









http://www.oschina.net/question/12_195840?sort=time
块存储系统
分布式存储有出色的性能,可以扛很多故障,能够轻松扩展,所以我们使用Ceph构建了高性能、高可靠的块存储系统,并使用它支撑公有云和托管云的云主机、云硬盘服务。
由于使用分布式块存储系统,避免了复制镜像的过程,所以云主机的创建时间可以缩短到10秒以内,而且云主机还能快速热迁移,方便了运维人员对物理服务器上硬件和软件的维护。
用户对于块存储系统最直观的感受来源于云硬盘服务,现在我们的云硬盘的特点是:
- 每个云硬盘最大支持 6000 IOPS和170 MB/s的吞吐率,95%的4K随机写操作的延迟小于2ms 。
- 所有数据都是三副本,强一致性,持久性高达10个9。
- 创建、删除、挂载、卸载都是秒级操作。
- 实时快照。
- 提供两种云硬盘类型,性能型和容量型。
软硬件配置
经过多轮的选型和测试,并踩过无数的坑之后,我们选择了合适我们的软件和硬件。
软件

硬件
- 从SATA磁盘到SSD,为了提高IOPS和降低Latency。
- 从消费级SSD到企业级SSD,为了提高可靠性。
- 从RAID卡到HBA卡,为了提高IOPS和降低Latency。
最小部署架构
随着软硬件的升级,需求的调整, 我们的部署架构也不断在演进,力求在成本、性能、可靠性上达到最佳平衡点。
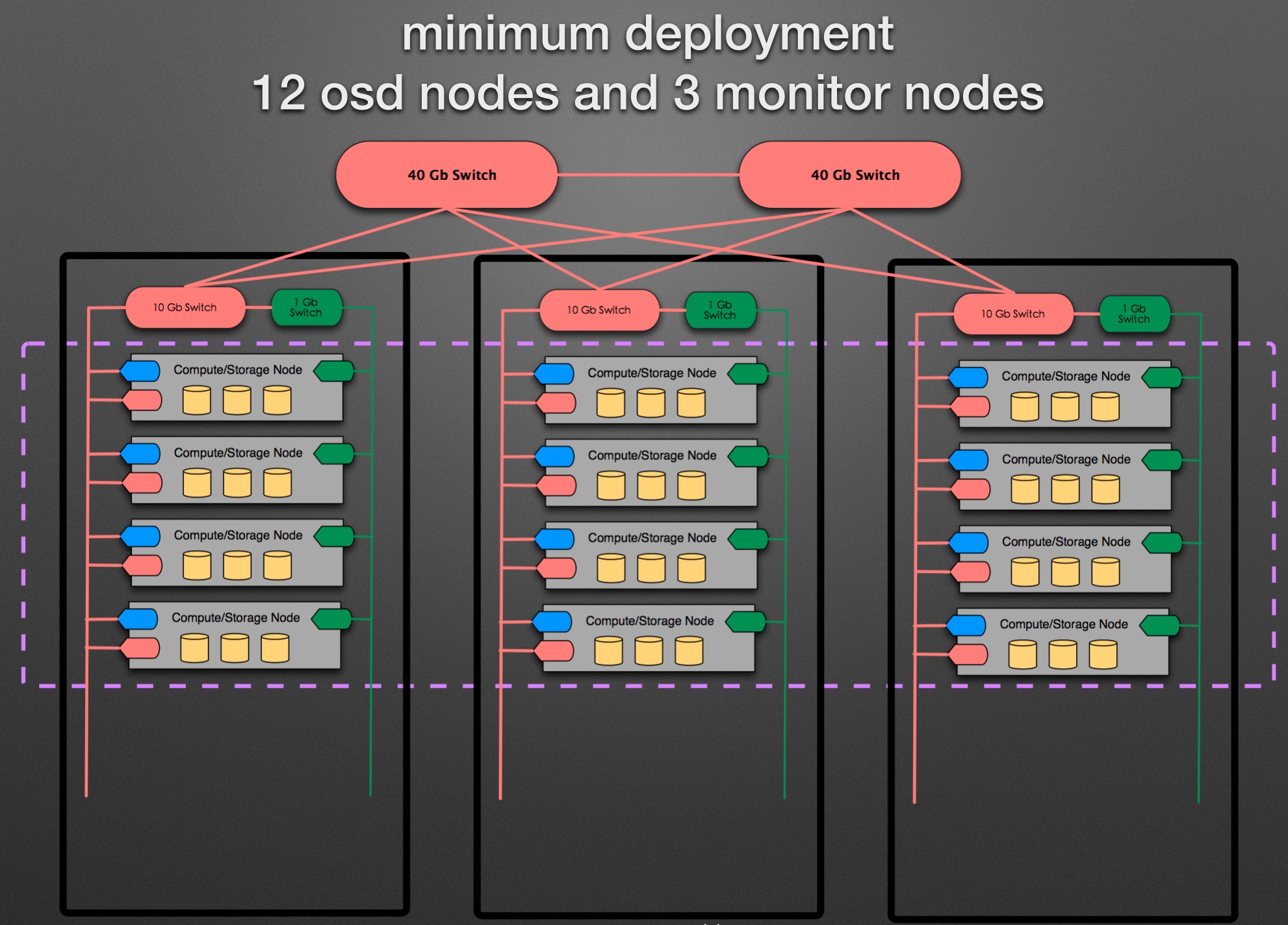
最小规模部署中有12个节点,每个节点上有3块SSD。节点上有2个万兆口和1个千兆口,虚拟机网络和存储网络使用万兆口,管理网络使用千兆口。每个集群中都有3个Ceph Monitor节点。
轻松扩展
云计算的好处是极强的扩展性,作为云计算的底层架构,也需要有快速的Scale-out能力。在块存储系统的部署架构中,可以以12台节点为单位进行扩展。

