






本月发表的两篇重要研究论文揭示了如何通过优化测试时计算来显著提高大型语言模型 (LLM) 的性能而无需额外的训练。加州大学伯克利分校和谷歌 DeepMind 的 Snell 等人撰写的《优化扩展 LLM 测试时间计算比扩展模型参数更有效》和 Appier AI Research 和台湾大学的 Tam 等人撰写的《让我畅所欲言?格式限制对大型语言模型性能影响的研究》挑战了传统方法,即更高质量的响应必然需要扩展 LLM 参数并等待更大、更强大的基础模型。
测试时计算(test-time compute),也称为推理计算,是指 LLM 生成提示响应时使用的计算资源。与用于创建和完善模型本身的训练计算不同,每次使用模型时都会应用测试时间计算。研究表明,通过在推理过程中战略性地分配这些计算资源,组织可以从其现有的语言模型中获取更多价值,而无需承担与大规模训练相关的大量成本。
这种方法为企业提供了几个潜在的好处:
- 成本效益:无需昂贵的再训练或更大的模型即可提高模型性能。
- 适应性:使模型能够在特定任务或领域中表现更好,而无需改变基础模型。
- 可扩展性:允许在各种应用程序和用例中实施性能改进。
这些发现对于设计其检索增强生成 (RAG) 管道的企业和改进其快速工程策略的个人尤其重要。通过优化测试时间计算,可以显著提高现有 LLM 在各种应用程序中的有效性,例如商业环境中的内容本地化和创译。
下面,我将探讨和说明所有八种策略,并研究如何将这些策略应用于提示工程和 RAG 管道。接下来,我们将讨论在 Perplexity.ai 等高级搜索 GPT 解决方案中可以观察到的真实示例。对于希望最大限度发挥 AI 投资潜力的组织来说,理解和实施这些测试时计算策略可能会带来翻天覆地的变化。
在推理时优化 LLM 性能的策略:在以下部分中,我们将探讨八种利用测试时计算来显著改善 LLM 响应的创新策略。对于每种策略,我们将:
- 提供概念的简明解释
- 在适用的情况下提供数学表示
- 使用可关联的类比解释方法
- 讨论快速工程和 RAG 管道中的实际应用
这些策略代表了 LLM 优化技术的前沿,提供了在应用环境中增强模型性能的强大方法,而无需更大的模型和上下文窗口。

NSDT工具推荐: Three.js AI纹理开发包 - YOLO合成数据生成器 - GLTF/GLB在线编辑 - 3D模型格式在线转换 - 可编程3D场景编辑器 - REVIT导出3D模型插件 - 3D模型语义搜索引擎 - AI模型在线查看 - Three.js虚拟轴心开发包 - 3D模型在线减面 - STL模型在线切割
1、最佳 N 抽样
概念:最佳 N 抽样是一种技术,其中 LLM 针对给定的提示生成多个独立响应 (N)。然后,验证器(例如,过程奖励模型或 PRM)从这些候选中选择最佳响应。此方法利用并行计算来探索更广泛的潜在答案,从而增加找到高质量响应的可能性。
数学表示:
P(best) = 1 - (1 - p)^N其中:
- “p”是一次尝试生成正确响应的概率
- “N”是生成的独立响应数
类比:想象一下让 10 个不同的人独立解决数学问题。然后,数学老师检查所有不同的方法和答案,并选择最佳方法。例如:
人类:15 x 7 是多少?通过使用独立方法生成多个答案,逐步解答这个问题。
助理:
[回答 1] 以下是分步解答:
从 15 x 7 开始
将 15 分解为 10 + 5
计算 10 x 7 = 70
计算 5 x 7 = 35
将结果相加:70 + 35 = 105
因此,15 x 7 = 105。
[回答 2] 让我们使用分配律来解决这个问题:
15 x 7 可以写成 (10 + 5) x 7
分配 7:(10 x 7) + (5 x 7)
计算每个部分:70 + 35
将结果相加:70 + 35 = 105
因此,15 x 7 等于 105
[回答 3] 我们也可以使用重复加法来解决这个问题
15 x 7 意味着加 15 7 次相乘
15 + 15 + 15 + 15 + 15 + 15 + 15
计算总和:105
因此 15 x 7 等于 105。
人工或自动化系统根据清晰度、正确性和任何其他相关标准评估响应。
最佳 N 抽样在提示工程中的应用:
- 为同一任务生成略有变化的多个提示。
- 使用 LLM 为每个提示变体生成响应。
- 根据预定义标准或单独的评估模型选择最佳响应。
RAG 管道中的应用:
- 检索给定查询的“N”个相关文档或段落。
- 使用每个检索到的项目作为上下文生成响应。
- 使用质量指标或相关性分数选择最佳响应。
在这种方法中,RAG 管道利用多个检索到的文档或段落来生成不同的响应。 通过根据质量或相关性选择最佳响应,系统增加了为用户查询提供准确且信息丰富的答案的可能性:
def best_of_n_rag(query, n=5):
documents = retrieve_top_n_documents(query, n)
responses = []
for doc in documents:
prompt = f"Given the context: {doc}\nAnswer the query: {query}"
responses.append(generate_response(prompt))
return select_best_response(responses)2、顺序修订
概念:顺序修订是一种方法,其中 LLM 生成初始响应,然后迭代修订它。每次修订都以之前的尝试为条件,允许模型从过去的输出中学习并改进。
数学表示:
Q(t) = Q_max - (Q_max - Q_0) * e^(-λt)其中:
Q(t)是修订t时的质量Q_max是可实现的最大质量Q_0是初始质量λ是改进率
类比:想象一个学生写一篇论文草稿,然后根据他们之前的版本多次审查和改进它。例如:
人类:为一个发生在小镇上的神秘故事写一个简短的开头段落。
助手:霍洛溪是一个古朴的小镇,坐落在连绵起伏的山丘和茂密的森林之中,以宁静而闻名。但在田园诗般的外表下,却隐藏着一个令人不寒而栗的秘密,等待着打破其居民的和平生活。
人类:太好了,现在修改这段文字,增加更多的悬念和生动的感官细节。
助手:霍洛溪的教堂钟声哀伤地响起,它们的回声被渐行渐远的暮色吞没。浓雾笼罩着鹅卵石街道,掩盖了少数剩余镇民的脚步声。空气中弥漫着一种诡异的寂静,只有远处猫头鹰的叫声打破了寂静,这是即将发生的令人不安的事件的预兆。
人类:太好了。现在,加入一个关于神秘人物的暗示,但不要透露太多。
助理:教堂的钟声在空心溪里哀伤地响起,回声被渐渐逼近的暮色吞没。浓雾弥漫在鹅卵石街道上,淹没了少数镇民的脚步声。空气中弥漫着一种诡异的寂静,只有远处猫头鹰的叫声和山上维多利亚式老宅邸窗户微弱的吱吱声打破了寂静。窗帘后面站着一个黑影,目光注视着下面的小镇,默默地观察着隐藏在其中的秘密。
人工或自动化系统通过迭代、提供反馈和在每次修订时要求具体改进或添加来继续此过程。
顺序修订在快速工程中的应用:
- 从初始提示开始并生成响应
- 分析响应并提供反馈以指导进一步改进
- 迭代此过程,在每次修订时改进输出,结合反馈以根据特定需求或标准定制响应
def enhanced_sequential_revisions(query, max_revisions=3):
response = generate_initial_response(query)
for _ in range(max_revisions):
response = revise_response(response) # Revise the response iteratively
if structured_output_required():
return convert_to_structured_format(response)
return response在RAG 管道中的应用:
- 从初始检索和响应生成开始。
- 分析响应并使用它来优化检索查询或上下文选择。
- 迭代此过程,在每个步骤中提高检索到的信息和生成的响应的相关性和质量。
在这种方法中,RAG 管道根据之前的响应迭代地优化其查询,使其能够专注于早期迭代中可能遗漏或未充分解决的方面。这可以带来更全面和准确的响应,特别是对于需要多条信息的复杂查询:
def sequential_revision_rag(initial_query, max_iterations=3):
query = initial_query
for i in range(max_iterations):
# Retrieve relevant documents
documents = retrieve_documents(query)
# Generate a response based on the retrieved documents
context = concatenate_documents(documents)
response = generate_response(query, context)
# Analyze the response and refine the query
query = refine_query(initial_query, response)
# Check if the response is satisfactory
if is_response_satisfactory(response):
break
return response
def refine_query(initial_query, previous_response):
refinement_prompt = f"""
Based on the initial query: "{initial_query}"
And the previous response: "{previous_response}"
Generate a refined query that addresses any gaps or inaccuracies in the previous response.
