







哈希表定义:
如果记录的关键字与存储位置存在一一映射的关系,你们就可以通过待查记录的关键字,计算其存储位置,直接找到该记录。
关键字K到D的映射关系H表示为H(key):K->D,key∈K
K为主关键字集合,H称为哈希函数或散列函数。D为一个连续的存储单元。按照哈希函数构建的表称为哈希表/散列表。同时有关的重要概念是D的大小m,即哈希表的地址区间长度。
另外一个概念是冲突,即如果在一个单元格上插入一个元素,之后另一个元素通过哈希函数计算出的位置也在这个单元格上,即不同关键字的哈希函数值也可能相同。哈希函数值相同的关键字称为同义词。所以要进行冲突处理。
为什么要用哈希表:能够通过待查记录的关键字,直接找到存储位置,提高查找效率
哈希表特点:一般单元格不会存满,查找算法即为存储算法,不可避免的发生冲突,一个好的哈希表应该有好的哈希函数和冲突处理方法
哈希表的构造过程:
1、 设计哈希函数
2、 进行冲突方法处理
进行哈希函数的设计:
经过哈希函数映射到地址中任一地址概率是相等的,则称为均匀的哈希函数,越均匀,越少冲突。所以设计有两原则,一,计算过程尽量简单,二,哈希函数尽量均匀。
通常考虑的因素有:
• 计算哈希函数所需时间
• 关键字的长度
• 哈希表的大小
• 关键字的分布情况
• 记录的查找频率
1、 直接寻址法:
取关键字或关键字的某个线性函数值为散列地址。即H(key)=key或H(key) = a*key + b,其中a和b为常数(这种散列函数叫做自身函数)。但是实际应用上,关键字是很少连续的,采用这种特殊的哈希函数会造成哈希表空间浪费。