改造OpenStack
原生的OpenStack并不支持统一存储,云主机服务Nova、镜像服务Glance、云硬盘服务Cinder的后端存储各不相同,造成了严重的内耗。我们把这三大服务的后端统一起来,进行高效管理,解决了虚拟机创建时间长和镜像风暴等问题,还能让虚拟机随便漂移。
原生的OpenStack
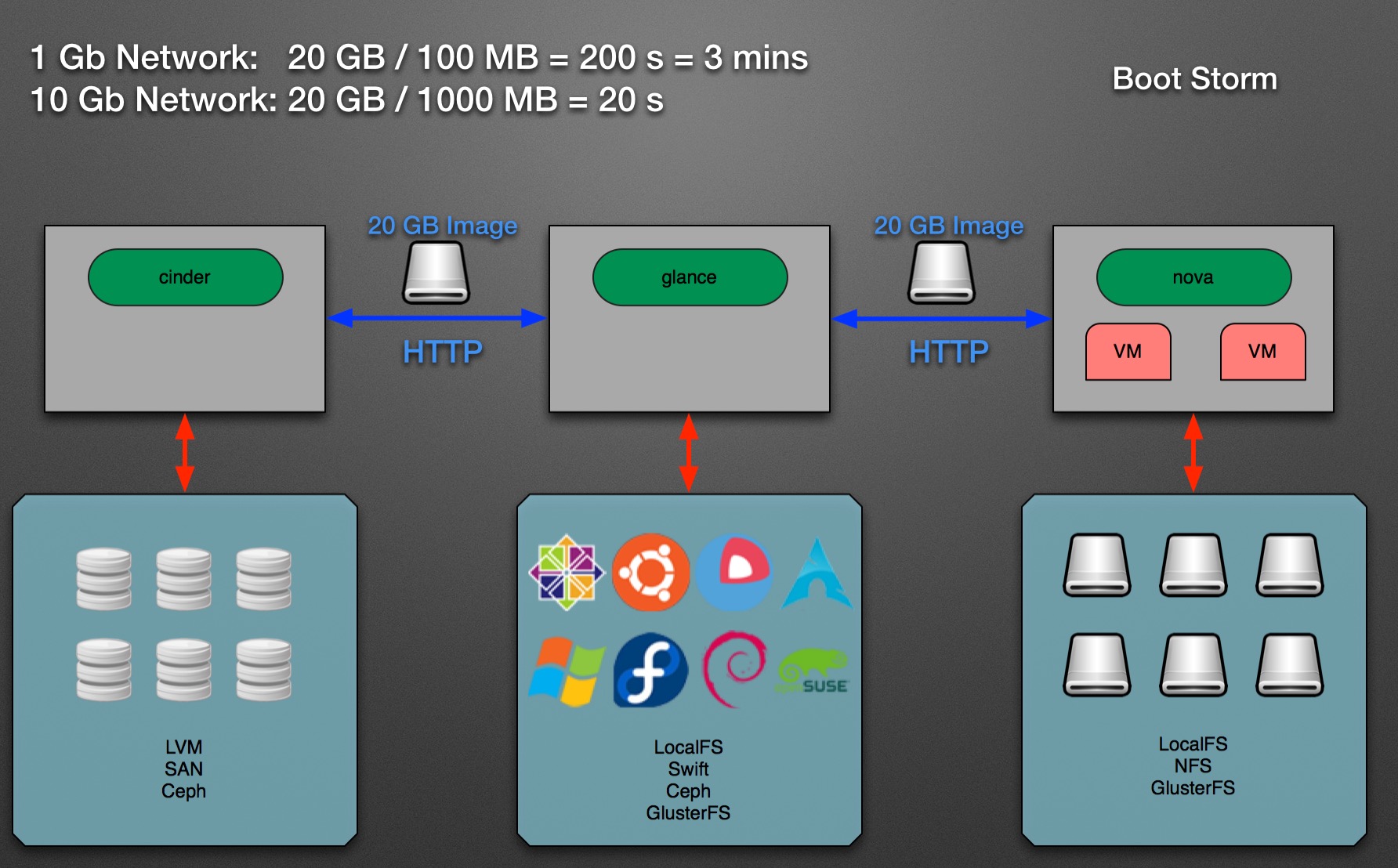
改造后的OpenStack

