







1. 概要
说明:此次分享,整理有独立的 keynote.
目标:高性能的网站,要求响应时间短、支持高并发。
几个问题:
- 指标:衡量网站性能的指标,有哪些?牛不牛逼,不能听你瞎说,总得有个衡量标准,谁的高,谁在这方面就牛逼
- 监控:如何收集指标信息?
- 改进:不同指标的改进措施和原理?
2. 指标
2.1. 不同人员的指标
不同人,不同视角,关注的网站高性能指标不同:
- 用户:用户感觉到的,网站响应速度
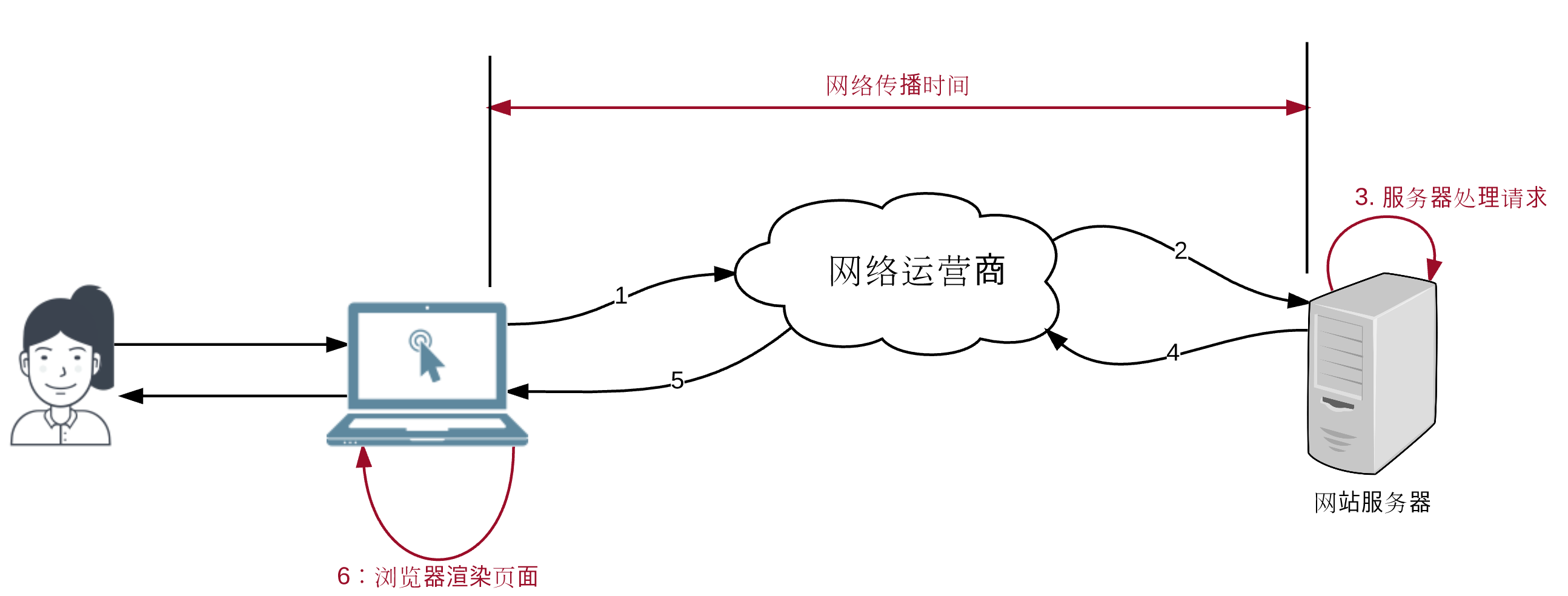
- 网站响应时间:
- 服务器处理时间
- 网络传输时间
- 浏览器 HTML 渲染时间
- 网站响应时间:
- 开发人员:
- 请求处理时间:
- 思考:端到端的延时?不仅仅是服务器的处理时间,此时,需要前端页面中观察请求的响应时间。
- 系统吞吐量
- 思考:什么是吞吐量?跟并发量有什么关系?QPS?TPS?
- 高并发处理能力
- QPS 的意义?高并发,就是 QPS? 1s = 1000ms,可能包含好多批次的处理。
- 请求处理时间:
- 运维人员:
- 基础设施:资源利用率
- OS 层级
- 运营商的网络利用率
- 硬件配置
- 数据中心网络架构
- 基础设施:资源利用率