如图,按照年龄存储,H(key)=key-17
int get_key1(int key) //直接定址法
{
return key;
}
2、 除,留余数法:
对于地址长度为m的哈希表,取某个不大于m的数p为模,将哈希函数定义为H(key)=key%p(p<=m)
值得注意的是,模p的选择十分重要,当p去不大于m且最接近m的素数(保证key对p取模后,再对p取模等于0),或不包含小于20的质因子的合数时,能是哈希地址均匀分布。
int get_key2(int key, int length) //除留余数法
{
return (3*key) % length;
}
3、 数字分析法:
分析一组数据,比如一组员工的出生年月日,这时我们发现出生年月日的前几位数字大体相同,这样的话,出现冲突的几率就会很大,但是我们发现年月日的后几位表示月份和具体日期的数字差别很大,如果用后面的数字来构成散列地址,则冲突的几率会明显降低。因此数字分析法就是找出数字的规律,尽可能利用这些数据来构造冲突几率较低的散列地址。
4、 折叠法:
将关键字分割成位数相同的几部分,最后一部分位数可以不同,然后取这几部分的叠加和(去除进位)作为散列地址。
例:设哈希地址长度为10000,关键字key=401108105302169891,允许的地址为4位十进制数。那么进行拆分相加,得到最后地址为0040+1108+1053+0216+9891 =(1)2308去掉最高为1,则地址即为2308
int get_key3(int key) //折叠法
{
int sum = 0;
int j = 100;
int q = 0; //得到每次取得的数
while (key != 0)
{
q = key % j; //对key进行分割
sum += q; //加上分割的数
key = key / j;
}
return sum;
}
5、 平方取中法
先取关键字的平方,根据哈希表长度m的大小,选取平方数的中间若干为作为哈希地址。
例:
设哈希表长度为1000,取关键字平方值的中间三位
| 关键字 | 关键字平方 | 哈希函数值 |
|---|---|---|
| 3569 | 12737761 | 377 |
| 7653 | 58568409 | 684 |
| 5891 | 34703881 | 38 |
int get_key4(int key) //取中法
{
//这个是长度为1000的哈希表,取百千万位
key = key * key / 100;
if (key >= 1000)
{
key = key - key / 1000 * 1000;
}
return key;
}
处理哈希表冲突的方法:
链地址法:
将关键字的同义词记录链接到同一个单链表上,此单链表称为同义词链表。
例:哈希表T是由m个头指针数组组成的指针数组,凡是为i的记录,都插入到T[i]的链表处,其他没有记录的头指针都置为空。
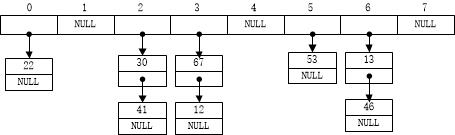
由上图,我们可以看到,哈希表是一个指针数组,当找到位置就能把他加上。如果发生冲突,那么就在当前位置的元素后面接上,形成一个单链表。
typedef struct Node
{
int data; //数据域
struct Node * next; //指针域
}Node;
typedef struct HashTable
{
Node ** list; //存储Node*的数组
int length; //表长度
int count; //元素个数
int(*hash)(int key, int length); //函数指针,哈希函数
}HashTable;
//哈希表的初始化,主要是把指针数组的每一个元素都置空
HashTable * initTable(HashTable * table, int len, int(*hash)(int key, int length)) //哈希表初始化
{
//分配内存,初始化
table = (HashTable *)malloc(sizeof(HashTable));
table->count = 0;
table->length = len;
table->list = (Node **)malloc(len * sizeof(HashTable));
for (int i = 0; i < len; i++)
{
table->list[i] = NULL;
}
table->hash = hash; //指定哈希函数
return table;
}
//查找函数,通过哈希函数进行定位。找到位置后,在链表下往下查找。
Node * searchTable(HashTable * table, int key)
{
int ans = table->hash(key, table->length);
//通过哈希函数得到位置
if (table->list[ans] == NULL) return NULL;
//如果当前位置为空则返回NULL
else
//如果当前位置上已经有元素,则开始查找
{
Node * p = table->list[ans];
for (; p != NULL; p = p->next)
{
if (p->data == key) return p;
//沿着链表找,直到找到为止,找到即返回
}
}
return NULL;
//如果到最后都还没找到的话,那还是返回NULL
}
//插入函数,先通过查找函数定位到表中位置,判断是否有这个elem已存在表中。如果p!=NULL,那么就说明表中本身就有这个元素,无法插入。如果没有这个元素的话,那么就可以进行插入,插入的方法与单链表插入操作相同。
void insertTable(HashTable * table, int elem)
{
Node * p = searchTable(table, elem);
if (p != NULL) return;
//即表上已有这个元素,无法插入重复的数据
else
{
int ans = table->hash(elem, table->length);
Node * newNode = (Node *)malloc(sizeof(Node));
newNode->data = elem;
newNode->next = NULL;
//用头插法进行插入
newNode->next = table->list[ans];
table->list[ans] = newNode;
table->count++;
}
return;
}
//删除函数,先通过查找函数定位查找,如果没有这个元素则无法删除。
void deleteTable(HashTable * table, int elem, int * e)
{
Node * p = searchTable(table, elem);
if (p == NULL) return;
//如果没有这个元素则返回
else
{
int ans = table->hash(elem, table->length);
Node * q = table->list[ans];
//找到元素所在的位置上
p = table->list[ans];
for (; p != NULL; p = p->next) //沿着链表找
{
//与单链表删除相似
if (p->data == elem)
{
*e = p->data;
if (p == table->list[ans])
{
table->list[ans] = p->next;
free(p);
p = NULL;
}
else
{
q->next = p->next;
}
table->count--;
return;
}
q = p;
}
}
return;
}
开放定址法:
如果插入时发生冲突,那么就另寻地址,如果这个新的地址不冲突,即没有元素则插入,否则继续查找,直到找到空闲地址为止。在探测过程中,求得一系列地址称为探测地址序列。有两种常用开放定址法:线性探测法和二次探测法
线性探测法:将哈希表看作一个循环空间,若此单元格有元素,则到隔壁的单元格查找,如果走到哈希表末尾则重哈希表头继续找。那么线性探测法的探测地址序列可表示为:
Hnew = (H(key)+1)%m Hnew为冲突时探测的新空间
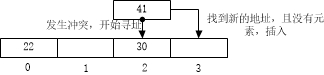
线性探测法处理冲突虽然简单清晰,但却容易造成堆聚现象,即存入哈希表的记录连成一片。那么如果堆聚的记录越多,发生冲突的探测次数越多,降低查找效率。
为解决线性探测法的堆聚现象,我们使用二次探测法。二次探测法生成的探测序列不是连续的,而是跳跃性的。可表示为Hnew = (H(key)+di)%m
其中,di = 1²,-1²,2²,-2²…
所以探测时会在第一次冲突位置的左右跳动寻找。

