







视频方案,雷霄骅的专栏- http://blog.csdn.net/leixiaohua1020
> SI, TI
ITU-R BT.1788建议使用时间信息(TI,Temporal perceptual Information,也可以称时间复杂度)和空间信息(SI,Spatial perceptual Information,也可以称空间复杂度)来衡量视频的特性。
SI表征一帧图像的空间细节量。空间上越复杂的场景,SI值越高。TI表征视频序列的时间变化量。运动程度较高的序列通常会有更高的TI值。
SI计算方法:对第n帧视频进行Sobel滤波,然后对滤波后图像计算标准差。选这些帧中的最大值为SI。TI计算方法:求n与n-1帧图像的帧差,然后对帧差图像计算标准差。选这些帧中的最大值为TI。
-- 视频特性TI(时间信息)和SI(空间信息)
视频特性TI(时间信息)和SI(空间信息)的计算工具:TIandSI-压缩码流版。基于YUV视频数据的TI和SI计算工具:一个图形界面工具和一个命令行工具。
目前的TIandSI项目中一共包含4个项目:
1.TIandSI : 计算YUV数据的TI和SI-图形界面版。
2.TIandSIcmd : 计算YUV数据的TI和SI-命令行版。
3.TIandSIpro : 计算压缩码流数据的TI和SI-图形界面版。
4.TIandSIprocmd : 计算压缩码流数据的TI和SI-命令行版。
每一帧图像的TI(Temporal perceptual Information)信息和SI(Spatial perceptual Information)信息。TI和SI两个指标取自于ITU BT.1788标准。TI越大,代表视频运动剧烈(时间上变化大);SI越大,代表视频内容复杂(空间上纹理多)。
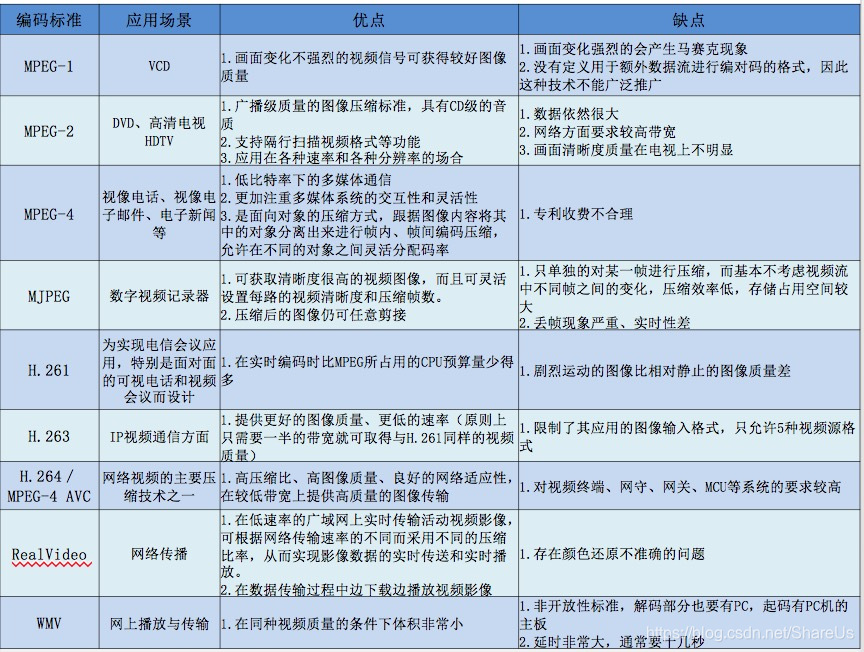
-- 视频格式

> RTMP
RTMP协议是一个互联网TCP/IP五层体系结构中应用层的协议。RTMP协议中基本的数据单元称为消息(Message)。当RTMP协议在互联网中传输数据的时候,消息会被拆分成更小的单元,称为消息块(Chunk)。
RTMP协议中一共规定了十多种消息类型,分别发挥着不同的作用。例如,Message Type ID在1-7的消息用于协议控制,这些消息一般是RTMP协议自身管理要使用的消息,用户一般情况下无需操作其中的数据。Message Type ID为8,9的消息分别用于传输音频和视频数据。Message Type ID为15-20的消息用于发送AMF编码的命令,负责用户与服务器之间的交互,比如播放,暂停等等。消息首部(Message Header)有四部分组成:标志消息类型的Message Type ID,标志消息长度的Payload Length,标识时间戳的Timestamp,标识消息所属媒体流的Stream ID。
RTMP协议中规定,消息在网络上传输时被拆分成消息块(Chunk)。消息块首部(Chunk Header)有三部分组成:用于标识本块的Chunk Basic Header,用于标识本块负载所属消息的Chunk Message Header,以及当时间戳溢出时才出现的Extended Timestamp。
RTMP传输媒体数据的过程中,发送端首先把媒体数据封装成消息,然后把消息分割成消息块,最后将分割后的消息块通过TCP协议发送出去。接收端在通过TCP协议收到数据后,首先把消息块重新组合成消息,然后通过对消息进行解封装处理就可以恢复出媒体数据。
RTMP流媒体到视音频数据开始播放的全过程。
RTMP协议规定,播放一个流媒体有两个前提步骤:第一步,建立一个网络连接(NetConnection);第二步,建立一个网络流(NetStream)。其中,网络连接代表服务器端应用程序和客户端之间基础的连通关系。网络流代表了发送多媒体数据的通道。服务器和客户端之间只能建立一个网络连接,但是基于该连接可以创建很多网络流。
-- RTSP
RTSP(Real-TimeStream Protocol )是一种基于文本的应用层协议。RTSP被用于建立的控制媒体流的传输,它为多媒体服务扮演“网络远程控制”的角色。尽管有时可以把RTSP控制信息和媒体数据流交织在一起传送,但一般情况RTSP本身并不用于转送媒体流数据。媒体数据的传送可通过RTP/RTCP等协议来完成。
> RTMPDump(libRTMP),RTMPdump源代码分析- https://blog.csdn.net/leixiaohua1020/article/list/17
rtmpdump 是一个用来处理 RTMP 流媒体的工具包,支持 rtmp://, rtmpt://, rtmpe://, rtmpte://, and rtmps:// 等。AMF编码广泛用于Adobe公司的Flash以及Flex系统中。由于RTMP协议也是Adobe公司的,所以它也使用AMF进行通信。/*AMF数据采用 Big-Endian(大端模式),主机采用Little-Endian(小端模式) */ 。因为消息(Message)在网络上传播的时候,实际上要分割成块(Chunk)。
rtmpdump 是一个用来处理 RTMP 流媒体的开源工具包,支持 rtmp://, rtmpt://, rtmpe://, rtmpte://, and rtmps://.也提供 Android 版本。rtmpdump 是一个可以通过RTMP协议下载流媒体的工具。
-- 最简单的基于librtmp的示例:接收(RTMP保存为FLV),RTMPDump
最简单的基于librtmp的示例:发布(FLV通过RTMP发布).使用librtmp发布RTMP流的可以使用两种API:RTMP_SendPacket()和RTMP_Write()。
> ffmpeg
-- 使用FFMpeg进行视频编码的主要流程如:
1.首先解析、处理输入参数,如编码器的参数、图像的参数、输入输出文件;
2.建立整个FFMpeg编码器的各种组件工具,顺序依次为:avcodec_register_all -> avcodec_find_encoder -> avcodec_alloc_context3 -> avcodec_open2 -> av_frame_alloc -> av_image_alloc;
3.编码循环:av_init_packet -> avcodec_encode_video2(两次) -> av_packet_unref
4.关闭编码器组件:avcodec_close,av_free,av_freep,av_frame_free
-- FFMpeg解码器的流程与编码器类似,只是中间需要加入一个解析的过程。整个流程大致为:
1.读取码流数据 -> 2.解析数据,是否尚未解析出一个包就已经用完?是返回1,否继续 -> 3.解析出一个包?是则继续,否则返回上一步继续解析 -> 4.调用avcodec_decode_video2进行解码 -> 5.是否解码出一帧完整的图像?是则继续,否则返回上一步继续解码 -> 6.写出图像数据 -> 返回步骤2继续解析。
FFMpeglibavfilter库实际上实现的是视频的滤镜功能,除了水印之外,还可以实现视频帧的灰度化、平滑、翻转、直方图均衡、裁剪等操作。
FFMpeg提供了libswscale库,可以轻松实现视频的分辨率转换功能。除此之外,libswscale库还可以实现颜色空间转换等功能。FFMpeg中libswscale库也是针对AVFrame结构进行缩放处理。视频缩放的主要思想是对视频进行解码到像素域后,针对像素域的像素值进行采样或差值操作
-- 视频信号的表示方法:RGB与YUV。在实际的编解码等视频处理的过程中,YUV格式比RGB格式更为常用。在YUV格式中,一个像素由亮度分量和色度分量表示,每一个像素由一个亮度分量Y和两个色度分量U/V组成。亮度分量可以与色度分量一一对应,也可以对色度分量进行采样,即色度分量的总量少于亮度分量。
-- MPEG到目前为止已经制定并正在制定以下和视频相关的标准:
MPEG-1: 第一个官方的视訊音訊压缩标准,随后在Video CD中被采用,其中的音訊压缩的第三级(MPEG-1 Layer 3)简称MP3, 成为比较流行的音訊压缩格式。
MPEG-2: 广播质量的视訊、音訊和传输协议。被用于無線數位電視-ATSC、DVB以及ISDB、数字卫星电视(例如DirecTV)、 数字有线电视信号,以及DVD视频光盘技术中。
MPEG-3: 原本目标是为高解析度电视(HDTV)设计,随后發現MPEG-2已足夠HDTV應用,故 MPEG-3的研發便中止。
MPEG- 4:2003 年发布的视訊压缩标准,主要是扩展MPEG-1、MPEG-2等標準以支援視訊/音訊物件(video/audio "objects")的編碼、3D內容、低位元率編碼(low bitrate