2.2. 通用指标
排除不可控的指标,在研发和运维角度,有一些通用的指标:
- 响应时间:服务器侧,收到请求到返回响应的时间
- 并发数
- 吞吐量
- 性能计数器:OS 层级的统计信息,CPU、Mem、网络、磁盘等
按照层级,分类如下:
- App 级:
- 响应时间
- 吞吐量
- OS 级:
- 性能计数器
2.2.1. 响应时间
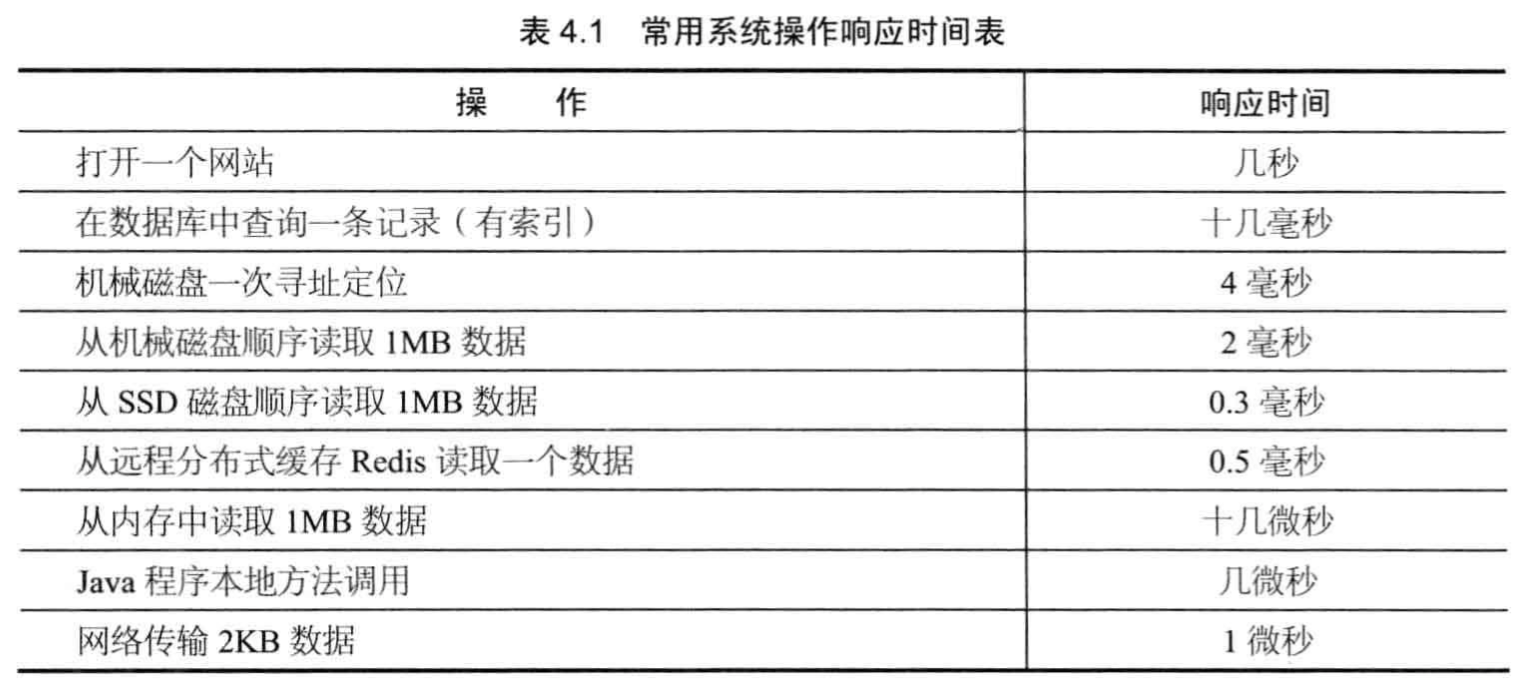
几个常见的时间:
- CPU 执行时间?2 GHz,对应 0.5 ns,实际涉及到读取指令,一般在 us 量级
- 内存读取数据:1~n x 10 us
- 通过网络读取数据时间?0~1ms (跟距离和跳数相关)
- 机械磁盘读取数据:1~5 ms,7200 rpm (round per minute)
- 数据库索引方式,查询记录:2~10 ms
其他时间汇总:
2.2.2. 并发数
并发数:同时处理请求的数据。 简单的说,就是同时处理的线程数量。
2.2.3. 吞吐量
吞吐量:单位时间内处理的请求数量。
具体衡量指标:
- TPS:每秒处理的事务数量
- QPS:每秒处理的查询请求数量
- HPS:每秒处理的 HTTP 请求数量
思考:
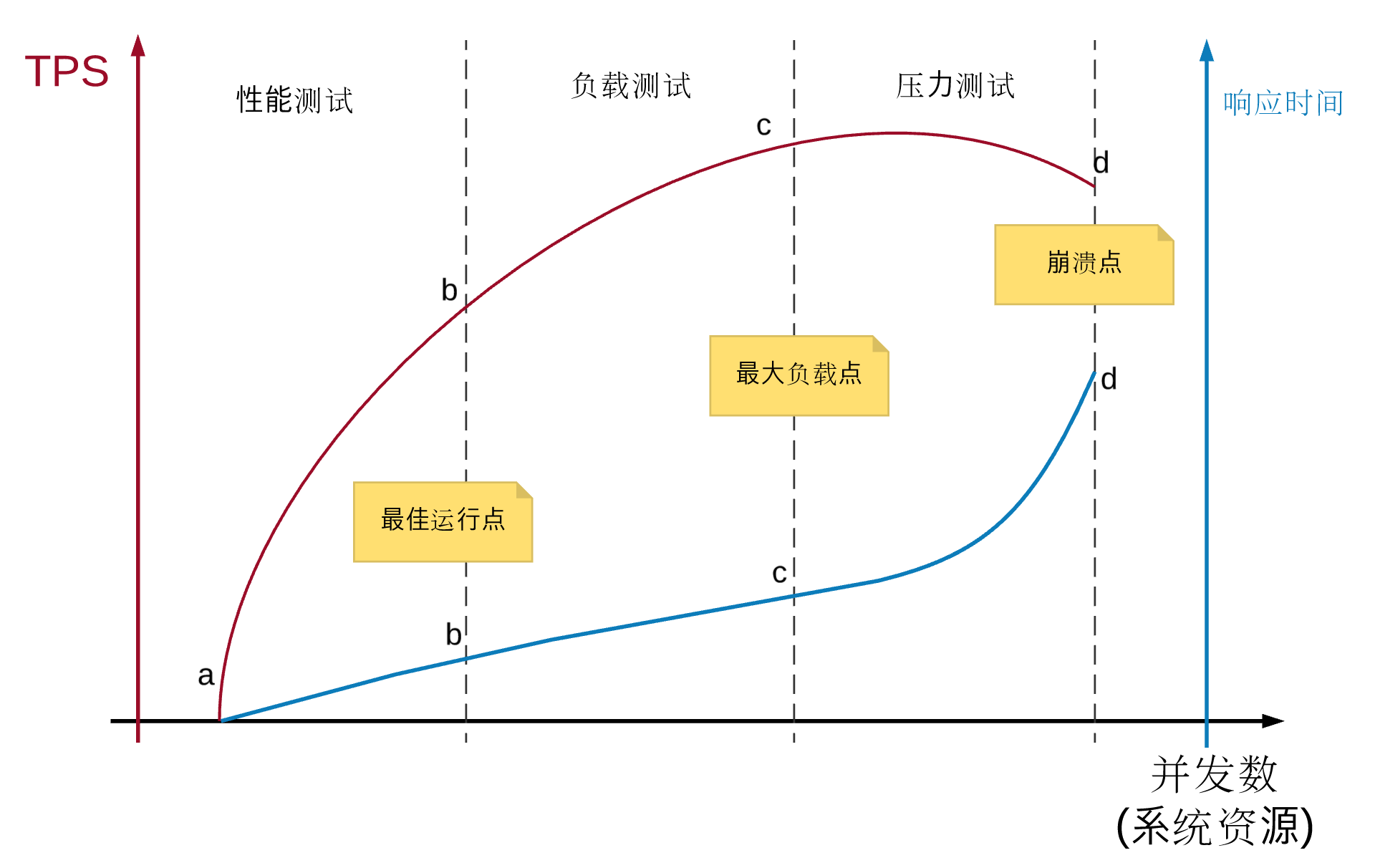
并发数 vs. 吞吐量?
Re:
- 随着「并发数」增加,系统「吞吐量」会上升
- 达到系统极限后,随着「并发数」增加,系统吞吐量会降低,最后系统资源耗尽,崩溃
2.2.4. 性能计数器
性能计数器:描述硬件/OS 级别的数据指标,例如:系统负载、线程数、内存使用、CPU 使用、磁盘 IO 、网络 IO 等。
部分指标,简单解释:
- 系统负载:
system load,(正在执行 + 排队执行的线程)/ CPU 核心数目,一般设置 0.3,0.5,0.7,1 几个指标,表示不同的状态。
3. 监控