但是上面两个探测方法都有一个相同的问题。那就是查找。我们的查找一般都是判断当前单元格是否为空,如果为空且不等于要查找的的值,那么说明表中不存在这个值。否则的话继续往下找。
那么如果像此例子一样,在查找之前,把要查找的值的前一个元素删除了,那么走到空的单元格,查找会退出,返回找不到此元素。
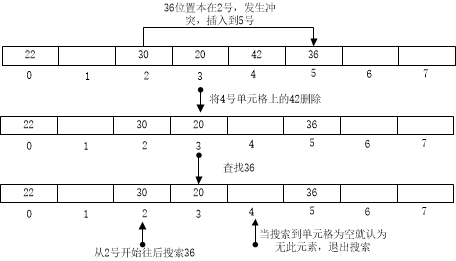
解决方法:添加标志位tag,当tag=1说明这个单元格有元素,tag=0说明这个单元格没有元素一直都为空,tag=-1说明这个单元格曾有元素,但是被删了。那么我们的删除操作即为假删,就是保留被删除的元素在表中,但是将其标志位改变为-1。
typedef struct HashTable
{
int * list;
int size;
int count;
int *tag;
//设置标志位,-1为删除,1为存在,0为空
int(*hash)(int key, int length);
int(*collision)(int key, int length); //处理冲突函数
}HashTable;
//线性定址法
int collision1(int key, int length)
{
int value = (key + 1) % length;
return value;
}
//二次定址法
int collision2(int key, int length)
{
//通过计算,得到跳跃的value值
int static i = 0;
int static j = 1;
int value = 0;
value = abs((int)(key + pow(-1, i) * pow(j,2)) % length);
if (i % 2 != 0) j++;
i++;
return value;
}
//初始化函数,这里主要给结构体内所有值赋值,并且指定函数。对每一个tag都赋值为0.
HashTable * initHash(HashTable * table, int length, int(*hash)(int key, int length), int(*collision)(int key, int length))
{
table = (HashTable *)malloc(sizeof(HashTable));
table->size = length;
table->count = 0;
table->list = (int *)malloc(sizeof(int) * length);
table->hash = hash;
table->tag = (int *)malloc(sizeof(int) * length);
table->collision = collision2;
for (int i = 0; i < length; i++)
{
table->tag[i] = 0;
}
return table;
}
//查找函数,对元素在表中进行查找。如果发现此处有元素,那么处理冲突。
int searchHash(HashTable * table, int key)
{
int i = 0;
int value = table->hash(key, table->size);
while ((1 == table->tag[value] && table->list[value] != key) || -1 == table->tag[value])
//当此位置有元素且不等于key时,或者等于key但是此元素已被删除时
{
//处理冲突
value = table->collision(value, 10);
}
if (table->list[value] == key) return -1;
//如果有此元素,返回-1
return 0;
}
//插入函数
void insertHash(HashTable * table, int key)
{
if (searchHash(table, key) == -1) //表中有此元素则不插入
{
return;
}
else
{
int value = table->hash(key, table->size);
while (table->tag[value] == 1 )
//只要位置上面有元素,那么就要往后找
{
value = table->collision(value, table->size);
}
if (table->tag[value] == 0 || table->tag[value] == -1) //当位置上为空或删除时,可进行插入
{
table->list[value] = key;
table->tag[value] = 1;
table->count++;
}
return;
}
}
//删除函数
void deleteHash(HashTable * table, int elem, int *e)
{
if (searchHash(table, elem) == 0)return;
//找不到元素
else
{
int value = table->hash(elem, table->size);
while ((table->list[value] != elem && table->tag[value] == 1) || table->tag[value] == -1)
//当此位置有元素且不等于key时,或者等于key但是此元素已被删除时,处理冲突
{
value = table->collision(value, table->size);
}
//如果找到元素就删除
if (table->list[value] == elem && table->tag[value] == 1)
{
*e = table->list[value];
table->tag[value] = -1;
table->count--;
}
return;
}
}哈希表的查找性能:
对散列表查找效率的量度,依然用平均查找长度来衡量。
查找过程中,关键码的比较次数,取决于产生冲突的多少,产生的冲突少,查找效率就高,产生的冲突多,查找效率就低。因此,影响产生冲突多少的因素,也就是影响查找效率的因素。影响产生冲突多少有以下三个因素:
散列函数是否均匀;
处理冲突的方法;
散列表的装填因子。
散列表的装填因子定义为:α= 填入表中的元素个数 / 散列表的长度
α是散列表装满程度的标志因子。由于表长是定值,α与“填入表中的元素个数”成正比,所以,α越大,填入表中的元素较多,产生冲突的可能性就越大;α越小,填入表中的元素较少,产生冲突的可能性就越小。
实际上,散列表的平均查找长度是装填因子α的函数,只是不同处理冲突的方法有不同的函数。















 5439
5439

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