encoding)和數位版權管理(Digital Rights Management),其中第10部分由ISO/IEC和ITU-T联合发布,称为H.264/MPEG-4 Part 10。参见H.264。
MPEG-7:MPEG-7并不是一个视訊压缩标准,它是一个多媒体内容的描述标准。
MPEG-21:MPEG-21是一个正在制定中的标准,它的目标是为未来多媒体的应用提供一个完整的平台。
> MPEG-1标准
MPEG-1是国际标准化组织ISO下属的移动图像专家组负责制定的早期视频压缩标准,主要用于视频信息的存储、广播电视和网络传输应用。其中在VCD中保存的视频信息便使用MPEG-1标准进行压缩,其码率越为1.2~1.5Mb/s。
-- MPEG-1标准所支持的图像类型与H.263类似,支持I、B、P帧类型:
1.I帧:帧内编码帧,采用帧内编码,可作为P/B帧的参考帧;
2.P帧:前向预测帧,采用帧间编码,以I/P帧作为参考帧;
3.B帧:双向预测帧,参考前后两个方向的参考帧;
> MPEG-2标准
MPEG-2标准是ITU-T和ISO合作制定的编码标准,其视频部分也称作H.262标准,其标准编号为ISO-13818。ISO-13818是一系列标准的集合,包括了系统、视频、音频、一致性、参考软件等10个部分。MPEG-2标准在数字电视广播和音视频媒体容器等场合得到了广泛应用,常见的DVD视盘采用的就是MPEG-2视频编码方法。
MPEG-2格式的主要改进之处之一是支持支持逐行或者隔行扫描视频,使用基于帧或场的编码。在MPEG-2中,为适应隔行扫描视频信号的特点,在DCT、预测和运动估计算法中对帧和场进行了不同的处理。
另一方面,MPEG-2根据不同的编码工具定义了5个Profile:简单SP、主要MP、SNR可分级SNP、空间可分级SSP和高级HP。根据视频分辨率的不同定义了4个Level:低级LL、主级ML、高-1440级High1440和高级HL。
-- MPEG-2的码流分为三层:
1.基本流:ES,由视频编码的视频基本流和音频编码的音频基本流构成
2.打包基本流:PES,为音视频ES分别打包
3.传输流、节目流:TS/PS,若干个PES进行复用后输出,分别用于传输和存储
在MPEG-2的ES流层中,其码流结构采用了类似MPEG-1码流结构的分层封装的方法:
-- 图像序列层:包括若干GOP,序列头包含起始码和序列参数等;
1.图像组(GOP)层:包括若干图像,GOP头包括起始码、GOP标识等;
2.图像层:包括若干个Slice,图像头中包括起始码和图像参数等;
3.片(Slice)层:最小的同步单位,包括若干宏块,Slice头中包括起始码、片地址、量化步长等信息;
4.宏块(Macroblock)层:由4个亮度块和2个色度块组成,宏块头包括地址、类型、MV等信息
> MPEG4
MPEG-4是ISO与1999年颁布的视频编码标准。同前任的MPEG-1和MPEG-2相比,MPEG-4更注重多媒体系统的交互性、灵活性和可扩展性。MPEG-4的标准编号为ISO-14496,也包括多个部分,如系统、视觉信息、音频、一致性等。
MPEG-4中最为显著的特点是采用了基于对象的编码。在MPEG-4中,一个视频对象主要定义为画面中分割出来的不同物体,每个物体由三类信息描述:运动信息、轮廓信息和纹理信息。MPEG-4通过编码这三类信息来实现对视频对象的编码。
mp4是MPEG-4标准的第14部分所制定的容器标准。所谓容器,就是把编码器生成的多媒体内容(视频,音频,字幕,章节信息等)混合封装在一起的标准。
不同的容器有不同的特性,mp4是官方指定的容器,属于”太子党“,硬件支持广泛;rmvb是一种封闭标准的容器,只能用来封装realvideo编码的视频;mkv是社区设计的开放性容器,最大的特性在于几乎可以封装一切的编码格式;avi历史悠久,其陈旧的架构本身已经不能适应新的编码格式。
MP4和MPEG4搞混, 前者是文件容器(container),后者是视频编码格式
mp4应该算是一种比较复杂的媒体格式了,起源于QuickTime。以前研究的时候就花了一番的功夫,尤其是如何把它完美的融入到视频点播应用中,更是费尽了心思,主要问题是处理mp4文件庞大的“媒体头”。当然,流媒体点播也可以采用flv格式来做,flv也可以封装H.264视频数据的,不过Adobe却不推荐这么做,人家说毕竟mp4才是H.264最佳的存储格式嘛。
这几天整理并重构了一下mp4文件的解析程序,融合了分解与合并的程序,以前是c语言写的,应用在linux上运行的服务器程序上,现在改成c++,方便我在其他项目中使用它,至于用不用移植一份c#的
常用MIME类型(Mp4的mime类型设置),服务器MIME配置有问题, 原来服务器配置的MIME type为:application/octet-stream。改为video/mp4之后就好了。
MP4文件格式中,所有的内容存在一个称为movie的容器中。一个movie可以由多个tracks组成。每个track就是一个随时间变化的媒体序列,例如,视频帧序列。track里的每个时间单位是一个sample,它可以是一帧视频,或者音频。sample按照时间顺序排列。注意,一帧音频可以分解成多个音频sample,所以音频一般用sample作为单位,而不用帧。MP4文件格式的定义里面,用sample这个单词表示一个时间帧或者数据单元。每个track会有一个或者多个sample descriptions。track里面的每个sample通过引用关联到一个sample description。这个sampledescriptions定义了怎样解码这个sample,例如使用的压缩算法。
ISO/IEC 14496是MPEG专家组制定的MPEG-4标准于1998年10月公布第1版,1999年1月成为国际标准,1999年12月公布了第2版,2000年初成为国际标准。MPEG4分为21个部分:
(1)ISO/IEC 14496-1,系统部分,描述了组成一个场景的音频和视频成分之间的关系
(2、3)ISO/IEC 14496-2,视频部分和ISO/IEC 14496-3音频部分,分别规定自然的和合成的视频对象、音频对象的编码表示。 (MPEG4编码方式)
(4)ISO/IEC 14496-4,一致性测试部分,定义了比特流和设备的一致性条件,用来测试MPEG-4的实现。
(5)ISO/IEC 14496-5,参考软件,包括与MPEG-4的主要部分相对应的软件。
(6)ISO/IEC 14496-6,多媒体传送整体框架DMIF,这是MPEG-4应用层与传输网络的接口,定义了通信协议,使MPEG-4系统的数据流能进入各种传输网络。还包含一个存储格式MP4,用于存储编码的场景。
(7) ISO/IEC 14496-7,为MPEG-4工具优化软件,提供了对实现进行优化的例子(这里的实现指的是第五部分)。
(8)ISO/IEC 14496-8,定义了在IP网络上传输MPEG-4内容的方式。
(9)ISO/IEC 14496-9,为参考硬件描述,提供了用于演示怎样在硬件上实现本标准其他部分功能的硬件设计方案。
(10)ISO/IEC 14496-10,高级视频编码AVC,定义了一个被称为AVC的视频编解码器。(就是H.264)
(11)ISO/IEC 14496-11,场景描述和应用引擎。
(12)ISO/IEC 14496-12,ISO媒体文件格式,定义了一个存储媒体内容的文件格式。
(13)ISO/IEC 14496-13,知识产权管理和保护(IPMP)扩展。
(14)ISO/IEC 14496-14,MP4文件格式,定义了基于第十二部分的用于存储MPEG-4内容的容器文件格式。(.mp4封装格式)
(15)ISO/IEC 14496-15,AVC文件格式,定义了基于第十二部分的用于存储第十部分的视频内容的文件格式。
(16)ISO/IEC 14496-16,动画框架扩展AFX(Animation Framework eXtension)。
(17)ISO/IEC 14496-17,同步文本字幕格式(尚未完成,2005年1月达成"最终委员会草案"。
(18)ISO/IEC 14496-18,字体压缩和流式传输(针对公开字体格式)。
(19)ISO/IEC 14496-19,综合材质流(Synthesized Texture Stream)。
(20)ISO/IEC 14496-20,简单场景表示(尚未完成,2005年1月达成"最终委员会草案"。
(21)ISO/IEC 14496-21,用于描绘(Rendering)的MPEG-J拓展(尚未完成,2005年1月达成"委员会草案"。
> MPEG-7
