







最近又用到Hive,重新记录一下安装方式,搭建了Hadoop+Hive,在运行Hive之前要首先搭建好Hadoop,关于Hadoop的搭建有三种模式,在以下的介绍中,我主要的采用的是Hadoop的伪分布安装模式。写下来给各位分享。
准备工作:
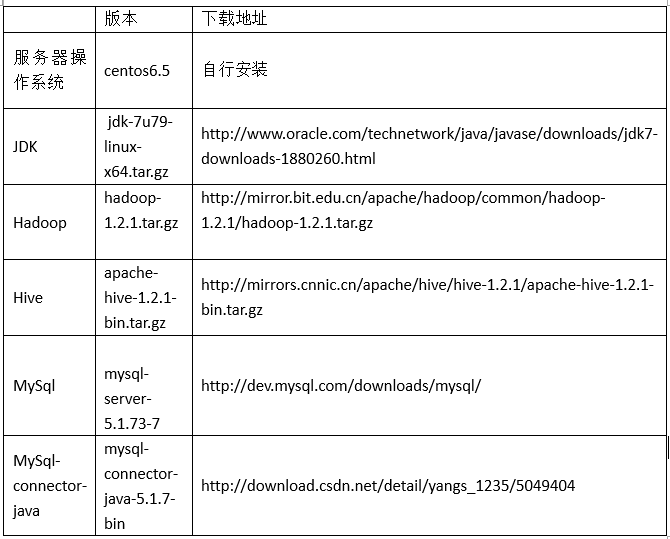
以上所有的下载的安装包和解压后文件均在/usr/local/hadoop目录

1、分别ssh到每台服务器上,在root用户下修改hostname
su root
vim /etc/sysconfig/network
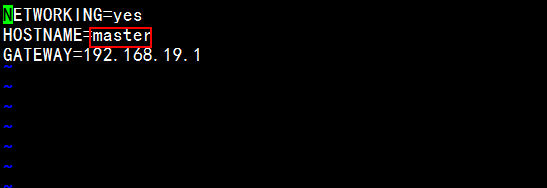
如上图所示,HOSTNAME=master
vim /etc/hosts
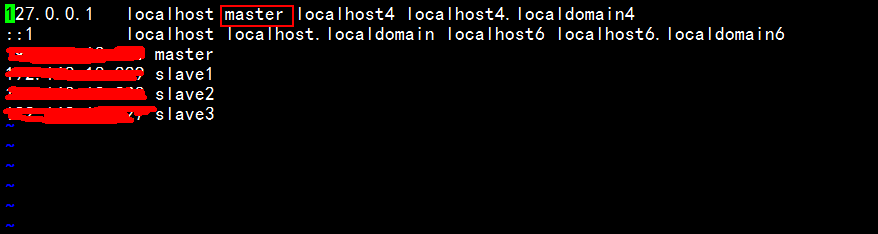
如上图所示,将localhost.localmain处改成master,遮挡处是IP地址,囧,然后重启服务器
reboot
在master服务器添加每台主机名字和地址的映射
vim /etc/hosts
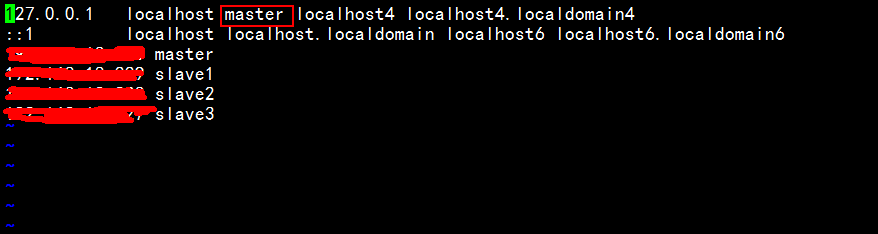
然后检查ping连接
ping slave1
同理,在其他三台服务器上修改主机名和添加地址映射。
2、分别在每台服务器上建立相应的文件夹,并修改文件夹权限
mkdir /usr/local/hadoop
chmod 777 –R /usr/local/hadoop
3、安装jdk,Hadoop使用环境必须有jdk,每台服务器上都必须安装
首先检查有无jdk:Java -version
cd /usr/local/hadoop
http://www.oracle.com/technetwork/java/javase/downloads/jdk7-downloads-1880260.html
将下载的安装包上传到master上的/usr/local/hadoop文件夹下
tar-zxvf jdk-7u79-Linux-x64.tar.gz
配置jdk的环境变量:
vim /etc/profile
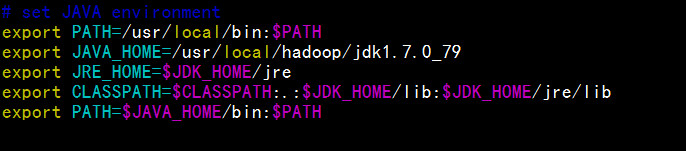
使其立即生效 source /etc/profile
检查是否安装成功:java –version

