






所需条件:
windows系统
python 3.12 (最好是python3)
PyCharm 2023
ChromeDriver (selenium)
题外话:
在python中,scrapy、pyechart等库需自行下载
1、获取项目
先说一下为什么使用scrapy框架:
选择scrapy框架的优势
①模块化组件:Scrapy的设计将爬虫的各功能模块如引擎、调度器、下载器等分离,使得框架结构清晰,便于开发者理解和扩展。
②中间件扩展:通过编写中间件,通过拦截请求可以对请求进行特定处理,可以方便地添加过滤器等处理机制,进一步定制数据提取过程。
③管道机制:通过管道的方式,Scrapy可以轻松地将抓取的数据存入数据库,支持多种存储形式。
④高效并发:Scrapy采用了异步处理请求机制,多线程爬取数据,使得爬取网页十分迅速。能够在等待响应时处理其他请求,避免了传统同步请求中的等待时间,对应还可以灵活调节并发量,使得爬虫在处理大量请求时效率更高。
在本次爬虫程序中,使用MySQL和JSON方式来存储数据,在单次请求后提交单个视频的item到pipelines中进行数据清洗和存储,使用scrapy更为便捷。
快速获取gitee仓库项目,在cmd中使用git命令:
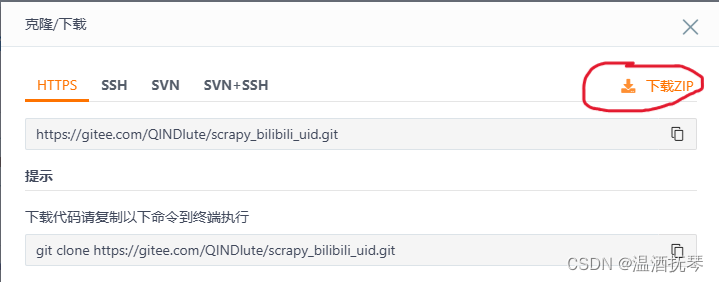
git clone https://gitee.com/QINDlute/scrapy_bilibili_uid.git若读者的电脑中未安装git,则访问该网址下载zip,自行解压后,用pycharm打开。
https://gitee.com/QINDlute/scrapy_bilibili_uid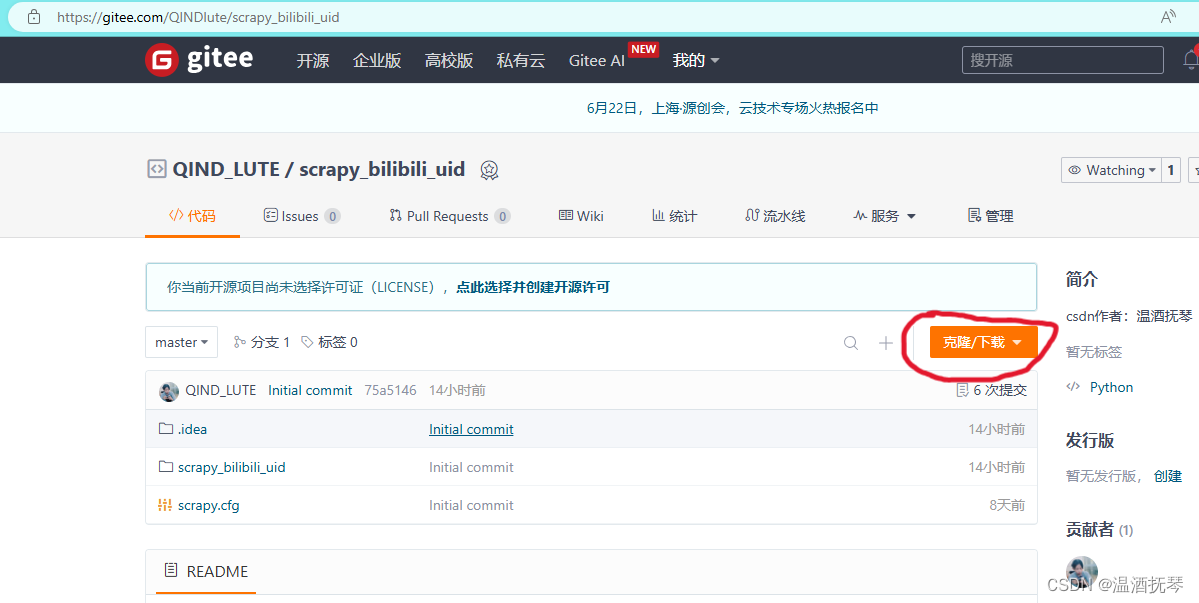
