









来源于李宏毅老师机器学习课程,笔记是其中meta learning部分,few-shot learning学习也可以观看此部分课程。
课程主页:http://t.cn/Exykrk9
video: http://t.cn/ExykrkC
bilibili:https://www.bilibili.com/video/BV1Gb411n7dE?p=32

meta learning和life-long learning区别。
- life-long关注于怎么用一个模型学好所有的任务,及对新任务良好效果以及旧任务的不遗忘。
- meta不同任务可以有不同的模型,但是可以从之前的任务中学习到知识,模型在新任务上可以学得更快更好。

meta learning是通过训练数据 D t r a i n D_{train} Dtrain训练学习算法F,输出一个拟合函数 f ∗ f^* f∗,用于预测。

ML是找一个函数f来拟合训练数据。
Meta通过训练数据拟合一个F,F能够输出拟合函数f.

机器学习三步:1. 定义函数集合。2.定义评估方法,一般就是loss function定义。3.选择最好的function。
Meta三步:1. 定义Learning algorithm F的集合。2. 定义评估方法(loss)。3. 选择最好的Learning algorithm。
那么Learning algorithm是什么样的呢?

梯度下降的方法流程:1. 定义网络,随机初始化 θ \theta θ。2. 通过训练数据计算梯度,更新 θ \theta θ. 3. 通过多个epoch拟合,输出最终的参数 θ \theta θ.
所以,梯度下降可以作为一种learning algorithm。同时其中的红色框部分都是人为设计的。
如果图中的红框部分,使用机器自己来学,比如初始化参数 θ \theta θ时候,是机器学出如何去初始化 θ \theta θ,不同的初始化参数看做不同的learning algorithm,就构成多种learning algorithm set。
那么如何评估不同的learning algorithm呢?

对于task1,使用learning algorithm F,在其训练数据上训练输出 f 1 f^1 f1,然后用测试集评估其损失 l 1 l^1 l1。
同理,对于task2,仍然使用F,输出 f 2 f^2 f2,在测试集上其损失 l 2 l^2 l2,那么最终F的loss为:
L ( F ) = ∑ n = 1 N l n L(F)=\sum_{n=1}^N l^n L(F)=n=1∑Nln

ML只需要任务对应的训练集、测试集,一般还需要验证集。
Meta learning需要多个训练的任务,每个任务都有对应的训练、测试集合。测试任务也有对应的训练测试集,有时候还需要验证任务,来决定参数调整。
如果在不同的任务中,训练集都很大的话,训练会很慢,所以当前会假设不同任务的task数据集会很少,就变成few-shot问题。
真实情况,如果每个task的训练数据集很多的话,使用ML方法也能取得很好的效果。但是从长远来说,数据集很大也需要meta learning。
同时在few-shot中,task中的训练集作为support set,测试集作为query set。
那么怎么找到最好的learning algorithm呢?

通过定义F的损失函数,找到使得loss最小的函数 F ∗ F^* F∗,通过测试任务的训练集输入到 F ∗ F^* F∗,获得测试任务对应的函数 f ∗ f^* f∗,然后使用测试集输入 f ∗ f^* f∗来评估获得损失 l l l,从而评估其效果。
那么有经典的上手数据集吗?

经典数据集:Omniglot,网址:https://github.com/brendenlake/omniglot

N-ways K-shot: 即每个训练和测试任务中,有N个类别,每个类别有K个样本。
那么有什么新人上手的demo吗?


MAML:关注于参数初始化的算法,通过参数初始化。
MAML和pre-training有什么区别呢?

MAML中,通过初始化参数,然后会继续训练,然后使用训练好的参数 θ ^ n \hat{\theta}^n θ^n来计算损失。其中只要通过计算 ϕ \phi ϕ的梯度,来更新它即可, ϕ ← ϕ − η ∇ ϕ L ( ϕ ) \phi \leftarrow \phi-\eta \nabla_{\phi} L(\phi) ϕ←ϕ−η∇ϕL(ϕ)
而pre-training是通过直接使用预训练好的 ϕ \phi ϕ来计算损失,其中并不会对 ϕ \phi ϕ求导,fine-tuning阶段也只会更新参数,而并不是初始化的 ϕ \phi ϕ。
ϕ \phi ϕ和模型参数有什么区别呢,我理解 ϕ \phi ϕ是初始化的模型参数,而最终的模型参数可以在训练阶段改变的。问题就是这个初始化参数是不是也是一个基于下游任务可训练的pre-training呢?是否是针对多个任务后的一个全局较优的 ϕ \phi ϕ?