使用原生的OpenStack创建虚拟机需要1~3分钟,而使用改造后的OpenStack仅需要不到10秒钟时间。这是因为nova-compute不再需要通过HTTP下载整个镜像,虚拟机可以通过直接读取Ceph中的镜像数据进行启动。
我们还增加两个OpenStack没有的功能: QoS 和 共享云硬盘。云计算的另外一个好处是租户资源隔离,所以必备QoS。共享云硬盘可以挂载给多台云主机,适用于数据处理的场景。
我们还使用了OpenStack的multi-backend功能,支持多种云硬盘类型,现在我们的云硬盘类型有性能型、容量型,可以满足数据库和大文件应用。
高性能
存储系统主要的性能指标是IOPS和Latency。我们对于IOPS的优化已经达到了硬件的瓶颈,除非更换更快的固态硬盘或者闪存卡,或者是改变整个架构。我们对于Latency的优化也快接近完成,可以达到企业级存储的水平。
复杂的I/O栈
整个块存储系统有着长长的I/O栈,每个I/O请求要穿过很多线程和队列。
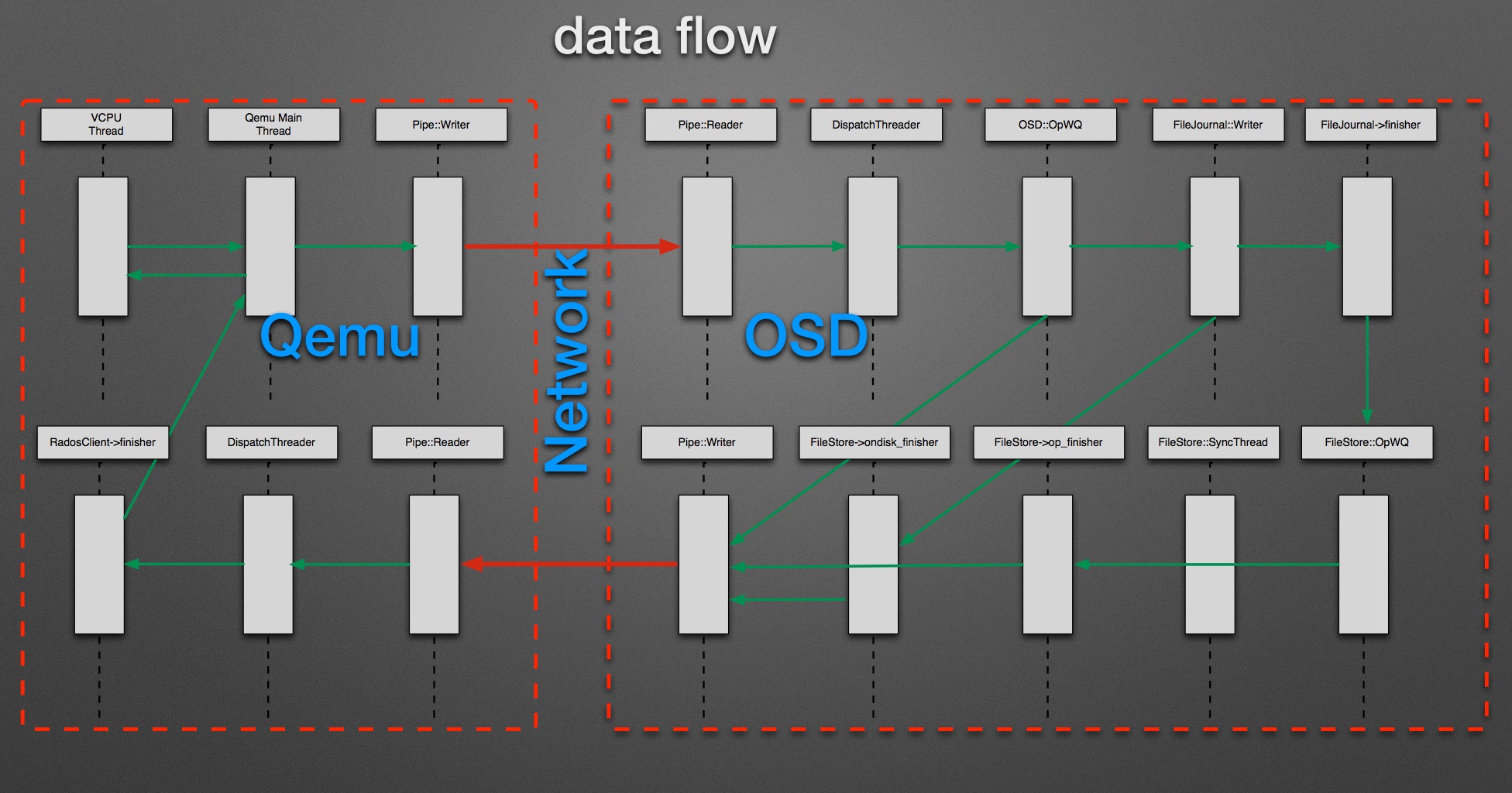
优化操作系统
优化操作系统的参数可以充分利用硬件的性能。
- CPU
- 关闭CPU节能模式
- 使用Cgroup绑定Ceph OSD进程到固定的CPU Cores上
- Memory
- 关闭NUMA
- 设置vm.swappiness=0
- Block
- 设置SSD的调度算法为deadline
- FileSystem
- 设置挂载参数”noatime nobarrier”
优化Qemu
Qemu作为块存储系统的直接消费者,也有很多值得优化的地方。
- Throttle: 平滑的I/O QoS算法
- RBD: 支持discard和flush
- Burst: 支持突发请求
- Virt-scsi: 支持多队列
优化Ceph
我们对于Ceph的优化是重头戏,有很多问题也是时间长、规模上去之后才暴露出来的。









