










RLP(Recursive Length Prefix) 递归长度前缀编码是以太坊中最常使用的序列化格式方法。到处都在使用它,如区块、交易、账户、消息等等。RLP 旨在成为高度简约的序列化方法,唯一目标就是存储嵌套的字节数组。 不同于protobuf、BSON和其他序列化方法,RLP 不企图定义任何特定数据类型,如布尔值、浮点数、双精度数,甚至是整数。 相反,RLP 只是以嵌套数组形式存储结构型数据,由上层协议来确定数组的含义。
以太坊中的序列化算法并没有使用已有的 protobuf 或 BSON,这是因为 RLP 编码更容易实现,并且可确保字节操作的完全一致性。许多编程语言中键/值字典没有明确的排序,浮点格式有许多特殊情况,可能导致相同的数据却又不同的编码结果,导致出现不一致的哈希值。以太坊自行开发RLP 编码,可以确保在设计这些协议时更牢记这些目标。
协议定义


下图则是公式的图形版:
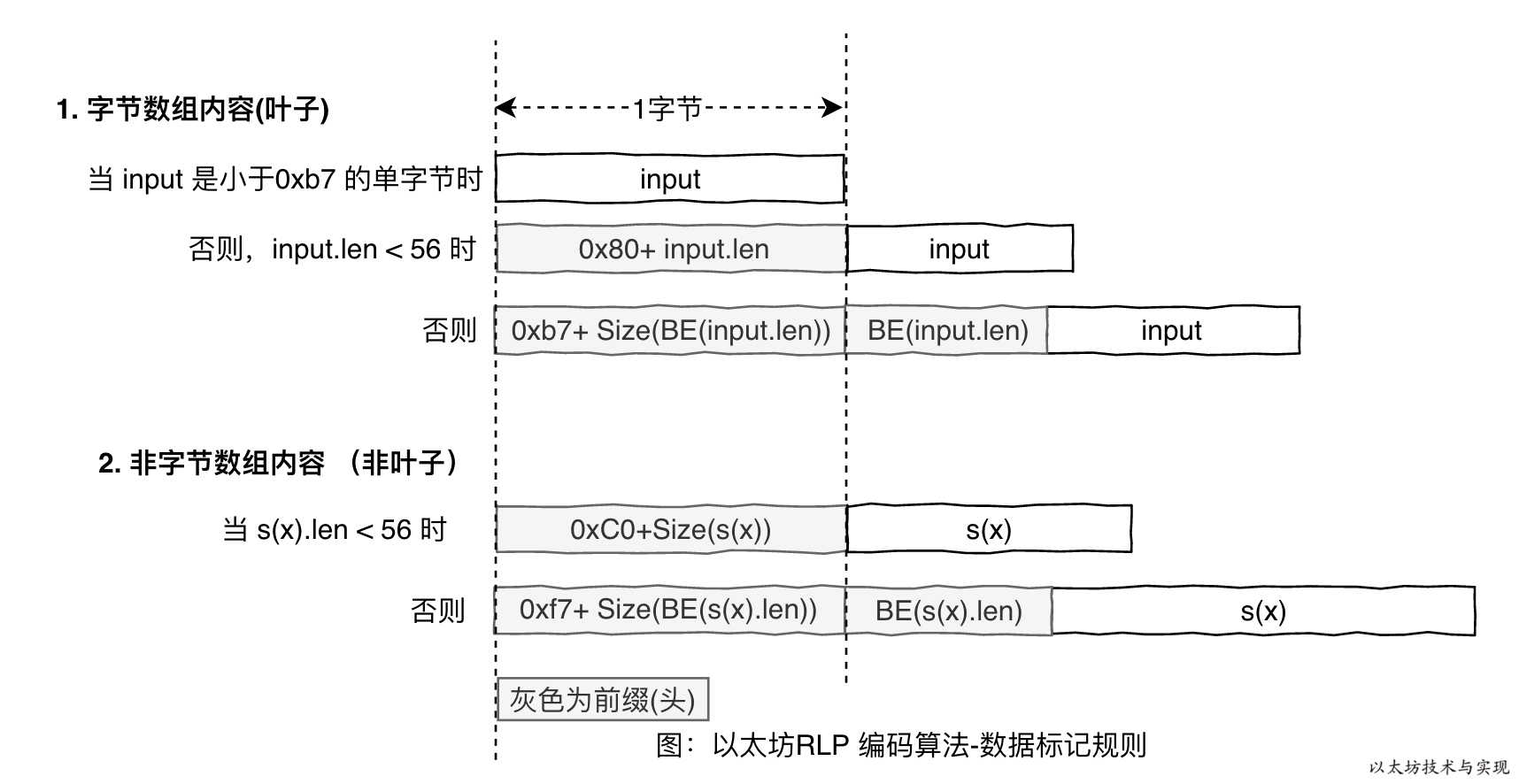
从图中可以看出,不同类型的数据,将有不同的前缀标识。 前缀也可以理解为报文头,通过报文头可准确获取报文内容。 图中灰色部分则为RLP编码输出前缀。
RLP编码示例
根据上面规则,我们可以计算出如下输入的 RLP 编码输出值。
- 字符串 “dog” = [ 0x83, ’d’, ‘o’, ‘g’ ]
- 列表 [ “cat”, “dog” ] = [ 0xc8, 0x83, ‘c’, ‘a’, ’t’, 0x83, ’d’, ‘o’, ‘g’ ]
- 空字符串 (‘null’) = [ 0x80 ]
- 空列表 = [ 0xc0 ]
- 数字 15 (’\x0f’) = [ 0x0f ]
- 数字 1024 (’\x04\x00’) = [ 0x82, 0x04, 0x00 ]
- 空子集合 [ [], [[]], [ [], [[]] ] ] = [ 0xc7, 0xc0, 0xc1, 0xc0, 0xc3, 0xc0, 0xc1, 0xc0 ]
- 字符串 “Lorem ipsum dolor sit amet, consectetur adipisicing elit” = [ 0xb8, 0x38, ‘L’, ‘o’, ‘r’, ‘e’, ’m’, ‘ ‘, … , ‘e’, ‘l’, ‘i’, ’t’ ]
需要清楚的是 RLP 编码时,并不关注结构数据的具体定义,均会被转换为一个嵌套型字节数组拼接处理。 比如,我们定义如下结构。
type Entity struct {
AccountNonce uint64
Price *big.Int
Payload []byte
S *big.Int
More struct {
