









前几天想把代码移植到linux下,想用服务器上的GPU来加速处理,结果搞了几天,头都大了,环境还没配好,ffmpeg ,opencv,gstreamer,单独装都没毛病,想让这些库关联起来,而且没毛病简直是闹心,还有各种依赖库,几十个,看着都头大,于是弃坑,还是回归到Windows的怀抱。不过配置的过程,也是头疼,网上各种教程,于是总结一下,加上自己的亲身经历,亲测有效,代码可以运行。
所需的软件和库
1.GPU
首先要确定你电脑上的GPU支持cuda吗,这个可以再英伟达的官网上查看规格参数,我用的是笔记本,配的是GTX950M,cuda核心数:640 ,架构:Maxwell,还算新的架构,这个架构问题后面还是挺蛋疼的。
2.opencv2.4.13
下载地址:http://opencv.org/downloads.html
如果是2.4.9也是可以的
安装后,就是解压到一个文件下,
安装完,需要配置windows的环境变量,在path中加入:D:\application\opencv\build\x64\vc12\bin; D:\application\opencv\build\x86\vc12\bin
3.CUDA ToolKit 7.5
下载地址:https://developer.nvidia.com/cuda-75-downloads-archive
让它默认安装,一般在c:programfiles/NVIDIAGPU computing toolkit/下。
没有用最新的8.0,感觉应该没差吧
4.cmake3.4.3
下载地址:https://cmake.org/download/
别问为什么是3.4.3,网上有人说只能用这个,说其他的报错,好吧,我信了,且也用了。它的作用就是将opencv和cuda一起编译,生成一个新的版本。
5.TBB ,据说是编译opencv_core库用的,我下的最新的,
下载地址:https://github.com/01org/tbb/releases
可以自定义安装,好找位置。
将D:\application\tbb2017_20170226oss\bin\intel64\vc12添加到环境变量中。
6.python2.7
下载地址:https://www.python.org/downloads/
这个作用不明,好像有用吧
开始配置
启动cmake
1.在source code :填入D:/application/opencv/sources(根据自己的目录定,就是sources文件夹位置)
在where is to build :填入D:/application/opencv/build/cuda。这个cuda文件夹是自己建的,意思是最后编入得目的文件夹。
注意选择advanced
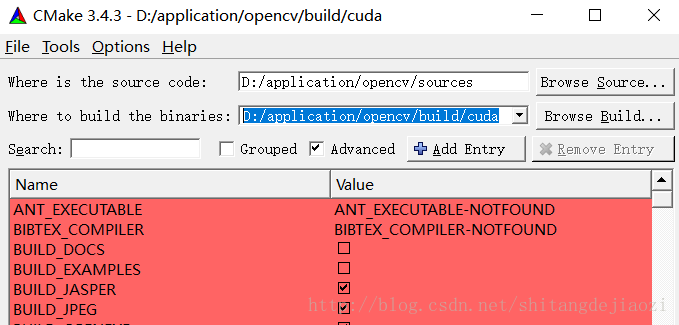
2.然后点configure
会提示你选择编译器,选择visual studio 12 2013 win64
cmake配置:
取消选择BUILD_DOCS 和‘BUILD_EXAMPLES
确认‘CMAKE_LINKER’, Visual Studio vs2013的路径
取消‘CUDA_ATTACH_VS_BUILD_RULE_TO_CUDA_FILE’
选择‘WITH_CUBLAS’, ‘WITH_CUDA’, ‘WITH_OPENGL’, ‘WITH_TBB’ (TBB is optional)
在CUDA_GENERATION,只能找到kelper,fermi,auto,还有空白,找不到maxwell,于是就选择空白,不要选其他的,如果你的可以找到可以直接选择,下边这两项就可以省略了。
由于我的显卡是maxwell,它的计算能力是5.0,这个你可以官网查到
所以就要设置,CUDA_ARCH_BIN=2.0 2.1(2.0) 3.0 3.5 5.0、CUDA_ARCH_PTX=5.0
再点击configure
会发现许多红的消失了
这时候回弹出新的红色,关于tbb的路径问题
include path :D:/tbb43_20140724oss\include
再次点击configure
会弹出配置tbb lib路径:D:/tbb43_20140724oss/lib/intel64/vc12
再点击configure,这次应该没红色了
3,没有红色,就可以点击generate
如果成功,就可以再目标目录D:/application/opencv/build/cuda下面找到一个opencv.sln
