父/祖先 RenderLayer,直到 Root RenderLayer 为止,然后绘制在有 GrphicsLayer 的父/祖先 RenderLayer 的缓存上,而 Root RenderLayer 总是会创建一个 GrphicsLayer 并拥有自己独立的缓存。最终,GraphicsLayer 又构成了一棵与 RenderLayer 并行的树,而 RenderLayer 与 GraphicsLayer 的关系有些类似于 RenderObject 与 RenderLayer 之间的关系。
混合加速渲染架构下的网页混合,也变得比以前复杂,不再是简单的将一个缓存拷贝到窗口缓存上,而是需要完成源自不同 Layer 的多个缓存的拷贝,再加上可能的2D/3D变换,再加上缓存之间的Alpha混合等操作,当然,对于支持硬件加速,使用 GPU 来完成混合的浏览器来说,速度还是很快的。
RenderLayer 生成 GraphicsLayer 的条件,来自 GPU Accelerated Compositing in Chrome
- Layer has 3D or perspective transform CSS properties
- Layer is used by < video> element using accelerated video decoding
- Layer is used by a < canvas> element with a 3D context or accelerated 2D context
- Layer is used for a composited plugin
- Layer uses a CSS animation for its opacity or uses an animated webkit transform
- Layer uses accelerated CSS filters
- Layer with a composited descendant has information that needs to be in the composited layer tree, such as a clip or reflection
- Layer has a sibling with a lower z-index which has a compositing layer (in other words the layer is rendered on top of a composited layer)
混合加速的渲染架构下,Layer 的内容变化,只需要更新所属的 GraphicsLayer 的缓存即可,而缓存的更新,也只需要绘制直接或者间接属于这个 GraphicsLayer 的 RenderLayer 而不是所有的 RenderLayer。特别是一些特定的 CSS 样式属性的变化,实际上并不引起内容的变化,只需要改变一些 GraphicsLayer 的混合参数,然后重新混合即可,而混合相对绘制而言是很快的,这些特定的 CSS 样式属性我们一般称之为是被加速的,不同的浏览器支持的状况不太一样,但基本上 CSS Transform & Opacity 在所有支持混合加速的浏览器上都是被加速的。被加速的CSS 样式属性的动画,就比较容易达到60帧/每秒的流畅效果了。

图片来自 Understanding Hardware Acceleration on Mobile Browsers,展现了经典的 CSS 动画 Demo – Falling Leaves 的图层混合的示意图,它所使用的 Transform 和 Opacity 动画在所有支持混合加速的浏览器上都是被加速的
不过并不是拥有独立缓存的 RenderLayer 越多越好,太多拥有独立缓存的 Layer 会带来一些严重的副作用 – 首先它大大增加了内存的开销,这点在移动设备上的影响更大,甚至导致浏览器在一些内存较少的移动设备上无法很好地支持图层混合加速;其次,它加大了混合的时间开销,导致混合性能的下降,而混合性能跟网页滚动/缩放操作的流畅度又息息相关,最终导致网页滚动/缩放的流畅度下降,让用户觉得操作不够流畅。
在 Chrome://flags 里面开启“合成渲染层边框”就可以看到哪些 Layer 是一个 Compositing Layer,也就是拥有自己的独立缓存。前端开发者可以用此帮助自己控制 Compositing Layer 的创建。总的的说, Compositing Layer 可以提升绘制性能,但是会降低混合性能,网页只有合理地使用 Compositing Layer,才能在绘制和混合之间取得一个良好的平衡,实现整体渲染性能的提升。

图片来自 Chrome,展现了经典的 CSS 动画 Demo – Falling Leaves 的合成渲染层边框
网页游戏渲染 - Canvas & WebGL

图片来自 [UC 浏览器 9.7 Android版],基于2D Canvas 的游戏不江湖,在主流配置手机上可以达到60帧/每秒的流畅度
以前网页游戏一般都是使用 Flash 来实现,但是随着 Flash 从移动设备被淘汰,越来越多的网页游戏会改用 Canvas 和 WebGL 来开发,浏览器关于 Canvas 的基本绘制流程可以参考我以前的文章 Introduce My Work。虽然一般网页元素都是使用 CPU 来绘制,但是对于加速的2D Canvas 和 WebGL 来说,它们的绘制是直接使用 GPU 的,所以它们一般会拥有一个 GL FBO(FrameBufferObject)作为自己的缓存,Canvas/WebGL 的内容被绘制到这个 FBO 上面,而这个 FBO 所关联的纹理再在混合操作里面被拷贝到窗口缓存上。简单的来说,对于加速的2D Canvas 和 WebGL,它们的绘制和混合都是使用 GPU。