CreateTime uint64
Remark string
}
}在进行 RLP 编码时,该结构体等同于字节数组:[AccountNonce, Price,Payload,S ,[CreateTime, Remark ]]。 下面,我们写一段代码来展示RLP 过程。
package main
import (
"fmt"
"math/big"
"os"
"github.com/ethereum/go-ethereum/common"
"github.com/ethereum/go-ethereum/rlp"
)
func toBig(v string) *big.Int {
b, ok := new(big.Int).SetString(v, 10)
if !ok {
panic("bad big.Int string")
}
return b
}
func main() {
items := []interface{}{
uint64(333013),
common.FromHex("0xfb8f2d4ae37582cb7ae307196d6e789b7f8ccb665d34ac77000000000"),
toBig("37788494754494904754064770007423869431791776276838145493898599251081614922324"),
[]interface{}{
uint64(131231012),
"交易扩展信息",
},
}
b, err := rlp.EncodeToBytes(items)
if err != nil {
fmt.Println(err)
os.Exit(1)
}
fmt.Println("RLP编码输出:\n", common.Bytes2Hex(b))
for i, v := range items {
b, err := rlp.EncodeToBytes(v)
if err != nil {
fmt.Println(err)
os.Exit(1)
}
fmt.Printf("items[%d]=RLP(%v)=%s\n", i, v, common.Bytes2Hex(b))
if list, ok := v.([]interface{}); ok {
for i, v := range list {
b, err := rlp.EncodeToBytes(v)
if err != nil {
fmt.Println(err)
os.Exit(1)
}
fmt.Printf("\t\t [%d]=RLP(%v)=%s\n", i, v, common.Bytes2Hex(b))
}
}
}