3.1. 监控的实现
测量指标,常见的实现:
- OS、JVM:性能计数器
- Ganglia、Zabbix、Falcon 等
- App 级别:响应时间、吞吐量
- Spring AOP 定制
- Nginx 访问日志
- Web Server 访问日志
3.2. 测试
有了监控,就可以进行压力测试了。
压力测试:构造模拟场景,测试系统在不同压力下,响应时间、并发数、吞吐量、性能计数器等指标的表现。
测试方法:
- 不断增加请求数量
- 2 个请求之间,增加随机的等待时间
- 不均匀、突发式、间断性
测试,有一个大前提:做好指标监控。
4. 改进
4.1. Web 前端性能优化
从「浏览器」角度,可优化的地方:
- 减少页面中 HTTP 请求次数:css、js、image 的请求
- 合并请求
- 浏览器缓存:HTTP response 中 HTTP Header 中添加 Cache-Control 和 Expires 属性
- 减少请求的数据大小:
- 压缩:服务器端压缩、浏览器端解压缩,需要 balance,因为压缩也需要时间,网络良好时,不建议压缩
- Cookie 简化:不必要的数据,不添加到 Cookie 中
- 浏览器渲染机制:下载完 css 之后,才会去渲染
- CSS 链接放在页面最前面
- 浏览器「就近获取」资源:
- CDN 加速:请求图片、css、js等静态资源时,就近运营商和机房获取
4.2. Server 后端性能优化
从「服务器」角度,可优化的地方:
- 缓存:要保证数据一致性
- 本地缓存:无法保证「数据一致性」
- 分布式缓存:通过「主动失效缓存」,能保证「数据一致性」
- 消息队列:异步操作,及时响应
- 异步操作带来的问题:无法 Fail-Fast,需要同步优化业务流程
- 集群:单台机器处理能力有限,扩充为集群
- 反向代理:缓存 + 负载均衡
- 优化代码:
- 多线程
- 资源复用