4、hadoop 用户准备:
添加用户:useradd hadoop
用户密码:passwd hadoop
授权给hadoop: chown -R hadoop:hadoop /usr/local/hadoop
5、SSH无密码登录配置
在Hadoop中,nameNode是通过SSH来启动和停止各个DataNode上的各种守护进程,这就要在节点之间执行指令的时候是不需要输入密码的形式,故需要配置SSH运用无密码公钥认证的形式。
切换到hadoop用户下:以下是配置master SSH无密码登录slave1
su hadoop
ssh-keygen –t rsa –P ‘’
三次Enter
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
chmod 600 ~/.ssh/authorized_keys
su root
vim /etc/ssh/sshd_config

service sshd restart
测试本地无密码连接是否成功:

然后将id_rsa.pub分发到slave1服务器上:
scp ~/.ssh/id_rsa.pub hadoop@slave1:~/
在slave1主机上,在hadoop用户下:
su hadoop
mkdir ~/.ssh(如果没有,就要新建.ssh文件夹)
chmod 700 ~/.ssh
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
chmod 600 ~/.ssh/authorized_keys
切换到root用户下:
vim /etc/sys
同上: vim /etc/ssh/sshd_config
service sshd restart
回到master主机上测试SSH无密码连接slave1:

同上,分别配置master SSH无密码连接slave2,slave3。
以上的配置过程,只能实现master 分别SSH无密码连接slave1,slave2,slave3,而无法实现slave1,slave2,slave3 SSH 无密码连接master。
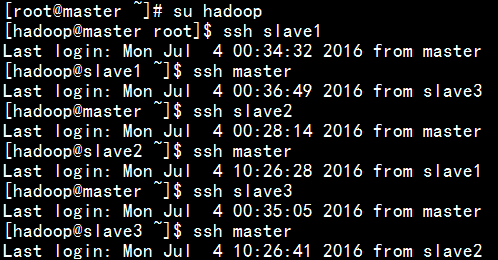
若要实现slave1,slave2,slave3 SSH无密码连接master,以slave1 SSH无密码连接master为例:同理,先在slave1主机上hadoop用户下,生成id_rsa.pub,再拷贝到master主机上,并追加到authorized_keys.最后配置成功如下图:
6、安装Hadoop(集群中的所有机器都要安装Hadoop)
cd /usr/local/hadoop
wget http://mirror.bit.edu.cn/apache/hadoop/common/hadoop-1.2.1/hadoop-1.2.1.tar.gz
tar –zxvf hadoop-1.2.1.tar.gz
修改环境变量:
su root
vim /etc/profile
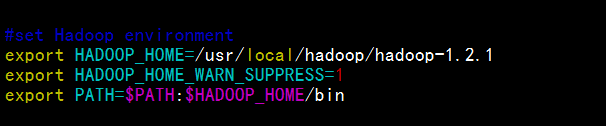
使之立即生效:
source /etc/profile
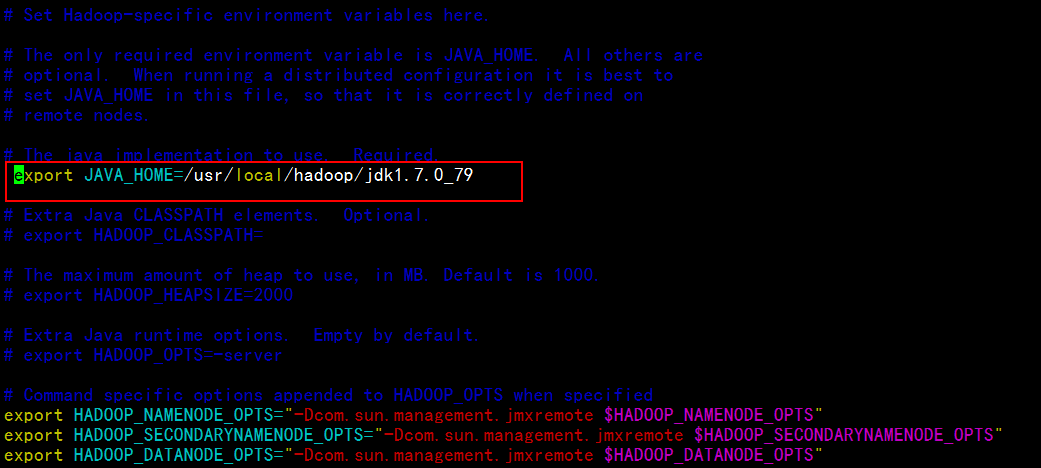
修改hadoop conf文件夹下的hadoop-env.sh
cd /usr/local/hadoop/hadoop-1.2.1/conf
vim hadoop-env.sh
将上图中红框下的文字取消注释;
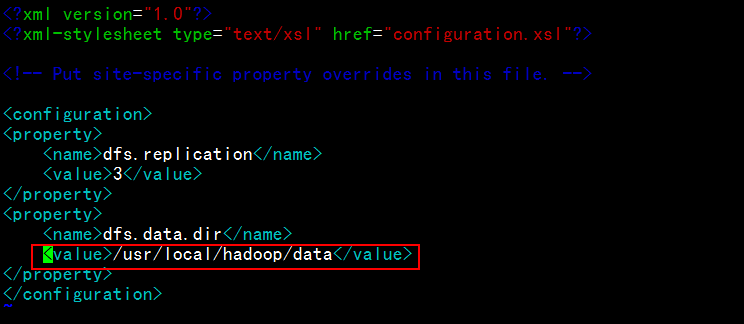
修改conf下的hdfs-site.xml文件
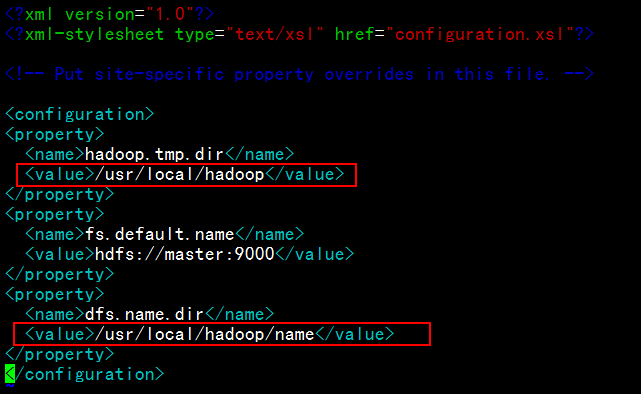
修改conf下core-site.xml文件:
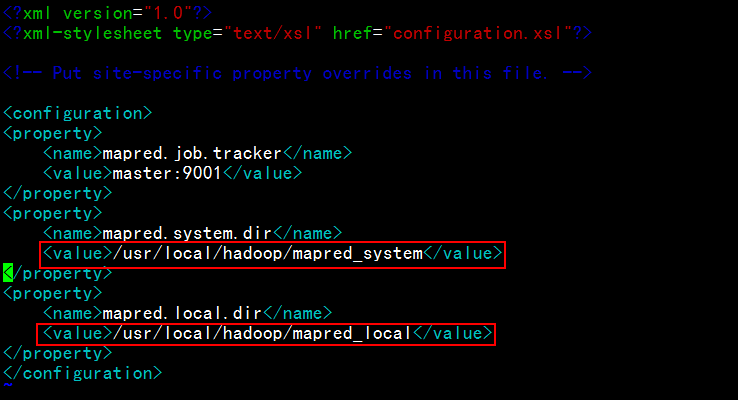
修改conf下mapred-site.xml:
注意:四台服务器上都要进行相应的配置。
7、master上进行验证:
格式化Hadoop:
cd /usr/local/hadoop/ hadoop-1.2.1/bin
./hadoop namenode –format
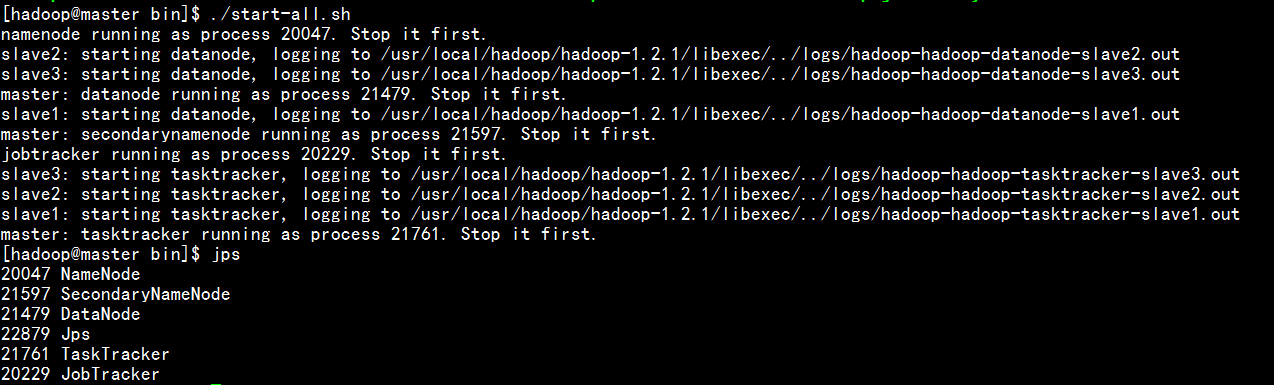
./start-all.sh
jps
(二)Hive安装(每个节点上都要安装Hive)
这里选用MySQL作为元数据库,将mySql和Hive安装在master服务器上
统一给放到/usr/local/hadoop
1、下载安装文件,并解压:
cd /usr/local/hadoop
wget http://mirrors.cnnic.cn/apache/hive/hive-1.2.1/apache-hive-1.2.1-bin.tar.gz
tar -zxvf apache-hive-1.2.1-bin.tar.gz
2、配置环境变量
在root用户下:
su root
vim /etc/profile