MPEG-7的正式名称是“多媒体内容描述接口”(Multimedia Content Description Interface),是由运动图像专家组(MPEG, Moving Picture Experts Group)提出的一个用于描述多媒体内容的ISO/IEC标准。
简单而言,MPEG-7其实就是一个规定如何来描述多媒体内容的特征的标准。MPEG-2、MPEG-4关注的是多媒体本身的编码压缩,而MPEG-7关注的是多媒体内容特征的描述。MPEG-7标准仅仅规定了如何描述,组织特征。特征的提取、特征的使用不属于MPEG-7标准的范围。
MPEG-7(Multimedia Content Description Interface,多媒体内容描述接口),MPEG-7是为互联网视频检索制定的压缩标准。
MPEG-7比不针对特定的应用领域。就目前来看,适合应用MPEG-7的领域包括:
<1> 基于内容的多媒体搜索(包括图像搜索、哼唱搜索、语音搜索等);
<2> 图像理解;
<3> 其他需要使用大量多媒体特征的应用;
视频工作者应该知道的几个网站- https://blog.csdn.net/leixiaohua1020/article/details/11729929
EvalVid - http://www2.tkn.tu-berlin.de/research/evalvid/
压缩编码DOOM9论坛- http://forum.doom9.org/
压缩编码中华视频网- http://www.chinavideo.org/portal.php
视频参数(流媒体系统对比,封装格式对比,视频编码对比,音频编码对比,播放器对比)https://blog.csdn.net/leixiaohua1020/article/details/11842919
电视机产业也需要一个更新换代的由头才能维持自身的生存,从前些年的 1080p、加密模块卡一体化、LED 背光到现在的智能电视、立体呈像,电视机行业每年都必须拿出点新东西来作为卖点推销给消费者,而超高清电视带来的产业链变革可以让几乎整个电视(电视机、机顶盒、编解码芯片等)、IT 产业(例如 4K 相关的软件、存储产品、互联网商等)都能获益。 7680*4320(UHDTV 8K)分辨率。UHDTV 规范 ITU-R Rec.2020 是视频方面的规格。机顶盒实质上是一个网页浏览器,每次开机之后会访问固定的网页,而该网页就是机顶盒的开机界面。
传统而言,色彩的可视范围取决于系统本身的基色(primaries,或者说原色)特性,但是色彩的准确度(accuracy)却取决于编码系统。到目前为止,人们都是把某一型号或者某种类型的显示设备基色定义为系统基色。
-- MPEG-7 标准中视觉描述工具包括基本结构和描述符。MPEG-7 主要定义了七种颜色描述符:颜色空间、主颜色、颜色的量化、颜色直方图、颜色布局、GOF/GOP 颜色、颜色结构、对颜色的特征和结构进行描述。
①颜色空间,该描述符主要用于其它基于颜色的描述。当前描述所支持的颜色空间有:RGB、YCbCr、HSV、HMMD、关于 RGB 的线性变换矩阵、单色。
②颜色量化,该描述符定义了颜色空间的均匀量化。量化产生的维(bin)的数目是可配置的,这样使得各种应用具有更大的灵活性。要使这个描述符在 MPEG-7 背景下有应用意义,例如表示主颜色值的含义,必须结合其它颜色描述符。
③主颜色,该描述符最适用于表示局部(对象或图像区域)特征,几种颜色就足以表达我们感兴趣区域的颜色信息。当然,它也可以用于整个图像,例如旗帜图像或彩色商标图像。颜色量化用于提取每个区域/图像的少数代表颜色,并相应的计算出区域中的每种量化颜色所占的百分比。同时还定义了整个描述符的空间相关性,用于相似性检索。
④颜色布局,该描述符以一种紧凑的形式,有效的表达了颜色的空间分布。这种紧凑性以很小的计算代价,带来高速的浏览和检索。它提供图像与图像的匹配和超高速的片断与片断的匹配,这些匹配要求大量相似性计算的重复。由于该描述符表达了颜色特征的布局信息,因此它可以提供相当友好的用户接口,例如使用其它颜色描述符中均不支持的手绘草图查询。
⑤可伸缩颜色,该描述符是 HSV 颜色空间的颜色直方图(用 Haar 变换编码)。根据维的数目和比特表示的精度,它的二进制表示在一定数据速率范围内是可伸缩的。这个描述符主要用于图像与图像的匹配和基于颜色特征的检索,检索的精度随着描述中使用的比特数目的增加而增加。
⑥颜色结构,该描述符是一个颜色特征描述符,它既包括颜色内容信息(类似于颜色直方图),又包括内容的结构信息。它的主要功能是图像与图像的匹配,主要用于静态图像检索,在这里一幅图像可能由一个单一矩形或者任意形状、可能是非连通的区域组成。提取的方法是:通过考虑一个 8×8 像素的结构化元素中的所有颜色,将颜色结构信息加入该描述符中,而不是单独考虑每个像素。
⑦帧组/图组颜色,该描述符将用于静态图像的可伸缩颜色描述符扩展到对视频片段或静态图像集合的颜色描述。在 Haar 变换之前,用附加的两个比特定义如何计算颜色直方图,是均值、中值还是相交。
-- MPEG-7 推荐了三种纹理描述符,同质纹理描述符(HomogenousTexture Descriptors)、纹理浏览描述符(Texture Browsing Descriptors)和边缘直方图描述符(Edge HistogramDescriptors)。
-- MPEG-7 定义了三种形状描述符:基于区域的形状(RegionShape)、基于轮廓的形状(Contour Shape)和三维形状(Shape 3D)
考虑到多媒体技术、虚拟世界和增强现实技术的持续发展,三维内容也成为当今多媒体信息系统的普遍特征。大多数情况下,三维信息是用多边形网格来表示的。MPEG-4的 SNHC 组研究这个问题并开发了有效的三维网格模型编码技术。在 MPEG-7 标准的框架中,要求对三维信息实现智能的基于内容的提取,用以查找、检索和浏览三维模型库。三维形状特征描述符对三维网格模型进行本质的形状描述,它善于挖掘三维表面的局部特征。
> MPEG-21
MPEG-21 Multimedia Framework,MPEG-21标准其实就是一些关键技术的集成,通过这种集成环境就对全球数字媒体资源进行透明和增强管理,实现内容描述、创建、发布、使用、识别、收费管理、产权保护、用户隐私权保护、终端和网络资源抽取、事件报告等功能。
MPEG-21 Multimedia Framework是致力于在大范围的网络上实现透明的传输和对多媒体资源的充分利用。MPEG-21致力于为多媒体传输和使用定义一个标准化的开放框架。这种框架将在开放的市场中为内容提供商和业务提供商创造同等的机会。同时,这将在一种互操作的模式下为用户提供更丰富的信息,用户将因此而受益。
MPEG-21景象可以总结如下:一个多媒体框架,它可以在广阔的范围里,为不同的网络用户提供透明的和可不断扩展的多媒体资源。 MPEG-21基于两个基本概念:分布和处理基本单元DI(the Digital Item)以及DI与用户间的互操作。 MPEG-21也可表述为:以一种高效、透明和可互操作的方式支持用户交换、接入、使用甚至操作DI的技术。
> H.261标准
--从H.261开始,视频编码方法采用了沿用至今的基于波形的混合编码方法。H.261标准主要目标是用于视频会议和可视电话等高实时性、低码率的视频图像传输场合。
-- H.261信源编码所采用的技术:
1.帧内编码/帧间编码判定:根据帧与帧之间的相关性判定——相关性高使用帧间编码,相关性低使用帧内编码。
2.帧内编码:对于帧内编码帧,直接使用DCT编码8×8的像素块。
3.帧间编码/运动估计:使用以宏块为基础的运动补偿预测编码;当前宏块从参考帧中查找最佳匹配宏块,并计算其相对偏移量(Vx, Vy)作为运动矢量;编码器使用DCT、量化编码当前宏块和预测宏块的残差信号;
4.环路滤波器:实际上是一个数字低通滤波器,滤除不必要的高频信息,以消除方块效应;
-- 经过H.261码流复合器输出的码流,总共可以分为四层,从上到下分别为帧层、块组层、宏块层和块层。每一层按照不同的封装格式包含了头信息和下一层的结构。
1.帧层:由帧首和块组数据构成;帧首包括帧起始码( PSC)、帧计数码( TR)、帧类型( PTYPE)等;
2.块组层:由块组首和宏块数据组成;块组首包括组起始码( GBSC)、块组编号码( GN)、块组量化步长等;
3.宏块层(Macroblock,MB):由宏块首和块数据构成;宏块首包括宏块地址码、宏块类型、宏块量化步长、运动矢量数据、编码模式等;
4.块层:包括每个8×8块的DCT系数按之字形扫描后的熵编码码流,以块结束符结尾。
> H.263标准
H.263是相对于H.261的改进标准,同样以低码率视频通信为目标,但是具有更好的压缩效率。与H.261相比,H.263支持更多种分辨率的图像格式:
Sub-QCIF: 128×96;QCIF: 176×144;
CIF:352×288;4CIF:704×576;16CIF:1480×1152;
-- 除了更多的分辨率选择之外,视频信源编码算法也相比H.261实现了多项改进。
1.运动矢量:相比于H.261,H.263的运动矢量分配更加灵活。在H.261中,每一个MB分配一个运动矢量;H.263中支持对每一个8×8像素块各自使用一个运动矢量。
2.MV精度:H.261只支持整数像素的运动矢量,在H.263中运动矢量精度为1/2像素。
3.双向预测模式:H.263的帧间编码帧除了P帧之外,也支持B帧,使用前后双向预测模式。
4.熵编码:采用了算术编码,以较高的运算复杂度换取更高的编码效率。
> H.264/AVC视频编解码技术,标准化组织
H.264/AVC视频编解码技术详解- https://blog.csdn.net/shaqoneal/article/list/1
【H.264/AVC视频编解码技术详解】二. 主流视频编码标准的发展- https://blog.csdn.net/shaqoneal/article/details/52081001
H.264被MPEG组织称作AVC(Advanced Video Codec/先进视频编码),是MPEG4标准的第10部分,用来取代之前MPEG4第2部分(简称MPEG4P2)所制定的视频编码,因为AVC有着比MPEG4P2强很多的压缩效率。最常见的MPEG4P2编码器有divx和xvid(开源),最常见的AVC编码器是x264(开源)。H.264/AVC(或者AVC/H.264或者H.264/MPEG-4 AVC或MPEG-4/H.264 AVC);而H.265则是次世代的视频编码技术,被MPEG组织称为HEVC(High Efficiency Video Coding),是次世代标准MPEG-H的第2部分,不属于MPEG-4标准,有着比H.264更强的压缩效率。
-- 从事视频编码算法的标准化组织主要有两个,ITU-T和ISO:
1.ITU-T,全称International Telecommunications Union - Telecommunication Standardization Sector,即国际电信联盟——电信标准分局。该组织下设的VECG(Video Coding Experts Group)主要负责面向实时通信领域的标准制定,主要制定了H.261/H263/H263+/H263++等标准。
2.ISO,全称International Standards Organization,即国际标准化组织。该组织下属的MPEG(Motion Picture Experts Group),即移动图像专家组主要负责面向视频存储、广播电视、网络传输的视频标准,主要制定了MPEG-1/MPEG-4等。
实际上,真正在业界产生较强影响力的标准均是由两个组织合作产生的。比如MPEG-2、H.264/AVC和H.265/HEVC等。
为了专门处理视频信息中的多种冗余,视频压缩编码采用了多种技术来提高视频的压缩比率。其中常见的有预测编码、变换编码和熵编码等。
3.Google:VP8/VP9;
4.Microsoft : VC-1;
5.国产自主标准:AVS/AVS+/AVS2
-- 预测编码可以用于处理视频中的时间和空间域的冗余。视频处理中的预测编码主要分为两大类:帧内预测和帧间预测。
1.帧内预测:预测值与实际值位于同一帧内,用于消除图像的空间冗余;帧内预测的特点是压缩率相对较低,然而可以独立解码,不依赖其他帧的数据;通常视频中的关键帧都采用帧内预测。
2.帧间预测:帧间预测的实际值位于当前帧,预测值位于参考帧,用于消除图像的时间冗余;帧间预测的压缩率高于帧内预测,然而不能独立解码,必须在获取参考帧数据之后才能重建当前帧。
在视频编码算法中通常使用正交变换进行变换编码,常用的正交变换方法有:离散余弦变换(DCT)、离散正弦变换(DST)、K-L变换等。
视频编码中的熵编码方法主要用于消除视频信息中的统计冗余。由于信源中每一个符号出现的概率并不一致,这就导致使用同样长度的码字表示所有的符号会造成浪费。通过熵编码,针对不同的语法元素分配不同长度的码元,可以有效消除视频信息中由于符号概率导致的冗余。
在视频编码算法中常用的熵编码方法有变长编码和算术编码等,具体来说主要有上下文自适应的变长编码(CAVLC)和上下文自适应的二进制算术编码(CABAC)。
> H.264 标准
H.264简介- https://blog.csdn.net/shaqoneal/article/details/52081021
在数字视频应用产业链的快速发展中,面对视频应用不断向高清晰度、高帧率、高压缩率方向发展的趋势,当前主流的视频压缩标准协议H.264(AVC)的局限性不断凸显。同时,面向更高清晰度、更高帧率、更高压缩率视频应用的HEVC(H.265)协议标准应运而生。
H264标准各主要部分有Access Unit delimiter(访问单元分割符),SEI(附加增强信息),primary coded picture(基本图像编码),Redundant Coded Picture(冗余图像编码)。还有Instantaneous Decoding Refresh(IDR,即时解码刷新)、Hypothetical Reference Decoder(HRD,假想参考解码)、Hypothetical Stream Scheduler(HSS,假想码流调度器)。
H.264是在MPEG-4技术的基础之上建立起来的,其编解码流程主要包括5个部分:帧间和帧内预测(Estimation)、变换(Transform)和反变换、量化(Quantization)和反量化、环路滤波(Loop Filter)、熵编码(Entropy Coding)。
H.264的算法在概念上可以分为两层:视频编码层负责高效的视频内容表示,网络提取层(NAL:Network Abstraction Layer)负责以网络所要求的恰当的方式对数据进行打包和传送。在VCL和NAL之间定义了一个基于分组方式的接口,打包和相应的信令属于NAL的一部分。这样,高编码效率和网络友好性的任务分别由VCL和NAL来完成。
-- H.264由视讯编码层(Video Coding Layer,VCL)与网络提取层(Network Abstraction Layer,NAL)组成
序列参数集SPS:作用于一系列连续的编码图像;
图像参数集PPS:作用于编码视频序列中一个或多个独立的图像;
VideoToolbox是 iOS8以后开放的硬编码与硬解码的API,一组用C语言写的函数。
所谓的H264数据,其实只是一堆堆的byte[]数组。RTMP流本质上是FLV格式的音视频。
H.264的一些关键算法例如采用CAVLC和CABAC两种基于上下文的熵编码方法、deblock滤波等都要求串行编码,并行度比较低。针对GPU/DSP/FPGA/ASIC等并行化程度非常高的CPU,H.264的这种串行化处理越来越成为制约运算性能的瓶颈。
H.264标准是属于MPEG-4家族的一部分,即MPEG-4系列文档ISO-14496的第10部分,因此又称作MPEG-4/AVC。同MPEG-4重点考虑的灵活性和交互性不同,H.264着重强调更高的编码压缩率和传输可靠性,在数字电视广播、实时视频通信、网络流媒体等领域具有广泛的应用。
在H.264进行编码的过程中,每一帧的H图像被分为一个或多个条带(slice)进行编码。每一个条带包含多个宏块(MB,Macroblock)。宏块是H.264标准中基本的编码单元,其基本结构包含一个包含16×16个亮度像素块和两个8×8色度像素块,以及其他一些宏块头信息。在对一个宏块进行编码时,每一个宏块会分割成多种不同大小的子块进行预测。帧内预测采用的块大小可能为16×16或者4×4,帧间预测/运动补偿采用的块可能有7种不同的形状:16×16、16×8、8×16、8×8、8×4、4×8和4×4。相比于早期标准只能按照宏块或者半个宏块进行运动补偿,H.264所采用的这种更加细分的宏块分割方法提供了更高的预测精度和编码效率。在变换编码方面,针对预测残差数据进行的变换块大小为4×4或8×8(仅在FRExt版本支持)。相比于仅支持8×8大小的变换块的早期版本,H.264避免了变换逆变换中经常出现的失配问题。
H.264标准中采用的熵编码方法主要有上下文自适应的变长编码CAVLC和上下文自适应的二进制算数编码CABAC,根据不同的语法元素类型指定不同的编码方式。通过这两种熵编码方式达到一种编码效率与运算复杂度之间的平衡。
-- 同前期标准类似,H.264的条带也具有不同的类型,其中最常用的有I条带、P条带和B条带等。另外,为了支持码流切换,在扩展档次中还定义了SI和SP片。