4.2.1. 缓存
衡量缓存的指标:缓存命中率。(命中率:从缓存请求数据的次数 / 从缓存读取到数据的次数)
合理使用缓存:
- 「一写多读」的数据访问模型
- 有明显的「热点数据」
- 恰当的「数据一致性」策略
- 缓存可用性的预期:高可用、低可用?
- 缓存预热
- 防止缓存击穿
分布式缓存,本质是「集群」,关键问题:
- 如何保证,同一个 key 放在同一个「服务器节点」?
- 如果「服务器节点」失效,如何保证不影响「其他服务器节点」的正常工作?
- 正常工作:Client 将 KeyA 放到了 Node B 上,Node A 失效后,Client 仍然知道去 Node B 上,读取 KeyA 的缓存数据?
- 如果「服务器节点」新增了一个,如何保证不影响「其他服务器节点」的正常工作?
- 正常工作:Client 将 KeyA 放到了 Node B 上,新增 Node C后,Client 仍然知道去 Node B 上,读取 KeyA 的缓存数据?
解决分布式缓存集群问题:一致性 Hash 算法
一致性 Hash 算法:本质,Client 使用「一致性 Hash 环」保存所有的「集群节点」,计算出 key 对应的 「Node」后,就对相应的 Node 进行读写操作。
更多细节,参考:
疑问:分布式缓存集群中,节点的增减,如何通知到 Client ?
Re:每次在集中的地点,进行一致性 hash 运算。