项目结构:
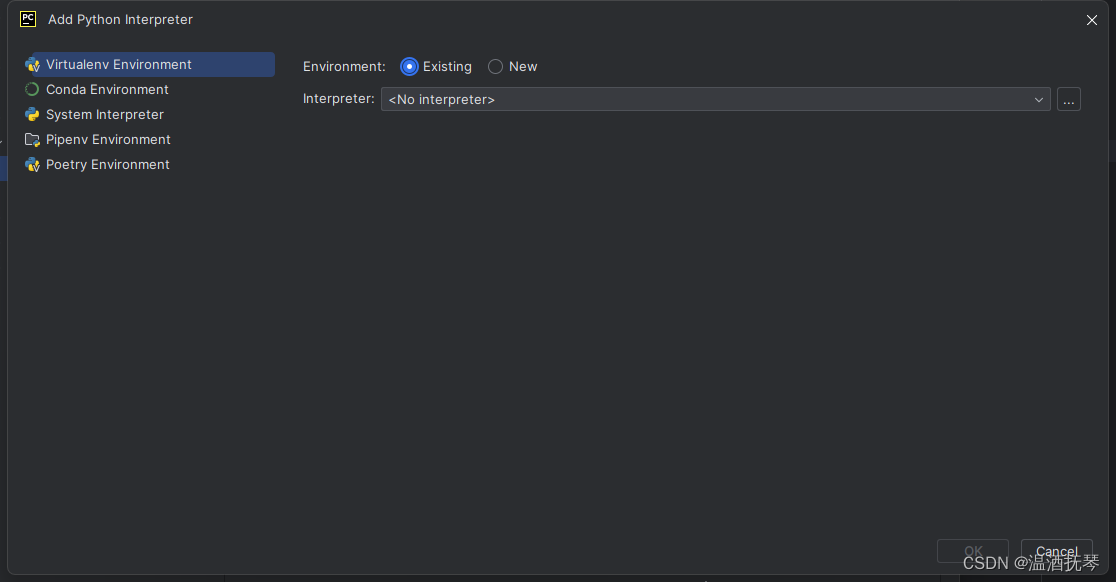
进入项目后设置python解释器:
添加已有python解释器:
选择Existing选项
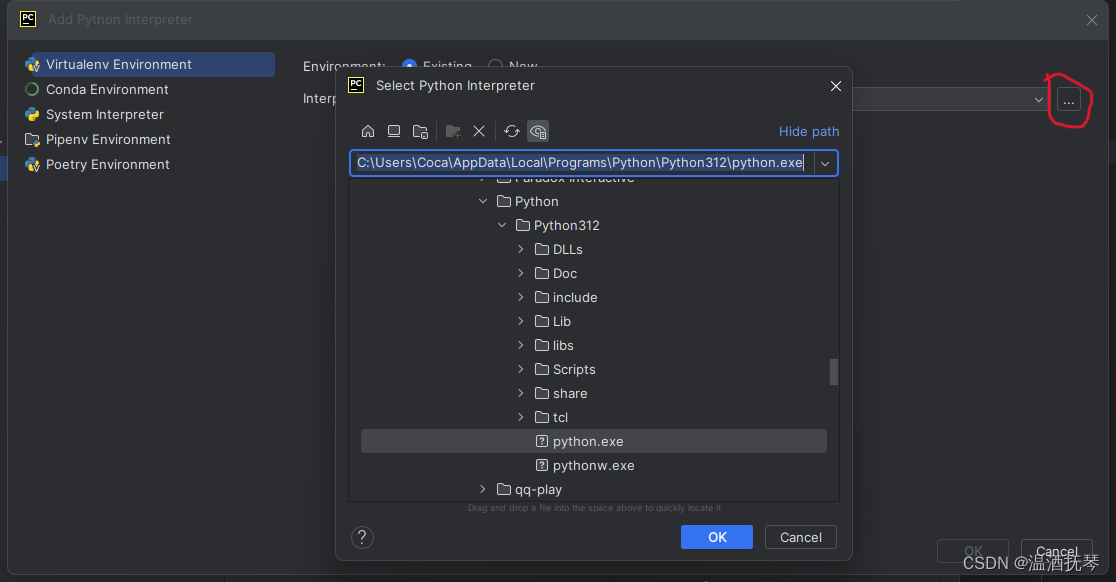
选择本地已下载python
2、selenium准备
由于b站网页优秀严密的反爬机制,使得requests配合BeautifulSoup这种常规解析网页源码的方式会被过滤拦截。
因此使用Selenium驱动ChromeDriver来抓取执行JavaScript时动态生成的页面,使浏览器自动化运行,能够模拟真实用户的浏览器行为。Selenium拥有很多有效的预防反爬机制,其中包括检测用户行为、IP地址的访问频率、请求头信息等。