高可靠性
存储需要高可靠性,保证数据可用并且数据不丢失。因为我们的架构中没有使用UPS和NVRAM,所以写请求的数据都是落到三块硬盘之后才返回,这样最大限度地保证了用户的数据安全。
如何计算持久性
持久性是数据丢失的概率,可以用于度量一个存储系统的可靠性,俗称 “多少个9”。数据的放置(DataPlacement)决定了数据持久性,而Ceph的CRUSH MAP又决定了数据的放置,因此CRUSH MAP的设置决定了数据持久性。但是,即时我们知道需要修改CRUSH MAP的设置,但是我们应该怎么修改CRUSH MAP的设置呢,我们该如何计算数据持久性呢?
我们需要一个计算模型和计算公式,通过以下资料,我们可以构建一个计算模型和计算公式。
- Reliability model
- 《CRUSH: Controlled, Scalable, Decentralized Placement of Replicated Data》
- 《Copysets: Reducing the Frequency of Data Loss in Cloud Storage》
- 《Ceph的CRUSH数据分布算法介绍》
最终的计算公式是: P = func(N, R, S, AFR)
- P: 丢失所有副本的概率
- N: 整个Ceph Pool中OSD的数量
- R: 副本数
- S: 在一个Bucket中OSD的个数
- AFR: 磁盘的年平均故障率
这个计算模型是怎么样得到计算公式的呢?下面是4个步骤。
- 先计算硬盘发生故障的概率。
- 定义哪种情况下丢失数据不能恢复。
- 计算任意R个OSD发生故障的概率。
- 计算Ceph丢失PG的概率。
硬盘发生故障的概率是符合泊松分布的:
- fit = failures in time = 1/MTTF ~= 1/MTBF = AFR/(24*365)
- 事件概率 Pn(λ,t) = (λt)n e-λt / n!
Ceph的每个PG是有R份副本的,存放在R个OSD上,当存有这个PG的R个OSD都发生故障时,数据是不可访问的,当这R个OSD都损坏时,数据是不可恢复的。
计算一年内任意R个OSD发生相关故障概率的方法是:
- 计算一年内有OSD发生故障的概率。
- 在Recovery时间内,(R-1)个OSD发生故障的概率。
- 以上概率相乘,就是一年内任意R个OSD发生相关故障概率,假设是 Pr。
- N个OSD中,任意R个OSD的组合数是C(R, N)。
因为这任意R个OSD不一定存有同一个PG的副本,所以这任意R个OSD发生故障并不会导致数据不可恢复,也就是不一定会导致数据丢失。
假设每个PG对应一组OSD(有R个OSD, 称之为Copy Set),有可能多个PG对应同一组OSD。假设有M个不同的Copy Set, M是一个非常重要的数字。
我们再来对Copy Set进行精确的定义:Copy Set上至少有一个PG的所有副本,当这个Copy Set损坏时,这个PG的所有副本也会丢失,这个PG上的所有数据就不可恢复。所以Ceph丢失数据的事件就是Ceph丢失PG, Ceph丢失PG就是有一个Copy Set发生损坏,一个Copy Set丢失的概率就是 P = Pr * M / C(R, N) 。
持久性公式就是个量化工具,它可以指明努力的方向。我们先小试牛刀,算一下默认情况下的持久性是多少?
假设我们有3个机架,每个机架上有8台节点,每个几点上有3块硬盘,每个硬盘做一个OSD,则一共有72个OSD。