图片来自 [UC 浏览器 9.7 Android版],一个演示 WebGL 的网页 Demo
关于如何优化 Canvas 游戏的性能,请参考我以前的文章 – High Performance Canvas Game for Android(高性能Android Canvas游戏开发)。
Posted by
Horky
on 2013 年 11 月 6 日
Google Chrome的历史和指导原则
【译注】这部分不再详细翻译,只列出核心意思。
驱动Chrome继续前进的核心原则包括:
- Speed: 做最快的(fastest)的浏览器。
- Security:为用户提供最为安全的(most secure)的上网环境。
- Stability: 提供一个健壮且稳定的(resilient and stable)的Web应用平台。
- Simplicity: 以简练的用户体验(simple user experience)封装精益求精的技术(sophisticated technology)。
本文关将注于第一点,速度。
关于性能的方方面面
一个现代浏览器就是一个和操作系统一样的平台。在Chrome之前的浏览器都是单进程的应用,所有页面共享相同的地址空间和资源。引入多进程架构这是Chrome最为著名的改进【译注:省略一些反复谈论的细节】。

一个进程内,Web应用主要需要执行三个任务:获取资源,页面 排版及渲染,和运行JavaScript。渲染和脚本都是在运行中交替以单线程的方式运行的,其原因是为了保持DOM的一致性,而JavaScript本 身也是一个单线程的语言。所以优化渲染和脚本运行无论对于页面开发者还是浏览器开发者都是极为重要的。
Chrome的渲染引擎是WebKit, JavaScript Engine则使用深入优论的V8 (“V8” JavaScript runtime)。但是,如果网络不畅,无论优化V8的JavaScript执行,还是优化WebKit的解析和渲染,作用其实很有限。巧妇难为无米之炊,数据没来就得等着!
相对于用户体验,作用最为明显的就是如何优化网络资源的加载顺 序、优先级及每一个资源的延迟时间(latency)。也许你察觉不到,Chrome网络模块每天都在进步,逐步降低每个资源的加载成本:向DNS lookups学习,记住页面拓扑结构(topology of the web), 预先连接可能的目标网址,等等,还有很多。从外面来看就是一个简单的资源加载的机制,但在内部却是一个精彩的世界。
关于Web应用
开始正题前,还是先来了解一下现在网页或者Web应用在网络上的需求。
HTTP Archive 项目一直在追踪网页构建。除了页面内容外,它还会分析流行页面使用的资源数量,类型,头信息以及不同目标地址的元数据(metadata)。下面是2013年1月的统计资料,由300,000目标页面得出的平均数据:

- 1280 KB
- 包含88个资源(Images,JavaScript,CSS …)
- 连接15个以上的不同主机(distinct hosts)
这些数字在过去几年中一直持续增长(steadily increasing),没有停下的迹象。这说明我们正不断地建构一个更加庞大的、野心勃勃的网络应用。还要注意,平均来看每个资源不过12KB, 表明绝大多数的网络传输都是短促(short and bursty)的。这和TCP针对大数据、流式(streaming)下载的方向不一致,正因为如此,而引入了一些并发症。下面就用一个例子来抽丝剥茧,一窥究竟……
一个Resource Request的一生
W3C的Navigation Timing specification定义了一组API,可以观察到浏览器的每一个请求(request)的时序和性能数据。下面了解一些细节:

给定一个网页资源地址后,浏览器就会检查本地缓存和应用缓存。如果之前获取过并且有相应的缓存信息(appropriate cache headers)(如Expires, Cache-Control, etc.), 就会用缓存数据填充这个请求,毕竟最快的请求就是没有请求(the fastest request is a request not made)。否则,我们重新验证资源,如果已经失效(expired),或者根本就没见过,一个耗费网络的请求就无法避免地发送了。
给定了一个主机名和资源路径后,Chrome先是检查现有已建立的连接(existing open connections)是否可以复用, 即sockets指定了以(scheme、host和port)定义的连接池(pool)。但如果配置了一个代理,或者指定了proxy auto-config(PAC)脚本,Chrome就会检查与proxy的连接。PAC脚本基于URL提供不同的代理,或者为此指定了特定 的规则。与每一个代理间都可以有自己的socket pool。最后,上述情况都不存在,这个请求就会从DNS查询(DNS lookup)开始了,以便获得它的IP地址。
幸运的话,这个主机名已经被缓存过。否则,必须先发起一个 DNS Query。这个过程所需的时间和ISP,页面的知名度,主机名在中间缓存(intermediate caches)的可能性,以及authoritative servers的响应时间这些因素有关。也就是说这里变量很多,不过一般还不致于到几百毫秒那么夸张。