"""
return generate_refined_query(refinement_prompt)
def is_response_satisfactory(response):
# Implement logic to determine if the response meets quality criteria
pass3、光束搜索
概念:光束搜索是一种启发式搜索算法,在生成过程的每个步骤中同时探索多条有希望的路径。它维护一组“光束”(部分解决方案)并并行扩展它们,仅保留基于验证器(例如 PRM)得分最高的候选者。这种方法在探索(考虑各种可能性)和利用(专注于最有可能的路径)之间取得了平衡。
数学表示:
B(t) = top_k(expand(B(t-1)))其中:
B(t)是步骤t的光束集top_k选择k个得分最高的候选者expand从当前光束生成所有可能的后续步骤
类比:想象一下解决迷宫,在每个交叉点,你探索几条短距离的路径,然后选择最有希望的路径继续进一步探索。或者让我们探索另一个日常示例,烹饪一顿复杂的饭菜,从一个广泛的想法开始:
示例:生成复杂的食谱
人类:创建一道美味意大利面食的食谱。首先列出可能的主要食材。
助理:[列出可能的主要食材]
人类:很好。现在,选择前 3 种食材,并为每种食材建议 2 种烹饪方法。
助理:[提供 3 种食材和每种食材的 2 种烹饪方法]
人类:非常好。对于评分最高的组合,提供食谱的前 3 个步骤。
助理:[提供前 3 个步骤]
人类或自动化系统继续此过程,迭代,在验证者分数的指导下,从每一步最有希望的部分解决方案中分支出来。
集束搜索在提示工程中的应用:
- 在每个步骤中生成多个提示变体。
- 评估每个提示的响应质量。
- 保留前 k 个最有希望的提示并继续完善它们。
def beam_search_prompting(initial_prompt, beam_width=3, max_depth=3):
prompts = [initial_prompt]
for depth in range(max_depth):
candidates = []
for prompt in prompts:
variations = generate_prompt_variations(prompt, beam_width)
responses = [generate_response(var) for var in variations]
candidates.extend(zip(variations, responses))
prompts = select_top_k_prompts(candidates, k=beam_width)
return select_best_prompt(prompts)
def generate_prompt_variations(prompt, n):
# Generate n variations of the given prompt
pass
def select_top_k_prompts(candidates, k):
# Select the k best prompts based on response quality
pass
def select_best_prompt(prompts):
# Select the overall best prompt
pass在RAG 管道中的应用:
- 检索初始查询的多个文档集。
- 使用每组文档生成响应。
- 保留前 k 个最有希望的文档-响应对。
- 根据这些顶级响应优化查询并重复该过程。
def beam_search_prompting(initial_prompt, beam_width=3, max_depth=3):
prompts = [initial_prompt]
for depth in range(max_depth):
candidates = []
for prompt in prompts:
variations = generate_prompt_variations(prompt, beam_width)
responses = [generate_response(var) for var in variations]
candidates.extend(zip(variations, responses))
prompts = select_top_k_prompts(candidates, k=beam_width)
return select_best_prompt(prompts)
def generate_prompt_variations(prompt, n):
# Generate n variations of the given prompt
pass
def select_top_k_prompts(candidates, k):
# Select the k best prompts based on response quality
pass
def select_best_prompt(prompts):
# Select the overall best prompt
pass这种方法允许 RAG 管道探索多个检索和生成路径,从而有可能发现单路径方法可能遗漏的更好的响应。完全以自然语言进行定向搜索,如果需要,只将最终选定的路径转换为结构化格式。
4、前瞻搜索
概念:前瞻搜索通过模拟未来步骤来扩展定向搜索方法,然后再决定要采取哪些路径。在每个步骤中,它都会评估潜在的未来状态,以更好地估计整体解决方案的质量。
数学表示:
V(s) = max(R(s), γ * max(V(s')))其中:
V(s)是状态s的值R(s)是状态s的即时奖励γ是折扣因子(控制未来奖励的重要性)s是从s可以到达的可能的未来状态