默认的crush map设置如下所示

通过持久性公式,我们得到下面的数据。

默认情况下,持久性有8个9,已经比一般的RAID5、RAID10要高,和RAID6差不多,但是还不能满足公有云的要求,因为公有云的规模很大,故障事件的数学期望也会很大,这就逼着我们尽量提高持久性。
提高持久性的方法有很多,比如增加副本数,使用Erase Code等。不过这些方法都有弊端,增加副本数势必会扩大成本;使用Erase Code会导致Latency提高,不适合于块存储服务。在成本和Latency的制约下,还有什么办法可以提高持久性呢?
前面我们已经得到一个量化公式 P = Pr * M / C(R, N), 我们从量化公式入手,去提高持久性(也就是降低P)。要想降低P, 就得降低Pr、M,或者是提高C(R, N)。因为C(R, N)已经确定,我们只能降低Pr和M。
降低恢复时间
从Pr的定义可以知道Pr与恢复时间有关,恢复时间越短,Pr的值越低。那么恢复时间跟什么有关系呢?


我们需要增加更多的OSD用于数据恢复,以便减少恢复时间。目前host bucket不能增加更多的OSD,这是因为主机的网络带宽限制和硬盘插槽限制。解决办法是从CRUSH MAP入手,增加一种虚拟的Bucket: osd-domain, 不再使用host bucket。



通过使用osd-domain bucket,我们把持久性提高了10倍,现在持久性有9个9。
减少Coepy Set个数
如何减少Copy Set的个数呢?Copy Sets是和PG的映射有关的,我们从CRUSH MAP的规则和条件入手,减少Copy Set的个数。解决办法增加虚拟的Bucket: replica-domain, 不再使用rack bucket。每个PG必须在一个replica-domain上,PG不能跨replica-domain,这样可以显著减少Copy Set的个数。
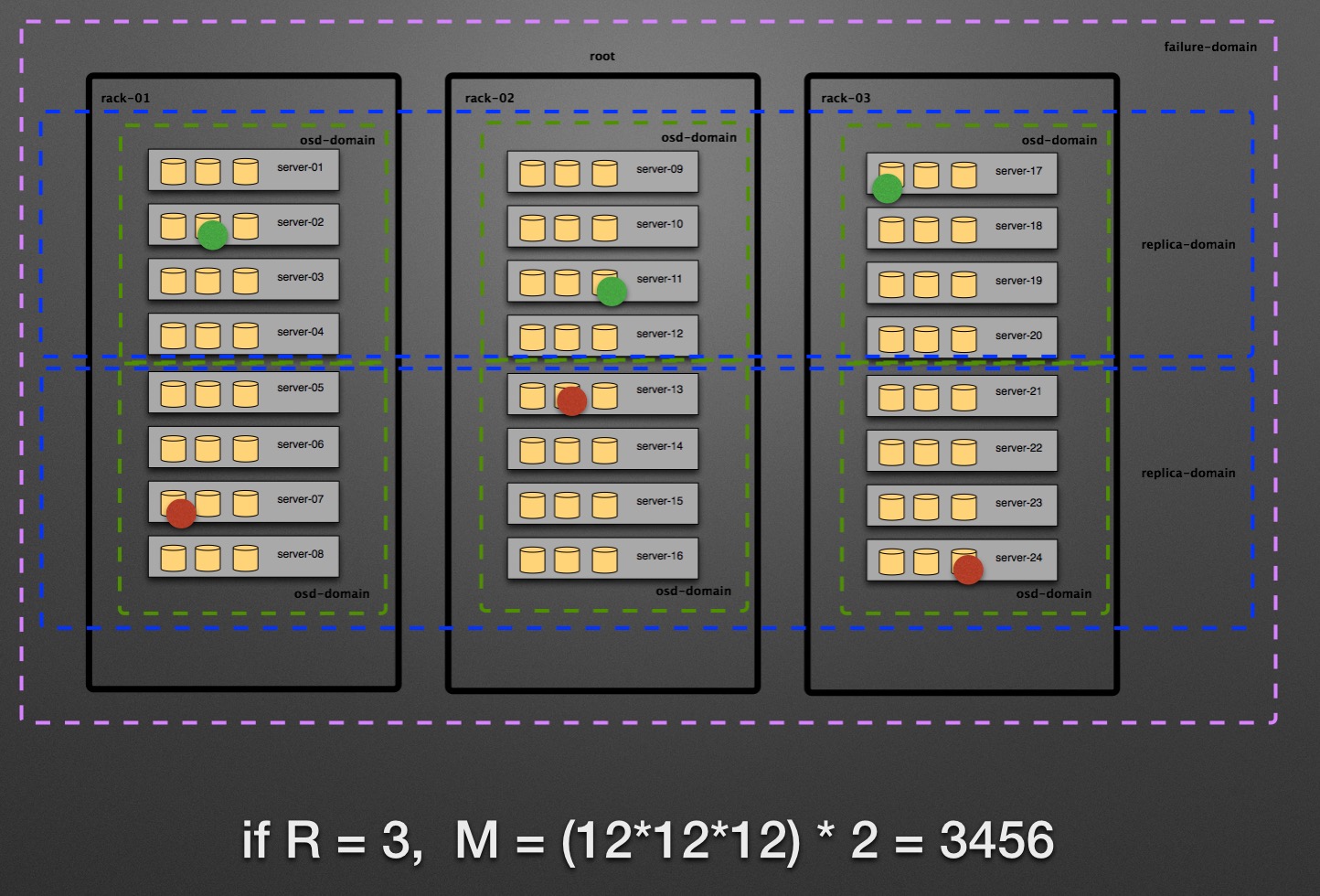