1.I条带:帧内编码条带,只包含I宏块;
2.P条带:单向帧间编码条带,可能包含P宏块和I宏块;
3.B条带:双向帧间编码条带,可能包含B宏块和I宏块;
视频编码中采用的如预测编码、变化量化、熵编码等编码工具主要工作在slice层或以下,这一层通常被称为“视频编码层”(Video Coding Layer, VCL)。相对的,在slice以上所进行的数据和算法通常称之为“网络抽象层”(Network Abstraction Layer, NAL)。设计定义NAL层的主要意义在于提升H.264格式的视频对网络传输和数据存储的亲和性。
-- 为了适应不同的应用场景,H.264也定义了三种不同的档次:
1.基准档次(Baseline Profile):主要用于视频会议、可视电话等低延时实时通信领域;支持I条带和P条带,熵编码支持CAVLC算法。
2.主要档次(Main Profile):主要用于数字电视广播、数字视频数据存储等;支持视频场编码、B条带双向预测和加权预测,熵编码支持CAVLC和CABAC算法。
3.扩展档次(Extended Profile):主要用于网络视频直播与点播等;支持基准档次的所有特性,并支持SI和SP条带,支持数据分割以改进误码性能,支持B条带和加权预测,但不支持CABAC和场编码。
H.264中使用的编码技术主要有以下类型(H264核心算法):帧内预测;帧间预测;交错视频编码;变换和量化编码;无损熵编码算法.H.264还定义了包括去块环路滤波器、SI/SP帧、码率控制等多种技术。
H.264的语法元素进行编码后,生成的输出数据都封装为NAL Unit进行传递,多个NAL Unit的数据组合在一起形成总的输出码流。对于不同的应用场景,NAL规定了一种通用的格式适应不同的传输封装类型。通常NAL Unit的传输格式分两大类:字节流格式和RTP包格式。
在信息论中,香农提出了信源编码定理。该定理说明了香农熵与信源符号概率之间的关系,说明信息的熵为信源无损编码后的平均码字长度的下限。在实际使用中,常用的熵编码主要有变长编码和算术编码等方法。其中变长编码相对于算术编码较为简单,但平均压缩比可能略低。常见的变长编码方法有哈夫曼编码和香农-费诺编码等。
指数哥伦布编码同样属于变长编码(VLC)的一种。指数哥伦布编码同哈夫曼编码最显著的一点不同在于,哈弗曼编码构建完成后必须在传递的信息中加入码字和码元值的对应关系,也就是编码的码表,而指数哥伦布编码则不需要。
-- 指数哥伦布编码同哈夫曼编码的比较:
1.哈夫曼编码在编码过程中考虑了信源各个符号的概率分布特性,根据符号的概率分布进行编码,因此对于不同的信源,即使是相同的符号的哈夫曼编码的结果也是不同的;指数哥伦布编码针对不同的信源采用的编码是统一的,因此无论是什么样的输入,输出的编码后的数据都是一致的。
2.由于哈夫曼编码是针对信源特性进行的编码,因此在存储或传输编码后的数据之前必须在前面保存一份码表供解码段重建原始信息使用;而指数哥伦布编码不需要存储任何额外信息就可以进行解码。
3.由于未考虑信源的实际特性,指数哥伦布编码的压缩比率通常比较低,对于有些信息甚至完全没有压缩效果,输出数据比原始数据更大,在这一点上哈夫曼编码作为“最优编码”在效率上更高;然而由于哈夫曼编码运算较指数哥伦布编码更为复杂,且必须保存码表信息增加了传输负荷,也对压缩比率造成了不利影响。
在H.264的各种语法元素中,SPS中的信息至关重要。SPS即Sequence Paramater Set,又称作序列参数集。SPS中保存了一组编码视频序列(Coded video sequence)的全局参数。所谓的编码视频序列即原始视频的一帧一帧的像素数据经过编码之后的结构组成的序列。而每一帧的编码后数据所依赖的参数保存于图像参数集中。
除了序列参数集SPS之外,H.264中另一重要的参数集合为图像参数集Picture Paramater Set(PPS)。通常情况下,PPS类似于SPS,在H.264的裸码流中单独保存在一个NAL Unit中,只是PPS NAL Unit的nal_unit_type值为8;而在封装格式中,PPS通常与SPS一起,保存在视频文件的文件头中。
整个H.264的码流结构可以分为两层:网络抽象层NAL和视频编码层VCL。在NAL层,H.264的码流表示为一系列的NAL Units,不同的NAL Units中包含不同类型的语法元素。
一个Slice包含一帧图像的部分或全部数据,换言之,一帧视频图像可以编码为一个或若干个Slice。一个Slice最少包含一个宏块,最多包含整帧图像的数据。在不同的编码实现中,同一帧图像中所构成的Slice数目不一定相同。
在H.264中设计Slice的目的主要在于防止误码的扩散。因为不同的slice之间,其解码操作是独立的。某一个slice的解码过程所参考的数据(例如预测编码)不能越过slice的边界。每一个Slice总体来看都由两部分组成,一部分作为Slice header,用于保存Slice的总体信息(如当前Slice的类型等),另一部分为Slice body,通常是一组连续的宏块结构(或者宏块跳过信息)。
-- H.264的Slice Header解析,根据码流中不同的数据类型,H.264标准中共定义了5总Slice类型:
I slice: 帧内编码的条带;
P slice: 单向帧间编码的条带;
B slice: 双向帧间编码的条带;
SI slice: 切换I条带,用于扩展档次中码流切换使用;
SP slice: 切换P条带,用于扩展档次中码流切换使用;
在I slice中只包含I宏块,不能包含P或B宏块;在P和B slice中,除了相应的P和B类型宏块之外,还可以包含I类型宏块。
预测残差等占据码流大量体积的数据则必须使用压缩率更高的算法,如CAVLC和CABAC等。H.264码流结构(如NAL Unit、Slice Header等)。
CAVLC算法不是像指数哥伦布编码那样采用固定的码流-码字映射的编码,而是一种动态编码的算法,因而压缩比远远超过固定变长编码UVLC等算法。在H.264标准中,CAVLC主要用于预测残差的编码。
-- 在编码过程中需要注意以下重要的语法元素:
非零系数的个数(TotalCoeffs):取值范围为[0, 16],即当前系数矩阵中包括多少个非0值的元素;
拖尾系数的个数(TrailingOnes):取值范围为[0, 3],表示最高频的几个值为±1的系数的个数。拖尾系数最多不超过3个,若超出则只有最后3个被认为是拖尾系数,其他被作为普通的非0系数;
拖尾系数的符号:以1 bit表示,0表示+,1表示-;
当前块值(numberCurrent):用于选择编码码表,由上方和左侧的相邻块的非零系数个数计算得到。设当前块值为nC,上方相邻块非零系数个数为nA,左侧相邻块非零系数个数为nB,计算公式为nC = round((nA + nB)/2);对于色度的直流系数,nC = -1;
普通非0系数的幅值(level):幅值的编码分为prefix和suffix两个部分进行编码。编码过程按照反序编码,即从最高频率非零系数开始。
最后一个非0系数之前的0的个数(TotalZeros);
每个非0系数之前0的个数(RunBefore):按照反序编码,即从最高频非零系数开始;对于最后一个非零系数(即最低频的非零系数)前的0的个数,以及没有剩余的0系数需要编码时,不需要再继续进行编码。
H.264的变换编码(一)——矩阵运算与正交变换基本概念。在实际应用中,矩阵可以在多个技术领域发挥重要作用,如音视频压缩编码、机器学习、人工智能等领域。
在H.264及更新的视频压缩标准中,采用的是DCT的优化改进版——整数变换。相对于浮点类型的离散余弦变换,整数变换有效降低了变换操作的运算复杂度,提升了编解码器的运行效率。
变换和量化编码在图像和视频的压缩编码中具有重要作用。通过变换编码,空间域信息可以被转换到频率域,使其能量集中于低频区域,并使其码率相对于空间信号有大幅下降。H.264定义了4×4的整数离散余弦变换(简称整数变换),相对浮点数的离散余弦变换,整数变换具有更低的运算复杂度,更适用于移动设备等适用于低功耗的设备运行。
量化运算实际上并非视频压缩领域首先使用的。在通信信号处理等领域,量化技术早就获得广泛的应用。在模拟-数字信号转化过程中,首先需要对模拟信号按照某个频率进行采样,获得离散时间信号,其取值范围为一个连续区间。此时的离散时间信号尚不能称之为数字信号。为了对信号进行数字化,必须对离散时间信号进行量化,将连续的取值范围区间也进行离散化。这样的取值位置离散,采样值也是离散的信号称之为数字信号。