拿到解析出的IP后,Chrome就会在目标地址间打开一个新TCP连接,我们就要执行一个3度握手(“three-way handshake”): SYN > SYN-ACK > ACK。这个操作每个新的TCP连接都必须完成,没有捷径。根据远近,路由路径的选择,这个过程可能要耗时几百毫秒,甚至几秒。而到现在,我们连一个有效的字节都还没收到。
当TCP握手完成了,如果我们连接的是一个HTTPS地址,还有一个SSL握手过程,同时又要增加最多两轮的延迟等待。如果SSL会话被缓存了,就只需一次。
最后,Chrome终于要发送HTTP请求了 (如上面图示中的requestStart)。 服务器收到请求后,就会传送响应数据(response data)回到客户端。这里包含最少的往返延迟和服务的处理时间。然后一个请求就完成了。但是,如果是一个HTTP重定向(redirect)的话?我们 又要从头开始这个过程。如果你的页面里有些冗余的重定向,最好三思一下!
你得出所有的延迟时间了吗? 我们假设一个典型的宽带环境:没有本地缓存,相对较快的DNS lookup(50ms), TCP握手,SSL协商,以及一个较快服务器响应时间(100ms)和一次延迟(80ms,在美国国内的平均值):
- 50ms for DNS
- 80ms for TCP handshake (one RTT)
- 160ms for SSL handshake (two RTT’s)
- 40ms (发送请求到服务器)
- 100ms (服务器处理)
- 40ms (服务器回传响应数据)
一个请求花了470毫秒, 其中80%的时间被网络延迟占去了。看到了吧,我们真得有很多事情要做!事实上,470毫秒已经很乐观了:
怎样才算”够快”?
前面可以看到服务器响应时间仅是总延迟时间的20%,其它都被DNS,握手等操作占用了。过去用户体验研究(user experience research)表明用户对延迟时间的不同反应:
- 0 – 100ms 迅速
- 100 – 300ms 有点慢
- 300 – 1000ms 机器还在运行
- 1s+ 想想别的事……
- 10s+ 我一会再来看看吧……
上表同样适用于页面的性能表现: 渲染页面,至少要在250ms内给个回应来吸引住用户。这就是简单地针对速度。从Google, Amazon, Microsoft,以及其它数千个站点来看,额外的延迟直接影响页面表现:流畅的页面会吸引更多的浏览、以及更强的用户吸引力(engagement) 和页面转换率(conversion rates).
现在我们知道了理想的延迟时间是250ms,而前面的示例告诉我们,DNS Lookup, TCP和SSL握手,以及request的准备时间花去了370ms, 即便不考虑服务器处理时间,我们也超出了50%。
对于绝大多数的用户和网页开发者来说,DNS, TCP,以及SSL延迟都是透明,很少有人会想到它。这也就是为什么Chrome的网络模块那么的复杂。
我们已经识别出了问题,下面让我们深入一下实现的细节…
深入Chrome的网络模块
多进程架构
Chrome的多进程架构为浏览器的网络请求处理带来了重要意义,它目前支持四种不同的执行模式(four different execution models)。
默认情况下,桌面的Chrome浏览器使用process-per-site模式, 将不同的网站页面隔离起来, 相同网站的页面组织在一起。举个简单的例子: 每个tab独立一个进程。从网络性能的角度上说,并没什么本质上的不同,只是process-per- tabl模式更易于理解。

每一个tab有一个渲染进程(render process),其中包括了用于解析页面(interpreting)和排版(layout out)的WebKit的排版引擎(layout engine), 即上图中的HTML Render。还有V8引擎和两者之间的DOM Bindings,如果你对这部分很好奇,可以看这里(great introduction to the plumbing)。
每一个这样的渲染进程被运行在一个沙箱环境中,只会对用户的电 脑环境做极有限的访问–包括网络。而使用这些资源,每一个渲染进程必须和浏览内核进程(browser[kernel] process)沟通,以管理每个渲染进程的安全性和访问策略(access policies)。
进程间通讯(IPC)和多进程资源加载
渲染进程和内核进程之间的通讯是通过IPC完成的。在Linux和 Mac OS上,使用了一个提供异步命名管道通讯方式的socketpair()。每一个渲染进程的消息会被序列化地到一个专用的I/O线程中,然后再由它发到内 核进程。在接收端,内核进程提供一个过滤接口(filter interface)用于解析资源相关的IPC请求(ResourceMessageFilter), 这部分就是网络模块负责的。