通过使用replica-domain,现在的持久性有10个9,持久性比默认的crush map设置提高了100倍。
自动化运维
Ceph的运维比较费心,稍有差池,整个云平台都会受到影响,因此我们觉得运维的目标是可用性:
减少不必要的数据迁移,进而减少slow requests,保证SLA。
部署
我们整个云平台都是使用Puppet部署的,因此我们使用了Puppet去部署Ceph。一般Ceph的安装是分阶段的:
- 安装好Ceph Monitor集群。
- 格式化Disk,使用文件系统的UUID去注册OSD, 得到OSD ID。
- 根据OSD ID去创建数据目录,挂载Disk到数据目录上。
- 初始化CRUSH MAP。
Puppet只需要完成前三步,第四步一般根据具体情况用脚本去执行。因为OSD ID是在执行过程中得到的,而Puppet是编译后执行,这是一个悲伤的故事,所以puppet-ceph模块必须设计成retry的。
相比eNovance和Stackforge的puppet-ceph模块,我们的puppet-ceph模块的优点是:
- 更短的部署时间
- 支持Ceph所有的参数
- 支持多种硬盘类型
- 使用WWN-ID替代盘符。
维护
在升级Ceph、替换硬盘、重启机器、扩展集群的准则是:
- 提前通知monitor哪些OSD需要维护,避免slow requests
- 注意replica-domain的weight,避免不必要的数据迁移
- 注意recovery的速度,太慢和太快的都不行。
监控
Ceph自家的Calamari长得不错,但是不够实用,而且它的部署、打包还不完善,在CentOS上还有一些BUG,我们只能继续使用原有的工具。
- 收集:使用diamond,增加新的colloctor,用于收集更详细的数据。
- 保存:使用graphite,设置好采集精度和保存精度。
- 展示:使用grafana,挑了十几个工具,发现还是grafana好看好用。
- 报警:zabbix agent && ceph health
我们根据Ceph软件架构对每个OSD分成了很多个throttle层,下面是throttle模型:

有了throttle model,我们可以对每个throttle进行监控,我们在diamond上增加了新的collector用于对这些throttle进行监控,并重新定义了metric name。

