







前篇——软件设计模式-基础
前篇——软件设计模式-三种工厂模式
前篇——软件设计模式-装饰者模式
前篇——软件设计模式-单例模式
原型模式属于创建型模式
1. 概念引入
1.1 克隆
克隆:复制和拷贝,即从原型中产生出同样的复制品,其外表以及遗传基因与原型完全相同,但大多行为思想不同。
1.2 Java中的“克隆”—原型模式
1.2.1 原型模式的定义
定义:用原型实例指定创建对象的种类,并且通过复制这些原型创建新的对象
1.2.2 原型模式的特点
- 创建对象非常高效,不需要知道对象创建的细节。用一个已经创建完成的实例作为原型
- 避免了重新执行构造过程步骤,效率高
- 克隆创造出来的对象,属性值完全和原型对象相同,而且克隆出的新对象不会影响原型对象。而new出来的对象属性采用的时默认值
1.2.3 类图
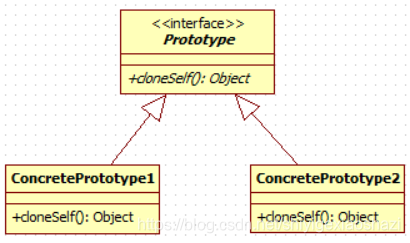
1.2.4 结构
原型模式的结构中包含两种角色:
- 抽象原型:一个接口,负责定义对象复制自身的方法
- 具体原型:实现抽象原型接口的类。具体原型实现抽象原型的方法,以便所创建的对象调用该方法复制自己
2. 原型模型分类及实现
2.0 知识回顾
(别骗自己了,就是忘了或者不会(淦))
2.0.1 Object类型
Object类型是所有引用类型的基础类,在引用类型的顶端。
它的引用变量可以指向任何类型的一个对象
2.0.2 super关键字
super用于在子类中指代父类的对象
super使用三种情况:
- 访问父类的方法
- 调用父类的构造方法
- 访问父类的隐藏成员变量
2.0.3 Cloneable接口
cloneable其实就是一个标记接口(空接口),只有实现这个接口后,然后在类中重写Object中的clone方法,然后通过类调用clone方法才能克隆成功,如果不实现这个接口,则会抛CloneNotSupportedException(克隆不被支持)异常。这段话来自“漫步夕阳下”的博客
2.0.4 异常处理
tip:finally 关键字:无论是否发生异常,代码总被执行
一般我们做异常处理通过三种:
- 通过try、catch 捕获异常
try{
//程序代码
}catch(ExceptionName e1){
//catch块
}
- 通过throws抛出异常:定义一个方法时可以用throws声明,表示此方法不处理异常、交给调用处处理
- throw关键字抛出异常:throw抛出的时一个异常类的实例化对象
2.0.5 Java中创建对象的4种方式
- 使用new 来创建对象
- 使用反射机制创建对象 Java反射机制—来自“ao63946”转载的博客
- 采用clone
- 采用序列化机制(详情见下)
2.1 简单实现
2.1.1 实现注意点
- 实现克隆,一定要实现Cloneable的空接口
- 重写clone()方法,Object类中的clone()方法
2.1.2 e.g.1 克隆立方体
简单了解克隆的方式:
//抽象原型(Prototype)
public interface Prototype{
//抛出克隆不支持的异常
public Object clone() throws CloneNotSupportedException;
}
//具体原型()立方体类
public class Cubic implements Prototype,Cloneable{
//长宽高
double length,width,height;
//构造方法赋值
public Cubic(douible length,double width,double height){
this.length = length;
this.width = width;
this.height = height;
}
//实现抽象原型接口的克隆方法
public Object clone() throws CloneNotSupportedException{
Object obj = super.clone();
return obj;
}
}
//测试类
public class Test{
public static void main(String args[]){
Cubic c = new Cubic(10.0,9.0,8.0);
Cubic c1 = (Cubic)c.clone();
System.out.println("c1值"+c1.length+c1.width+c1.height);
}
}
2.2 原型模式分类
2.2.1 原型模式中的浅克隆
浅克隆:不能做到完全克隆,如下面的例子,修改sheep1的日期,克隆的对象sheep2,也会更改,即两个对象同时使用一个date对象,一改都改,聚有耦合性。
2.2.1.1 e.g.2 克隆羊
import java.util.Date;
//Cloneable是个空接口,通过原型模式来创建对象,克隆方法不是原型中的方法,是Object类中的方法
public class Sheep implements Cloneable{
private String name;
private Date birthday;
//构造方法赋值
public Sheep(String name,Date birthday){
this.sname = sname;
this.birthday = birthday;
}
//重写Object类中的克隆方法
public Object clone()throws CloneNotSupportedException{
Object obj = super.clone();
return obj;
}
//一些get、set方法
public void setName(String name){
this.name = name;
}
public String getName(){
return name;
}
public void setBirthday(Date birthday){
this,birthday = birthday;
}
public Date getbirthday(){
return birthday;
}
}
//测试类
public class test{