对于16×16的亮度块,变换量化的块包括两个部分:直流部分DC和交流部分AC。16×16亮度块的变换和量化依然要分为16个4×4个子块实现,而与4×4模式不同的是,16×16模式首先抽取出16个4×4系数矩阵的直流分量,组成一个新的4×4矩阵,再对这个直流矩阵进行Hadamard变换后再进行量化。对于4×4模式的色度分量,同样需要抽取直流分量进行Hadamard变换然后再进行量化。然而色度分量的大小为8×8,每个分量分为4个4×4个子块。
-- 视频信息中通常包含的冗余有三种:空间冗余、时间冗余和统计冗余。处理这三种冗余信息通常采用不同的方式:
1.空间冗余采用帧内预测编码压缩;
2.时间冗余采用运动搜索和运动补偿压缩;
3.统计冗余采用熵编码压缩。
在各种视频帧类型中,I帧(包括IDR帧等)全部采用帧内预测,I帧的压缩比率通常比P和B帧更低,因此帧内预测编码的效率对视频整体平均码率具有较大影响。另一方面,I帧通常都会作为P/B帧解码过程中的参考帧,如果I帧的编码出现了错误,那么不仅仅是该I帧出现错误,参考该I帧的P/B帧也同样不能正确解码。
在早期的视频编码标准中就已经存在了帧内编码的方法。如MPEG-1/MPEG-2等早期的标准中,帧的类型已经定义了I/P/B三种类型,分别表示帧内编码帧、预测编码帧和双向预测编码帧。然而在H.264/AVC之前的标准中,编码I帧时并未采用预测编码,只有编码P/B帧时采用了帧间预测编码。在MPEG-1/MPEG-2等编码标准中,I帧的编码采用的是DCT-RLC的方法进行编码。
视频信息在输出码流之前需要经过量化操作。量化完成后的信息用数字化表示,其所需要的位数与表示信息的范围与方差有关。对于取值范围小、方差较小的信息,量化器所需要的比特范围就更小,每个像素数的比特位数便更小。统计表明,相比于原始的图像像素,预测残差的方差与动态范围远小于原始图像像素。通过预测编码,不仅降低了表示像素信息所需要的比特数,还可以保留视频图像的画面质量不至于降低。
-- 在H.264中采用的算法主要可分为预测编码模式和PCM编码模式。
预测编码并非H.264最先采用的技术。在早期的压缩编码技术中便采用了预测数据+残差的方法来表示待编码的像素。然而在这些标准中预测编码仅仅用于帧间预测来去除空间冗余,对于帧内编码仍然采用直接DCT+熵编码的方法,压缩效率难以满足多媒体领域的新需求。H.264标准深入分析了I帧中空间域的信息相关性,采用了多种预测编码模式,进一步压缩了I帧中的空间冗余信息,极大提升了I帧的编码效率,为H.264的压缩比取得突破奠定了基础。
H.264的帧内预测算法通常可以分为三种情况讨论:4×4的亮度分量预测、16×16的亮度分量预测、色度分量预测。
对于每一个帧内预测宏块,其编码模式可以分为I_4x4和I_16x16两种。对于I_4x4模式,该宏块的亮度分量被分为16个4×4大小的子块,每一个4×4大小的子块作为一个帧内预测的基本单元,针对每一个4×4像素块进行过预测与编码。
帧内预测会参考每一个像素块的相邻像素来构建预测数据。对于某一个4×4的子块而言,该子块上方4个、右上方4个、左侧4个以及左上方顶点的1个像素,共13个像素会作为参考数据构建预测块
除了帧内预测编码之外,H.264还定义了一种特殊的编码模式,即为I_PCM模式。I_PCM模式不对像素块进行预测-变换-量化操作,而是直接传输图像的像素值。在有些时候(如传输图像的不规则纹理信息,或低量化参数条件下),该模式比预测编码模式效率更高。
熵编码是利用信息的统计冗余进行数据压缩的无损编码方法。H.264的算术编码,CABAC的全称为上下文自适应的二进制算术编码(Context-Adaptive Binary Arithmetic Coding, CABAC),是一种经过特殊设计的算术编码,其具体步骤主要有:
设定编码上下文;语法元素的二值化;算术编码;
算术编码属于熵编码的一种重要的类型,其作用同变长编码等熵编码方法类似,用于压缩输入数据中的统计冗余,并且使用算术编码的压缩同样是无损压缩。
哈夫曼编码在内的变长编码具有一个共同特点,就是针对每一个码元不同的概率,分配每个码元对应的码字。通常针对概率更高的码元,分配长度更短的码字;针对概率较低的码元,分配长度较长的码字。通过这种不同长度码字的分配使得整体输入信息的平均码字长度小于定长编码,达到数据压缩的效果。
另一方面,由于采用这种变长度的编码方法,变长编码存在一项难以突破的性能瓶颈:即使是某一个输入信源的概率再高,也至少需要1个bit的码字。这种特性限制了编码性能进一步向信源熵逼近,也导致了无法进一步提升整体的压缩性能。
算术编码的引入可以有效解决这个问题。算术编码的思想同变长编码完全不同,算术编码无法针对每一个输入码元准确细分出对应的码字。另外,变长编码可以针对短输入信息进行编码,而算术编码对类似一两个码元的输入信息通常没有任何意义,因为生成的码流长度通常更长。在算术编码执行的过程中,始终需要两个区间来计算,这两个区间即信源的概率区间和码流的编码区间。
H.264/AVC视频编码标准,整个系统框架分为两层:视频编码层面(Video Coding Layer,简称VCL)和网络抽象层面(Network Abstraction Layer,简称NAL)。VCL负责表示有效视频数据的内容,NAL负责格式化数据并提供头信息,以保证数据适合各种信道和存储介质上的传输。
H.264编码框架分为两层:VCL、NAL。VCL(Video Coding Layer,视频编码层),负责高效的视频内容表示;NAL(Network Abstraction Layer,网络抽象层),负责以网络所要求的恰当的方式对数据进行打包和传送。在H.264协议里定义了三种帧,完整编码的帧叫I帧(关键帧),参考之前的I帧生成的只包含差异部分编码的帧叫P帧,还有一种参考前后的帧编码的帧叫B帧。H.264编码采用的核心算法是帧内压缩和帧间压缩。其中,帧内压缩是生成I帧的算法,它的原理是当压缩一帧图像时,仅考虑本帧的数据而不用考虑相邻帧之间的冗余信息,由于帧内压缩是编码一个完整的图像,所以可以独立的解码显示;帧间压缩是生成P、B帧的算法,它的原理是通过对比相邻两帧之间的数据进行压缩,进一步提高压缩量,减少压缩比。
H264采用的核心算法是帧内压缩和帧间压缩,帧内压缩是生成I帧的算法,帧间压缩是生成B帧和P帧的算法。
上下文自适应的二进制算术编码。H.264采用的为称作上下文自适应的二进制算术编码(Context-based Adaptive Binary Arithmetic Coding, CABAC)。CABAC算法是H.264中新引入的一种非常复杂的熵编码算法,专门用于视频的压缩编码。事实证明,在视频压缩编码领域,CABAC保持了强大的生命力,在H.264更新的标准H.265中继续保留了CABAC算法,并且废弃了CAVLC而将CABAC作为主要的熵编码方法。 在CABAC中,主要步骤或算法可以分为3个步骤/类别:语法元素的二值化;上下文模型;算术编码;
> H 265 / HEVC
H.265/HEVC的编码架构大致上和H.264/AVC的架构相似,主要也包含,帧内预测(intra prediction)、帧间预测(inter prediction)、转换 (transform)、量化(quantization)、去区块滤波器(deblocking filter)、熵编码(entropy coding)等模块,但在HEVC编码架构中,整体被分为了三个基本单位,分别是:编码单位(coding unit,CU)、预测单位(predict unit,PU) 和转换单位(transform unit,TU )。H.265的帧内预测模式支持33种方向(H.264只支持8种),并且提供了更好的运动补偿处理和矢量预测方法。截止2013年的HEVC标准共有三种模式:Main、Main 10、Main Still Picture。H.265标准在同等的内质量上会显著减少带宽消耗,有了H.265,高清1080P电视广播和4K视频的网络播放将不在困难,但前提是索尼或者其它媒体巨头能想出办法来传送这些内容。同时,如果移动设备要采用H.265标准,那么其在解码视频时对电量的高消耗也是各大厂商需要解决的问题。
比起H.264/AVC,H.265/HEVC提供了更多不同的工具来降低码率,以编码单位来说,H.264中每个宏块(macroblock/MB)大小都是固定的16x16像素,而H.265的编码单位可以选择从最小的8x8到最大的64x64。H.265的帧内预测模式支持33种方向(H.264只支持8种)基于其更高的压缩比,H.265适用于安防行业再合适不过了!因为安防行业每天都有着海量的视频数据在产生,同时需要实时传输、分析、存储…在带宽和存储成本依然昂贵的今天,我们极度需要更低的码率!更低的码率就等同于更低的成本,因此今天各个安防厂商已经逐渐将视频设备由264转移到265了,这同时对于265编码也有着积极的推动作用.
