







ArrayList
- 数组的实现,连续的存储空间,随机读取快,增删性能差,每次扩容都比较耗性能
LinkedList
- 双向链表实现,随机读取性能不如ArrayList,增删性能好。forEach 读取性能远好for循环,get(index)有个查找过程:
/**
* Returns the (non-null) Node at the specified element index.
*/
Node<E> node(int index) {
// assert isElementIndex(index);
if (index < (size >> 1)) {
Node<E> x = first;//从首链接开始查找
for (int i = 0; i < index; i++)
x = x.next;
return x;
} else {
Node<E> x = last;
for (int i = size - 1; i > index; i--)
x = x.prev;
return x;
}
}
HashTable
鉴于Hashtable是历史遗留的类,现在很少有人使用它,即使我们在对线程安全有要求的场景中,也是通过使用ConcurrentHashMap来解决,而不是使用Hashtable 。这里可以简要的说一下原因:Hashtable使用synchronized来实现线程安全,效率不高,而ConcurrentHashMap采用锁分段技术来实现线程安全,大大提高了效率。在多线程环境中,当A线程访问Hashtable的put方法时,其他线程是不能访问诸如get,clear这些方法的,但是在ConcurrentHashMap中只要保证A线程与B线程不是持有一个段锁,是可以A线程访问put时其他线程同时访问get操作。
SparseArray
-
使用int[]数组存放key,避免了HashMap中基本数据类型需要装箱的步骤,其次不使用额外的结构体(Entry),单个元素的存储成本下降。(变量简写lo:low hi:higher)
-
为什么不用String做key stackoverflow
SparseArray is only a thing when integers are the key. It’s a memory optimization that’s only possible with integer values because you need to binary search the keys. Binary searches on strings are expensive and not well defined (should ‘1’ be less than or greater than ‘a’ or ‘crazy japanese character’?), so they don’t do it.
-
数据量不大,最好在千级以内
key必须为int类型,这中情况下的HashMap可以用SparseArray代替: -
存放key的数组是有序的(二分查找的前提条件)
如果冲突,新值直接覆盖原值,并且不会返回原值(HashMap会返回原值)
如果当前要插入的 key 的索引上的值为DELETE,直接覆盖
前几步都失败了,检查是否需要gc()并且在该索引上插入数据
事实上,SparseArray在进行remove()操作的时候分为两个步骤: -
删除value — 在remove()中处理,数组不会压缩(不像ArrayList的实现,每次都会压缩一次数组)
删除key — 在gc()中处理,注意这里不是系统的 GC,只是SparseArray 的一个方法,remove()中,将这个key指向了DELETED,这时候value失去了引用,如果没有其它的引用,会在下一次系统内存回收的时候被干掉。但是可以看到key仍然保存在数组中,并没有马上删除,目的应该是为了保持索引结构,同时不会频繁压缩数组,保证索引查询不会错位,那么key什么时候被删除呢?当SparseArray的gc()被调用时。 -
size的大小获取,每次都会gc一次
public int size() {
if (mGarbage) {
gc();
}
return mSize;
}
-
总结
了解了SparseArray的实现原理,就该来总结一下它与HashMap之间来比较的优缺点-
优势:
避免了基本数据类型的装箱操作
不需要额外的结构体,单个元素的存储成本更低
数据量小的情况下,随机访问的效率更高 -
有优点就一定有缺点
插入操作需要复制数组,增删效率降低
数据量巨大时,复制数组成本巨大,gc()(非系统gc)成本也巨大
数据量巨大时,查询效率也会明显下降
-
forEach
-
JAVA提供的语法糖,其原理是Iterator实现(反编译后可以看到源码的iterator实现)
-
ArrayList的遍历中for比Iterator快,而LinkedList中却是Iterator远快于for
-
ArrayList是基于索引(index)的数组,索引在数组中搜索和读取数据的时间复杂度是O(1),但是要增加和删除数据却是开销很大的,因为这需要重排数组中的所有数据。
LinkedList的底层实现则是一个双向循环带头节点的链表,因此LinkedList中插入或删除的时间复杂度仅为O(1),但是获取数据的时间复杂度却是O(n)。 明白了两种List的区别之后,就知道,ArrayList用for循环随机读取的速度是很快的,因为ArrayList的下标是明确的,读取一个数据的时间复杂度仅为O(1)。但LinkedList若是用for来遍历效率很低,读取一个数据的时间复杂度就达到了为O(n)。而用Iterator的next()则是顺着链表节点顺序读取数据的效率就很高了
LinkedList
- 底层实现双链表结构,随机读取慢,增删快
- 通过索引获取值需要遍历整个list
Node<E> node(int index) {
// assert isElementIndex(index);
if (index < (size >> 1)) {//index 大于size/2
Node<E> x = first;
for (int i = 0; i < index; i++)//index和存储顺序一致
x = x.next;
return x;
} else {
Node<E> x = last;
for (int i = size - 1; i > index; i--)
x = x.prev;
return x;
}
}
HashMap
- 数组+链表+红黑树(java8优化点)
- HashMap内部是使用一个默认容量为16的数组来存储数据的,而数组中每一个元素却又是一个链表的头结点,所以,更准确的来说,HashMap内部存储结构是使用哈希表的拉链结构(数组+链表),如图:
这种存储数据的方法叫做拉链法
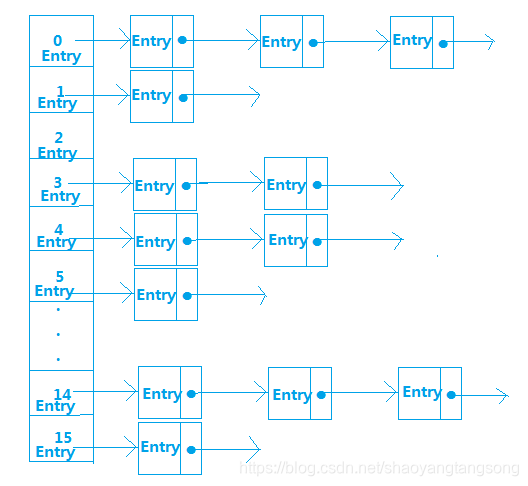
- HashMap中处理hash冲突的方法是链地址法
- put实现