}执行实例,我们可以得到输出结果。分别输出了 items 的 RLP 编码结构以及 items 中所有元素单独的RLP 编码结果。
RLP编码输出:
f85c830514d59d0fb8f2d4ae37582cb7ae307196d6e789b7f8ccb665d34ac77000000000a0538b87b3af985c8f03a7bd0785ef8d087f833a1a56312ce3c67d40b292d51254d88407d26d2492e4baa4e69893e689a9e5b195e4bfa1e681af
items[0]=RLP(333013)=830514d5
items[1]=RLP([15 184 242 212 174 55 88 44 183 174 48 113 150 214 231 137 183 248 204 182 101 211 74 199 112 0 0 0 0])=9d0fb8f2d4ae37582cb7ae307196d6e789b7f8ccb665d34ac77000000000
items[2]=RLP(37788494754494904754064770007423869431791776276838145493898599251081614922324)=a0538b87b3af985c8f03a7bd0785ef8d087f833a1a56312ce3c67d40b292d51254
items[3]=RLP([131231012 交易扩展信息])=d88407d26d2492e4baa4e69893e689a9e5b195e4bfa1e681af
[0]=RLP(131231012)=8407d26d24
[1]=RLP(交易扩展信息)=92e4baa4e69893e689a9e5b195e4bfa1e681afRLP 编码 items 时,所有元素都可以转换为字节数组。将其元素作为叶子转换为字节数组后,再将各项输出根据子方法2 的规则拼接成最终 RLP 编码结果。
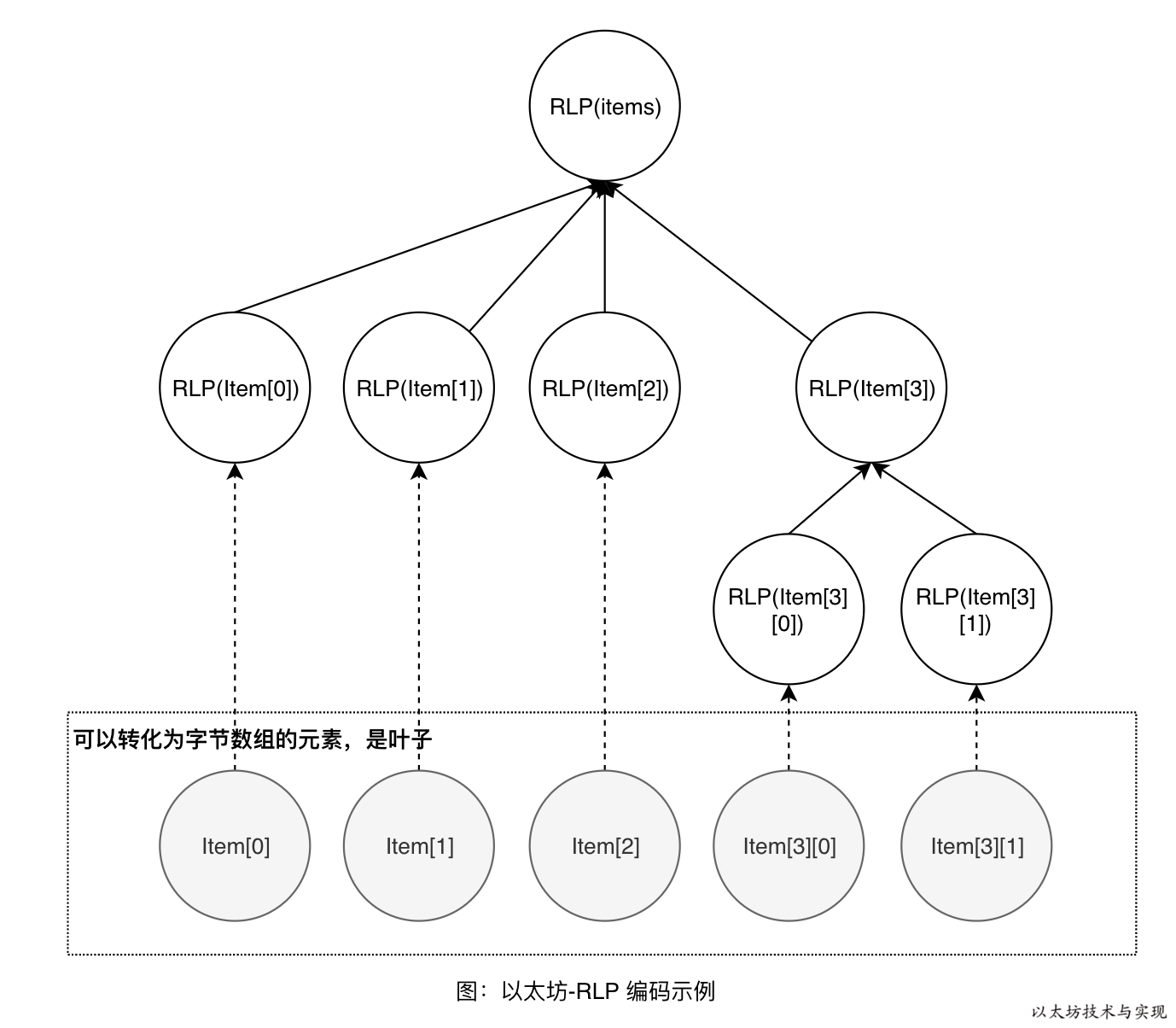
下图是本示例的 RLP 编码计算过程。先依次 RLP 编码 items[0]、items[1]、items[2]和 items[3]。 因为 items[3] 并非字节数组,将使用子方法2处理。
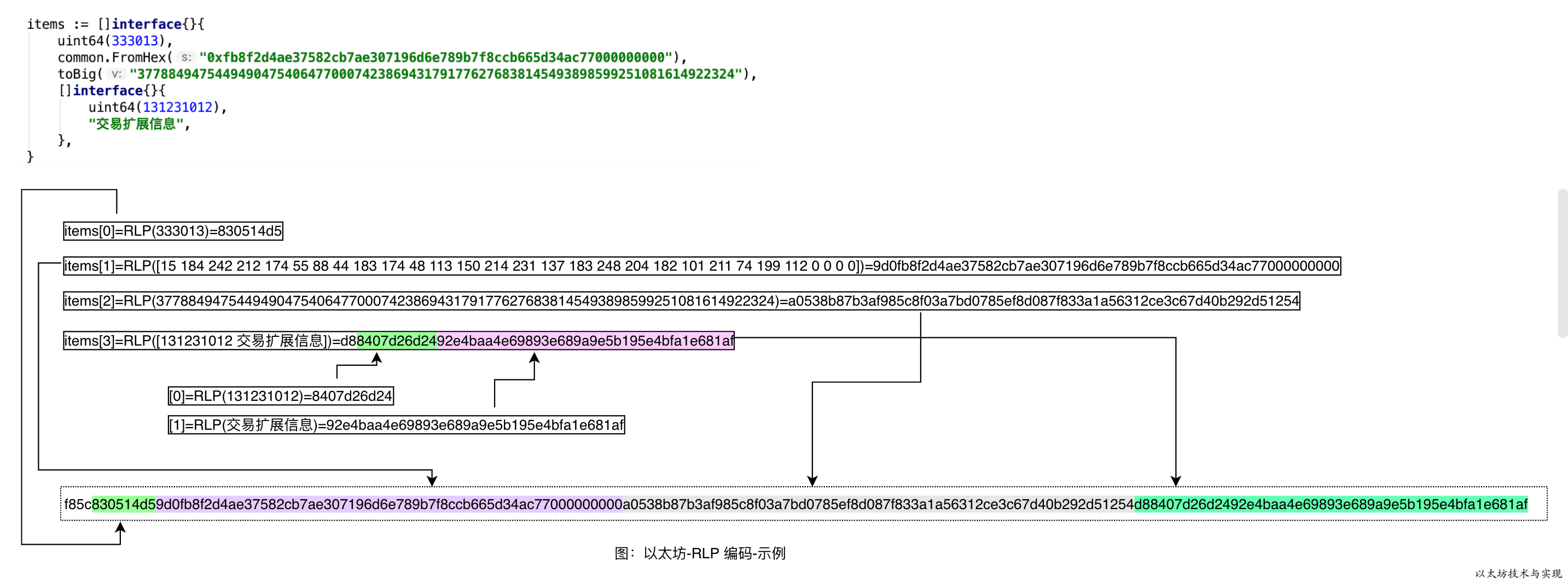
items[3]的两个子项 RLP 拼接后的值为0x8407d26d2492e4baa4e69893e689a9e5b195e4bfa1e681af, 占用 24 字节,因此 items[3] 的前缀为 0xC0+24=0xd8。 而items[0]到 items[3] 的各项 RLP 拼接后的字节数组长度为 占用 92 个字节,因此 items 的前缀为 [0xf7+1,92]。
