







1. 简单的流程
knowledge-based推荐系统没有考虑特殊用户的偏好;也没有尝试去推断不同电影之间的相似性。以Internet Movie Database (IMDB)为例,基本流程可以概述为:
- 选择度量(或评分标准)为电影打分
- 决定电影在排行榜上出现的先决条件
- 计算每一部满足条件的电影的得分
- 按照分数的递减顺序输出电影列表
2. 度量 metric
以电影推荐为例:如果一部电影的评分高于另一部电影,那么它就被认为比另一部电影更好。鲁棒而可靠的度量标准对于电影评分来说非常重要,是影响推荐结果的关键。
度量的选择可以是任意的。例如,最简单的指标之一是电影评分。然而,这也有许多缺点。首先,电影评分不考虑电影的受欢迎程度。因此,一部被10万用户评为9.0级的电影将低于一部被100用户评为9.5级的电影。这是不可取的,因为一部只有100人观看和评分的电影很有可能迎合(cater to...)一个非常特殊的细分市场(a very specific niche),对普通人的吸引力不如前者大。众所周知,随着投票者人数的增加,一部电影的评分具有一定的“权威性”,并且可以反映电影质量和大众化的价值。换句话说,评分很低的电影并不十分可靠。一部由五位用户评为10/10的电影并不一定意味着它是一部好电影。因此,我们需要的是一个能够在某种程度上考虑电影评分和它获得的投票数的指标。这将使10万人观看的大片(评分8)比100人观看的艺术片(评分9)更受欢迎。这里,将直接使用IMDB的加权评分公式作为度量:
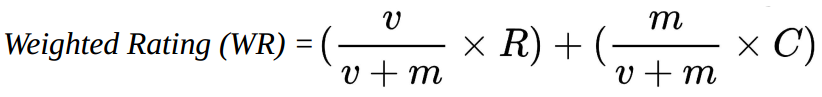
- v是电影获得的票数
- m是电影在图表中所需的最小投票数(前提条件)
- R是电影的平均得分
- C是数据库中所有电影的平均得分
3. 先决条件 Prerequisties
在上面公式中,m明显是先决条件,也就是说,只有投票数超过一定阈值的电影才有可能参与最终评分的计算。
和度量一样,m值的选择也是任意的。换言之,m没有统一的取值原则。最好先尝试m的不同取值,然后选择能给出最佳推荐结果对应的m值。唯一需要记住的是,m值越高,对电影受欢迎程度的强调越高,因此被选择的概率越高。
对于此处的推荐系统设计,我们将使用第80百分位电影获得的票数作为m的值。换句话说,对于要在排名中考虑的电影,它必须获得超过我们数据集中存在的电影的至少80%的选票。此外,第80百分位电影获得的选票用前面描述的加权公式计算分数值。
import pandas as pd
import numpy as np
df = pd.read_csv('C:/Users/Administrator/Desktop/RecoSys/data/movies_metadata.csv')
m = df['vote_count'].quantile(0.80)
print(m)
>>> 50.0另一个先决条件是电影的持续时间。这里只考虑长度大于45分钟小于300分钟的电影。因此,定义一个新的DataFrame,用它保存所有满足条件的电影列表。
q_movie = df[ (df['runtime'] >= 45) & (df['runtime'] <= 300) ]
q_movie = q_movie[ q_movie['vote_count'] >= m ]
print(q_movie.shape)
>>> (8963, 24)4. 计算得分 Score
在计算最终电影分数之前,需要计算最后一个值是C(数据集中所有电影的平均评分):
C = df[ 'vote_average' ].mean()
print(C)
>>> 5.618207215133889因此,我们可以根据上面的公式,对于满足先决条件的电影计算得分:
def weighted_rating(x, m=m, C=C):
v = x[ 'vote_count' ]
R = x[ 'vote_average' ]
return ( v/(v+m) * R ) + (m/(v+m) * C)
q_movie['score'] = q_movie.apply(weighted_rating, axis = 1)
print(q_movie['score'].head(5))
>>>
0 7.680953
1 6.873979
2 6.189510
4 5.681661
5 7.646235
Name: score, dtype: float645. 排序和输出 Sorting and Output
q_movie = q_movie.sort_values('score', ascending=False)
q_movie[['title', 'vote_count', 'vote_average', 'score', 'runtime']].head(10)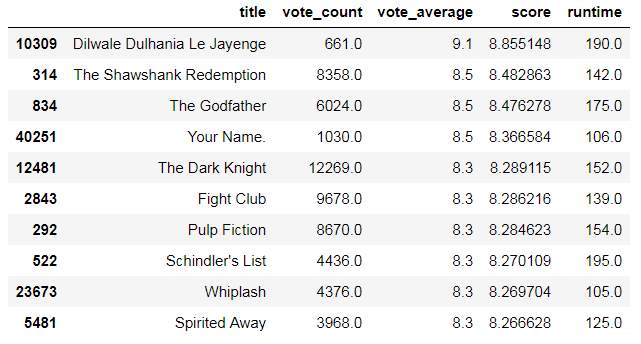
6. 总结与提升
在推荐系统设计中,往往还需要人机交互的功能。在前面设计基础上,需要执行以下任务:
- 向用户询问他/她正在寻找的电影类型
- 向用户询问电影的持续时间
- 向用户询问推荐的电影时间表
- 使用收集的信息,向用户推荐具有高评分(根据IMDB公式)且满足上述条件的电影
查看原始数据集中包含的所有的特征:
import pandas as pd
import numpy as np
df = pd.read_csv('C:/Users/Administrator/Desktop/RecoSys/data/movies_metadata.csv')
df.columns
>>>
Index(['adult', 'belongs_to_collection', 'budget', 'genres', 'homepage', 'id',
'imdb_id', 'original_language', 'original_title', 'overview',
'popularity', 'poster_path', 'production_companies',
'production_countries', 'release_date', 'revenue', 'runtime',
'spoken_languages', 'status', 'tagline', 'title', 'video',
'vote_average', 'vote_count'], dtype='object')削减DataFrame,使得新的数据结构仅仅包括我们需要的特征:
df = df[ ['title','genres', 'release_date', 'runtime', 'vote_average', 'vote_count'] ]
df.head()
从release_date特征中提取出year,并且提出year特征中的异常值(NAN):
