







1. CABAC上下文模型
1.1. MCoder
如第二章所述,算术编码一般采用区间递归分隔的方法来进行。在CABAC的二值化算术编码中,区间使用区间的左端点L和区间的长度R两个变量来表示。则:
RLPS = pLPS* R (8)
其中,pLPS表示LPS符号出现的概率,RLPS表示LPS符号对应的区间,与此相反MPS符号对应的区间大小为:
RMPS = R - RLPS (9)
假设二进制串b= (b1,b2,b3,…,bN),其中bi∈{LPS,MPS},LPS和MPS对应着0或者1。经过N此递归分隔后对应着区间[L(N),L(N) + R(N)),在这个区间中选择一个具有最少二进制串表示的值作为最终的二进制算术编码值。如第二章所讲由于寄存器精度有限,在编码过程中,将移出寄存器的高位,同时当编码区间R小于某个阈值时将对区间进行缩放。
1.1.1. 概率转移
从效率方面来考虑,在实际实现过程中,没有采用如上所示的乘法操作,而是采用了基于查表操作的区间分隔算法。在H264/AVC和HEVC中将区间长度R量化为4个子区间,在进行区间划分时将2^8~2^9 即256-512之间分为4份(当区间大小小于256时进行下溢处理,进行区间缩放后的范围仍然将会在2^8~2^9之间),取每部分中间部分,如下所示,
第一部分RQ0:287= 1 00 011111;
第二部分RQ1:351= 1 01 011111;
第三部分RQ2:415= 1 10 011111;
第四部分RQ3:479= 1 11 011111;
LPS的概率pLPS将根据公式(10)量化为64个不同的概率状态,根据公式计算出的pLPS和转移规律如表3-1所示,其中transIdxMps表示当MPS位出现时的状态转移,transIdxLps表示当LPS字符出现时的状态转移。

表3-1概率转移表
| σ | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| pLPS | 0.5 | 0.474609 | 0.450507 | 0.427629 | 0.405912 | 0.385299 | 0.365732 | 0.347159 | 0.32953 | 0.312795 | 0.296911 | 0.281833 | 0.26752 | 0.253935 | 0.241039 | 0.228799 |
| transIdxLps | 0 | 0 | 1 | 2 | 2 | 4 | 4 | 5 | 6 | 7 | 8 | 9 | 9 | 11 | 11 | 12 |
| transIdxMps | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 | 16 |
| σ | 16 | 17 | 18 | 19 | 20 | 21 | 22 | 23 | 24 | 25 | 26 | 27 | 28 | 29 | 30 | 31 |
| pLPS | 0.21718 | 0.206151 | 0.195682 | 0.185744 | 0.176312 | 0.167358 | 0.158859 | 0.150792 | 0.143134 | 0.135866 | 0.128966 | 0.122417 | 0.1162 | 0.110299 | 0.104698 | 0.099381 |
| transIdxLps | 13 | 13 | 15 | 15 | 16 | 16 | 18 | 18 | 19 | 19 | 21 | 21 | 22 | 22 | 23 | 24 |
| transIdxMps | 17 | 18 | 19 | 20 | 21 | 22 | 23 | 24 | 25 | 26 | 27 | 28 | 29 | 30 | 31 | 32 |
| σ | 32 | 33 | 34 | 35 | 36 | 37 | 38 | 39 | 40 | 41 | 42 | 43 | 44 | 45 | 46 | 47 |
| pLPS | 0.094334 | 0.089543 | 0.084996 | 0.08068 | 0.076583 | 0.072694 | 0.069002 | 0.065498 | 0.062172 | 0.059014 | 0.056018 | 0.053173 | 0.050473 | 0.047909 | 0.045476 | 0.043167 |
| transIdxLps | 24 | 25 | 26 | 26 | 27 | 27 | 28 | 29 | 29 | 30 | 30 | 30 | 31 | 32 | 32 | 33 |