代码实现
在 go-ethereum 项目中, RLP 的实现在 github.com/ethereum/go-ethereum/rlp 包中,文件结构如下:
rlp
├── decode.go
├── doc.go
├── encode.go
├── raw.go
└── typecache.go- decode.go: RLP 反序列化解码实现
- encode.go: RLP 序列化编码实现
- raw.go: 辅助类
- typecache.go: 类型反射缓存
我们重点关注 encode.go,反向的 decode.go 不进行说明。
首先,RLP 提供三个 API 接口:
- Encode(w io.Writer, val interface{}) error
- EncodeToBytes(val interface{}) ([]byte, error)
- EncodeToReader(val interface{}) (size int, r io.Reader, err error)
允许将符合要求的 val 编码为字节输出或者写入到文件流中。最重要的则是不同类型数据的RLP实现。 go-ethereum 中分别实现了不同数据类型转换为字节数组的函数:
- writeUint
- writeBigInt
- writeBigIntNoPtr
- writeBigIntPtr
- writeBool
- writeByteArray
- writeBytes
- writeRawValue
- writeString
- writeInterface
- writeEncoder
- writeEncoderNoPtr
根据数据的不同类型分别使用对应的转换函数,在 makeWriter 函数中完成转换。
//rlp/encode.go:345
func makeWriter(typ reflect.Type, ts tags) (writer, error) {
kind := typ.Kind()
switch {
case typ == rawValueType:
return writeRawValue, nil
case typ.Implements(encoderInterface):
return writeEncoder, nil
case kind != reflect.Ptr && reflect.PtrTo(typ).Implements(encoderInterface):
return writeEncoderNoPtr, nil
case kind == reflect.Interface:
return writeInterface, nil
case typ.AssignableTo(reflect.PtrTo(bigInt)):
return writeBigIntPtr, nil
case typ.AssignableTo(bigInt):
return writeBigIntNoPtr, nil
case isUint(kind):
return writeUint, nil
case kind == reflect.Bool:
return writeBool, nil
case kind == reflect.String:
return writeString, nil
case kind == reflect.Slice && isByte(typ.Elem()):
return writeBytes, nil
case kind == reflect.Array && isByte(typ.Elem()):
return writeByteArray, nil
case kind == reflect.Slice || kind == reflect.Array:
return makeSliceWriter(typ, ts)
case kind == reflect.Struct:
return makeStructWriter(typ)
case kind == reflect.Ptr:
return makePtrWriter(typ)
default:
return nil, fmt.Errorf("rlp: type %v is not RLP-serializable", typ)
}
}可以看到 RLP 仅只是能转换非负整数的基本数据类型:bool、uint、string、byte、big.Int。 而具体 RLP 编码工作由 encbuf 类实现。
//rlp/encode.go:121
type encbuf struct {
str []byte // 字符串数据,包含列表标题以外的所有内容
lheads []*listhead // 所有列表标题
lhsize int // 所有编码列表标题的大小总和
sizebuf []byte // 9字节辅助缓冲区,用于uint编码
}
func (w *encbuf) reset() {
w.lhsize = 0
if w.str != nil {
w.str = w.str[:0]
}
if w.lheads != nil {
w.lheads = w.lheads[:0]
}
}
// encbuf implements io.Writer so it can be passed it into EncodeRLP.