先管理员权限打开vs2013,然后打开这个opencv.sln
在解决方案管理器下,看到许多的库,这就是要重新编译的部分,
首先,先编译modules下的opencv_core,opencv_gpu,分别,右键-仅用于此项目-生成
如果这两个没问题,那恭喜你,基本没问题了,其中opencv_gpu是最慢的。
你就可以ALL_BUILD,如果没有错误,就cmake_target 中INSTALL
先在release下编译,完成后,再到debug下进行。
一次要两个小时,这过程,慢慢等吧,而且还要祈祷没问题发生。
编译完会有一个重新加载,点击全部重新加载。
比较开心的就是,我release没报错,在debug的时候,报错了,于是我在debug下先编译了opencv_gpu,然后再all_build,就成功了,简直是个玄学。
安装成功后,就在build/cuda/下生成install文件夹。
4.就是使用和测试了
好多坑,这个搞了一天
先将D:\application\opencv\build\cuda\install\x64\vc12\bin中的dll,拷贝到C:windows/system32目录下。
将C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v7.5\bin加入到系统环境变量中。
D:\application\opencv\build\cuda\install\x64\vc12\bin加入到系统变量中
重启电脑。
新建一个项目,比如main.cpp,打开视图-其他窗口-属性管理器,win32.user-属性
vc++目录
包含目录:
D:\application\opencv\build\cuda\install\include\opencv2
D:\application\opencv\build\cuda\install\include\opencv
D:\application\opencv\build\cuda\install\includ
库目录:
D:\application\opencv\build\cuda\install\x64\vc12\lib
C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v7.5\lib\Win32
链接器-输入:
debug下
opencv_imgproc2413d.lib
opencv_calib3d2413d.lib
opencv_contrib2413d.lib
opencv_core2413d.lib
opencv_features2d2413d.lib
opencv_flann2413d.lib
opencv_gpu2413d.lib
opencv_highgui2413d.lib
opencv_legacy2413d.lib
opencv_ml2413d.lib
opencv_nonfree2413d.lib
opencv_objdetect2413d.lib
opencv_ocl2413d.lib
opencv_photo2413d.lib
opencv_stitching2413d.lib
opencv_superres2413d.lib
opencv_ts2413d.lib
opencv_video2413d.lib
opencv_videostab2413d.lib
cudart.lib
release下
opencv_imgproc2413.lib
opencv_calib3d2413.lib
opencv_contrib2413.lib
opencv_core2413.lib
opencv_features2d2413.lib
opencv_flann2413.lib
opencv_gpu2413.lib
opencv_highgui2413.lib
opencv_legacy2413.lib
opencv_ml2413.lib
opencv_nonfree2413.lib
opencv_objdetect2413.lib
opencv_ocl2413.lib
opencv_photo2413.lib
opencv_stitching2413.lib
opencv_superres2413.lib
opencv_ts2413.lib
opencv_video2413.lib
opencv_videostab2413.lib
cudart.lib
配置完debug,配置release(感觉没啥用)
