







1.用户代理
解析:User Agent中文名为用户代理,简称 UA,它是一个特殊字符串头,使得服务器能够识别客户使用的操作系统及版本、CPU 类型、浏览器及版本、浏览器渲染引擎、浏览器语言、浏览器插件等。
2.AttributeError: module ‘enum’ has no attribute 'IntFlag’
解析:pip uninstall enum34。
3.selenium
解析:Selenium是一个用于Web应用程序测试的工具。Selenium测试直接运行在浏览器中,就像真正的用户在操作一样。
4.<img>标签的alt属性
解析:如果无法显示图像,浏览器将显示替代文本。
5.cgi-bin
解析:CGI-BIN是一种特殊的目录,在进行交互式的WWW访问时,需要服务器上有相应的程序对访问者输入的信息进行处理,这些程序就是CGI程序。
6.cookie属性
解析:cookie常用属性,如下所示:
[1]value
[2]domain
[3]path
[4]expires
[5]secure
[6]HttpOnly
7.Selenium支持的操作系统,浏览器和编程语言
解析:
[1]编程语言:C#,Java,Python,PHP,Ruby,Perl和JavaScript
[2]操作系统:Android,iOS,Windows,Linux,Mac,Solaris。
[3]浏览器:谷歌浏览器,MozillaFirefox,InternetExplorer,Edge,Opera,Safari等。
说明:Selenium Remote Control(RC)与WebDriver API一起被称为Selenium 2.0。
8.Selenium工具套件
解析:Selenium组成部分,如下所示:

[1]Selenium集成开发环境[IDE]
[2]Selenium远程控制器[现已弃用]
[3]webdriver:SeleniumWebDriver提供了一个编程接口来创建和执行测试用例。编写测试脚本是为了识别网页上的Web元素,然后对这些元素执行所需的操作。
[4]SeleniumGrid
说明:SeleniumIDE仅作为MozillaFirefox和Chrome插件提供,它无法在Firefox和Chrome以外的浏览器上记录测试用例。记录的测试脚本也可以导出到C#,Java,Ruby或Python等编程语言。
9.Selenium组件和测试自动化工具的一些组件关系
解析:

10.Selenium WebDriver架构
解析:Selenium WebDriver API提供编程语言和浏览器之间的通信工具。如下所示:
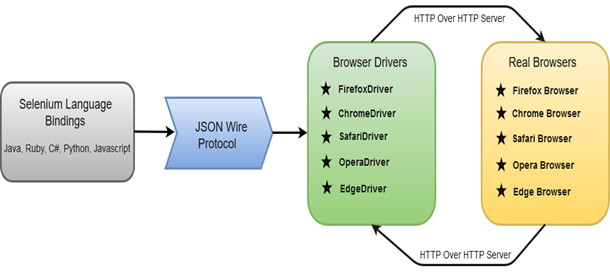
[1]Selenium语言绑定
[2]JSON有线协议
[3]浏览器驱动
[4]真正的浏览器:Selenium WebDriver支持的浏览器InternetExplorer,MozillaFirefox,GoogleChrome,Safari。
11.scrapy genspider命令
解析:用来创建爬虫模板的。如下所示:
[1]scrapy genspider -t crawl taobao2 taobao.com[crawl类型爬虫]
[2]scrapy genspider TaoBaoSpider taobao.com
12.PhantomJS
解析:PhantomJS是一个基于WebKit内核、无UI界面的浏览器,WebKit是一个开源的浏览器引擎。比如,主流的Safari,Google Chrome,傲游3,猎豹浏览器,百度浏览器,opera浏览器基于Webkit开发。PhantomJS会把网站数据加载到内存中,并执行页面上的JavaScript,但不会向用户展示图形界面。
13.Headless Chrome
解析:Headless模式在Windows中是Chrome59中的新特征,要使用Chrome需要安装chromedriver。
14.无头浏览器
解析:日常使用浏览器的步骤为:启动浏览器、打开一个网页、进行交互,而无头浏览器指的是使用脚本来执行以上过程的浏览器,能模拟真实的浏览器使用场景。
15.无头浏览器功能
解析:
[1]对网页进行截图保存为图片或pdf
[2]抓取单页应用[SPA]执行并渲染[解决传统HTTP爬虫抓取单页应用难以处理异步请求的问题]
[3]做表单的自动提交、UI的自动化测试、模拟键盘输入等
[4]用浏览器自带的一些调试工具和性能分析工具帮助分析问题
[5]在最新的无头浏览器环境里做测试、使用最新浏览器特性
[6]写爬虫做你想做的事情
说明:无头浏览器很多,包括但不限于:PhantomJS[基于Webkit],SlimerJS[基于Gecko],HtmlUnit[基于Rhnio],TrifleJS[基于Trident],Splash[基于Webkit]。
16.DEBUG: Crawled (404) <GET http://…/robots.txt> (referer: None)
解析:在settings.py中设置ROBOTSTXT_OBEY = False即可。
17.Splash
解析:Splash是一个JavaScript渲染服务,是一个带有HTTP API的轻量级浏览器,同时它对接了Python中的Twisted和QT库。利用它,同样可以实现动态渲染页面的抓取。
[1]异步方式处理多个网页渲染过程
[2]获取渲染后的页面的源代码或截图
[3]通过关闭图片渲染或者使用Adblock规则来加快页面渲染速度
[4]可执行特定的JavaScript脚本
[5]可通过Lua脚本来控制页面渲染过程
[6]获取渲染的详细过程并通过HAR[HTTP Archive]格式呈现
18.通过PyCharm调试Scrapy
解析:设置Script Path为D:\Anaconda3\Lib\site-packages\scrapy\cmdline.py即可。
19.Charles
解析:Charles是一款代理服务器,通过过将自己设置成系统[电脑或者浏览器]的网络访问代理服务器,然后截取请求和请求结果达到分析抓包的目的。如下所示:
[1]截取Http和Https网络封包。
[2]支持重发网络请求,方便后端调试。
[3]支持修改网络请求参数。
[4]支持网络请求的截获并动态修改。
[5]支持模拟慢速网络。
20.scrapy-redis
解析:scrapy-redis是scrapy框架基于redis数据库的组件,用于scrapy项目的分布式开发和部署。
21.CONCURRENT_REQUESTS
解析:Scrapy downloader并发请求[concurrent requests]的最大值,默认为16。
22.DOWNLOAD_DELAY
解析:下载器在下载同一个网站下一个页面前需要等待的时间。该选项可以用来限制爬取速度,减轻服务器压力。同时也支持小数。默认值为0。
23.cookie和session应用场景
解析:
[1]cookie应用场景
- 判断用户是否登陆过网站
- 保存上次登录的时间等信息
- 保存上次查看的页面
- 浏览计数
[2]session应用场景
- 网上商城中的购物车
- 保存用户登录信息
- 将某些数据放入session中,供同一用户的不同页面使用
- 防止用户非法登录
24.浏览器数据库IndexedDB
解析:IndexedDB就是浏览器提供的本地数据库,它可以被网页脚本创建和操作。如下所示:
[1]数据库:IDBDatabase对象
[2]对象仓库:IDBObjectStore对象
[3]索引:IDBIndex对象
[4]事务:IDBTransaction对象
[5]操作请求:IDBRequest对象
[6]指针:IDBCursor对象
[7]主键集合:IDBKeyRange对象
25.Twisted
解析:twisted是一个用python语言写的事件驱动的网络框架,它支持很多种协议,包括UDP,TCP,TLS和其他应用层协议,比如HTTP,SMTP,NNTM,IRC,XMPP/Jabber。
参考文献:
[1]Selenium:https://www.seleniumhq.org/
[2]Selenium教程:https://www.yiibai.com/selenium
[3]chromedriver与chrome版本映射表:http://chromedriver.storage.googleapis.com/index.html
[4]chromedriver与chrome版本映射表:http://npm.taobao.org/mirrors/chromedriver/
[5]Scrapy:https://scrapy.org/
[6]Scrapyd:https://scrapyd.readthedocs.io/en/stable/
[7]爬虫教程:https://piaosanlang.gitbooks.io/spiders/content/
[8]Getting Started with Headless Chrome:https://developers.google.com/web/updates/2017/04/headless-chrome
[9]Chrome DevTools Protocol:https://chromedevtools.github.io/devtools-protocol/
[10]GoogleChrome/puppeteer[Headless Chrome Node API]:[https://github.com/GoogleChrome/puppeteer][https://pptr.dev/]
[11]Scrapy Plugins[Plugins for the Scrapy framework]:https://github.com/scrapy-plugins
[12]Splash[A javascript rendering service]:https://splash.readthedocs.io/en/stable/
[13]scrapy-splash教程:https://splash-cn-doc.readthedocs.io/zh_CN/latest/scrapy-splash-toturial.html
[14]Charles:https://www.charlesproxy.com
[15]Redis命令:http://www.redis.cn/commands.html
[16]microsoftarchive/redis:https://github.com/microsoftarchive/redis/releases
[17]Redis教程:https://www.runoob.com/redis/redis-tutorial.html
[18]Scrapy-Redis’s documentation:https://scrapy-redis.readthedocs.io/en/v0.6.x/#
[19]Scrapy 0.24文档:https://scrapy-chs.readthedocs.io/zh_CN/0.24/index.html
[20]自动限速[AutoThrottle]扩展:https://scrapy-chs.readthedocs.io/zh_CN/0.24/topics/autothrottle.html
[21]浏览器数据库IndexedDB入门教程:http://www.ruanyifeng.com/blog/2018/07/indexeddb.html
[22]What is Twisted:https://twistedmatrix.com/trac/
















 381
381

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