4.2.2. MQ:异步操作
将需要处理的业务流程,暂时存放到 MQ 中,提前返回用户响应信息。
MQ 的注意事项:
延迟处理业务,需要同步优化「业务流程」
Note: 技术上很棘手的问题,可以优化业务流程来解决。

4.2.3. 集群
集群方式:减弱单机的压力,通过多台机器分担并发请求,提升整体集群的吞吐量。’

4.2.4. 代码优化
优化代码,提升系统性能。
常用方法:
- 多线程:多线程并发处理
- 资源复用:Spring MVC 中单例的对象、数据库连接的连接池、线程池
4.2.4.1. 多线程
多线程工作,提升处理效率,疑问:
- 是不是线程数量越多越好?
- 有没有极限?
- 有没有理论最大值?
- 如何确定最优的线程数量?
多线程方式,能够提升系统吞吐量,本质优化点:线程的 IO 时间 » 线程的 CPU 执行时间。
采用多线程,实际是,在「一个线程 IO 执行过程中」,尽可能启动多个线程,使用「CPU 资源」。

所以,理论上,最佳的「并发线程数量」:
T1/(T1-T2)x CPU 核心数Note:
IO 执行时间除以CPU 执行时间,就是可以新增的线程个数。
因此,需要根据具体业务场景,判断是否适合采用「多线程」:
- 计算密集型业务场景:不适合过多的「多线程」,只要求「线程数」=「CPU核心数」
- IO 频繁型业务场景:可采用「多线程」策略,增加系统吞吐量。
多线程,就涉及到「线程安全」问题,解决策略:
- 对象设计为「无状态」
- 使用局部变量
- 并发放问资源时,采用「锁」
4.2.4.2. 资源复用
线程池、连接池等。
4.3. 存储性能优化
几点:
- 「固态硬盘」替换机械磁盘
- 数据结构:B+ 树或者 LSM 树,充分利用「磁盘局部性原理」:机械磁盘特性,顺序读写快、随机读写慢。
- RAID(廉价磁盘冗余阵列)和 HDFS 提升:可用性、容错性,
- Note:提升磁盘 IO 的访问速率,单块磁盘,IO 有上限,数据分不到多块磁盘上,能够并发读写。
RAID vs. HDFS,本质都是数据冗余,数据分散存储,提升读取速度,适用场景:
- 传统系统、高可用系统,SQL 数据库,建议采用 RAID10 进行一次数据操作
- 现在的海量数据分析系统,可以直接上 HDFS
5. 参考资料
- 《大型网站技术架构:核心原理与案例分析》第4章 瞬时响应:网站的高性能架构















 1675
1675

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