/** * Implements Map.put and related methods * * @param hash hash for key * @param key the key * @param value the value to put * @param onlyIfAbsent if true, don't change existing value * @param evict if false, the table is in creation mode. * @return previous value, or null if none */ final V putVal(int hash, K key, V value, boolean onlyIfAbsent, boolean evict) { Node<K,V>[] tab; Node<K,V> p; int n, i; if ((tab = table) == null || (n = tab.length) == 0) // 空检查 n = (tab = resize()).length; if ((p = tab[i = (n - 1) & hash]) == null) // 不存在,直接插入 // 注意 i = (n - 1) & hash 就是取模定位数组的索引 tab[i] = newNode(hash, key, value, null); else { // 已存在:一模一样的值或者碰撞冲突 Node<K,V> e; K k; if (p.hash == hash && ((k = p.key) == key || (key != null && key.equals(k)))) // 已经存在一个一模一样的值 e = p; else if (p instanceof TreeNode) // 树,略 e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value); else { // 碰撞冲突,顺藤摸瓜挂在链表的最后一个next上 for (int binCount = 0; ; ++binCount) { if ((e = p.next) == null) { p.next = newNode(hash, key, value, null); if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st treeifyBin(tab, hash); break; } if (e.hash == hash && ((k = e.key) == key || (key != null && key.equals(k)))) break; p = e; } } // 注意:if true, don't change existing value if (e != null) { // existing mapping for key V oldValue = e.value; if (!onlyIfAbsent || oldValue == null) e.value = value; afterNodeAccess(e); return oldValue; } } ++modCount; if (++size > threshold) resize(); afterNodeInsertion(evict); return null; } - 数组长度为什么总是设定为 2 的 N 次方?
- 取模快。
其实就是上面为什么快的原因:位与取模比 % 取模要快的多。 - 分散平均,减少碰撞。
这个是主要原因。
如果二进制某位包含 0,则此位置上的数据不同对应的 hash 却是相同,碰撞发生,而 (2^x - 1) 的二进制是 0111111…,分散非常平均,碰撞也是最少的。
-
巧妙的取模
加入数组长度是 n, 如果要对 hash 取模,大家可能想到的解法是:
hash % n
而 HashMap 采用的方法是:// n 是 2 的次方,所以 n - 1 的二进制01111111111…
// hash “与” 01111111111实际上是取保留低位值,结果在 n 的范围之内,类似于取模。
// 还是很巧妙的。
hash & (n - 1) -
HashMap 迭代器实现
HashIterator() {
expectedModCount = modCount;
Node<K,V>[] t = table;
current = next = null;
index = 0;
if (t != null && size > 0) { // advance to first entry
do {} while (index < t.length && (next = t[index++]) == null);
//这段循环的逻辑是找到在table数组中第一个不为null的Node
}
**实现迭代的地方**
final Node<K,V> nextNode() {
Node<K,V>[] t;
Node<K,V> e = next;
if (modCount != expectedModCount)
throw new ConcurrentModificationException();
if (e == null)
throw new NoSuchElementException();
**//如果当前链的next节点已经为空了表示该拉链已经读取完了,则寻找下一个拉链头节点。直到全部读取完成**
if ((next = (current = e).next) == null && (t = table) != null) {
do {} while (index < t.length && (next = t[index++]) == null);
}
return e;
}
LinkedHashMap
-
LinkedHashMap的迭代输出的结果保持了插入顺序,底层又双向链表实现顺序,LRU算法底层是基于LinkedHashMap实现的
-
final boolean accessOrder; //按元素插入顺序(默认)或元素最近访问顺序(LRU)排列
-
重写了HashMap newNode()每次新增节点的时候都会记录它的前后节点
Node<K,V> newNode(int hash, K key, V value, Node<K,V> e) {
LinkedHashMapEntry<K,V> p =
new LinkedHashMapEntry<K,V>(hash, key, value, e);
linkNodeLast(p);
return p;
}
运算符
<< 左移运算符,num << 1,相当于num乘以2 低位补0
>> 右移运算符,num >> 1,相当于num除以2 高位补0
>>> 无符号右移,忽略符号位,空位都以0补齐
% : 模运算 取余
^ : 位异或 第一个操作数的的第n位于第二个操作数的第n位相反,那么结果的第n为也为1,否则为0
& : 与运算 第一个操作数的的第n位于第二个操作数的第n位如果都是1,那么结果的第n为也为1,否则为0
| : 或运算 第一个操作数的的第n位于第二个操作数的第n位 只要有一个是1,那么结果的第n为也为1,否则为0
~ : 非运算 操作数的第n位为1,那么结果的第n位为0,反之,也就是取反运算(一元操作符:只操作一个数)














 3341
3341











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