| transIdxMps | 33 | 34 | 35 | 36 | 37 | 38 | 39 | 40 | 41 | 42 | 43 | 44 | 45 | 46 | 47 | 48 |
| σ | 48 | 49 | 50 | 51 | 52 | 53 | 54 | 55 | 56 | 57 | 58 | 59 | 60 | 61 | 62 | 63 |
| pLPS | 0.040975 | 0.038894 | 0.036919 | 0.035044 | 0.033264 | 0.031575 | 0.029972 | 0.02845 | 0.027005 | 0.025633 | 0.024332 | 0.023096 | 0.021923 | 0.02081 | 0.019753 | 0.01875 |
| transIdxLps | 33 | 33 | 34 | 34 | 35 | 35 | 35 | 36 | 36 | 36 | 37 | 37 | 37 | 38 | 38 | 63 |
| transIdxMps | 49 | 50 | 51 | 52 | 53 | 54 | 55 | 56 | 57 | 58 | 59 | 60 | 61 | 62 | 62 | 63 |
若当前概率状态为σ,且当前待编解码的二进制符号为MPS,当前概率状态将转化为transIdxMps[σ],若前待编解码的二进制符号为LPS,当前概率状态将转化为transIdxLps[σ],从状态转移表可以看出:若当前编码比特为MPS符号,更新后的概率索引值变大,说明下一个符号是MPS的概率变大。当概率模型变量σ为0时,说明MPS和LPS的概率相同,若下一次再出现LPS符号,则MPS和LPS符号将互换。
由于区间长度R被量化为4个子区间,符号的概率值pLPS被量化为64个状态σ,那么公式(8)将被量化为一个4×64的表格TabRangeLPS(将表格大小定为256字节主要是从内存访问等访问的限制考虑)。编解码过程中通过预先计算好状态转移表3-1和TabRangeLPS表3-2进行状态转移,减少编解码过程中的乘法运算。
将pLPS值与量化后的4个区间长度值RQi相乘,即可算出rangeTabLps表中对应的ρi。如表3-2所示,由于一共有64个状态太占用空间,这里只列出了21个元素。从表3-2可以看出,前16个元素的RQ量化值会发生变化,而从第17个元素值开始RQ将保持稳定,目前还没有找出量化RQ的公式。
表3-2 编码区间索引表rangeTabLps(只列出了前21个状态)
| σ | pLPS | RQ0 | RQ1 | RQ2 | RQ3 | ρ0 | ρ1 | ρ2 | ρ3 |
| 0 | 0.5 | 256 | 352 | 416 | 480 | 128 | 176 | 208 | 240 |
| 1 | 0.474609 | 270 | 352 | 415 | 478 | 128 | 167 | 197 | 227 |
| 2 | 0.450507 | 284 | 351 | 415 | 479 | 128 | 158 | 187 | 216 |
| 3 | 0.427629 | 288 | 351 | 416 | 479 | 123 | 150 | 178 | 205 |
| 4 | 0.405912 | 286 | 350 | 416 | 480 | 116 | 142 | 169 | 195 |
| 5 | 0.385299 | 288 | 350 | 415 | 480 | 111 | 135 | 160 | 185 |
| 6 | 0.365732 | 287 | 350 | 416 | 478 | 105 | 128 | 152 | 175 |
| 7 | 0.347159 | 288 | 351 | 415 | 478 | 100 | 122 | 144 | 166 |
| 8 | 0.32953 | 288 | 352 | 416 | 479 | 95 | 116 | 137 | 158 |
| 9 | 0.312795 | 288 | 352 | 416 | 480 | 90 | 110 | 130 | 150 |
| 10 | 0.296911 | 286 | 350 | 414 | 478 | 85 | 104 | 123 | 142 |
| 11 | 0.281833 | 287 | 351 | 415 | 479 | 81 | 99 | 117 | 135 |
| 12 | 0.26752 | 288 | 351 | 415 | 478 | 77 | 94 | 111 | 128 |