使用selenium的好处:
🍪处理Cookies和Session:Selenium能够处理浏览器的cookies和session,甚至于登陆账号,这对需要保持登录状态或跟踪会话信息的B站非常有用。
🤖延迟和随机化请求:Selenium可以设置随机的延时间隔,模拟人类的思考时间和操作间隔,减少被识别为爬虫的风险。
⭐动态访问:动态加载的内容或者需要与JavaScript交互的页面,必须使用Selenium来渲染页面并获取完整的HTML响应
1)安装谷歌浏览器Chrome
2)下载ChromeDriver
3、运行项目
1)准备工作:
在settings.py中修改自己的mysql连接属性和需要目标up主的uid号:

# 设置数据库连接信息
MYSQL_HOST = '127.0.0.1' # 主机域名,基本不用改
MYSQL_USER = 'root' # mysql用户名
MYSQL_PASSWORD = '123456' # 密码
MYSQL_PORT = 3306 # 端口号
MYSQL_DB = 'bilibili_scrapy' # 要存放信息的数据库名
CHARSET = 'utf8' # 数据库编码方式
use_unicode = False
UID = '18706318' # up主uid号
SAVE_DIR_JSON = 'spiders/json' # json文件存储文件夹2)运行方式
方式一:
直接运行main.py文件(推荐)
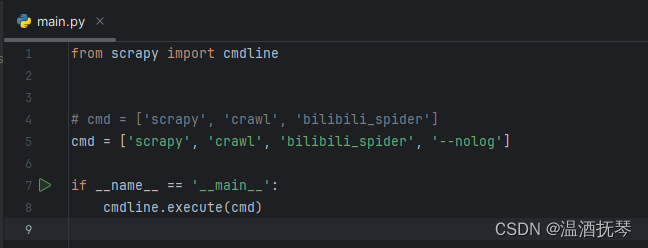
方式二:
将第五行注释,取消第四行注释,此时运行main.py会有日志输出,可查看运行日志、爬虫过程详情、调用实例信息等,通常在检查报错时使用