这样做其中一个好处是所有的资源请求都由I/O进程处理,无论是UI产生的活动,或者网络事件触发的交互。在内核进程(browser/kernel process)的I/O线程解析资源请求消息,将转发到一个ResourceDispatcherHost的单例(singleton)对象中处理。
这个单例接口允许浏览器控制每个渲染进程对网络的访问,也能达到有效和一致的资源共享:
- Socket pool 和 connection limits: 浏览器可以限定每一个profile打开256个sockets, 每个proxy打开32个sockets, 而每一组{scheme, host, port}可以打开6个。注意同时针对一组{host,port}最多允计打开6个HTTP和6个HTTPS连接。
- Socket reuse: 在Socket Pool中提供持久可用的TCP connections,以供复用。这样可以为新的连接避免额外建立DNS、TCP和SSL(如果需要的话)所花费的时间。
- Socket late-binding(延迟绑定): 网络请求总是当Scoket准备好发送数据时才与一个TCP连接关连起来,所以首先有机会做到对请求有效分级(prioritization),比如,在 socket连接过程中可能会到达到一个更高优先级的请求。同时也可以有更好的吞吐率(throughput),比如,在连接打开过程中,去复用一个刚好 可用的socket, 就可以使用到一个完全可用的TCP连接。其实传统的TCP pre-connect(预连接)及其它大量的优化方法也是这个效果。
- Consistent session state(一致的会话状态): 授权、cookies及缓存数据会在所有渲染进程间共享。
- Global resource and network optimizations(全局资源和网络优化): 浏览器能够在所有渲染进程和未处理的请求间做更优的决策。比如给当前tab对应的请求以更好的优先级。
- Predictive optimizations(预测优化): 通过监控网络活动,Chrome会建立并持续改善预测模型来提升性能。
- … 项目还在增加中。
单就一个渲染进程而言, 透过IPC发送资源请求很容易,只要告诉浏览器内核进程一个唯一ID, 后面就交给内核进程处理了。
跨平台的资源加载
跨平台也是Chrome网络模块的一个主要考量,包括Linux, Windows, OS X, Chrome OS, Android, 和iOS。 为此,网络模块尽量实现成了单进程模式(只分出了独立的cache和proxy进程)的跨平台函数库, 这样就可以在平台间共用基础组件(infrastructure)并分享相同的性能优化,更有机会做到同时为所有平台进行优化。
相关的代码可以在这里找到the “src/net” subdirectory)。本文不会详细展开每个组件,不过了解一下代码结构可以帮助我们理解它的能力结构。 比如:
- net/android 绑定到Android 运行时(runtime) [译注(Horky):运行时真是一个很烂的术语,翻和没翻一样。]
- net/base 公共的网络工具函数。比如,主机解析, cookies, 网络转换侦测(network change detection),以及SSL认证管理
- net/cookies 实现了Cookie的存储、管理及获取
- net/disk_cache 磁盘和内存缓存的实现
- net/dns 实现了一个异步的DNS解析器(DNS resolver)
- net/http 实现了HTTP协议
- net/proxy 代理(SOCKS 和 HTTP)配置、解析(resolution) 、脚本抓取(script fetching), …
- net/socket TCP sockets,SSL streams和socket pools的跨平台实现
- net/spdy 实现了SPDY协议
- net/url_request URLRequest, URLRequestContext和URLRequestJob的实现
- net/websockets 实现了WebSockets协议
上面每一项都值得好好读读,代码组织的很好,你还会发现大量的单元测试。
Mobile平台上的架构和性能
移动浏览器正在大发展,Chrome团队也视优化移动端的体验为最高优先级。先要说明的是移动版的Chrome的并不是其桌面版本的直接移植,因为那样根本不会带来好的用户体验。移动端的先天特性就决定了它是一个资源严重受限的环境,在运行参数有一些基本的不同:
- 桌面用户使用鼠标操作,可以有重叠的窗口,大的屏幕,也不用担心电池。网络也非常稳定,有大量的存储空间和内存。
- 移动端的用户则是触摸和手势操作,屏幕小,电池电量有限,通过只能用龟速且昂贵的网络,存储空间和内存也是相当受限。
再者,不但没有典型的样板移动设备,反而是有一大批各色硬件的设备。Chrome要做的,只能是设法兼容这些设备。好在Chrome有不同的运行模式(execution models),面对这些问题,游刃有余!
在Android版本上,Chrome同样运用了桌面版本的多进程架构。一个浏览器内核进程,以及一个或多个渲染进程。但因为内存的限制,移动版的Chrome无法为每一个tabl运行一个特定的渲染进程,而是根据内存情况等条件决定一个最佳的渲染进程个数,然后就会在多个tab间共享这些渲染进程。
如果内存实在不足,或其它原因导致Chrome无法运行多进程,它就会切到单进程、多线程的模式。比如在iOS设备上,因为其沙箱机制的限制,Chrome只能运行在这种模式下。
关于网络性能,首先Chrome在Android和iOS使用的是 各其它平台相同的网络模块。这可以做到跨平台的网络优化,这也是Chrome明显领先的优势之一。所不同的是需要经常根据网络情况和设备能力进行些调整, 包括推测优化(speculative optimization)的优先级、socket的超时设置和管理逻辑、缓存大小等。
比如,为了延长电池寿命,移动端的Chrome会倾向于延迟关闭空 闲的sockets (lazy closing of idle sockets), 通常是为了减少信号(radio)的使用而在打开新的socket时关闭旧的。另外因为预渲染(pre-rendering,稍后会介绍)会使用一定的网 络和处理资源,它通常只在WiFi才会使用。