| 13 | 0.253935 | 287 | 350 | 413 | 480 | 73 | 89 | 105 | 122 |
| 14 | 0.241039 | 286 | 353 | 415 | 481 | 69 | 85 | 100 | 116 |
| 15 | 0.228799 | 288 | 350 | 415 | 481 | 66 | 80 | 95 | 110 |
| 16 | 0.21718 | 287 | 351 | 415 | 479 | 62 | 76 | 90 | 104 |
| 17 | 0.206151 | 287 | 351 | 415 | 479 | 59 | 72 | 86 | 99 |
| 18 | 0.195682 | 287 | 351 | 415 | 479 | 56 | 69 | 81 | 94 |
| 19 | 0.185744 | 287 | 351 | 415 | 479 | 53 | 65 | 77 | 89 |
| 20 | 0.176312 | 287 | 351 | 415 | 479 | 51 | 62 | 73 | 84 |
1.1.2. 重归一化
HEVC采用了10bits进行算术编码,表3-2 rangeTabLps表中量化后的子区间表示的是RLPS,如果经过区间划分后新区间RLPS的长度不在2^8~2^9 即256~512之间就需要进行重归一化操作(算术编码为10bits时,high的最大值为1024,mid即为512,L对应于low,R对应于high-low)。从第二章第三节可以知道重归一化操作分为三类,图7展示了编码端的重归一化流程图:
1) low>=mid,也就是L>=512时,high也大于512,此时low和high的最高位相同都为1,可以将1移出寄存器;
2) low<1/4full range=256时,high=low+range,因为low和range都小于256,因此high<mid,此时,low和high都有相同的最高位0,可以将0移出寄存器;
3) low∈[1/4 full range,1/2 full range),high∈[1/4 full range,3/4 full range)时,此时编码区间[low, high)可能在[256, 512)区间内,也有可能在[256, 768)之间。low和high的最高位可能相同都是01,也有可能不同low是01,high是10,无法将二进制比特输出到码流中,将按照第二章第三节重归一化中的第三种方式进行下溢处理(抛弃次高位,记录下溢比特数)。
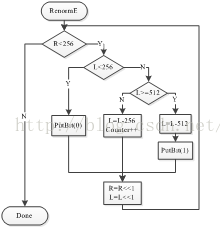
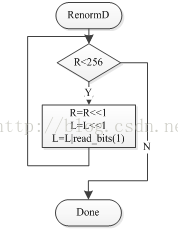
图7 编码端重归一化流程图 图8 解码段重归一化流程图
解码时不需要和编码一样进行复杂的操作,只需要对R和L进行移位,直到R>=256时停止,在实现通过查表获得使R>=256所需的移位位数,一步到位,无需循环判断。
在图7的编码过程中调用了PutBit子过程,该过程的主要作用是输出特定比特B,并根据是否下溢输出Counter个下溢的比特1-B,如图9所示。同时PutBit子过程不会编码第一个比特,在CABAC初始化时,以[0,210)表示浮点区间[0,1),而在初始化区间时R=510和L=0,相当于此时已经进行了第一次区间选择,区间为[0,0.5),需要输出“0”,PutBit子过程在这里通过firstBitFlag阻止这个“0”的输出,如此才能得到正确的算术编码结果。
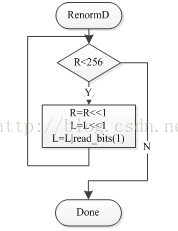
图9 PutBit子过程
1.1.3. 概率模型初始化
在编解码第一个二进制符号前,需要对相应语法元素初始化上下文概率模型,HEVC为每一个上下文模型索引分配了一个初始值initValue,通过initValue来计算该语法元素的初始状态σ(公式中用pStateIdx表示)和MPS符号(公式中用valMps表示),如下所示:
slopeIdx = initValue >> 4;
offsetIdx = initValue & 15;
m = slopeIdx * 5 – 45;
n = (offsetIdx << 3) – 16;
preCtxState = Clip3( 1, 126, ( (m * Clip3( 0, 51, SliceQpY ) ) >> 4 ) + n );
valMps = ( preCtxState <= 63 )? 0 : 1;
pStateIdx = valMps ? (preCtxState − 64 ) : ( 63 − preCtxState )。