# convert release_date into pandas datetime format
df['release_date'] = pd.to_datetime(df['release_date'], errors = 'coerce')
# Extract year from datetime
df['year'] = df['release_date'].apply(lambda x: str(x).split('-')[0] if x != np.nan else np.nan)
# conver object to int; and convert NAT to 0
def convert_int(x):
try:
return int(x)
except:
return 0
df['year'] = df['year'].apply(convert_int)
df['year']有了year特征,就不在需要release_date特征了,因此删除:
df = df.drop('release_date', axis=1)
df.head(5)
从上面图我们可以看出来,genres特征并不满足交互处理的需求,首先看一下genres特征的内容:
type(df.iloc[0]['genres'])
print(df.iloc[0]['genres'])
>>>
str
[{'id': 16, 'name': 'Animation'}, {'id': 35, 'name': 'Comedy'}, {'id': 10751, 'name': 'Family'}]我们可以观察到输出是一个字符串化的字典。为了使这个特性可用,我们必须将这个字符串转换成一个Python字典。幸运的是,python允许我们访问一个名为literal_eval(在ast库中可用)的函数,它正好做到了这一点。literal_eval解析传入它的任何字符串,并将其转换为相应的python对象。此外,应该注意的是,上面的genre输出包括了id和name两个要素。在我们实际应用上,我们仅仅需要name属性:
from ast import literal_eval
#Convert all NaN into stringified empty lists
df['genres'] = df['genres'].fillna('[]')
#Apply literal_eval to convert to the list object
df['genres'] = df['genres'].apply(literal_eval)
#Convert list of dictionaries to a list of strings
df['genres'] = df['genres'].apply(lambda x: [i['name'] for i in x] if isinstance(x,list) else [])
df.head()
如果电影有多个流派,我们将创建该电影的多个副本,每个电影都有一个流派。例如, 电影Just Go With It 具有 romance 和
comedy 属性, 这时候我们需要把它拆分成两行: 一行是 Just Go With It (具有romance属性);另一行是 Just Go With It (具有comedy 属性)。
#Create a new feature by exploding genres
s = df.apply(lambda x: pd.Series(x['genres']),axis=1).stack().reset_index(level=1,drop=True)
#Name the new feature as 'genre'
s.name = 'genre'
#Create a new dataframe gen_df which by dropping the old 'genres' feature and adding the new 'genre'.
gen_df = df.drop('genres', axis=1).join(s)
gen_df.head()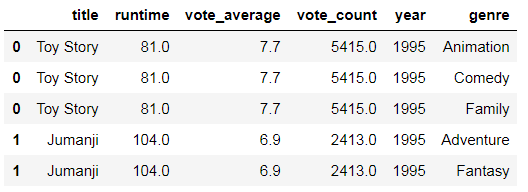
这样,原始的DataFrame经过数据清洗后,就很方便进行推荐系统设计了。
===========================================================================================
设计人机交互式推荐系统功能,需要满足三个功能子模块:
- 获得用户偏好的输入
- 提取电影库中所有与用户偏好相关的电影
- 利用前面的方法反馈推荐结果
def build_RecSys(gen_df, percentile=0.8):
print("Input preferred genre")
genre = input()
print("Input shortest duration")
low_time = int(input())
print("Input longest duration")
high_time = int(input())
print("Input earliest year")
low_year = int(input())
print("Input latest year")
high_year = int(input())
movies = gen_df.copy()
movies = movies[(movies['genre'] == genre) &
(movies['runtime'] >= low_time) & (movies['runtime'] <= high_time) &
(movies['year'] >= low_year) &(movies['year'] <= high_year)]
C = movies['vote_average'].mean()
m = movies['vote_count'].quantile(percentile)
q_movies = movies.copy().loc[movies['vote_count'] >= m]
q_movies['score'] = q_movies.apply(lambda x: (x['vote_count']/(x['vote_count']+m) * x['vote_average'])
+ (m/(m+x['vote_count']) * C),axis=1)
q_movies = q_movies.sort_values('score', ascending=False)
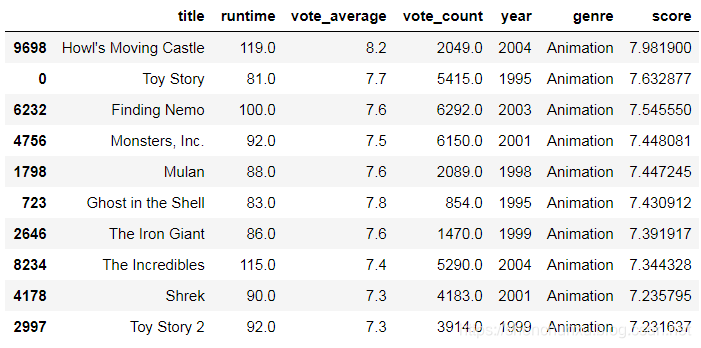
return q_movies测试结果:














 427
427











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