关于移动浏览体验会独立一章,也许就在POSA系列的下一期。
Chrome Predictor的预测功能优化
Chrome会随着使用变得更快。它这个特性是通过一个单例对象Predictor来实现的。这个对象在浏览器内核进程(Browser Kernel Process)中实例化,它唯一的职责就是观察和学习当前网络活动方式,提前预估用户下一步的操作。下面是一个示例:
- 用户将鼠标停留在一个链接上,就预示着一个用户的偏好以及下一步的浏览行为。这时Chrome就可以提前进行DNS Lookup及TCP握手。用户的点击操作平均需要将近200ms,在这个时间就可能处理完DNS和TCP相关的操作, 也就是省去几百毫秒的延迟时间。
- 当在地址栏(Omnibox/URL bar) 触发高可能性选项时,就同样会触发一个DNS lookup和TCP预连接(pre-connect),甚至在一个不可见的页签中进行预渲染(pre-render)!
- 我们每个人都一串天天会访问的网站, Chrome会研究在这些页面上的子资源, 并且尝试进行预解析(pre-resolve), 甚至可能会进行预加载(pre-fetch)以优化浏览体验。
除了上面三项,还有很多..
Chrome会在你使用过程中学习Web的拓扑结构,而不单单是你的浏览模式。理想的话,它将为你省去数百毫秒的延迟, 更接近于即时页面加载的状态. 正是为了这个目标,Chrome投入了以下的核心优化技术:
- DNS预解析(pre-resolve):提前解析主机地址,以减少DNS延迟
- TCP预连接(pre-connect):提前连接到目标服务器,以减少TCP握手延迟
- 资源预加载(prefetching):提前加载页面的核心资源,以加载页面显示
- 页面预渲染(prerendering):提前获取整个页面和相关子资源,这样可以做到及时显示
每一个决策都包含着一个或多个的优化, 用来克服大量的限制因素. 不过毕竟都只是预测性的优化策略,如果效果不理想,就会引入多余的处理和网络传输。甚至可能会带来一些加载时间上的负体验。
Chrome如何处理这些问题呢? Predictor会尽量收集各种信息,诸如用户操作,历史浏览数据,以及来自渲染引擎(render)和网络模块自身的信息。
和Chrome中负责网络事务调度的ResourceDispatcherHost不同,Predictor对象会针对用户和网络事务创建一组过滤器(filter):
- IPC channel filter用来监控来自render进程的事务。
- 每个请求上都会加一个ConnectInterceptor 对象,这样就可以跟踪网络传输的模式以及每一个请求的度量数据。
渲染进程(render process)会在一系列的事件下发送消息到浏览器进程(browser process), 这些事件被定义在一个枚举(ResolutionMotivation)中以便于使用 (url_info.h):
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
enum
ResolutionMotivation
{
MOUSE_OVER_MOTIVATED
,
// 鼠标悬停.
OMNIBOX_MOTIVATED
,
// Omni-box建议进行解析.
STARTUP_LIST_MOTIVATED
,
// 这是在前10个启动项中的资源.
EARLY_LOAD_MOTIVATED
,
// 有时需要使用prefetched来提前建立连接.
// 下面定义了预加载评估的方式,会由一个navigation变量指定.
// referring_url_也需要同时指定.
STATIC_REFERAL_MOTIVATED
,
// 外部数据库(External Database)建议进行解析。
LEARNED_REFERAL_MOTIVATED
,
// 前一次浏览(prior navigation建议进行解析.
SELF_REFERAL_MOTIVATED
,
// 猜测下一个连接是不是需要进行解析.
// <略> ...
}
;
|
通过这些给定的事 件,Predictor的目标就可以评估它成功的可能性, 然后再适时触发操作。每一项事件都有其成功的机率、优先级以及时间戳,这些可以在内部维护一个用优先级管理的队列,也是优化的一个手段。最终,对于这个队 列中发出的每一个请求的成功率,都可以被Predictor追踪到。基于这些数据,Predictor就可以进一步优化它的决策。
Chrome网络架构小结
- Chrome使用多进程架构,将渲染进程同浏览器进程隔离开来。
- Chrome维护着一个资源分发器的实例(a single instance of the resource dispatcher), 它运行在浏览器内核进程,并在各个渲染进程间共享。
- 网络层是跨平台的,大部分情况下以单进程库存在。
- 网络层使用非阻塞式(no-blocking)操作来管理所有网络任务。
- 共享的网络层支持有效的资源排序、复用、并为浏览器提供在多进程间进行全局优化的能力。
- 每一个渲染进程通过IPC和资源分发器(resource dispatcher)通讯。
- 资源分发器(Resource dispatcher)通过自定义的IPC Filter解析资源请求。
- Predictor在解析资源请求和响应网络事务中学习,并对后续的网络请求进行优化。
- Predictor会根据学习到的网络事务模式预测性的进行DNS解析, TCP握手,甚至是资源请求,为用户实际操作时节省数百毫秒的时间。
了解晦涩的内部细节后,让我们来看一下用户可以感受到的优化。一切从全新的Chrome开始。
优化冷启动(Cold-Boot)体验
第一次启动浏览器,它当然不可能了解你的使用习惯和喜欢的页面。但事实上,我们大多数会在浏览器的冷启动后做些类似的事情,比如到电子邮箱查看邮件,加一些新闻页面、社交页面及内部 页面到我的最爱,诸如此类。这些页面各有不同,但它们仍然具有一些相似性,所以Predictor仍然可以对这个过程提速。
Chrome记下了用户在全新启动浏览器时最常用的10个域名。当浏览器启动时,Chrome会提前对这些域名进行DNS预解析。你可以在Chrome中使用chrome://dns查看到这个列表。在打开页面的最上面的表格中会列出启动时的备选域名列表。