具体来说,一个好的初始化的 ϕ \phi ϕ应该像图中一样,初始化的时候,可能并不是多个任务的较优点(甚至不是局部最优),但是从这个初始化的点,每个任务n上学习可以获得全局最优参数 θ ^ n \hat{\theta}^n θ^n,

而pre-training关注的是,这个初始化的 ϕ \phi ϕ能够在多个任务上,整体loss最低,但是不保证有个别任务在局部最优解,所以也就没法保证训练之后每个任务能够到达全局最优解。这里感觉pre-trianing是把多个任务一起学习。
个人理解,任务1和任务2如果是不相关的话,有没有可能没法学到一个较好的初始化的 ϕ \phi ϕ。或者说这种多任务,meta learing有什么限制吗?

MAML关注于 ϕ \phi ϕ的潜力,而pre-traing关注于当下的表现,老师类比了下读博(MAML)和工作(Pre-training)
那么MAML到底是怎么做的呢?
在这里插入图片描述
首先 ϕ \phi ϕ通过训练得到之后,在模型训练阶段,假设模型只会被训练一次,那么最终参数和 ϕ \phi ϕ关系就是
θ ^ = ϕ − ε ∇ ϕ l ( ϕ ) \hat{\theta}=\phi-\varepsilon \nabla_{\phi} l(\phi) θ^=ϕ−ε∇ϕl(ϕ)
只做一次训练,主要是1)速度快。2)希望好的初始化参数能够更少的训练次数获得好的结果,提升难度。3)测试任务上可以训练多次。4)few-shot一般训练数据有限,训练多次容易过拟合。

通过指定目标函数 y = a s i n ( x + b ) y=a\ sin(x+b) y=a sin(x+b),通过将函数采样K个点的样本,然后使用这些样本来估计目标函数。

pre-training任务中,由于存在波峰和波谷,所以初始化的参数会是一条水平的线,接下来的fine-tuning也没办法训练得很好。
其实这一块还是没有懂,为啥fine-tuning时候还是一条水平线,是说模型陷入了局部最优吗?
我猜测可能和样本数量比较少有关系,pre-training在样本少的时候,没法很好的拟合。
然而MAML学到了一个很好的初始化参数,所以测试集上继续训练能够很好的拟合。
感觉像是一个极端例子,如果有更真实的测试集,可以看看结果。

https://arxiv.org/abs/1703.03400
这是在omniglot和mini-imageNet上的实验结果,也证明说MAML会有更好的效果,特别是在少量样本上的效果。

那么怎么通过loss对 ϕ \phi ϕ计算梯度来更新的呢,将偏导展开:
∂ l ( θ ^ ) ∂ ϕ i = ∑ j ∂ l ( θ ^ ) ∂ θ ^ j ∂ θ ^ j ∂ ϕ i \frac{\partial l(\widehat{\theta})}{\partial \phi_{i}}=\sum_{j} \frac{\partial l(\widehat{\theta})}{\partial \hat{\theta}_{j}} \frac{\partial \widehat{\theta}_{j}}{\partial \phi_{i}} ∂ϕi∂l(θ )=j∑∂θ^j∂l(θ )∂ϕi∂θ j
对于每一维偏导拿出来,由于最终的参数 θ ^ \hat\theta θ^是通过一次迭代训练获得的,对于第j维度参数:
θ ^ j = ϕ j − ε ∂ l ( ϕ ) ∂ ϕ j \hat{\theta}_{j}=\phi_{j}-\varepsilon \frac{\partial l(\phi)}{\partial \phi_{j}} θ^j=ϕj−ε∂ϕj∂l(ϕ)
θ ^ j \hat\theta_j θ^j表示最终参数的第j维向量的值, ϕ j \phi_j ϕj表示其第j维向量的值。
所以理解为什么设定为只训练一次了,否则可能会有递归的情况出现,会更加复杂。
然后我们再求导,需要分情况讨论,当
i
≠
j
i \neq j
i=j:
∂
θ
^
j
∂
ϕ
i
=
−
ε
∂
l
(
ϕ
)
∂
ϕ
i
∂
ϕ
j
\frac{\partial \hat{\theta}_{j}}{\partial \phi_{i}}=-\varepsilon \frac{\partial l(\phi)}{\partial \phi_{i} \partial \phi_{j}}
∂ϕi∂θ^j=−ε∂ϕi∂ϕj∂l(ϕ)
当
i
=
j
i=j
i=j时候:
∂
θ
^
j
∂
ϕ
i
=
1
−
ε
∂
l
(
ϕ
)
∂
ϕ
i
∂
ϕ
j
\frac{\partial \hat{\theta}_{j}}{\partial \phi_{i}}= 1 -\varepsilon \frac{\partial l(\phi)}{\partial \phi_{i} \partial \phi_{j}}
∂ϕi∂θ^j=1−ε∂ϕi∂ϕj∂l(ϕ)
为了方便计算,作者将复杂项做了近似:

那么最终的
ϕ
\phi
ϕ梯度方向其实就是下一次参数
θ
^
\hat \theta
θ^更新方向,即:
∂
l
(
θ
^
)
∂
ϕ
i
≈
∂
l
(
θ
^
)
∂
θ
^
i
\frac{\partial l(\widehat{\theta})}{\partial \phi_{i}}\approx \frac{\partial l(\widehat{\theta})}{\partial \hat{\theta}_{i}}
∂ϕi∂l(θ
)≈∂θ^i∂l(θ
)
注意,这个近似很重要,后面会用到。
那么实际MAML是怎么做的呢?

在应用中,MAML通过训练任务m的样本训练好的 θ ^ m \hat\theta^m θ^m根据loss计算出梯度,然后使用其梯度方向来更新初始化参数,对于任务n也是同理。
而pre-trining,对于任务m,初始化参数 ϕ \phi ϕ会向训练好的参数 θ ^ m \hat \theta ^m θ^m方向更新,对于任务n也会想参数 θ ^ n \hat \theta ^n θ^n方向更新。

Reptile方法,可以训练多次,然后 ϕ \phi ϕ向每次任务训练的好的参数 θ ^ \hat \theta θ^方向更新,多次叠加获得最终的 ϕ \phi ϕ。那么和pre-tring有什么区别呢?
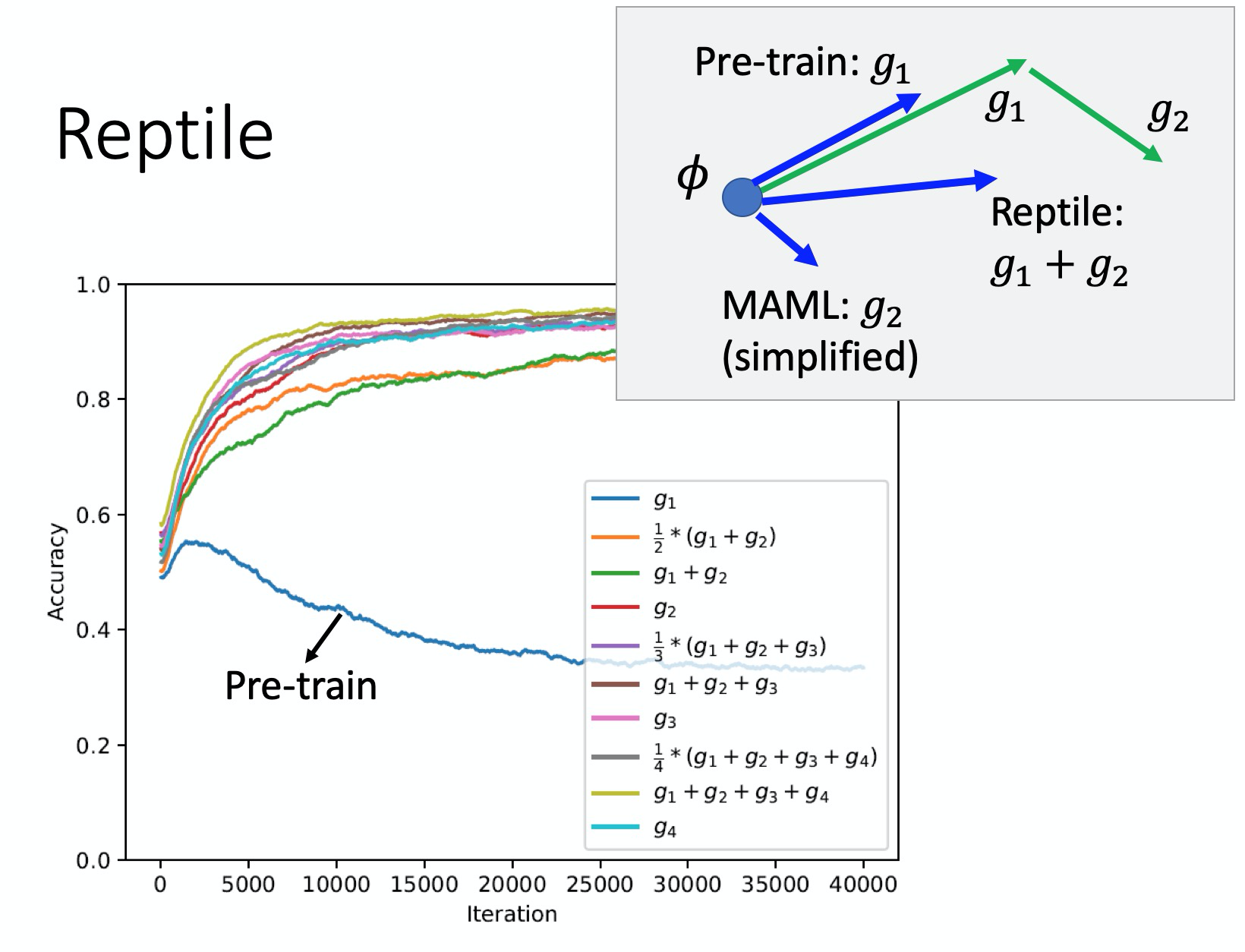
通过上面的图来解释,训练时候通过 g 1 g_1 g1, g 2 g_2 g2来更新参数,pre-tring会通过第一次update朝着g1方向更新 ϕ \phi ϕ,而maml会朝着g2方向更新,而reptile会朝着 g 1 + g 1 g_1+g_1 g1+g1方向更新。
为什么pre-trining不是更新两次呢?