不是所有的安卓机都支持H.265的硬解码,对于这些不支持硬解码的,使用ffmpeg进行软解即可,这方面资料也不在少数。
> MediaInfo
MediaInfo 用来分析视频和音频文件的编码和内容信息,是一款是自由软件 (免费使用、免费获得源代码)。他除了提供DLL之外,本身也提供GUI工具用于查看视频信息。新版本的MediaInfo支持HEVC。MediaInfo中解码JPEG信息。
-- 使用MediaInfo可以获得多媒体文件的哪些信息?
内容信息:标题,作者,专辑名,音轨号,日期,总时间……
视频:编码器,长宽比,帧频率,比特率……
音频:编码器,采样率,声道数,语言,比特率……
文本:语言和字幕
段落:段落数,列表
-- MediaInfo支持哪些文件格式?
视频:MKV, OGM, AVI, DivX, WMV, QuickTime, Real, MPEG-1, MPEG-2, MPEG-4, DVD (VOB)...
(编码器:DivX, XviD, MSMPEG4, ASP, H.264, AVC...)
音频:OGG, MP3, WAV, RA, AC3, DTS, AAC, M4A, AU, AIFF...
字幕:SRT, SSA, ASS, SAMI...
-- MediaInfo的主要功能特点:
支持众多视频和音频文件格式
多种查看方式:文本,表格,树形图,网页……
自定义查看方式
信息导出:文本,CSV,HTML……
三种发布版本:图形界面,命令行,DLL(动态链接库)
与Windows资源管理器整合:拖放,右键菜单
国际化:有多种界面语言供选择.
MediaInfo 用来分析视频和音频文件的编码和内容信息,是一款是自由软件 (免费使用、免费获得源代码)。
SDL库的作用是封装了复杂的视音频底层操作,简化了视音频处理的难度。SDL(Simple DirectMedia Layer)是一套开放源代码的跨平台多媒体开发库,使用C语言写成。SDL提供了数种控制图像、声音、输出入的函数,让开发者只要用相同或是相似的代码就可以开发出跨多个平台(Linux、Windows、Mac OS X等)的应用软件。目前SDL多用于开发游戏、模拟器、媒体播放器等多媒体应用领域。
3D视觉原理之深度暗示(即立体感)主要有两种:心理深度暗示和生理深度暗示。心理深度暗示主要由平时的经验积累获得。即使用单眼观看也会使人有3D效果。生理深度暗示包括单眼立体视觉暗示和双眼立体视觉暗示。 单眼立体视觉暗示包括有两种:焦点调节和单眼移动视差。双眼立体视觉暗示主要利用的是人的两眼在观察同一物体的时候成像的不同来获得物体的前后关系。由于左眼看到物体的左边多一点,右眼看到的物体右边多一点,因而形成了视觉上的差异,即双目视差(如图所示)。双目视差是获得深度信息的生理基础。当前的3D系统基本上采用的都是该原理进行成像。换句话说,就是分别让左眼和右眼在同一时间看到不同的图像。
3D显示技术:分别让左眼和右眼在同一时间看到不同的图像。红蓝3D。偏振光3D。快门3D。
> AAC规格
-- AAC规格有三种:LC-AAC(最基本的),HE-AAC(AACPlus v1),HE-AAC v2(AACPlus v2)。
1.HE:“High Efficiency”(高效性)。HE-AAC v1(又称AACPlusV1,SBR),用容器的方法实现了AAC(LC)和SBR技术。SBR其实代表的是Spectral Band Replication(频段复制)。简要叙述一下,音乐的主要频谱集中在低频段,高频段幅度很小,但很重要,决定了音质。如果对整个频段编码,若是为了 保护高频就会造成低频段编码过细以致文件巨大;若是保存了低频的主要成分而失去高频成分就会丧失音质。SBR把频谱切割开来,低频单独编码保存主要成分, 高频单独放大编码保存音质,“统筹兼顾”了,在减少文件大小的情况下还保存了音质,完美的化解这一矛盾。
2.HEv2:用容器的方法包含了HE-AAC v1和PS技术。PS指“parametric stereo”(参数立体声)。原来的立体声文件文件大小是一个声道的两倍。但是两个声道的声音存在某种相似性,根据香农信息熵编码定理,相关性应该被去 掉才能减小文件大小。所以PS技术存储了一个声道的全部信息,然后,花很少的字节用参数描述另一个声道和它不同的地方。
3.LC-AAC,HE-AAC,HE-AAC v2比特率和主观质量之间的关系。由图可见,在低码率的情况下,HE-AAC,HE-AAC v2编码后的音质要明显好于LC-AAC.