通过Omnibox优化与用户的交互
引入Omnibox是Chrome的一项创新, 并不是简单地处理目标的URL。除了记录之前访问过的页面URL,它还与搜索引擎的整合,并且支持在历史记录中进行全文搜索(比如,直接输入页面名称)。
当用户输入时,Omnibox自动发起一个行为,要么查找浏览记录中的URL, 要么进行一次搜索。每一次发起的操作都会被加以评分,以统计它的性能。你可以在Chrome输入chrome://predictors来观察这些数据。

Chrome维护着一个历史记录,内容包括用户输入的前置文字,采用的行为,以命中的资数。在上面的列表,你可以看到,当输入g时,有76%的机会尝试打开Gmail. 如果再补充一个m (就是gm), 打开Gmail的可能性增加到99.8%。
那么网络模块会做什么呢?上 表中的黄色和绿色对于ResourceDispatcher非常重要。如果有一个一般可能性的页面(黄色), Chrome就是发起DNS预解析。如果有一个高可能性的页面(绿色),Chrome还会在DNS解析后发起TCP预连接。如果这两项都完成了,用户仍然 继续录入,Chrome就会在一个隐藏的页签进行预渲染(pre-render)。
相对的,如果输入的前置文字找不到合适的匹配项目,Chrome会向搜索引擎服务者发起DNS预解析和TCP预连,以获取相似的搜索结果。
平均而言用户从填写查询内容到评估给出的建议需要花费数百毫秒。此时Chrome可以在后台进行预解析,预连接,甚至进行预渲染。再当用户准备按下回车键时,大量的网络延迟已经被提前处理掉了。
优化缓存性能
最快的请求就是没有请求。 无论何时讨论性能,都不能不谈缓存。相信你已经为页面上所有资源的都提供了Expires, ETag, Last-Modified和Cache-Control这些响应头信息(response headers)。什么? 还没有?那你还是先处理好再来看吧!
Chrome有两种不同的内部缓存的实现:一种备份于本地磁盘(local disk),另一种则存储于内存(in-memory)中。内存模式(in-memory)主要应用于无痕浏览模式(Incognito browsing mode),并在关闭窗口清除掉。 两种方式使用了相同的内部接口(disk_cache::Backend, 和disk_cache::Entry),大大简化了系统架构。如果你想实现一个自己的缓存算法,可以很容易地实现进去。
在内部,磁盘缓存(disk cache)实现了它自己的一组数据结构, 它们被存储在一个单独的缓存目录里。其中有索引文件(在浏览器启动时加载到内存中),数据文件(存储着实际数据,以及HTTP头以及其它信息)。比较有趣 的是,16KB以下的文件存储于共同的数据块文件中(data block-files,即小文件集中存储于一个大文件中),其它较大的文件才会存储到自己专属的文件中。最后,磁盘缓存的淘汰策略是维护一个LRU,通 过比如访问频率和资源的使用时间(age)的度量进行管理。