类比:在国际象棋游戏中,玩家会提前思考几步,在决定当前动作之前想象可能的情况。
示例:规划假期行程
人类:计划在巴黎度过 3 天假期。首先建议 5 个必游景点。
助理:[列出 5 个景点]
人类:太好了。现在,对于每个景点,描述一项潜在活动并预测它可能如何影响当天剩余的行程。
助理:[提供活动和潜在影响]
人类:根据这些预测,选择最适合一起游览的 3 个景点,并为第一天制定粗略的行程。
助理:[提供第一天的行程]
继续这个过程,始终要求人工智能考虑每个选择对未来计划的影响。
提示工程中的前瞻搜索应用:
- 生成多个提示变体。
- 对于每个变体,通过生成后续提示和响应来模拟几个步骤。
- 选择导致最佳预测结果的初始提示。
def lookahead_prompting(initial_prompt, lookahead_depth=2, num_variations=3):
variations = generate_prompt_variations(initial_prompt, num_variations)
best_prompt = None
best_score = float('-inf')
for prompt in variations:
score = simulate_prompt_chain(prompt, depth=lookahead_depth)
if score > best_score:
best_prompt = prompt
best_score = score
return best_prompt
def simulate_prompt_chain(prompt, depth):
# Simulate a chain of prompts and responses, return a score
pass在RAG 管道中的应用:
- 检索一组初始文档。
- 对于每个文档,模拟查询细化和文档检索的几个步骤。
- 选择可产生最佳预测结果的初始文档。
def lookahead_rag(query, lookahead_depth=2, num_docs=3):
initial_docs = retrieve_documents(query, k=num_docs)
best_doc = None
best_score = float('-inf')
for doc in initial_docs:
score = simulate_rag_chain(query, doc, depth=lookahead_depth)
if score > best_score:
best_doc = doc
best_score = score
return generate_response(query, best_doc)
def simulate_rag_chain(query, doc, depth):
# Simulate a chain of RAG steps, return a score
pass5、混合方法
概念:混合方法结合了多种测试时间计算策略,以利用它们的互补优势并减轻各自的弱点。这使得系统更加强大和适应性更强,可以处理更广泛的任务和查询。
数学表示:
E[H] = max(E[S1], E[S2], ..., E[Sn])
其中:
E[H]是混合方法的预期性能E[Si]是第 i 个策略的预期性能
类比:想象一场写作比赛,其中多位作者各自在几轮中撰写和修改自己的故事。然后,评委从所有作者中选出最好的最终故事,结合个人写作和修改过程的优势。
混合方法在快速工程中的应用:
- 结合不同的策略,例如 Best-of-N、顺序修订和 Beam Search。
- 在快速细化过程的不同阶段使用不同的策略。
def hybrid_prompting(initial_query, n_initial=5, beam_width=3, max_revisions=2):
# Step 1: Best-of-N for initial prompts
initial_prompts = generate_diverse_prompts(initial_query, n=n_initial)
initial_responses = [generate_response(prompt) for prompt in initial_prompts]
best_initial = select_best_response(initial_responses)
# Step 2: Beam Search for prompt refinement
refined_prompts = beam_search_prompts(best_initial, width=beam_width)
# Step 3: Sequential Revisions for final improvements
final_prompt = sequential_revise_prompt(refined_prompts[0], max_revisions=max_revisions)
return final_prompt
def generate_diverse_prompts(query, n):
# Generate n diverse prompts based on the query
pass
def beam_search_prompts(prompt, width):
# Perform beam search to refine the prompt
pass
def sequential_revise_prompt(prompt, max_revisions):
# Sequentially revise the prompt
pass在RAG 管道中的应用:
- 结合不同的检索策略、查询细化技术和响应生成方法。