func (w *encbuf) Write(b []byte) (int, error) {
w.str = append(w.str, b...)
return len(b), nil
}
func (w *encbuf) encode(val interface{}) error {
rval := reflect.ValueOf(val)
ti, err := cachedTypeInfo(rval.Type(), tags{})
if err != nil {
return err
}
return ti.writer(rval, w)
}
func (w *encbuf) encodeStringHeader(size int) {
if size < 56 {
w.str = append(w.str, 0x80+byte(size))
} else {
sizesize := putint(w.sizebuf[1:], uint64(size))
w.sizebuf[0] = 0xB7 + byte(sizesize)
w.str = append(w.str, w.sizebuf[:sizesize+1]...)
}
}
func (w *encbuf) encodeString(b []byte) {
if len(b) == 1 && b[0] <= 0x7F {
// fits single byte, no string header
w.str = append(w.str, b[0])
} else {
w.encodeStringHeader(len(b))
w.str = append(w.str, b...)
}
}
func (w *encbuf) list() *listhead {
lh := &listhead{offset: len(w.str), size: w.lhsize}
w.lheads = append(w.lheads, lh)
return lh
}
func (w *encbuf) listEnd(lh *listhead) {
lh.size = w.size() - lh.offset - lh.size
if lh.size < 56 {
w.lhsize++ // length encoded into kind tag
} else {
w.lhsize += 1 + intsize(uint64(lh.size))
}
}
func (w *encbuf) size() int {
return len(w.str) + w.lhsize
}
func (w *encbuf) toBytes() []byte {
out := make([]byte, w.size())
strpos := 0
pos := 0
for _, head := range w.lheads {
// write string data before header
n := copy(out[pos:], w.str[strpos:head.offset])
pos += n
strpos += n
// write the header
enc := head.encode(out[pos:])
pos += len(enc)
}
// copy string data after the last list header
copy(out[pos:], w.str[strpos:])
return out
}
func (w *encbuf) toWriter(out io.Writer) (err error) {
strpos := 0
for _, head := range w.lheads {
// write string data before header
if head.offset-strpos > 0 {
n, err := out.Write(w.str[strpos:head.offset])
strpos += n
if err != nil {
return err
}
}
// write the header
enc := head.encode(w.sizebuf)
if _, err = out.Write(enc); err != nil {
return err
}
}
if strpos < len(w.str) {
// write string data after the last list header
_, err = out.Write(w.str[strpos:])
}
return err
}该类的设计,主要是存储 RLP 递归编码的树节点内容。同级节点则通过 head 有序排列。
ps: 代码实现的理解并非难事,只有掌握算法协议,则非常容易理解。
在我看你以太坊的 RLP 虽然高效,但是不经济的。所有存储在区块链中的数据应该仅可能少,而 RLP 并没有数据压缩过程。















 1113
1113











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