public static void main(String args[]){
Date date1 = new Date(12312312);
Sheep sheep1 = new Sheep("多莉",date1);
//显示sheep1的信息
System.out.println(sheep1+"--"+sheep1.getSname()+"--"+sheep1.getbirthday());
Sheep sheep2 = (Sheep)sheep1.clone();
//显示sheep2的信息
System.out.println(sheep2+"--"+sheep2.getSname()+"--"+sheep2.getbirthday());
//判断是否是同一个对象
System.out.println(sheep1 == sheep2);
//修改sheep1的信息
sheep1.getBirthday().setYear(2020);
sheep1.setName("布莱克");
//判断修改sheep1的日期,sheep2的日期是否会改变
System.out.println(sheep1.getBirthday()==sheep2.getbirthday());
}
}
2.2.2 原型模式中的深克隆
深克隆,即被克隆对象与克隆对象基本无任何关系。改原型中的任何属性都不会影响新克隆的对象。(降低耦合性)
从浅克隆修改:
克隆对象的同时也克隆其属性。
2.2.2.1 将e.g.2(克隆羊)改为深克隆
实现:(修改e.g.2种的clone()方法即可):
public Object clone() throws CloneNotSupportedException{
Object obj = super.clone();
Sheep p = (Sheep)obj;
p.birthday = (Date)this.birthday.clone();
return obj;
}
3.序列化和反序列
3.1 序列化和反序列化含义
所谓序列化和反序列化
就是将对象读到字节数组输出流中,在把它读出来。
3.2 序列化和反序列化来实现深克隆
在2.2.2.1种我们实现例二的深克隆是通过,修改clone方法来实现的,用序列化的放法,我们只需要在测试类种修改即可。
:(序列化、反序列化实现:
public class test1{
public static void main(String args[]){
Date d1 = new Date(12121221);
Sheep sheep3 = new Sheep("莱弗利",d1);
System.out.println("这是原型对象sheep3--"+sheep3+"--"+sheep3.name+"--"+sheep3.birthday);
/*
为了实现深克隆,不直接克隆
Sheep sheep2 = (Sheep)sheep1.clone();
*/
//序列化过程:
//声明一个字节数组输出流(对象),通过ByteOutputStream
ByteArrayOutputStream bos = new ByteArrayOutputStream();
//包装一下对象(对象输入流(ObjectOutputStream))
ObjectOutputStream oos = new ObjectOutputStream(bos);
oss.writeObject(sheep3);
byte[] bytes = bos.toByteArray();
//反序列化过程(把写入字节数组输出流的对象再读出来):
//通过ByteArrayInputStream
ByteArrayInputStream bis = new ByteArrayInputStream(bytes);
ObjectInputStream ois = new ObjectInputStream(bis);
//读出来是Object类型,强转成Sheep,得到对象sheep4
Sheep sheep4 = (Sheep)ois.readObject(sheep3);
System.out.println("这是克隆出的sheep4对象--"+sheep4+"--"+sheep4.name+"--"+sheep4.birthday);
}
}
此时,再次修改sheep3,对sheep4无任何影响。
因为用到序列化,所以说我们需要导入java的io包,以及让具体原型(Sheep)除了实现Cloneable接口,还要实现一个序列化的接口(Serializable)
即
import java.io.*;
public class Sheep implements Cloneable,Serializable{
/*
内部就省略了,均是在e.g.2中做出一点修改。
*/
}
4. 总结
4.1 浅克隆向深克隆转化(前三大点弄明白,这个可以不看)
4.1.1浅克隆存在的问题
复制的对象,所有的变量都含有原来对象相同的值,而所有的对其他对象的引用,仍然指向原来的对象。
而深克隆把引用的变量指向复制过的新的对象,而不是原有的被引用的对象。其实浅克隆的基本数据类型是自动进行深克隆的(值的复制)
4.1.2 转化方式
浅克隆转化为深克隆:
- 让已实现Clonable接口中的属性也实现Clonable接口
- 利用序列化和反序列化来实现深克隆
4.2 原型模式的应用场景和优点
4.2.1 优点
- clone创建对象的时间 比 直接new 低的多得多
- 动态地保存当前对象的状态
- 动态添加、删除原型的复制品
- 当需要创建新实例代价过大,可以先复制已有的实例再做修改。
4.2.2 应用场景
- 原型模式很少单独出现,一般是和工厂方法模式一起出现。通过clone的方法创建一个对象,然后由工厂方法提供调用者。具体例子,在设计模式尾声会结合起来说明(标重点以防忘记)。
- 这一点显而易见:程序需要从一个对象出发,得到若干个和其状态相同并可以独立变化的对象时。
- 对象的创建过程比较麻烦,但复制比较简单时。
- 当对象的创建需要独立于它的构成过程和表示时。














 3413
3413











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