- 根据查询的复杂性或初始结果的质量调整策略。
def hybrid_rag(query, n_initial=5, beam_width=3, max_revisions=2):
# Step 1: Best-of-N for initial document retrieval
initial_docs = retrieve_diverse_documents(query, n=n_initial)
initial_responses = [generate_response(query, doc) for doc in initial_docs]
best_initial = select_best_response(initial_responses)
# Step 2: Beam Search for context refinement
refined_contexts = beam_search_contexts(query, best_initial, width=beam_width)
# Step 3: Sequential Revisions for final response generation
final_response = sequential_revise_response(query, refined_contexts[0], max_revisions=max_revisions)
return final_response
def retrieve_diverse_documents(query, n):
# Retrieve n diverse documents relevant to the query
pass
def beam_search_contexts(query, initial_context, width):
# Perform beam search to refine the context
pass
def sequential_revise_response(query, context, max_revisions):
# Sequentially revise the response
pass混合方法可以灵活地适应不同的查询和任务,通过减轻单个策略的弱点来增强稳健性,并且有可能通过不同策略的协同组合实现更高质量的输出。但是,它们的实施和维护也可能会更复杂,可能需要更多的计算资源,并且通常需要仔细调整才能找到组件策略之间的最佳平衡。为了与格式限制方面的见解保持一致,建议在整个混合方法中优先考虑自然语言处理,仅在需要时将结构化格式化作为最终的后处理步骤。
6、计算最优扩展
概念:计算最优扩展涉及根据手头任务的估计难度或复杂性自适应地选择最佳测试时间计算策略。这种方法旨在通过为具有挑战性的任务分配更多资源,为较简单的任务分配较少资源来优化可用计算资源的使用。
数学表示:
S* = argmax_S (P(correct|S, d) / C(S))其中:
S*是最优策略P(correct|S, d)是在给定策略 S 和难度 d 的情况下得到正确答案的概率C(S)是策略 S 的计算成本
类比:想象一个学生,他使用抽认卡学习简单主题,使用小组学习课程学习中等难度的科目,使用一对一辅导学习最具挑战性的概念。学生根据感知到的材料难度调整学习策略。
计算最优扩展在快速工程中的应用:
- 评估任务或查询的复杂性。
- 根据评估的复杂性选择适当的提示策略。
- 相应地分配计算资源。
def compute_optimal_prompting(query):
complexity = assess_query_complexity(query)
if complexity == 'low':
return simple_prompt_strategy(query)
elif complexity == 'medium':
return beam_search_prompting(query, beam_width=3, max_depth=2)
else: # high complexity
return hybrid_prompting(query, n_initial=5, beam_width=3, max_revisions=2)
def assess_query_complexity(query):
# Implement logic to assess query complexity
# This could be based on query length, presence of specific keywords, etc.
pass
def simple_prompt_strategy(query):
# Implement a simple prompting strategy for low-complexity queries
pass在RAG 管道中的应用:
- 估计查询的难度或所需信息的预期复杂性。
- 相应地调整检索深度、上下文长度和响应生成策略。
def compute_optimal_rag(query):
difficulty = estimate_query_difficulty(query)
if difficulty == 'easy':
return simple_rag(query)
elif difficulty == 'moderate':
return beam_search_rag(query, beam_width=3, max_depth=2)
else: # difficult
return hybrid_rag(query, n_initial=5, beam_width=3, max_revisions=2)
def estimate_query_difficulty(query):