首先基本设定是参数只更新一次,这时候,pre-trining的方向就是第一次的方向 g 1 g_1 g1,mamal方向是 g 2 g_2 g2方向,由于reptile可以更新多次,所以可以是第二次的最终参数方向,也可以是第三次的最终方向,即可以是 g 1 + g 2 + g 3 + . . . g_1+g_2+g_3+... g1+g2+g3+...
为什么maml是朝着g2的方向的?这个问题可以参考maml的数学推导,由于是取了近似,所以方向等于参数第二次更新的方向。
当然,图中实验从效果上说明,似乎reptile会略好于maml,两者都明显优于pre-trining。
在这里插入图片描述
其他也有一些方法,例如通过一个网络来生成训练的网络结构,或者更新参数的梯度。可以参考另一个视频:Video: https://www.youtube.com/watch?v=c10nxBcSH14

老师讲到meta learning的方法缺点,例如maml是通过学习初始化参数 ϕ \phi ϕ,那么maml的初始化参数 ϕ 0 \phi^0 ϕ0是否也需要学习得到,变成一个套娃问题。

未来:
- 怎么设计一个训练的算法,脱离当前的训练范式?
- 设计一个更大的网络,将训练、测试集中到一起?
例如,设计一个learning algorithm, 输出的是分类网络的参数 θ ^ \hat \theta θ^, 然后 θ ^ \hat \theta θ^输出的是样本类别,那么我们就可以直接将训练测试任务丢进去,训练出一个模型了。
且听下回分解。
李宏毅老师Meta Learning课程笔记-2















 583
583











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











