







一. 引入
在日常生活中,经常遇到找零钱的问题。假设1元、2元、5元、10元、20元、50元、100元的纸币分别有c0, c1, c2, c3, c4, c5, c6张。现在要用这些钱来支付K元,至少要用多少张纸币?
很显然,每一步尽可能用面值大的纸币即可。这就是日常生活中贪心算法思想的使用。
二. 概念
百度百科的定义是:
贪心算法(又称贪婪算法)是指,在对问题求解时,总是做出在当前看来是最好的选择。也就是说,不从整体最优上加以考虑,他所做出的是在某种意义上的局部最优解。
贪心是一种特殊的动态规划,动态规划的本质是独立的子问题,而贪心则是每次可以找到最优的独立子问题。后面我会细说两者的异同点。
三.最小生成树
图示
生成树,就是用边来把所有的顶点连通起来,前提条件是最后形成的连通图中不能存在回路,所以就形成这样一个无向图。
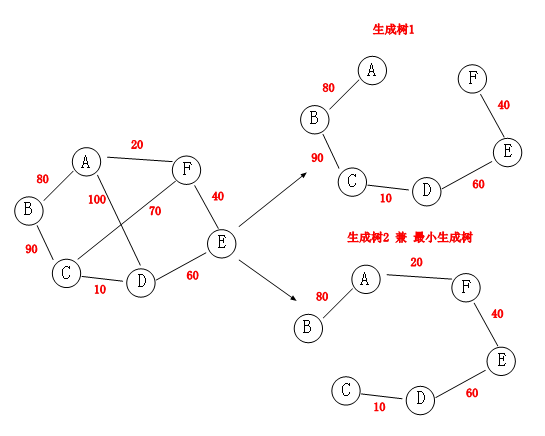
推理:假设图中的顶点有n个,则生成树的边有n-1条,多一条会存在回路,少一路则不能把所有顶点连通起来,如果非要在图中加上权重,则生成树中权重最小的叫做最小生成树。
Prim算法
算法简单描述
1. 输入:一个加权连通图,其中顶点集合为V,边集合为E;
2. 初始化:Vnew = {x},其中x为集合V中的任一节点(起始点),Enew = {},为空;
3. 重复下列操作,直到Vnew = V:
a.在集合E中选取权值最小的边<u,v>,其中u为集合Vnew中的元素,而v不在Vnew集合当中,并且v∈V(如果存在有多条满足前述条件即具有相同权值的边,则可任意选取其中之一);
b.将v加入集合Vnew中,将<u, v>边加入集合Enew中;
4. 输出:使用集合Vnew和Enew来描述所得到的最小生成树。四.Prim编码
图的存储有很多方式,邻接矩阵,邻接表,十字链表等等,当然都有自己的适合场景,下面分别用邻接矩阵和邻接表。
其中邻接矩阵需要采用两个数组,一个是保存顶点信息的一维数组,另一个是保存边信息的二维数组。
邻接矩阵:
/*
* prim最小生成树
*
* 参数说明:
* start -- 从图中的第start个元素开始,生成最小树
*/
public void prim(int start) {
int num = mVexs.length; // 顶点个数
int index=0; // prim最小树的索引,即prims数组的索引
char[] prims = new char[num]; // prim最小树的结果数组
int[] weights = new int[num]; // 顶点间边的权值
// prim最小生成树中第一个数是"图中第start个顶点",因为是从start开始的。
prims[index++] = mVexs[start];
// 初始化"顶点的权值数组",
// 将每个顶点的权值初始化为"第start个顶点"到"该顶点"的权值。
for (int i = 0; i < num; i++ )
weights[i] = mMatrix[start][i];
// 将第start个顶点的权值初始化为0。
// 可以理解为"第start个顶点到它自身的距离为0"。
weights[start] = 0;
for (int i = 0; i < num; i++) {
// 由于从start开始的,因此不需要再对第start个顶点进行处理。
if(start == i)
continue;
int j = 0;
int k = 0;
int min = INF;
// 在未被加入到最小生成树的顶点中,找出权值最小的顶点。
while (j < num) {
// 若weights[j]=0,意味着"第j个节点已经被排序过"(或者说已经加入了最小生成树中)。
if (weights[j] != 0 && weights[j] < min) {
min = weights[j];
k = j;
}
j++;
}
// 经过上面的处理后,在未被加入到最小生成树的顶点中,权值最小的顶点是第k个顶点。
// 将第k个顶点加入到最小生成树的结果数组中
prims[index++] = mVexs[k];
// 将"第k个顶点的权值"标记为0,意味着第k个顶点已经排序过了(或者说已经加入了最小树结果中)。
weights[k] = 0;
// 当第k个顶点被加入到最小生成树的结果数组中之后,更新其它顶点的权值。
for (j = 0 ; j < num; j++) {
// 当第j个节点没有被处理,并且需要更新时才被更新。
if (weights[j] != 0 && mMatrix[k][j] < weights[j])
weights[j] = mMatrix[k][j];
}
}
// 计算最小生成树的权值
int sum = 0;
for (int i = 1; i < index; i++) {