# Implement logic to estimate query difficulty
# This could be based on query complexity, domain specificity, etc.
pass
def simple_rag(query):
# Implement a simple RAG strategy for easy queries
pass结合对格式限制的洞察,计算优化扩展可以进一步调整其方法,通过考虑任务复杂性来确定计算策略和格式化方法。对于结构化输出可能有利的简单任务,系统可以直接生成所需格式的响应。但是,对于需要更复杂推理的复杂任务,重点应该放在利用 LLM 的自然语言功能上,并可选择在必要时将结构化格式化作为最终的后处理步骤。
7、过程奖励模型 (PRM) 引导搜索
概念:PRM 引导搜索利用学习奖励模型 (PRM) 在生成过程中提供反馈和指导。PRM 评估中间步骤或部分解决方案,将 LLM 引向更有希望的方向并提高最终输出的整体质量。
数学表示:
R(s, a, s') = f(φ(s, a, s'))其中:
R是奖励s是当前状态a是采取的行动s'是下一个状态φ是从状态和行动中提取相关信息的特征函数f是将特征映射到奖励值的学习奖励函数
类比:想象一个烹饪节目,专业厨师品尝并评分参赛者菜肴准备的每个步骤,指导他们在整个烹饪过程中做出更好的选择。
示例:解决复杂的数学问题
人类:让我们一步一步解决这个微积分问题:求 f(x) = x³ * sin(x) 的导数。首先,陈述乘积规则。
助理:[陈述乘积规则]
人类:很好。现在,确定我们要区分的两个函数。
助理:[识别函数]
人类:很好。现在将乘积规则应用于这些函数。
助理:[应用乘积规则]
人类:完美。现在简化表达式。
助理:[简化表达式]
在每个步骤中,您(充当 PRM)通过提供反馈并询问下一步来引导 AI 找到正确的解决方案。
提示工程中的 PRM 引导搜索应用:
- 训练奖励模型来评估提示或响应的质量。
- 使用此模型来指导提示的选择和细化。
def prm_guided_prompting(query, n_candidates=10, n_iterations=3):
candidates = generate_initial_prompts(query, n_candidates)
for _ in range(n_iterations):
responses = [generate_response(prompt) for prompt in candidates]
scores = reward_model.evaluate(responses)
best_candidates = select_top_k(candidates, scores, k=n_candidates//2)
candidates = best_candidates + generate_variations(best_candidates, n_candidates//2)
return select_best(candidates, reward_model)
def generate_initial_prompts(query, n):
# Generate n initial prompt candidates
pass
def generate_variations(prompts, n):
# Generate n variations of the given prompts
pass
class RewardModel:
def evaluate(self, responses):
# Evaluate the quality of the responses
pass
reward_model = RewardModel()在RAG 管道中的应用:
- 训练奖励模型以评估检索到的文档和生成的响应的相关性和质量。
- 使用此模型指导文档检索和响应生成过程。
def prm_guided_rag(query, n_docs=10, n_iterations=3):
documents = retrieve_initial_documents(query, n_docs)
for _ in range(n_iterations):
contexts = [create_context(doc) for doc in documents]
responses = [generate_response(query, context) for context in contexts]
scores = reward_model.evaluate(responses, query)
best_docs = select_top_k(documents, scores, k=n_docs//2)
documents = best_docs + retrieve_similar_documents(best_docs, n_docs//2)
best_context = create_context(select_best(documents, reward_model))
return generate_response(query, best_context)
def retrieve_initial_documents(query, n):
# Retrieve n initial relevant documents
pass
def create_context(document):
# Create a context from the document for response generation
pass