初始化完成后即可根据待编码的二进制符号串和表3-1进行概率状态转移。而在H264中参数m和n是直接给定的,所以只需要执行最后三句话即可完成概率状态的初始化操作。
1.1.4. 常规编解码
编码过程中,输入值是上下文模型变量和待处理的binVal值,状态是当前编码区间R、区间下限L和概率状态σ,如图10所示为编码流程图。
首先计算区间索引ρ,如公式(11)所示,可以发现公式先对R右移6位,再和3相与,四个子区间的划分287= 1 00011111、351= 1 01 011111、415=1 10 011111和479=1 11 011111按照公式(11)的方式计算后将会得到00、01、10和11四个索引值。

其次,如果当前二进制符号binVal是MPS,则MPS的编码区间 作为下一个二进制符号的编码区间R,区间下限L不变;如果当前二进制符号是LPS,则LPS的区间 作为下一个二进制符号的编码区间R,区间下限L增加 ,如果概率状态σ为零,则互换LPS和MPS。
最后按照表格3-1进行状态转移和归一化。
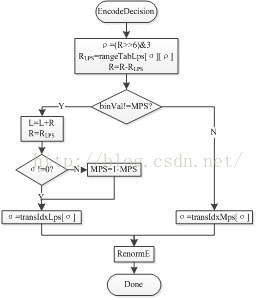
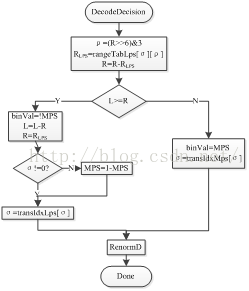
图10. 常规编码流程图 图11. 常规解码流程图
解码流程如图11所示,其和编码流程几乎一样,主要的不同点在于:编码时是对二进制进行编码,所以需要判断二进制符号是MPS还是LPS,而解码时候需要根据当前的RMPS (RMPS=R - RLPS)区间和区间下限L的关系,判断当前是在MPS符号的区间还是在LPS符号的区间,进而解码出二进制符号。
1.1.5. 旁路编解码
对概率分布比较均匀(概率为1/2左右)的语法元素,HEVC采用旁路编码模式。旁路编码模式无需进行概率更新,同时为了降低计算复杂度,采用了保持编码区间R不变,使区间下限L加倍的方法来实现区间划分(如果使用和常规编码一样的区间划分方法的话,还需要进行区间缩放等操作,计算复杂度会高一些),降低计算复杂度,旁路编码流程如图12所示。
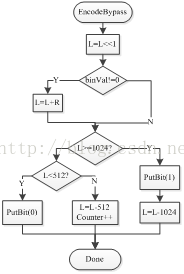
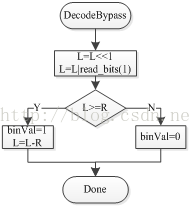
图12. 旁路编码流程图 图13. 旁路解码流程图
在图12的编码路程图中包含了编码部分也包含了重归一化部分,其原理和常规编码的重归一化原理一样。由于对L进行了左移一位的操作,因此判断时将常规编码中的256和512变大为了512和1024。图13显示了旁路解码流程图。
1.1.6. 终止符编解码
在状态转移表3-1中,状态σ=63是终止符的保留状态。σ=63时RLPS = 2,所以,针对具有终止含义的语法元素,如:end_of_slice_segment_flag、end_of_sub_stream_one_bit或者pcm_flag时流程图如图15所示。在编码过程中有10个比特将被输出,如图16所示。由于在算术编解码的常规编解码中R最大值为510,需要9个比特表示,L最大值1024需要10个比特(Bypass编解码过程中L可以大于1024,编码过程结束后会在正常范围内),为了保证编解码过程的正确性,需要将10个比特表示的L全部都写入到码流中。因此当编码终止符时,首先设置RLPS = 2,借助重归一化过程可以将L的高7位写入到码流中(当RLPS >= 256时重归一化过程将终止, RLPS = 2时左移7位即可使RLPS >= 256),此时L中还剩下3个比特没有写入到码流中,首先通过PutBit((L>>9)&1)将原始L中的第3位(二进制串按照从右往左的顺序计数)输出(在重归一化过程中,L将要左移7位,此时L的低7位将被0填充,因此原始的L中的低3位将变成新L的高3位,如图16所示,因此通过(L>>9)&1即可获取原始L的第3位,同时在重归一化过程中可能会有下溢存在,因此使用PutBit可能处理下溢的情况),其次通过WriteBits输出低2位到码流中。
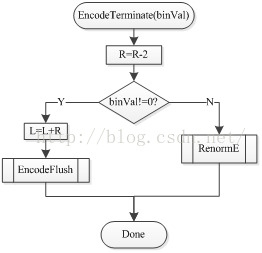
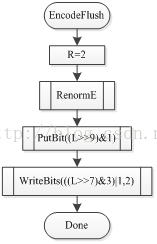
图14终止符编码流程图 图15 输出最后10比特流程图
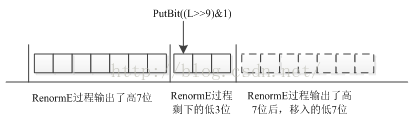
图16 输出最后三比特示意图














 2721
2721











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