然后调试
报错:
模块计算机类型“x64”与目标计算机类型“X86”冲突
因为库是x64编译器编出来的,但是vs默认是win32的编译配置
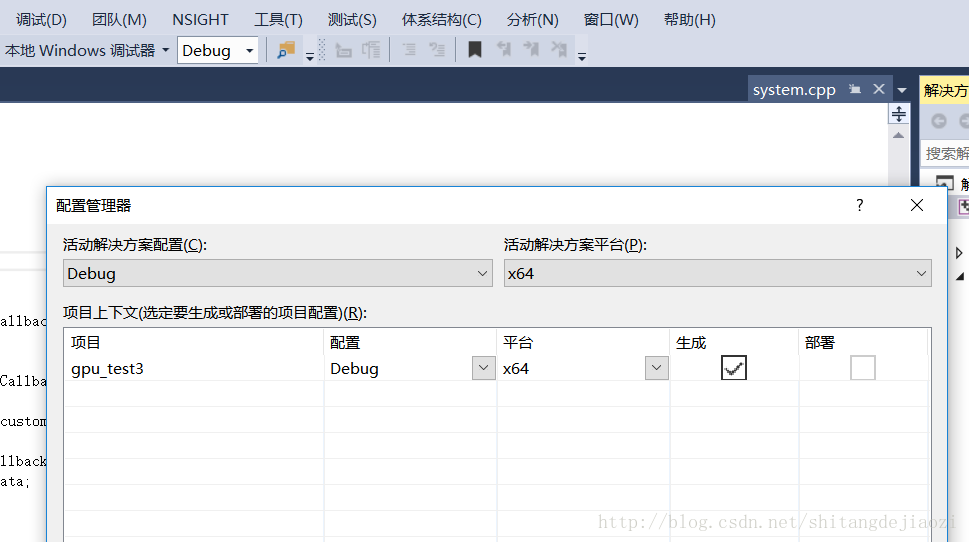
在配置管理器中选择平台x64,没有就新建一个,选中x64,(默认你的vs是支持编译x64)
这个时候再去看属性管理器,发现多了两个debug/x64,release/x64
安装上面配的过程,把这两个也配了,主要是配debug
再源文件中添加,新建项-cuda7.5
test.cu文件
#include "cuda_runtime.h"
#include "device_launch_parameters.h"
#include <stdio.h>
//cudaError_t addWithCuda(int *c, const int *a, const int *b, unsigned int size);
__global__ void addKernel(int *c, const int *a, const int *b)
{
int i = threadIdx.x;
c[i] = a[i] + b[i];
}
// Helper function for using CUDA to add vectors in parallel.
extern "C"
cudaError_t addWithCuda(int *c, const int *a, const int *b, unsigned int size)
{
int *dev_a = 0;
int *dev_b = 0;
int *dev_c = 0;
cudaError_t cudaStatus;
// Choose which GPU to run on, change this on a multi-GPU system.
cudaStatus = cudaSetDevice(0);
if (cudaStatus != cudaSuccess) {
fprintf(stderr, "cudaSetDevice failed! Do you have a CUDA-capable GPU installed?");
goto Error;
}
// Allocate GPU buffers for three vectors (two input, one output) .
cudaStatus = cudaMalloc((void**)&dev_c, size * sizeof(int));
if (cudaStatus != cudaSuccess) {
fprintf(stderr, "cudaMalloc failed!");
goto Error;
}
cudaStatus = cudaMalloc((void**)&dev_a, size * sizeof(int));
if (cudaStatus != cudaSuccess) {
fprintf(stderr, "cudaMalloc failed!");
goto Error;
}
cudaStatus = cudaMalloc((void**)&dev_b, size * sizeof(int));
if (cudaStatus != cudaSuccess) {
fprintf(stderr, "cudaMalloc failed!");
goto Error;
}
// Copy input vectors from host memory to GPU buffers.
cudaStatus = cudaMemcpy(dev_a, a, size * sizeof(int), cudaMemcpyHostToDevice);
if (cudaStatus != cudaSuccess) {
fprintf(stderr, "cudaMemcpy failed!");
goto Error;
}
cudaStatus = cudaMemcpy(dev_b, b, size * sizeof(int), cudaMemcpyHostToDevice);
if (cudaStatus != cudaSuccess) {
fprintf(stderr, "cudaMemcpy failed!");
goto Error;
}
// Launch a kernel on the GPU with one thread for each element.