def retrieve_similar_documents(documents, n):
# Retrieve n documents similar to the given documents
pass
class RewardModel:
def evaluate(self, responses, query):
# Evaluate the quality and relevance of the responses
pass
reward_model = RewardModel()8、多数投票
概念:多数投票是一种简单而有效的方法,它涉及对给定的查询或任务生成多个答案,然后选择最常见或最频繁的答案作为最终输出。这种方法依赖于这样的假设:“群体智慧”往往会导致更准确或更可靠的结果。
数学表示:
P(correct) = Σ (k=⌊N/2⌋+1 to N) C(N,k) * p^k * (1-p)^(N-k)其中:
N是投票数p是每次投票正确的概率C(N,k)是二项式系数(从一组 N 中选择 k 个项目的方式数)⌊N/2⌋+1表示多数所需的最低投票数
类比:想象一个游戏节目,参赛者可以“向观众”寻求帮助。观众最喜欢的答案通常是正确的。
提示工程中多数表决的应用:
- 生成多个提示及其相应的响应。
- 识别响应中的共同元素或主题。
- 根据最常见或最一致的信息构建最终响应。
def majority_voting_prompting(query, n_prompts=5, n_responses_per_prompt=3):
prompts = generate_diverse_prompts(query, n_prompts)
all_responses = []
for prompt in prompts:
responses = [generate_response(prompt) for _ in range(n_responses_per_prompt)]
all_responses.extend(responses)
return aggregate_responses(all_responses)
def generate_diverse_prompts(query, n):
# Generate n diverse prompts based on the query
pass
def aggregate_responses(responses):
# Implement logic to identify common elements and construct a final response
# This could involve techniques like text summarization or extractive methods
pass在RAG 管道中的应用程序:
- 检索多组文档并为每组生成响应。
- 识别响应中的共同信息或答案。
- 根据最一致的检索信息构建最终响应。
def majority_voting_rag(query, n_retrievals=5, n_docs_per_retrieval=3):
all_responses = []
for _ in range(n_retrievals):
documents = retrieve_documents(query, n_docs_per_retrieval)
context = create_context(documents)
response = generate_response(query, context)
all_responses.append(response)
return aggregate_responses(all_responses)
def retrieve_documents(query, n):
# Retrieve n relevant documents for the query
pass
def create_context(documents):
# Create a context from the documents for response generation
pass
def aggregate_responses(responses):
# Implement logic to identify common information and construct a final response
# This could involve techniques like text summarization or answer fusion
pass在实践中,最好的结果往往来自于结合多种方法并针对特定用例进行微调。随着人工智能领域的不断发展,我们可以期待在快速工程和 RAG 流程中看到这些策略更加复杂的应用。
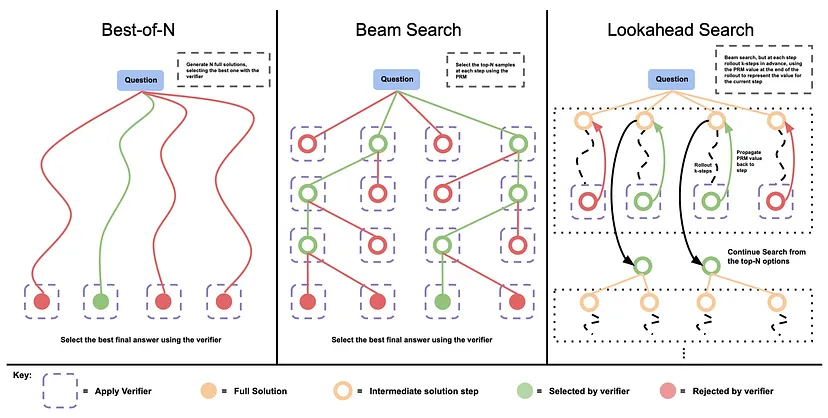
三种 LLM 测试时计算优化策略的比较:Best-of-N、Beam Search 和 Lookahead Search。该图描述了每种策略用于生成和选择问题最佳答案的过程。这些策略从左到右在复杂性和前瞻性能力方面不断进步,展示了它们在推理时增强 LLM 性能的潜力。来源:Snell 等人 (2024) 中的图 2
9、搜索 GPT 中的应用
当我阅读论文时,我不得不思考这些测试时计算策略如何已经为尖端的现实世界 AI 应用程序提供信息,例如 perplexity.ai,这是一个创新的搜索引擎,它利用复杂的 LLM 技术提供更准确和上下文相关的结果。虽然我不能 100% 确信,但这就是我如何看待 perplexity.ai 结合其中一些策略来阐述方法和协同作用的方式。
