







Map集合
Map和collection一样,也是java.util包下的一个接口,同样也是一个集合的接口,不同的是Map中存储的元素是以映射键值对的形式存在,将键映射到值的对象,一个映射不能包含重复的键,每个键最多只能映射到一个值。
Map接口下有很多的子类实现了它,最常见的3个子类是HashMap,HashTabel,TreeMap,它们都是实现了Map接口,自己也有自己独特的使用方法,现在我们就来一一介绍。
1.HashMap和HashTabel
它们是基于哈希表的 Map 接口的实现的,所以它元素的排序就是按照哈希表来进行排序的,HashMap后来出现,它的线程是不同步的,而它的映射中允许出现null值;除了非同步和允许使用 null 之外,HashMap 类与 Hashtable 大致相同。
//用一个实例来说明一下
class demo01
{
public static void main(String[] args)
{
//创建了一个HashMap对象
HashMap<students,String> ha =
new HashMap<students,String>();
ha.put(new students("brm",12),"beijing");//往里面添加元素
ha.put(new students("arm",19),"shanghai");
ha.put(new students("crm",16),"guangzhou");
ha.put(new students("zrm",10),"shenzhen");
/* //用了keySet方法进行遍历集合
Set<students> se = ha.keySet();
Iterator<students> it = se.iterator();
while(it.hasNext())
{
students s = it.next();
//String key = s.toString();
String value = ha.get(s);
sop(s+"--"+value);
}
*/
//用了entrySet方法进行遍历集合
//获得一个Set集合
Set<Map.Entry<students,String>> sa = ha.entrySet();
//获得Set集合的迭代器
Iterator<Map.Entry<students,String>> it = sa.iterator();
while(it.hasNext())
{
//获得Map.Entry的对象
Map.Entry<students,String> s = it.next();
students key = s.getKey(); //getKey获取键
String value = s.getValue();//getValue获取值
sop(key+"--"+value);//输出键和值
}
}
//打印
public static void sop(Object obj)
{
System.out.println(obj);
}
}
//创建了一个学生类
class students
{
private String name;
private int age;
private String addr;
//构造函数
students(String name,int age)
{
this.name = name;
this.age = age;
}
public void getAddr(String addr)
{
this.addr = addr;
}
public String putAddr()
{
return addr;
}
public String putName()
{
return name;
}
public int putAge()
{
return age;
}
//复写了tostring方法
public String toString()
{
return name+"-toString方法-"+age;
}
}说一下Map集合中元素的迭代,Map集合自身是没有迭代器的,它是通过keyset和entryset两个方法来获取Map集合映射关系的 Set 视图,通过Set集合中的迭代器来获取Map集合中的元素再进行输出。
keyset方法
获取Map集合里面的键集合 存在一个set集合里面(返回一个set)
然后用iterator迭代器一个一个取出 然后用get方法就可以打印出键值
entryset方法
获取的是一个键值对 然后存在set集合里面
存在形式是这样子的 Set《Map.Entry》《键类,键值类》
取出的方法是《Map.Entry》.getKey 《Map.Entry 》 .getValue
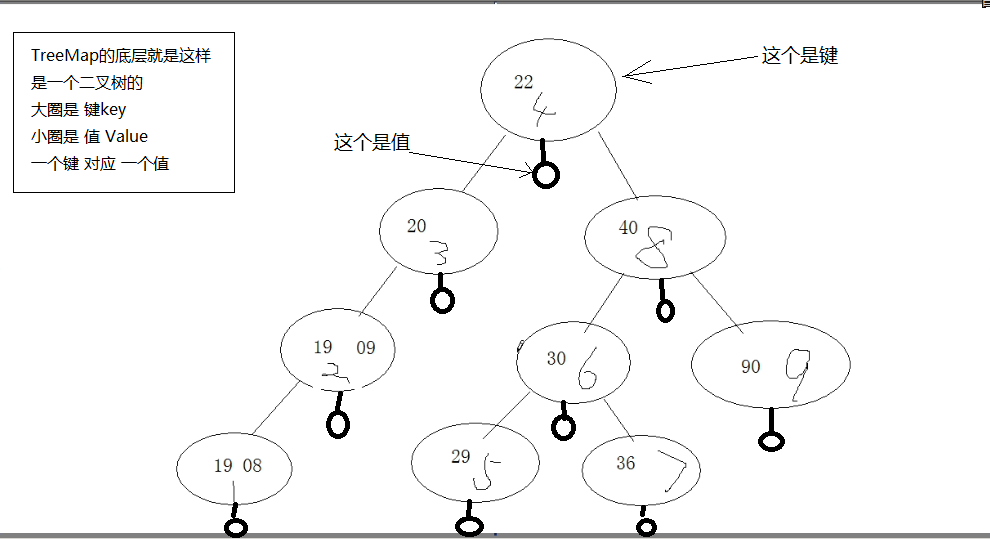
TreeMap集合
TreeMap集合底层是二叉树的,所以TreeMap是根据其键的自然顺序进行排序,或者根据创建映射时提供的 Comparator 进行排序,具体取决于使用的构造方法。TreeMap集合的线程也是不同步的,它映射中的键不能重复,值可以重复。
二叉树的一个原理图:
//用一个小程序来说明
import java.util.*;
class demo02
{
public static void main(String[] args)
{
//创建TreeMap集合
/*TreeMap<students,String> haa =
new TreeMap<students,String>(new TreeMapcompare());
传入了一个TreeMapcompare的比较器进行比较
*/
//对象自身的比较性
TreeMap<students,String> haa = newTreeMap<students,String>();
haa.put(new students("brm",12),"beijing");
//添加元素<学生对象,城市>
haa.put(new students("arm",19),"shanghai");
haa.put(new students("crm",16),"guangzhou");
haa.put(new students("zrm",10),"shenzhen");
//用了keySet方法进行遍历集合
Set<students> se = haa.keySet();
Iterator<students> it = se.iterator();
while(it.hasNext())
{
students s = it.next();
//String key = s.toString();
String value = haa.get(s);
sop(s+"--"+value);
}
}
//打印
public static void sop(Object obj)
{
System.out.println(obj);
}
}
//创建了一个学生类实现了Comparable接口
class students implements Comparable<students>
{
private String name;
private int age;
private String addr;
//复写了compareTo方法
public int compareTo(students s)
{
int num = new Integer(this.age).compareTo(new Integer(s.putAge()));
if(num == 0)
return this.name.compareTo(s.putName());
return num;
}
students(String name,int age)//构造函数
{
this.name = name;
this.age = age;
}
public void getAddr(String addr)
{
this.addr = addr;
}
public String putAddr()
{
return addr;
}
public String putName()
{
return name;
}
public int putAge()
{
return age;
}
public String toString()//复写了tostring方法
{
return name+"-toString方法-"+age;
}
}
//建立自定义的 比较器
class TreeMapcompare implements Comparator<students>
{
public int compare(students s1,students s2)
{
int num = s1.putName().compareTo(s2.putName());
if(num == 0)
return new Integer(s1.putAge()).compareTo(new Integer(s2.putAge()));
return num;
}
}
最后一点要注意的就是:
HashMap集合中是可以有重复元素的;
TreeMap集合中键不可以有重复,值可以重复,键的重复判断是由compareTo方法判断(对象类要先实现Comparable接口),或者是由传入的比较器去判断。















 836
836

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









