







一.查找及其相关概念
查找,就是根据给定的某个值,在查找表中确定一个关键字等于数据值的数据元素的过程
查找表按操作方式可分为两种:
静态查找表:只做查找操作的查找表
动态查找表:在查找过程中插入新的数据元素或删除原有的数据元素
二.静态查找的三种具体方式
1.顺序查找算法
顺序查找,也称线性查找,是从第一个元素开始,将后面的每个元素与给定元素进行比对,若相同,则返回该元素;若没有与之相同的元素,返回空
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
代码很简单,调用rand函数是用来随机生成数组索引的
线性查找是最简单的查找方式,但一般来说越简单的东西时间效率往往不会太高,例如简单的冒泡排序。那么我们如何对这个算法进行优化呢?我们注意到在代码中每次for循环中都会进行i是否越界的比较,那么我们可以这样修改
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
这种方法通过在尽头设置哨兵,免去了每次都要判断是否越界的过程,在数据量较大时,这个算法与前一种算法的差异将非常大
顺序查找最后的情况是第一次查找就找到,时间复杂度为O(1),最差为O(n),平均来说,时间复杂度为O(n)
2.二分查找
二分查找要求查找表中的数据的关键码必须有序(通常要按从小到大排列),必须使用线性结构存储;具体思路是,将关键值与中间元素作比较,若大于中间元素,则在右半区中继续查找;若小于中间元素,则在左半区继续查找,直到找到或失败为止
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23

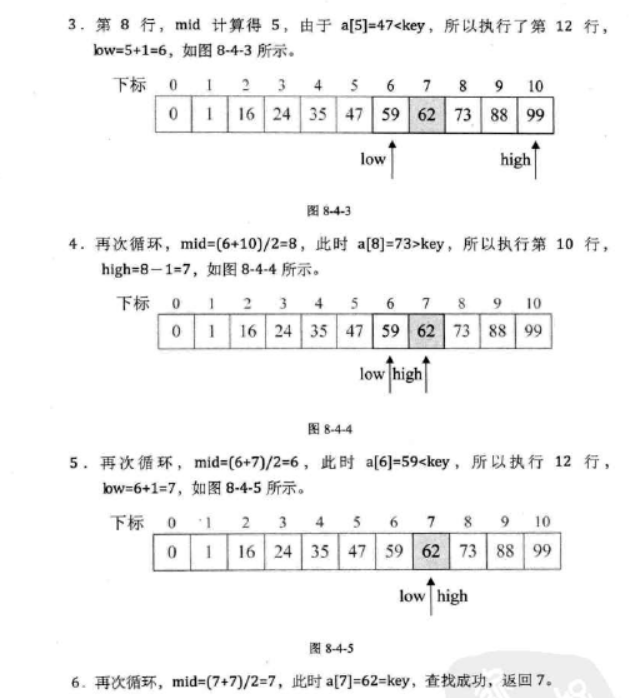
上图清晰地分析了整个算法的执行过程,图片来自《大话数据结构》
3.分块查找
分块查找是顺序查找的一种改进方法。首先需要对数组进行分块,分块查找需要建立一个“索引表”。索引表分为m块,每块含有N/m个元素,块内是无序的,块间是有序的,例如块2中最大元素小于块3中最小元素。
先用二分查找索引表,确定需要查找的关键字在哪一块,然后再在相应的块内用顺序查找。分块查找又称为索引顺序查找。
#include <stdio.h>
#define MAXL 100 //数据表的最大长度
#define MAXI 20 //索引表的最大长度
typedef int KeyType;
typedef char InfoType[10];
typedef struct
{
KeyType key; //KeyType为关键字的数据类型
InfoType data; //其他数据
} NodeType;
typedef NodeType SeqList[MAXL]; //顺序表类型
typedef struct
{
KeyType key; //KeyType为关键字的类型
int link; //指向对应块的起始下标
} IdxType;
typedef IdxType IDX[MAXI]; //索引表类型
int IdxSearch(IDX I,int m,SeqList R,int n,KeyType k)
{
int low=0,high=m-1,mid,i;
int b=n/m; //b为每块的记录个数
while (low<=high) //在索引表中进行二分查找,找到的位置存放在low中
{
mid=(low+high)/2;
if (I[mid].key>=k)
high=mid-1;
else
low=mid+1;
}
//应在索引表的high+1块中,再在线性表中进行顺序查找
i=I[high+1].link;
while (i<=I[high+1].link+b-1 && R[i].key!=k) i++;
if (i<=I[high+1].link+b-1)
return i+1;
else
return 0;
}
int main()
{
int i,n=25,m=5,j;
SeqList R;
IDX I= {{14,0},{34,5},{66,10},{85,15},{100,20}};
KeyType a[]= {8,14,6,9,10,22,34,18,19,31,40,38,54,66,46,71,78,68,80,85,100,94,88,96,87};
KeyType x=85;
for (i=0; i<n; i++)
R[i].key=a[i];
j=IdxSearch(I,m,R,n,x);
if (j!=0)
printf("%d是第%d个数据\n",x,j);
else
printf("未找到%d\n",x);
return 0;
}














 7108
7108

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