滑动窗口方法:增强预测上下文
Perplexity.ai 使用滑动窗口技术评估固定长度语言模型,展示了类似于波束搜索和前瞻搜索的原理的实际应用。
滑动窗口方法可以概念化为同时探索上下文的多个“波束”。窗口的每个位置都充当一个波束,允许模型根据不同的上下文信息进行预测。此方法提供了对输入空间的更细致的探索,类似于波束搜索探索多个部分解决方案的方式。
通过为每个预测提供更多先前标记,滑动窗口有效地实现了一种前瞻形式。这类似于前瞻搜索如何模拟未来步骤以做出更好的决策。在滑动窗口的情况下,“未来”上下文实际上是额外的过去上下文,这有助于模型对下一个标记做出更明智的预测。
高效采样:优化数据选择
Perplexity.ai 使用高效采样技术,尤其是重要性采样,展示了 Best-of-N 采样策略的高级应用。
perplexity.ai 不是生成 N 个完整响应并选择最佳响应,而是在数据选择阶段应用采样原则。通过仔细选择测试数据的子集并根据其相关性对样本进行加权,这种方法实现了更高效、更有针对性的评估。重要性采样中的加权机制可以看作 Best-of-N 采样中使用的验证器的隐式形式。
分层计算:自适应评估策略
perplexity.ai 采用的分层或多级困惑度计算与计算最优扩展方法共享核心原则。
通过计算不同语言结构级别的困惑度,该方法可以根据被评估语言的规模和复杂性有效地调整其计算策略。这在概念上类似于计算最优扩展如何根据估计的问题难度调整其方法。
优化的硬件利用率:实现高效的混合方法
虽然 perplexity.ai 中优化的硬件利用率不是直接的测试时间计算策略,但它可以更有效地实施所有策略,尤其是混合方法。
通过将计算分布在运行不同 LLM 的不同硬件类型(CPU、GPU、专用 AI 芯片)上,perplexity.ai 有效地在硬件和模型级别实现了一种混合方法。这允许以最佳方式执行各种测试时间计算策略,可能并行运行不同的策略或根据任务的当前需求在它们之间切换。
方法之间的协同作用
perplexity.ai 中这些推理计算策略的实现突出了几个关键的协同作用:
- 上下文感知处理:滑动窗口技术与高效采样的结合允许广泛的上下文考虑和有针对性的相关数据选择。
- 自适应计算:分层计算方法与优化的硬件和模型利用率相结合,使系统能够根据任务复杂性动态分配计算资源。
- 平衡探索和利用:使用重要性抽样和滑动窗口技术在探索不同背景和利用最相关信息之间取得平衡。
- 可扩展性和效率:高效抽样与优化硬件利用率的结合使系统能够处理大规模任务,同时保持计算效率。
这些协同作用表明,结合多种测试时间计算策略可以带来更强大、更灵活的系统。通过利用不同方法的优势,像 perplexity.ai 这样的高级 AI 解决方案可以在各种任务和查询类型中实现卓越的性能。随着我们继续突破 LLM 功能的界限,我们可以期待看到这些推理计算策略的更复杂、更集成的实现出现。
10、LLM 优化的未来
Snell 等人和 Tam 等人的研究提出了一个令人信服的案例,让我们重新思考 LLM 的发展,超越当前“越大越好”的口号。Snell 等人的工作强调了现有和较小的 LLM 可以通过专注于测试时间计算方法获得显著的性能提升,为企业提供了一条改进 LLM 能力的途径,而无需进行昂贵的模型(重新)训练。例如,客户服务聊天机器人可以利用 Best-of-N 采样来生成不同的响应并选择最合适的响应,从而无需更大的模型即可提高用户满意度。
Tam 等人关于结构化输出权衡的研究结果强调了在施加格式限制时仔细考虑对推理能力的不利影响的重要性。虽然结构化输出对于作为涉及关系数据库的本地化工作流程的一部分的数据集成可能至关重要,但保留 LLM 对复杂语言查询执行细微推理的能力仍然至关重要。解决方案可以是一个简单的两阶段方法:首先允许模型以自然语言进行推理,然后将输出转换为结构化格式(例如,添加 .xml 格式的翻译记忆库)作为后处理步骤。
数据科学家和 AI 从业者都将在充分发挥这些进步的潜力方面发挥关键作用。仔细选择和组合测试时间计算策略将至关重要,并根据特定任务要求和资源限制进行量身定制。开发能够准确捕捉性能和效率之间权衡的稳健评估指标对于指导计算资源的最佳分配至关重要。将这些测试时间计算优化策略无缝集成到现有的 LLM 管道中,同时确保可扩展性和成本效益,对未来提出了重大挑战。
重要的是在推理时在这些策略的计算成本和它们提供的性能提升之间取得适当的平衡。这种权衡在代币预算可能成为限制因素的商业环境中尤为重要。最佳平衡可能涉及考虑训练更大模型的成本与采用复杂的测试时间计算策略的推理成本。最终,对于支付运行这些更复杂的推理方法所需的代币的最终用户来说,成本效益至关重要。本周早些时候,领先的 LLM 提供商 Anthropic 宣布了一项名为“提示缓存”的新功能,旨在将长而复杂的提示的效率提高 90%,并将延迟降低 85%,这也许并不奇怪。
展望未来,我预计甚至会出现更复杂的混合策略,可能由机器学习元优化器指导。这些未来系统可能会实时动态调整其计算策略,以响应任务和可用资源的不断变化的性质。我们还预见到硬件优化方法和集成开发环境的出现,从而简化这些策略的实施。LLM 测试时间计算优化的持续创新预示着未来这些强大的模型不仅功能更强大,而且更高效、更易于访问且更符合道德规范。
原文链接:8种测试时计算策略 - BimAnt















 2347
2347

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









