







反射
反射主要是指程序可以访问、检测和修改它本身的状态或行为的一种能力。这一概念的提出很快引发了**计算机科学领域**关于反射性的研究。它首先被程序语言的设计领域所采用,并在LISP和面向对象方面取得了成绩,其中LEAD/LEAD++、OpenC++、MetaXa和OpenJava等就是基于反射机制的语言。最近,反射机制也被应用到了视窗系统、操作系统和文件系统中。
反射本身并不是一个新概念,它可能会被联想到光学中的反射,尽管计算机科学赋予了反射概念新的含义,但是,从现象上老说,它们确实有些想通之处。在计算机科学领域,反射是指一类应用,它们能够自描述和自控制。也就是说,这类应用通过采用某种机制来实现对自己行为的描述和检测,并能根据自身行为的状态和结果,调整或修改应用所描述行为的状态和相关的语义。可以看出,与一般的反射概念相比,计算机科学领域的反射不单单指反射本身,还包括对反射结果所采取的措施。所有采用反射机制的系统都具有开放性,但具有开放性的系统并不一定采用了反射机制,开放性是反射系统的必要条件。一般来说,反射系统除了满足开放性条件外,还必须满足原因连接。所谓原因连接,是指对反射系统自描述的改变能够立即反映到系统底层的实际状态和行为上的情况,反之亦然。开放性和原因连接是反射系统的两大基本要素。
Java中的反射是一种强大的工具,它能够创建灵活的代码,这些代码可以在运行时装配,无须在组件之间进行链接。反射允许在编写与执行时,使成宿代码能够接入装载到JVM中的类的内部信息,而不是源代码中选定的类协作的代码。这使反射成为构建灵活应用的主要工具。如果使用不当,反射的成本会很高。
Java中传递参数到底是传值还是传引用
不管Java参数的类型是什么,一律传递参数的副本。thinking in java解释到:When you are passing primitives into a method,you get a distinct copy of the primitive. When you are passing a reference into a method,you get a copy of the reference.(如果Java是传值,那么传递的值的副本;如果Java是传引用,那么传递的是引用的副本)。
在Java中,变量氛围以下两类:
1. 对于基本类型变量,Java是传值的副本
2. 对于一切对象型变量,Java都市传引用的副本。其实,传引用副本的实质就是复制指向地址的指针,只不过Java不像C++中有显著的*和&符号。(C++中,当参数是引用类型时,传递的是真实引用而不是引用副本)
对基本类型而言,传值就是把自己复制一份传递,即使自己的副本变了,自己也不变;而对于对象类型而言,它传递的是引用副本,指向自己的地址,而不是自己实际值的副本。为什么要这么做呢?因为对象类型是放在堆里的,一方面,速度相对于基本类型比较慢,另一方面,对象类型本身比较大,如果采用重新复制对象值的办法,浪费内存且速度又慢。举个栗子:张三(张三相当于函数)打开仓库并检查库里面的货物(仓库相当于地址),有必要新建一座仓库(并放入想通货物)给张三吗?没有必要,你只需要把要是(引用)复制一把寄给张三就行了,张三会拿备用钥匙(引用副本,但是有时效性,函数结束,钥匙销毁)打开仓库。
“不管是基本类型还是对象类型,都是传值”----结论。这种说法没错,但理解起来有点牵强。
1. 基本类型
public static void main(String[] args) {
boolean test = true;
System.out.println("one:"+test);
test(test);
System.out.println("three:"+test);// three:true
}
public static void test(boolean test ) {
test = !test;
System.out.println("two:"+test); // two:false
}虽然在test(boolean)方法中改变了传进来的参数值,但对这个参数源本身并没有影响,即对main(String[])方法中的test变量没有影响,说明参数类型是简单类型的时候,是按值传递的。实际上传递的是值的副本,副本变化对源变量无影响(相当于有两个变量)。
2. 引用类型
public static void main(String[] args) {
StringBuffer str = new StringBuffer("Hello");
test(str);
System.out.print("在test方法里修改内容之后:"+str); // 在test方法里修改之后:Hello, Jerry
}
static void test(StringBuffer str) {
str.append(", Jerry");
}类似于:王五在一个粮仓放了200斤粮食,张三拿钥匙的副本取走了100斤。当王五在来的时候,库存就变为100斤了(即使王五没动过粮仓)。
3. 加点小难度
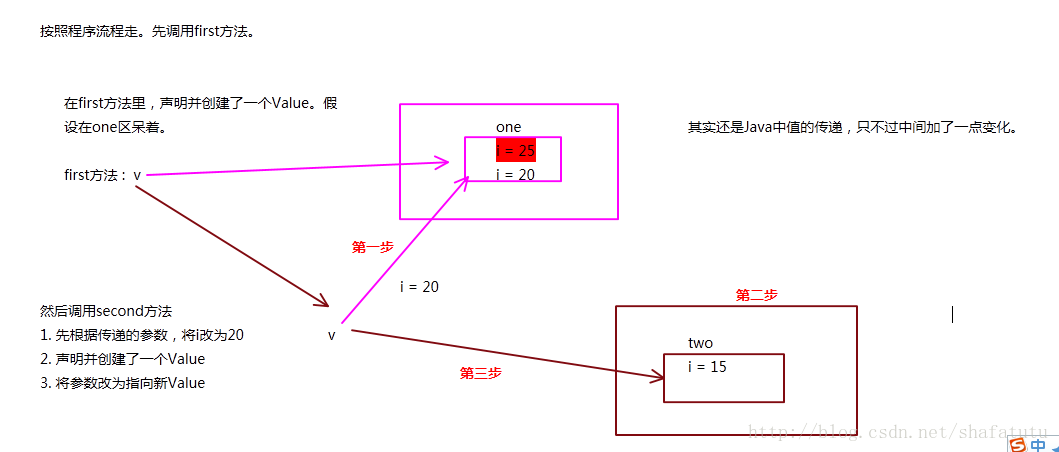
class Value{
public int i = 15;
}
public class One {
public static void main(String[] args) {
One o = new One();
o.first();
}
public void first() {
int i = 5;
Value v = new Value();
v.i = 25;
second(v,i);
System.out.println("first方法里:"+v.i+","+i); // 25 被阴了!!!(Right 20)
}
public void second(Value v, int i) {
i = 0;
v.i = 20;
Value val = new Value();
v = val;
System.out.println("second方法里:"+v.i+", "+i); // 15, 0
}
}
序列化
对象序列化能实现”轻量级额的persistence (lightweight persistence)”。所谓persistence,是指对象的生命周期不是由程序是否运行决定的,在程序的两次调用之间对象仍然还活着。通过“将做过序列化处理的对象写入磁盘,等到程序再次运行的时候再把它读出来”,可以达到persistence的效果。之所以说“轻量级”,是因为不能用像“persistent”这样的关键词来直接定义一个对象,然后让系统去处理所有的细节(将来可能会这样,越来越智能)。相反,必须明确地进行序列化和解序列化。
对象序列化不仅能保存对象的副本,而且还会跟着对象中的reference把它所引用的对象也保存起来,然后再继续跟踪那些对象的reference,以此类推。这种情形唱被称为“单个对象所联接的’对象网’”。这个机制所覆盖的范围不仅包括对象的成员数据,而且还包含数组里面的reference。如果要自己实现对象序列化,那么编写跟踪这些链接的程序将会是一件非常痛苦的任务。但是,Java的对象序列化就能精确无误地做到这一点,毫无疑问,它的遍历算法是做过优化的。














 850
850











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









