







粒度是指数据仓库的数据单位中保存数据的细化或综合程度的级别。细化程度越高,粒度级就越小;相反,细化程度越低,粒度级就越大。
数据的粒度一直是一个设计问题。在早期建立的操作型系统中,粒度是用于访问授权的。
当详细的数据被更新时,几乎总是把它存放在最低粒度级上。但在数据仓库环境中,对粒度不作假设。下图说明了粒度问题。
粒度的一个例子
左边是一个低粒度级,每个活动(在这里是一次电话)被详细记录下来,数据的格式如图所示。到月底每个顾客平均有2 0 0条记录(全月中每个电话都记录一次),因而总共需要40 000个字节。
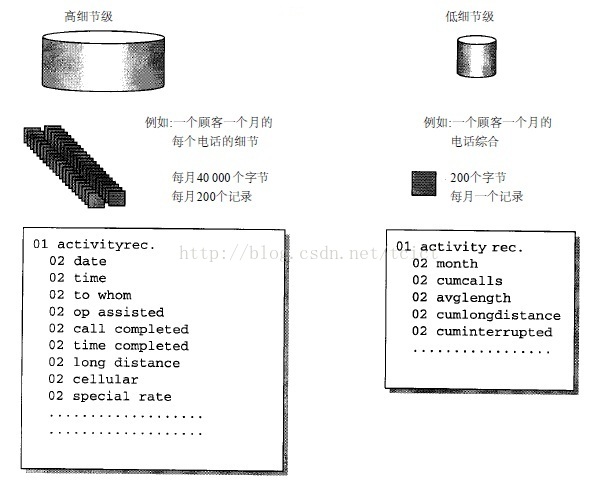
该图的右边是一个高粒度级。数据代表一位顾客一个月的综合信息,每位顾客一个月只有一个记录,这样的记录大约只需2 0 0个字节,记录的格式如图所示。
显然,如果数据仓库的空间很有限的话(数据量总是数据仓库中的首要问题),用高粒度级表示数据将比用低粒度级表示数据的效率要高得多。
高粒度级不仅只需要少得多的字节存放数据,而且只需要较少的索引项。然而数据量大小和原始空间问题不是仅有的应考虑的问题。为了访问大量数据,其处理能力的大小同样也是应考虑的一个因素。
所以,在数据仓库中数据压缩非常有用。当数据被压缩后就会大大节省所用的DASD存储空间,节省所需的索引项,以及节省处理数据的处理器资源。
但是,当提高粒度级时,数据压缩就会出现另一个问题,下图中表示作出的选择。
当提高数据粒度级时,数据所能回答查询的能力就会随之降低。换句话说,在一个很低的粒度级上你实际可以回答任何问题,但在高粒度级上,数据所能处理的问题的数量是有限的。
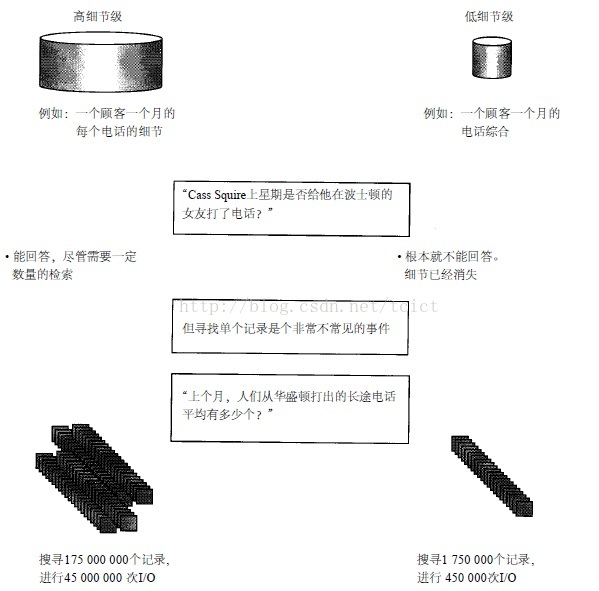
在一个D S S环境中这种查询类型是非常常见的。当然,它既可以在高粒度级上也可以在低粒度级上得到回答。但在回答这个问题时,在不同的粒度级上所使用的资源具有相当大的差异。在低粒度级上回答这个问题需要查询每一个记录,所以需要大量的资源来回答这个问题。
但在高粒度级上,数据进行了很大的压缩,而且能够提供一个答案。如果在高粒度级上包括了足够的细节,则使用高粒度级数据的效率将会高得多。
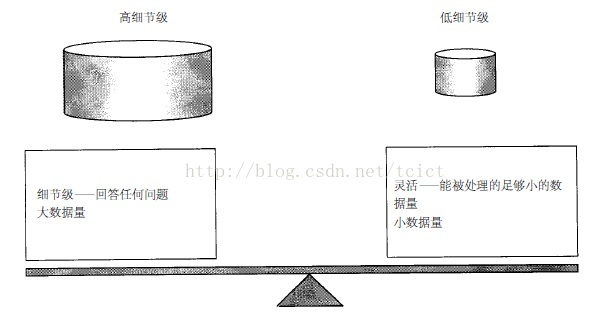
在管理数据的粒度问题中的权衡如图所示。在设计和构造数据仓库之初就必须仔细考虑这种权衡。
数据的粒度一直是一个设计问题。在早期建立的操作型系统中,粒度是用于访问授权的。
当详细的数据被更新时,几乎总是把它存放在最低粒度级上。但在数据仓库环境中,对粒度不作假设。下图说明了粒度问题。

粒度的一个例子
左边是一个低粒度级,每个活动(在这里是一次电话)被详细记录下来,数据的格式如图所示。到月底每个顾客平均有2 0 0条记录(全月中每个电话都记录一次),因而总共需要40 000个字节。
该图的右边是一个高粒度级。数据代表一位顾客一个月的综合信息,每位顾客一个月只有一个记录,这样的记录大约只需2 0 0个字节,记录的格式如图所示。
显然,如果数据仓库的空间很有限的话(数据量总是数据仓库中的首要问题),用高粒度级表示数据将比用低粒度级表示数据的效率要高得多。
高粒度级不仅只需要少得多的字节存放数据,而且只需要较少的索引项。然而数据量大小和原始空间问题不是仅有的应考虑的问题。为了访问大量数据,其处理能力的大小同样也是应考虑的一个因素。
所以,在数据仓库中数据压缩非常有用。当数据被压缩后就会大大节省所用的DASD存储空间,节省所需的索引项,以及节省处理数据的处理器资源。
但是,当提高粒度级时,数据压缩就会出现另一个问题,下图中表示作出的选择。
当提高数据粒度级时,数据所能回答查询的能力就会随之降低。换句话说,在一个很低的粒度级上你实际可以回答任何问题,但在高粒度级上,数据所能处理的问题的数量是有限的。
在一个D S S环境中这种查询类型是非常常见的。当然,它既可以在高粒度级上也可以在低粒度级上得到回答。但在回答这个问题时,在不同的粒度级上所使用的资源具有相当大的差异。在低粒度级上回答这个问题需要查询每一个记录,所以需要大量的资源来回答这个问题。
但在高粒度级上,数据进行了很大的压缩,而且能够提供一个答案。如果在高粒度级上包括了足够的细节,则使用高粒度级数据的效率将会高得多。
在管理数据的粒度问题中的权衡如图所示。在设计和构造数据仓库之初就必须仔细考虑这种权衡。















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









