







 本文详细解析SecondaryNameNode在Hadoop生态系统中的角色,探讨其如何协助NameNode管理HDFS元数据,包括定期合并编辑日志以优化NameNode性能的过程。
本文详细解析SecondaryNameNode在Hadoop生态系统中的角色,探讨其如何协助NameNode管理HDFS元数据,包括定期合并编辑日志以优化NameNode性能的过程。
SecondaryNameNode
Hadoop中SecondaryNameNode工作机制
首先来看一下HDFS的结构,如下图:
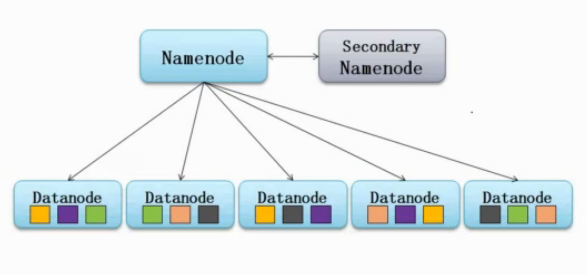
如上图,在HDFS架构中,NameNode是职责是管理元数据信息,DataNode的职责是负责数据存储,那么SecondaryNameNode的作用是什么呢?
其实SecondaryNameNode是hadoop1.x中HDFS HA的一个解决方案,下面我们来看一下SecondaryNameNode工作的流程,如下图:
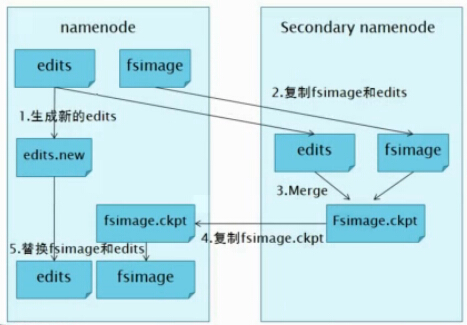
1.NameNode管理着元数据信息,元数据信息会定期的刷到磁盘中,其中的两个文件是edits即操作日志文件和fsimage即元数据镜像文件,新的操作日志不会立即与fsimage进行合并,也不会刷到NameNode的内存中,而是会先写到edits中(因为合并需要消耗大量的资源)。当edits文件的大小达到一个临界值(默认是64MB)或者间隔一段时间(默认是1小时)的时候checkpo
首先来看一下HDFS的结构,如下图:
如上图,在HDFS架构中,NameNode是职责是管理元数据信息,DataNode的职责是负责数据存储,那么SecondaryNameNode的作用是什么呢?
其实SecondaryNameNode是hadoop1.x中HDFS HA的一个解决方案,下面我们来看一下SecondaryNameNode工作的流程,如下图:
1.NameNode管理着元数据信息,元数据信息会定期的刷到磁盘中,其中的两个文件是edits即操作日志文件和fsimage即元数据镜像文件,新的操作日志不会立即与fsimage进行合并,也不会刷到NameNode的内存中,而是会先写到edits中(因为合并需要消耗大量的资源)。当edits文件的大小达到一个临界值(默认是64MB)或者间隔一段时间(默认是1小时)的时候checkpo
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 2956
2956

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