生效:source /etc/profile
chown –R hadoop:hadoop /usr/local/hadoop
3、安装mySql
yum install mysql-server
安装完成后;
service mysqld start
mysql>mysql;
如果报错:
mysqladmin: connect to server at ‘localhost’ failed
error: ‘Access denied for user ‘root’@’localhost’ (using password: YES)’
解决办法:
service mysqld stop
mysqld_safe –skip-grant-tables &;
mysql –uroot –p
use mysql;
update user set password=PASSWORD(“hadoop”)where user=”root”;
flush privileges;
quit
service mysqld restart
mysql -uroot –phadoop
或者mysql –uroot –hmaster –phadoop
如果可以登录成功,则表示MySQL数据库已经安装成功。
创建Hive用户:
mysql>CREATE USER ‘hive’ IDENTIFIED BY ‘hive’;
mysql>GRANT ALL PRIVILEGES ON . TO ‘hive’@’master’ WITH GRANT OPTION;
mysql> GRANT ALL PRIVILEGES ON . TO ‘hive’@’master’ IDENTIFIED BY ‘hive’;
mysql>flush privileges;
创建Hive数据库:
mysql>create database hive;
4、修改Hive配置文件:
cd /apache-hive-1.2.1-bin/conf
cp hive-default.xml.template hive-default.xml
vi hive-site.xml
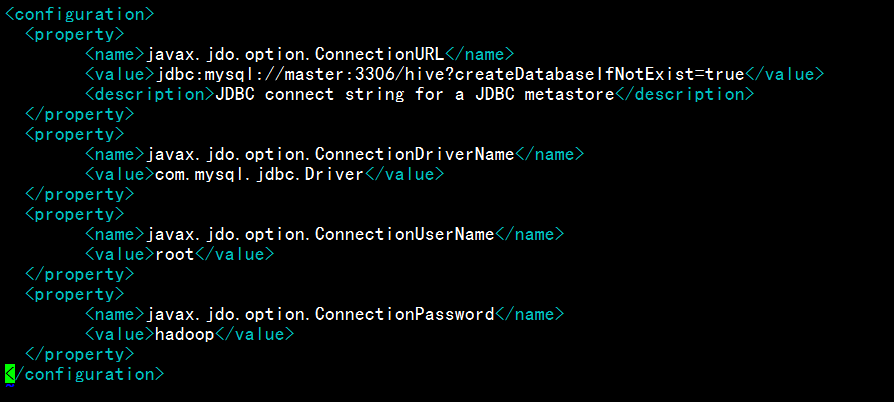
5、拷贝JDBC驱动包
将mySql的JDBC驱动包复制到Hive的lib目录下
cp mysql-connector-java.bin.jar /usr/local/hadoop/ apache-hive-1.2.1-bin /lib
6、分发Hive分别到slave1,slave2,slave3上
scp -r /usr/local/hadoop/apache-hive-1.2.1-bin slave1:/usr/local/hadoop/
scp -r /usr/local/hadoop/apache-hive-1.2.1-bin slave2:/usr/local/hadoop/
scp -r /usr/local/hadoop/apache-hive-1.2.1-bin slave3:/usr/local/hadoop/
配置环境变量如同master。
7、测试Hive
进入到Hive的安装目录,命令行:
cd /usr/local/hadoop/apache-hive-1.2.1-bin/bin
hive
hive>show tables;
正常显示,即是安装配置成功。
注意:在测试Hive之前要启动hadoop
若要进行远程服务启动则如下:
cd /usr/local/hadoop/apache-hive-1.2.1-bin/bin
nohup hive –-service hiveserver2
静止不动是正常的,在后台已经启动相关服务。














 3万+
3万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









