







文章转自:http://my.oschina.net/sundq/blog/189505
最近公司有个专供下载文件的http服务器出现了内存泄露的问题,该服务器是用node写的,后来测试发现只有在下载很大文件的时候才会出现内存泄露的情况。最后干脆抓了一个profile看看,发现有很多等待发送的buff占用着内存,我的profile如下(怎么抓取profile,大家可以google一下):
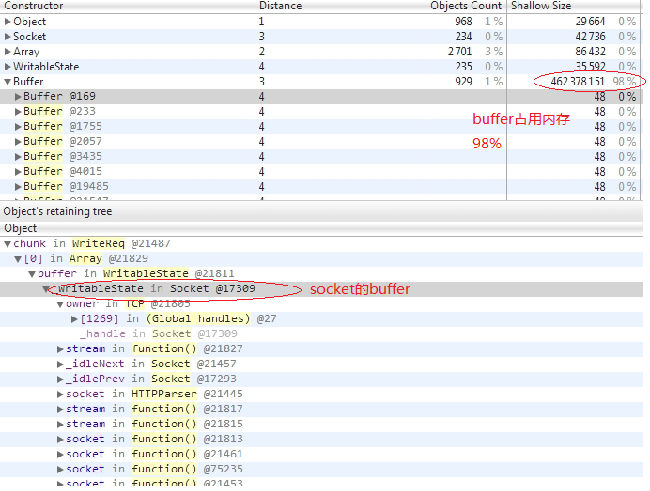
于是查看了一下发送数据的代码,如下:
|
1
2
3
4
5
6
7
|
var
fReadStream = fs.createReadStream(filename);
fReadStream.on(
'data'
,
function
(chunk) {
res.write(chunk);
});
fReadStream.on(
'end'
,
function
() {
res.end();
});
|
开始觉得没有什么问题,于是在google上查了一下node http处理大文件的方法,结果发现有人使用pipe方法,于是将代码修改如下:
|
1
2
|
var
fReadStream = fs.createReadStream(filename);
fReadStream.pipe(res)
|
测试了一下,发现OK,但是还是不明白为什么会这样,于是研究一个一下pipe方法的代码,发现pipe有如下代码:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
|
function
pipeOnDrain(src) {
//可写流可以执行写操作
return
function
() {
var
dest =
this
;
var
state = src._readableState;
state.awaitDrain--;
if
(state.awaitDrain === 0)
flow(src);
//写数据
};
}
function
flow(src) {
//写操作函数
var
state = src._readableState;
var
chunk;
state.awaitDrain = 0;
function
write(dest, i, list) {
var
written = dest.write(chunk);
if
(
false
=== written) {
//判断写数据是否成功
state.awaitDrain++;
//计数器
}
}
while
(state.pipesCount &&
null
!== (chunk = src.read())) {
if
(state.pipesCount === 1)
write(state.pipes, 0,
null
);
else
state.pipes.forEach(write);
src.emit(
'data'
, chunk);
// if anyone needs a drain, then we have to wait for that.
if
(state.awaitDrain > 0)
return
;
}
// if every destination was unpiped, either before entering this
// function, or in the while loop, then stop flowing.
//
// NB: This is a pretty rare edge case.
if
(state.pipesCount === 0) {
state.flowing =
false
;
// if there were data event listeners added, then switch to old mode.
if
(EE.listenerCount(src,
'data'
) > 0)
emitDataEvents(src);
return
;
}
// at this point, no one needed a drain, so we just ran out of data
// on the next readable event, start it over again.
state.ranOut =
true
;
}
|
原来pipe方法每次写数据的时候,都会判断是否写成功,如果写失败,会等待可写流触发"drain"事件,表示可写流可以继续写数据了,然后pipe才会继续写数据。
这下明白了,我们第一次使用的代码没有判断res.write(chunk)是否执行成功,就继续写,这样如果文件比较大,而可写流的写速度比较慢的话,会导致大量的buff缓存在内存中,就会导致内存撑爆的情况。
总结:
在使用流的过程中,一定要注意可读流和可写流读和写之间的平衡,负责会导致内存泄露,而pipe就实现了这样的功能。稍微研究了一下文档,发现stream类有pause()和resume()两个方法,这样的话我们也可以自己控制读写的平衡。代码如下:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
|
var
http = require(
"http"
);
var
fs = require(
"fs"
);
var
filename =
"file.iso"
;
var
serv = http.createServer(
function
(req, res) {
var
stat = fs.statSync(filename);
res.writeHeader(200, {
"Content-Length"
: stat.size});
var
fReadStream = fs.createReadStream(filename);
fReadStream.on(
'data'
,
function
(chunk) {
if
(!res.write(chunk)){
//判断写缓冲区是否写满(node的官方文档有对write方法返回值的说明)
fReadStream.pause();
//如果写缓冲区不可用,暂停读取数据
}
});
fReadStream.on(
'end'
,
function
() {
res.end();
});
res.on(
"drain"
,
function
() {
//写缓冲区可用,会触发"drain"事件
fReadStream.resume();
//重新启动读取数据
});
});
serv.listen(8888);
|















 862
862

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