-- AAC的音频文件格式有以下两种:(开源AAC解码器faad)
1.ADIF:Audio Data Interchange Format 音频数据交换格式。这种格式的特征是可以确定的找到这个音频数据的开始,不需进行在音频数据流中间开始的解码,即它的解码必须在明确定义的开始处进行。故这种格式常用在磁盘文件中。
2.ADTS:Audio Data Transport Stream 音频数据传输流。这种格式的特征是它是一个有同步字的比特流,解码可以在这个流中任何位置开始。它的特征类似于mp3数据流格式。这种格式可以用于广播电视。
简言之。ADIF只有一个文件头,ADTS每个包前面有一个文件头。
杜比数字AC-3(DolbyDigital AC-3)是杜比公司开发的新一代家庭影院多声道数字音频系统。杜比定向逻辑系统是一个模拟系统。杜比数字AC-3提供的环绕声系统由五个全频域声道加一个超低音声道组成,所以被称作5.1个声道。五个声道包括前置的“左声道”、“中置声道”、“右声道”、后置的“左环绕声道”和“右环绕声道”,它不仅具有很好的兼容性,它除了可执行自身的解码外,还可以为杜比定向逻辑解码服务,另外,原理上是它将每一声道的音频根据人耳听觉特性划分为许多最优的狭窄频段,利用音响心理学“听觉掩蔽效应”,删除人耳所听不到或可忽略的部分,并采用数字信号压缩编码。
> OTT TV , IPTV
OTT TV一般情况下使用HTTP传输视音频内容,而IPTV一般情况下使用RTP传输视音频内容。HTTP是基于TCP的,因此不会出现丢包情况。而RTP是基于UDP的,因而会出现丢包状况。正是因为这点不同导致IPTV 质量评价方法已经不适用于 OTT TV 质量评价。传统的网络视频IPTV业务主要是基于UDP承载视频流的,UDP承载的特点是实时性好,但出现丢包则不会重传,抖动和时延过大的包会被丢弃,对视频流而言是一种有损传输。
HTTP视频业务是基于TCP承载视频流的,TCP承载的特点是可靠连接,无损传输。丢包后会进行重传,抖动和延时会被客户端的下载缓冲所消化,一般情况下客户不会感知。只有缓冲区的视频播放完又没有及时下载到新的视频片段时,才会出现画面等待并缓冲
视频传输质量测量目的是以仪表模拟大量用户访问,衡量网络在大流量情况下的服务质量。而编码质量则取决于编码算法,与用户量或网络状态是无关的。例如VOD业务,它是编码软件离线编码后,把文件以非实时的方式送入网络存储(如CDN),再由网络向用户提供服务的。
传统的视频质量分析是基于有损传输的,MOS等指标本意是进行初步的综合的视频质量指示,以便做服务质量对比,再进一步做深入的指标分析,例如分析媒体流损伤情况、网络层丢包、抖动、延时等问题,最终找到影响用户体验的原因,并予以解决。
但由于HTTP视频的特殊性,不存在图像损伤,网络丢包、抖动、延时等网络问题都无法影响到MOS指标,而HTTP视频业务中,由于网络损伤而真正影响用户体验的主要问题,缓冲等待时间、等待次数、视频码率降低等都无法反应出来。
电子产品测评类网站——Zealer。http://www.zealer.com/。
> QoS,QoE
QoS:服务质量(QoS)这个术语被广泛地应用,并且随着新的通信环境的不断出现,其本身的应用范围也越来越广,比如有关于宽带网、无线网以及新兴的各种多媒体服务的内容。
QoE:此外,体验质量(QoE)这个术语也被广泛用于描述用户对于所交付服务的满意度。
QoS的作用是支持特定应用的特点和属性,然而的不同的应用可能有着差别很大的要求。例如,对于远程医疗,交付的准确性就比整体延迟或分组时延偏差(也就是抖动)更加重要,但是对于IP电话而言,抖动和延迟就是关键问题,而且必须进行最小化处理。QoS支持的体系结构框架的重点是网络内的某些机制提供所需的网络性能。
RTP/RTCP QoS 测量:丢包、抖动、乱序和延迟。
-- ITU-T Technical Paper: QoS的构建模块与机制- https://blog.csdn.net/leixiaohua1020/article/details/13508319
通过应用通信的通用参考架构模型,QoS的构建模块可以组织成三个平面内:
1.控制平面: 包括了与用户流量通过路径相关的处理机制(例如接入控制、QoS路由和资源预留);
2.数据平面: 包括了与用户流量的直接处理有关的机制(例如缓冲管理、拥塞避免,数据包标记、排队和调度、流量分类、流量监管和流量整形);
3.管理平面: 包括了与网络的操作和管理方面有关的处理机制(例如SLA、流量恢复、计量和记录,和相关策略)。控制平面机制的关键作用是控制网络服务的响应和流量。
IPTV监测设备主要用于设备和系统部署完成后对系统进行监视,测试设备主要用于在系统部署之前对系统和系统中用到的设备进行测试和验证。IPTV性能监测点。IPTV的体验质量(QoE)要求。代表电信市场所有各方(即用户、服务提供商、制造商和监管机构)的利益。
QoS(Qualityof Service)服务质量,是网络的一种安全机制, 是用来解决网络延迟和阻塞等问题的一种技术。当网络过载或拥塞时,QoS 能确保重要业务量不受延迟或丢弃,同时保证网络的高效运行。
QoE最初被理解为用户对提供给OSI模型不同层次的QoS机制整体感知的度量.服务层面的影响因素又包括网络(或者传输)层、应用层及服务层的参数.传输层的参数反映网络传输的状况,如延迟、带宽、丢包率、误码率、抖动等.应用层的参数反映没有经过传输的服务的性能,包含了OSI模型中会话层、表示层、应用层对服务的影响,如IPTV服务中的内容分辨率、编解码类型等.服务层的参数确定了通信的语义、内容、优先级、重要性以及定价,如服务层的配置(内容类型、服务的应用级别)及质量保证.环境层面的影响因素包括自然环境(如光照条件、噪声的大小、环境的固定或移动),人文与社会环境(如社会观念、文化规范)以及服务运行环境(包括软硬件环境)等.用户层面的因素包括用户的期望、体验经历、用户体验时所处的身心状态和自身背景(如年龄、性别、受教育程度、价值观念等).
Holly French等人在论文《Real Time Video QoE Analysis of RTMP Streams》中,研究了基于RTMP的实时视频的QoE。码率(bitrate)与帧率或者带宽结合,可以相对准确的反映RTMP视频流的QoE。
1. 对于高清晰度的视频,使用带宽+码率(BW+BR)预测QoE的精确度能达到80%。
2. 对于标准清晰度的视频,使用码率+帧率(BR+FR)或者单独使用码率预测QoE的精确度能达到70%。
> IP网络测量模型
IP网络测量模型。测量网络模型应该包括如下三种情况,它们都是由供应商提供的,用于保证不同端点之间的交付服务:
1*边到边(Edge-Edge): 扩展到供应商网络的边缘;
2*站点到站点(Site-Site): 扩展到客户端的边缘(也被称作端到端);
3*终端到终端(TE-TE):扩展到客户终端。
IP服务性能模型.基于IP的平台通信服务通常以两种方式进行:垂直和水平方式。分层(垂直)模型.
通用(水平)模型,服务性能的通用模型处理的是IP网络的水平配置,并且主要由两部分组成:交换链接和网段。每个性能参数都可用于在一个网段或一组串联的网段上单向转移的IP数据包
> DVB数字电视系统简介(DVB-C,DVB-S,DVB-T)
视音频编解码这些技术都是属于“信源”的技术,而《通信原理》研究的范围正好是它的补集,属于“信道”方面的技术。
数字视频广播(英语:Digital Video Broadcasting,缩写:DVB),是由“DVB Project”维护的一系列为国际所承认的数字电视公开标准。“DVB Project”是一个由300多个成员组成的工业组织,它是由欧洲电信标准化组织(European Telecommunications Standards Institute, ETSI)、欧洲电子标准化组织(European Committee for Electrotechnical Standardization, CENELEC)和欧洲广播联盟(European Broadcasting Union, EBU)联合组成的“联合专家组”(Joint Technical Committee, JTC)发起的。
DVB标准中描述的系统可以概括成图5所示的结构。根据所属的层次不同从上层到底层可以分为:音视频编码层,服务信息层,基带传输层,信道编码层,射频层。DVB这些层次完成的工作可以概括如下:
1.音视频编码层:使用MPEG1、2等多项标准对模拟音视频信号进行采样和压缩。
2.服务信息层:使用DVB SI标准产生PSI、SI和EPG等信息服务。
3.基带传输层:使用ASI(异步串行)、SPI(同步并行)、SSI(同步串行)接口。
4.信道编码层:使用各种DVB-S、DVB-C、DVB-T信道编码。
5.射频层:使用卫星、CATV(有线电视网)、SFN(单频网)、Internet等进行信号传送。
DVB-C系统中QAM调制与解调仿真,DVB-C(Cable,数字有线电视)系统。DVB系列标准是数字电视领域最重要的标准,它是一个完整的数字广播解决方案,涉及数字电视广播的方方面面。DVB 规范了数字电视的系统结构和信号处理方式,各厂商可以开发各自的 DVB设备,只要该设备能够正确接收和处理信号并满足规范中所规定的性能指标就可以了。我国的卫星数字电视采用了DVB-S标准,地面广播数字电视采用了自主的DTMB标准,有线数字电视传输标准采用了DVB-C 标准。
DVB-C 标准描述了有线数字电视的帧结构,信道编码和调制。主要用于传送电视中的视频和音频信号。
有线前端每个部分的功能:
(1)基带接口:该单元将数据结构与信号源格式匹配,帧结构应与包含同步字节的 MPEG-2 TS 流一致。
(2)SYNC1反转和随机化。该单元将依据 MPEG-2 帧结构转换 SYNC1字节;同时为了频谱成形,对数据流进行随机化。
(3)RS编码器。将每一个TS包送入RS编码器进行RS(204,188)信道编码。
(4)卷积交织器。完成深度 I=12 的卷积交织信道编码。
(5)字节变换到 m 比特符号。将字节变换为 QAM 符号。
(6)差分编码。为了获得旋转不变星座图,将每符号两个最高有效位进行差分编码。
(7)基带成形。将差分编码的符号映射到I、Q分量。此外对 I 和 Q 信号进行平方根升余弦滚降滤波。
(8)QAM 调制和物理接口。完成 QAM 调制。之后,它将 QAM 已调制信号连接到有线射频信道。
接收端的功能不再详细叙述。接收端只要按照前端的处理顺序进行逆处理就可以得到基带信号。














 832
832











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