在Chrome开个页签,输入chrome://net-internals/#httpCache。 如果你要看到实际的HTTP数据和缓存的响应处理,可以打开chrome://cache, 里面会列出所有缓存中可用的资源。打开每一项,还可以看到详细的数据头等信息。
优化DNS预连接
前面已经多次提到了DNS预解析,在深入实现之前,先汇总一下DNS预解析的场景和理由:
- 运行在渲染进程中的WebKit文档解析器(document parser), 会为当前页面上所有的链接提供一个主机名(hostname)列表,Chrome可以选择是否提前解析。
- 当用户要打开页面时,渲染进程先会触发一个鼠标悬停(hover)或按键(button down)事件。
- Omnibox可能会针对一个高可能性的建议页面发起解析请求。
- Chrome Predictor会基于过往浏览记录和资源请求数据发起主机解析请求。(下面会详细解释。)
- 页面本身会显式地要求Chrome对某些主机名称进行预解析。
上述各项对于Chrome都只是一个线索。Chrome并不保证预解析一定会被执行,所有的线索会由Predictor进行评估,以决定后续的操作。最坏的情况下,可能无法及时解析主机名,用户就必须等待一个 DNS解析时间,然后是TCP连接时间,最后是资源加载时间。Predictor会记下这个场景,在未来决策时相应地加以参考。总之,一定是越用越快。
之前提过到Chrome可以 记住每个页面的拓扑(topology),并可以基于这个信息进行加速。还记得吧,平均每个页面带有88个资源,分别来自于30多个独立的主机。每打开这 个页面,Chrome会记下资源中比较常用的主机名,在后续的浏览过程中,Chrome就会发起针对某些主机或者全部主机的DNS解析,甚至是TCP预连接!

使用chrome://dns 就可以观察到上面的数据(Google+页面), 其中有6个子资源对应的主机名,并记录了DNS预解析发生的次数,TCP预连接发生的次数,以及到每个主机的请求次数。这些数据就可以让Chrome Predictor执行相应的优化决策。
除了内部事件通知外,页面设计者可以在页面中嵌入如下的语句请求浏览器进行预解析:
|
|
<
link
rel
=
"dns-prefetch"
href
=
"//host_name_to_prefetch.com"
>
|
之所以有这个需求,一个典型的例子是重定向(redirects). Chrome本身没办法判断出这种模式,通过这种方式则可以让浏览器提前进行解析。
具体的实现也是因版本而有所差异,总体而言,Chrome中的DNS处理有两个主要的实现:1.基于历史数据(historically), 通过调用平台无关的getaddrinfo()系统函数实现。2.代理操作系统的DNS处理方法,这种方法正在被Chrome自行实现的一套异步DNS解析机制(asynchronous DNS resolver)所取代。
依赖于系统的实现,代码少而 且简单,但是getaddrInfo()是一个阻塞式的系统调用,无法有效地并行多个查询操作。经验数据还显示,并行请求过多甚至会超出路由器的负额。 Chrome为此设计了一个复杂的机制。对于其中带有worker-pool的预解析, Chrome只是简单的发送getaddrinfo() 调用, 同时阻塞worker thread直到收到响应数据。因为系统有DNS缓存的原因,针对解析过的主机,解析操作会立即返回。 这个过程简单,有效。
但还不够! getaddrinfo()隐藏了太多有用的信息,比如Time-to-live(TTL)时间戳, DNS缓存的状态等。于是Chrome决定自己实现一套跨平台的异步DNS解析器。

这个新技术可以支持以下优化:
- 更好地控制重转的时机,有能力并行执行多个查询操作。 清晰地记录TTLs。
- 更好地处理IPv4和IPv6的兼容。
- 基于RTT和其它事件,针对不同服务器进行错误处理(failover)
Chrome仍然进行着持续的优化. 通过chrome://histograms/DNS可以观察到DNS度量数据:

上面的柱状图展示了 DNS预解析延迟时间的分布:比如将近50%(最右侧)的查询在20ms内完成。这些数据基于最近的浏览操作(采样9869次),用户可以选择是否报告这 些使用数据,然后这些数据会以匿名的形式交由工程团队加以分析,这样就可以了解到功能的性能,以及未来如何进一步调整。周而复始,不断优化。
使用预连接优化了TCP连接管理
已经预解析到了主机名,也有了 由OmniBox和Chrome Predictor提供信号,预示着用户未来的操作。为什么再进一步连接到目标主机,在用户真正发起请求前完成TCP握手呢?这样就可省掉了另一个往返的 延迟,轻易地就能为用户节省到上百毫秒。其实,这就是TCP预连接的工作。 通过访问chrome://dns 就可以看到TCP预连接的使用情况。