int min = INF;
// 获取prims[i]在mMatrix中的位置
int n = getPosition(prims[i]);
// 在vexs[0...i]中,找出到j的权值最小的顶点。
for (int j = 0; j < i; j++) {
int m = getPosition(prims[j]);
if (mMatrix[m][n]<min)
min = mMatrix[m][n];
}
sum += min;
}
// 打印最小生成树
System.out.printf("PRIM(%c)=%d: ", mVexs[start], sum);
for (int i = 0; i < index; i++)
System.out.printf("%c ", prims[i]);
System.out.printf("\n");
}具体完整工程代码见我的github。
https://github.com/shibing624/BlogCode/blob/master/src/main/java/xm/math/mst/ListUDG.java
邻接表也是类似,不过要简单一些:
/*
* 创建图(用已提供的矩阵)
*
* 参数说明:
* vexs -- 顶点数组
* edges -- 边
*/
public ListUDG(char[] vexs, EData[] edges) {
// 初始化"顶点数"和"边数"
int vlen = vexs.length;
int elen = edges.length;
// 初始化"顶点"
mVexs = new VNode[vlen];
for (int i = 0; i < mVexs.length; i++) {
mVexs[i] = new VNode();
mVexs[i].data = vexs[i];
mVexs[i].firstEdge = null;
}
// 初始化"边"
for (int i = 0; i < elen; i++) {
// 读取边的起始顶点和结束顶点
char c1 = edges[i].start;
char c2 = edges[i].end;
int weight = edges[i].weight;
// 读取边的起始顶点和结束顶点
int p1 = getPosition(c1);
int p2 = getPosition(c2);
// 初始化node1
ENode node1 = new ENode();
node1.ivex = p2;
node1.weight = weight;
// 将node1链接到"p1所在链表的末尾"
if (mVexs[p1].firstEdge == null)
mVexs[p1].firstEdge = node1;
else
linkLast(mVexs[p1].firstEdge, node1);
// 初始化node2
ENode node2 = new ENode();
node2.ivex = p1;
node2.weight = weight;
// 将node2链接到"p2所在链表的末尾"
if (mVexs[p2].firstEdge == null)
mVexs[p2].firstEdge = node2;
else
linkLast(mVexs[p2].firstEdge, node2);
}
}具体完整工程代码见我的github。
https://github.com/shibing624/BlogCode/blob/master/src/main/java/xm/math/mst/ListUDG.java
五.贪心算法vs动态规划算法
异同点
同:动态规划和贪心算法都是一种递推算法,均有局部最优解来推导全局最优解。
异:
贪心算法:
- 贪心算法中,作出的每步贪心决策都无法改变,因为贪心策略是由上一步的最优解推导下一步的最优解,而上一步之前的最优解则不作保留;
- 由 1 可以知道贪心法正确的条件是:每一步的最优解一定包含上一步的最优解。
动态规划算法:
- 全局最优解中一定包含某个局部最优解,但不一定包含前一个局部最优解,因此需要记录之前的所有最优解;
- 动态规划的关键是状态转移方程,即如何由以求出的局部最优解来推导全局最优解;
- 边界条件:即最简单的,可以直接得出的局部最优解。
贪心算法的缺点
贪心法的缺点:
- 不能保证求得的最后解是最佳的;
- 不能用来求最大或最小解问题;
- 只能求满足某些约束条件的可行解的范围。
实现该算法的过程,从问题的某一初始解出发;
while 能朝给定总目标前进一步 do
求出可行解的一个解元素;
由所有解元素组合成问题的一个可行解 举个栗子:
还是给钱问题:
比如中国的货币,只看元,有1元2元5元10元20、50、100
如果我要16元,可以拿16个1元,8个2元,但是怎么最少呢?