addKernel<<<1, size>>>(dev_c, dev_a, dev_b);
// Check for any errors launching the kernel
cudaStatus = cudaGetLastError();
if (cudaStatus != cudaSuccess) {
fprintf(stderr, "addKernel launch failed: %s\n", cudaGetErrorString(cudaStatus));
goto Error;
}
// cudaDeviceSynchronize waits for the kernel to finish, and returns
// any errors encountered during the launch.
cudaStatus = cudaDeviceSynchronize();
if (cudaStatus != cudaSuccess) {
fprintf(stderr, "cudaDeviceSynchronize returned error code %d after launching addKernel!\n", cudaStatus);
goto Error;
}
// Copy output vector from GPU buffer to host memory.
cudaStatus = cudaMemcpy(c, dev_c, size * sizeof(int), cudaMemcpyDeviceToHost);
if (cudaStatus != cudaSuccess) {
fprintf(stderr, "cudaMemcpy failed!");
goto Error;
}
Error:
cudaFree(dev_c);
cudaFree(dev_a);
cudaFree(dev_b);
return cudaStatus;
} main.cpp文件
#include <iostream>
#include "cuda_runtime.h"
#include "device_launch_parameters.h"
using namespace std;
extern "C"
cudaError_t addWithCuda(int *c, const int *a, const int *b, unsigned int size);
int main(int argc,char **argv)
{
const int arraySize = 5;
const int a[arraySize] = { 1, 2, 3, 4, 5 };
const int b[arraySize] = { 10, 20, 30, 40, 50 };
int c[arraySize] = { 0 };
// Add vectors in parallel.
cudaError_t cudaStatus = addWithCuda(c, a, b, arraySize);
if (cudaStatus != cudaSuccess) {
fprintf(stderr, "addWithCuda failed!");
return 1;
}
cout<<"{1,2,3,4,5} + {10,20,30,40,50} = {"<<c[0]<<','<<c[1]<<','<<c[2]<<','<<c[3]<<'}'<<endl;
printf("cpp工程中调用cu成功!\n");
// cudaDeviceReset must be called before exiting in order for profiling and
// tracing tools such as Nsight and Visual Profiler to show complete traces.
cudaStatus = cudaDeviceReset();
if (cudaStatus != cudaSuccess) {
fprintf(stderr, "cudaDeviceReset failed!");
return 1;
}
system("pause"); //here we want the console to hold for a while
return 0;
} 右键工程-生成依赖项-生成自定义-选择cuda7.5
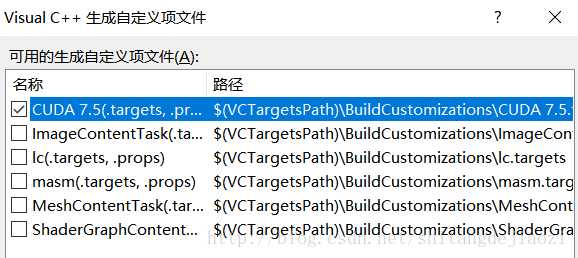
右键工程-属性 会发现多了很多东西
选中test.cu-右键-属性-项类型-cuda c/c++
工具-选项-文本编辑器-文件扩展名
添加cu cuh
致此,终于完成了,调试运行,成功。
你也可以直接测试cuda是否安装成功
vs2013
新建项目
起名为test
系统会为你生成一个kernel.cu文件
直接运行,完美,成功!
.cu文件和cpp文件混合编译,可以先建cpp,在添加.cu。也可以先建.cu,然后将代码替换掉系统给的kernel.cu,然后再添加cpp
其中自己的代码也出了很多问题,慢慢改,如果配置没问题,都是可解决的,再不行就重装一遍嘛,哈哈。














 480
480











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