首先, Chrome检查它的socket pool里有没有目标主机可以复用的socket, 这些sockets会在socket pool里保留一段时间,以节省TCP握手时间及启动延时(slow-start penalty)。如果没有可用的socket, 就需要发起TCP握手,然后放到socket pool中。这样当用户发起请求时,就可以用这个socket立即发起HTTP请求。
打开 chrome://net-internals#sockets 就可以看到当前的sockets的状态:

你可以看到每一个socket的时间轴:连接和代理的时间,每个封包到达的时间,以及其它一些信息。你也可以把这些数据导出,以方便进一步分析或者报告问题。有好的测试数据是优化的基础, chrome://net-internals就是Chrome网络的信息中心。
使用预加载优化资源加载
Chrome支持在页面的HTML标签中加入的两个线索来优化资源加载:
|
|
<
link
rel
=
"subresource"
href
=
"/javascript/myapp.js"
>
<
link
rel
=
"prefetch"
href
=
"/images/big.jpeg"
>
|
在rel中指定的 subresource(子资源)和prefetch(预加载)非常相似。不同的是,如果一个link指定rel(relation)为prefetch 后,就是告诉浏览器这个资源是稍后的页面中要用到的。而指定为subresource则表示在本页中就会用到,期望能在使用前加载。两者不同的语义让 resource loader有不同的行为。prefetch的优先级较低,一般只会在页面加载完成后才会开始。而subresource则会在解析出来时就被尝试优先执行。
还要注意,prefetch是HTML5的一部分,Firefox和Chrome都可以支持。但subresource还只能用在Chrome中。
应用Browser Prefreshing优化资源加载
不过,并不是所有的Web开发者会愿意加入上面所述的subresource relation, 就算加了,也要等收到主文档并解析出这些内容才行,这段时间开销依赖于服务器的响应时间和客户端与服务器间的延迟时间,甚至要耗去上千毫秒。
和前面的预解析,预连接一样,这里还有一个prefreshing::
- 用户初始化一个目标页面的请求。
- Chrome查询Predictor之前针对目标页面的子资源加载,初始化一组DNS预解析,TCP预连接及资源prefreshing。
- 如是在缓存中发现之前记录的子资源,由从磁盘中加载到内存中。
- 如果没有或者已经过期了,就是发送网络请求。

直到在2013年初, prefreshing还是处于早期的讨论阶段。如果通过数据结果分析,这个功能最终上线了,我们就可以稍晚些时候使用到它了。
使用预渲染优化页面浏览
前面讨论的每个优化都用来帮助减少用户发起请求到看到页面内容的延迟时间。多快才能带来即时呈现的体验呢?基于用户体验数据,这个时间是100毫秒,根本没给网络延迟留什么空间。而在100毫秒内,又怎样渲染页面呢?
大家可能都有这样的体验: 同时开多个页签时会明显快于在一个页签中等待。浏览器为此提供了一个实现方式:
|
|
<
link
rel
=
"prerender"
href
=
"http://example.org/index.html"
>
|
这就是Chrome的预渲染(prerendering in Chrome)! 相对于只下载一个资源的“prefetch”, “prerender”会让Chrome在一个不可见的页签中渲染一个页面,包含了它所有的子资源。当用户要浏览它时,这个页签被切到前台,做到了即时的体验。
可以浏览prerender-test.appspot.com来体验一下效果,再通过chrome://net-internals/#prerender查看下历史记录和预连接页面的状态。

因为预渲染会同时消耗CPU和网络资源,因些一定要在确信预渲染页面会被使用到情况下才用。Google Search就在它的搜索结果里加入prerender, 因为第一个搜索结果很可能就是下一个页面(也叫作Google Instant Pages)
你可以使用预渲染特性,但以下限制项一定要牢记:
- 所有的进程中最多只能有一个预渲染页。
- HTTPS和带有HTTP认证的页面不可以预渲染。
- 如果请求资源需要发起非幂等(non-idempotent,idempotent request的意义为发起多次,不会带来服务的负面响应的请求)的请求(只有GET请求)时,预渲染也不可用。
- 所有的资源的优先级都很低。
- 页面渲染进程的使用最低的CPU优先级。
- 如果需要超过100MB的内存,将无法使用预渲染。
- 不支持HTML5多媒体元素。
预渲染只能应用于确信安全的页面。另外JavaScript也最好在运行时使用Page Visibility API来判断一下当前页是否可见(参考 you should be doing anyway) !

最后,总之,Chrome正逐步优化网络延迟和用户体验,让它随着用户的使用越来越快!


























 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