最后,我们可以得到每个OSD每层throttle的监控数据。但平时只会关注IOPS、吞吐率、OSD Journal延迟、读请求延迟、容量使用率等。
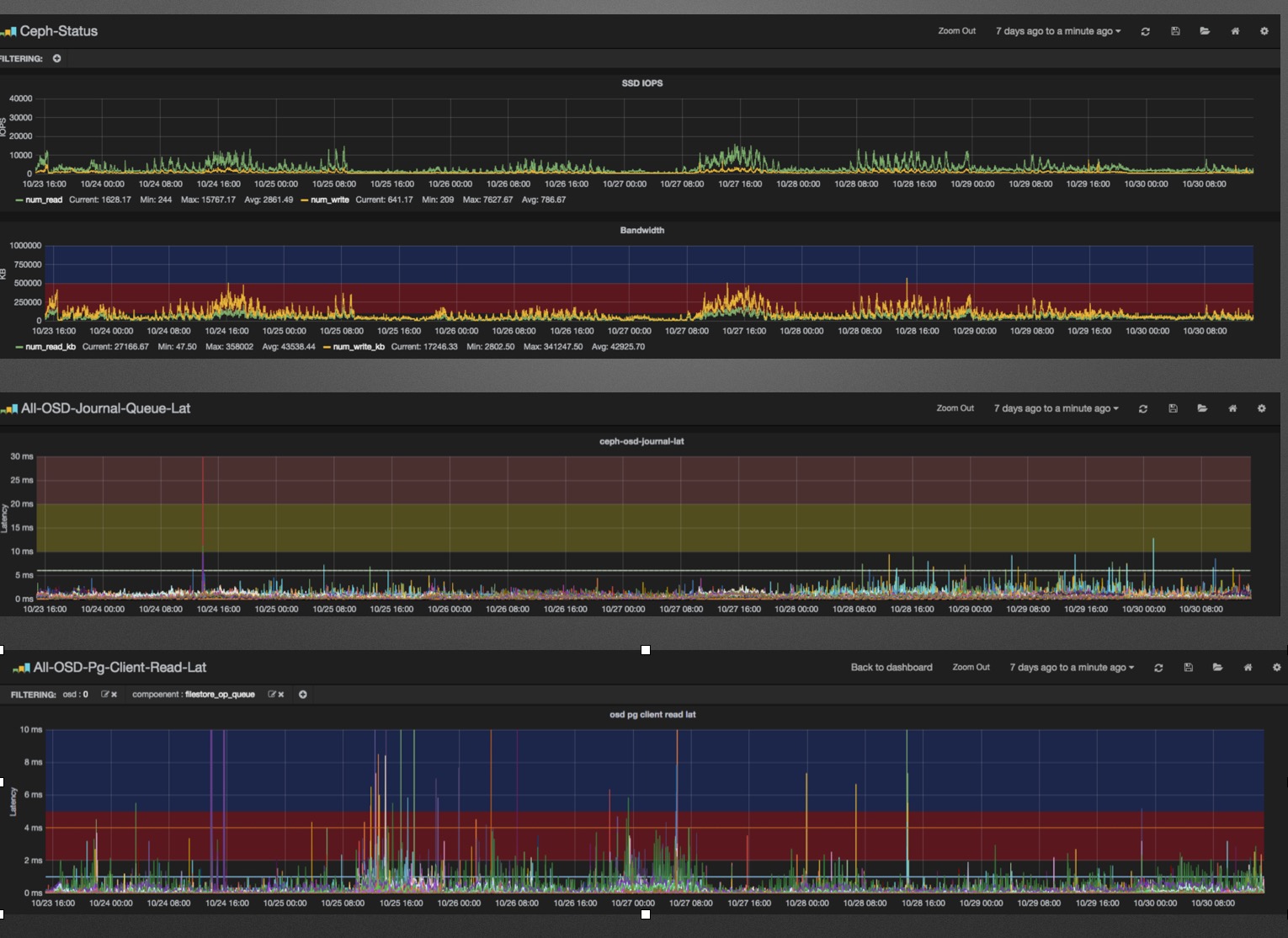
事故
在云平台上线已经快一年了,我们遇到的大小事故有:
- SSD GC问题,会导致读写请求的Latency非常大,飙到几百毫秒。
- 网络故障,会导致Monitor把OSD设置为down状态。
- Ceph Bug, 会导致OSD进程直接崩掉。
- XFS Bug, 会导致集群所有OSD进程直接崩掉。
- SSD 损坏。
- Ceph PG inconsistent。
- Ceph数据恢复时把网络带宽跑满。
总体来说,Ceph是非常稳定和可靠的。
未来
我们未来的工作会集中于
- 块存储系统Latency的优化
- 块存储系统管理平台的改进,使得更多运维操作自动化,监控信息可视化
- 块存储系统提供更多的接口,对接更多的应用
- 块存储系统无痛扩容,减少扩容对上层应用的影响
- 提供关系型数据库服务
- 提供NoSQL服务
- ……















 1277
1277

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