如果用贪心算,就是我每一次拿那张可能拿的最大的。
比如16,我第一次拿20拿不起,拿10元,OK,剩下6元,再拿个5元,剩下1元,
也就是3张:10、5、1。
每次拿能拿的最大的,就是贪心。 但是一定注意,贪心得到的并不是最优解,也就是说用贪心不一定是拿的最少的张数。贪心只能得到一个比较好的解,而且贪心算法很好想得到。
再注意,为什么我们的钱可以用贪心呢?因为我们国家的钱的大小设计,正好可以使得贪心算法算出来的是最优解(一般国家的钱币都应该这么设计)。
如果设计成别的样子情况就不同了,
比如:
某国的钱币分为:1元,3元,4元
如果要拿6元钱,怎么拿?
贪心的话:先拿4元,再拿两个1元,一共3张钱。
实际最优呢?两张3元就够了。给钱问题编码
问题:有最小面额为 11 5 1的三种人民币,用最少的张数找钱?
要求:比较 动态规划与贪心算法 解决问题
贪心算法解题
/***************************贪心算法********************************
*方法:
* Num_Value[i]表示 面额为VALUEi 的人民币用的张数
* 能用大面额的人民币,就尽量用大面额
*/
static int Greed(int money, int Num_Value[]) {
//要找开 money元人民币,Num_Value[1~3]保存 三种面额人民币的张数
int total = 0; //总张数,返回值也即是总张数。
Num_Value[1] = 0;
Num_Value[2] = 0;
Num_Value[3] = 0;
for (int i = money; i >= 1; ) {
if (i >= VALUE1) {
Num_Value[1]++;
i -= VALUE1;
total++;
} else if (i >= VALUE2) {
Num_Value[2]++;
i -= VALUE2;
total++;
} else if (i >= VALUE3) {
Num_Value[3]++;
i -= VALUE3;
total++;
} else {
}
}
return total;
}动态规划算法解题
//-------------------------求最小值---------------------------------
static int min(int a, int b, int c) {
return a < b ? (a < c ? a : c) : (b < c ? b : c);
}
//-------------------------动态规划算法-------------------------------
static int DP_Money(int money, int Num[]) {
//获得要找开money元钱,需要的人民币总张数
int i;
for (i = 0; i <= VALUE2; i++) { //0~4 全用 1元
Num[i] = i;
}
for (i = VALUE2; i <= money; i++) { //从5元开始 凑钱
if (i - VALUE1 >= 0) { //如果比 11 元大,说明多了一种用11元面额人民币的可能
//从用 11元、5元、1元中 选择一个张数小的
Num[i] = min(Num[i - VALUE1] + 1, Num[i - VALUE2] + 1, Num[i - VALUE3] + 1);
} else { //从5元、1元中 选择一个张数小的
Num[i] = Math.min(Num[i - VALUE2] + 1, Num[i - VALUE3] + 1);
}
}
return Num[money];
}具体完整实现的工程代码见我的github。
https://github.com/shibing624/BlogCode/blob/master/src/main/java/xm/math/mst/TanxinVSDongtaiGuihua.java
参考
- 百度百科:http://baike.baidu.com/link?url=NgaK-CjbKPvd88hpTibuIB5_kN0U0Q9pNZg5mcHp1SLVUDQL9r89orkShYE3B5Dw9jOersjJKqt9WF1vBwMfnyjX1TCzLgRXfKXBeMMwot48kS9cc_17m4V_yWewNcni
- csdn动态规划:http://blog.csdn.net/mingzai624/article/details/51543728
- prim算法:http://blog.csdn.net/yeruby/article/details/38615045
- 动态规划算法对比:http://blog.csdn.net/jarvischu/article/details/6056963















 352
352











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