爬取过程展示:
scrapy演示
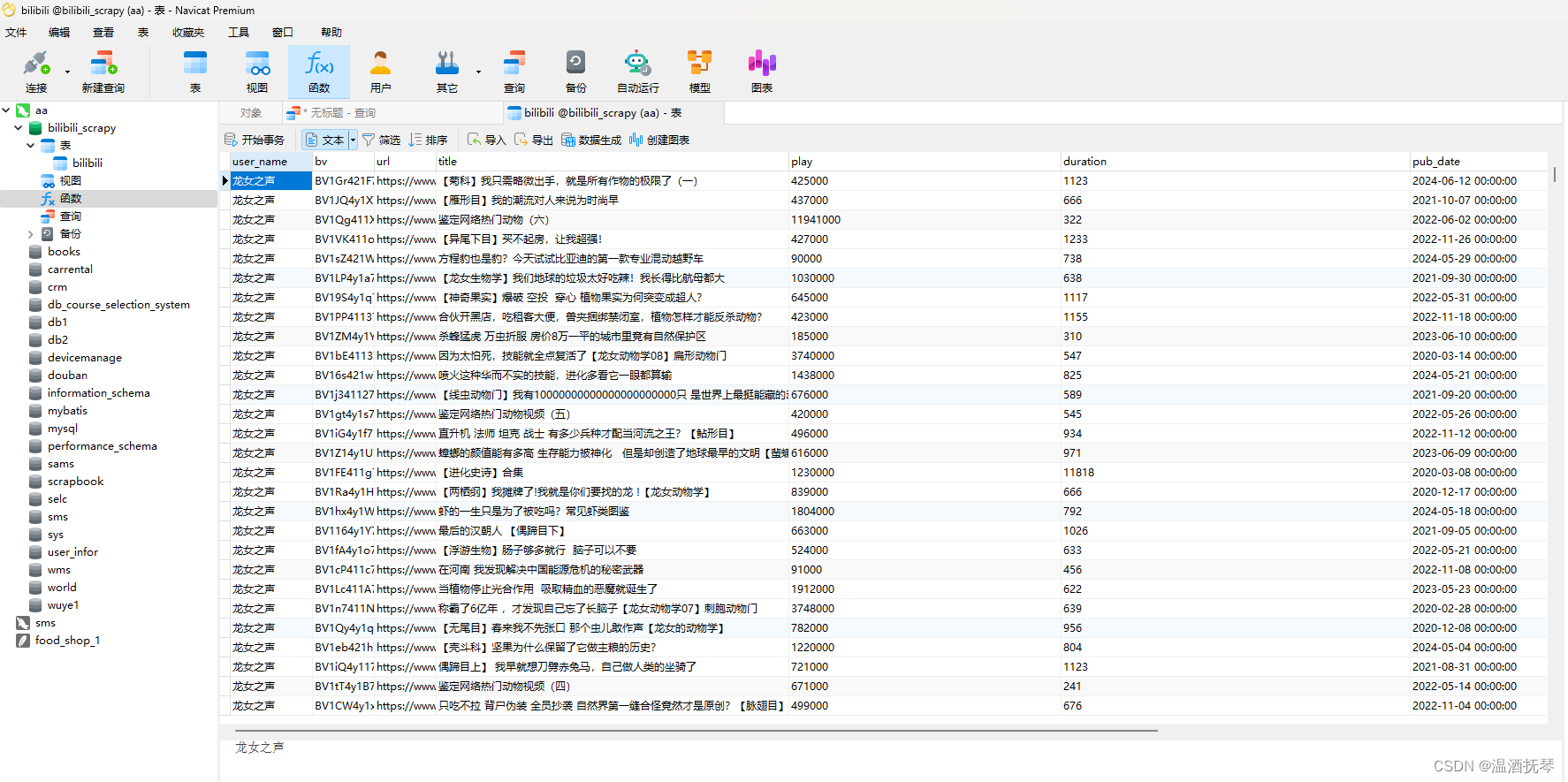
4、爬取结果
数据可视化
点击谷歌浏览器图标(或者Edge和Firefox),进入渲染页面,第一次加载稍等片刻:
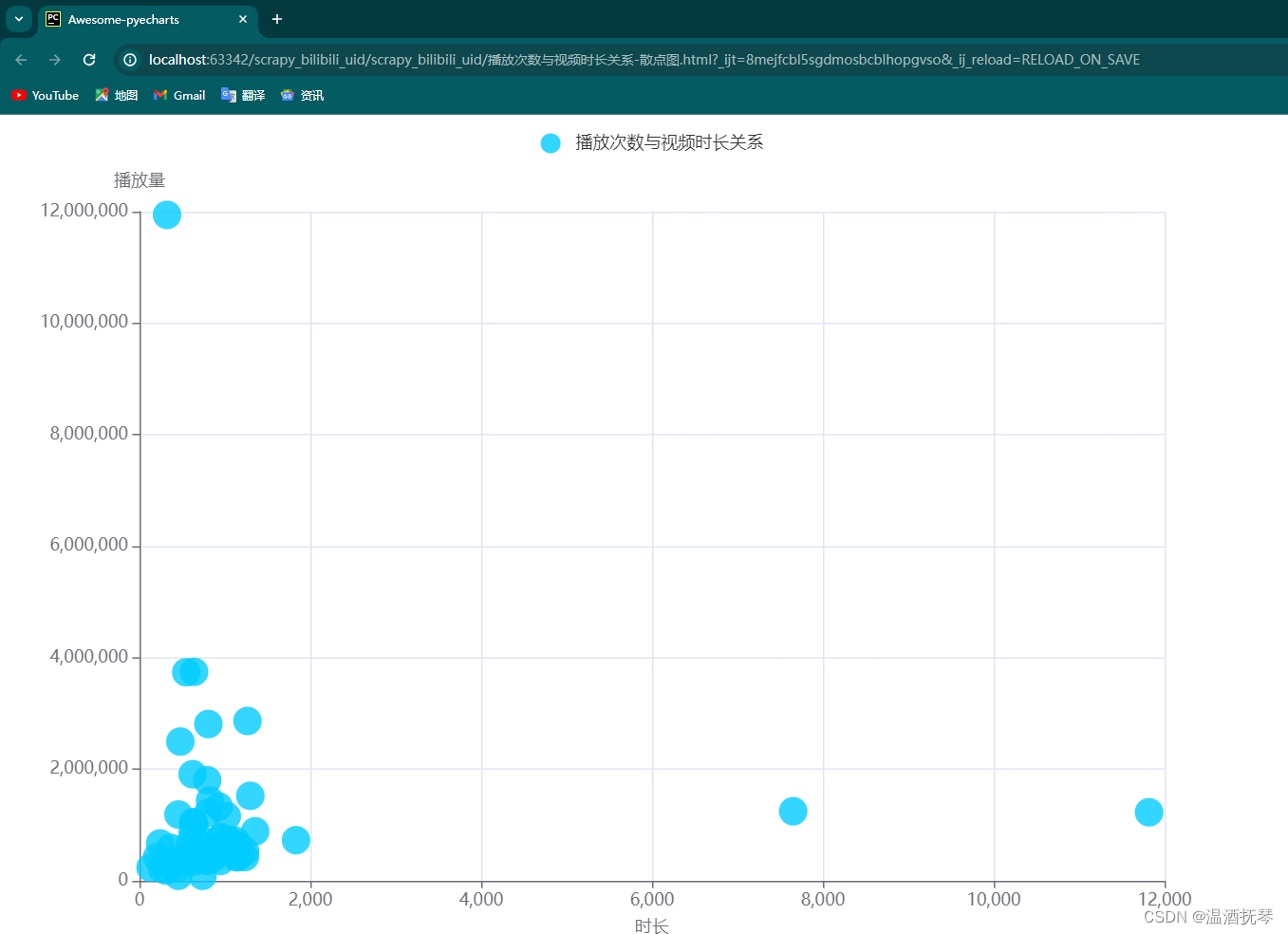
另外4个页面自行查阅
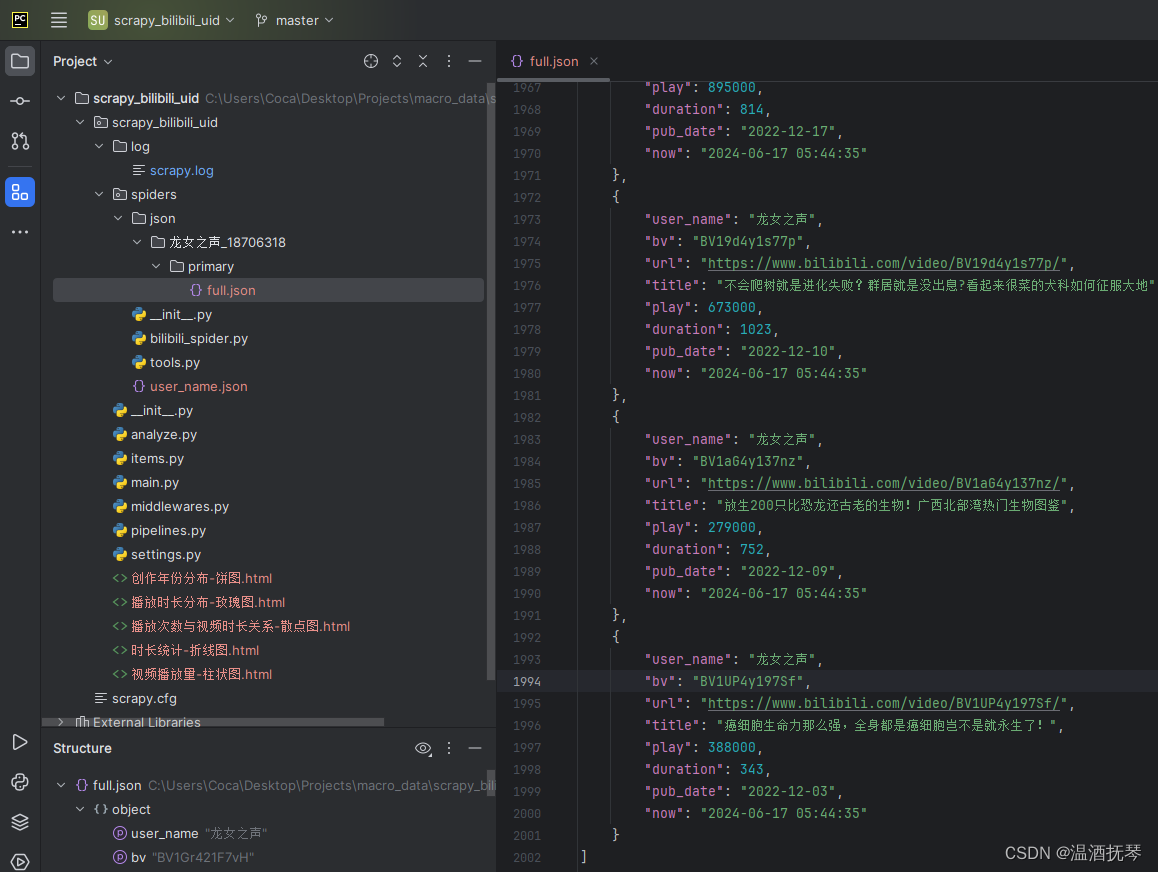
JSON文件永久化
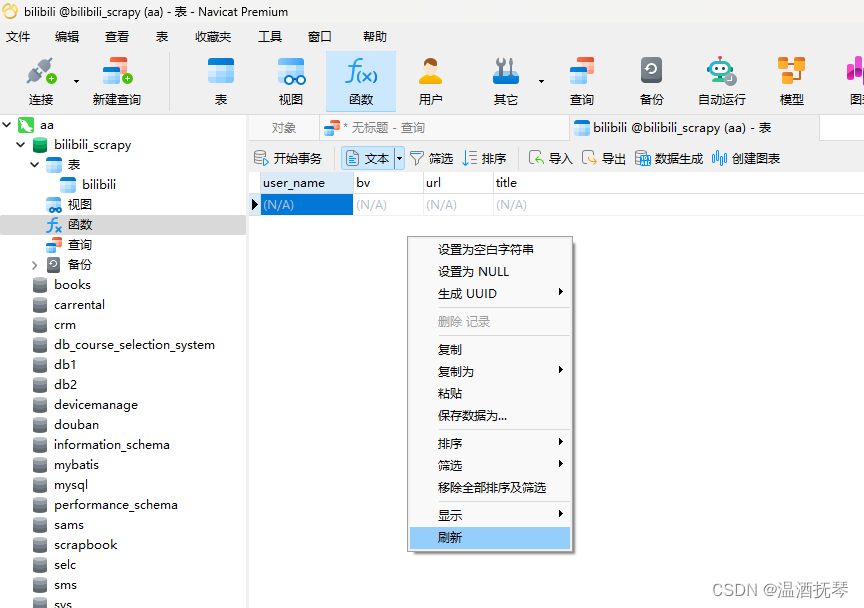
MySQL永久化
5、代码讲解
这里主要是为了想要了解该项目的深层运行逻辑的读者所编写的,想要借此文用作答辩的读者也可阅读。
先简单了解一下scrapy框架:
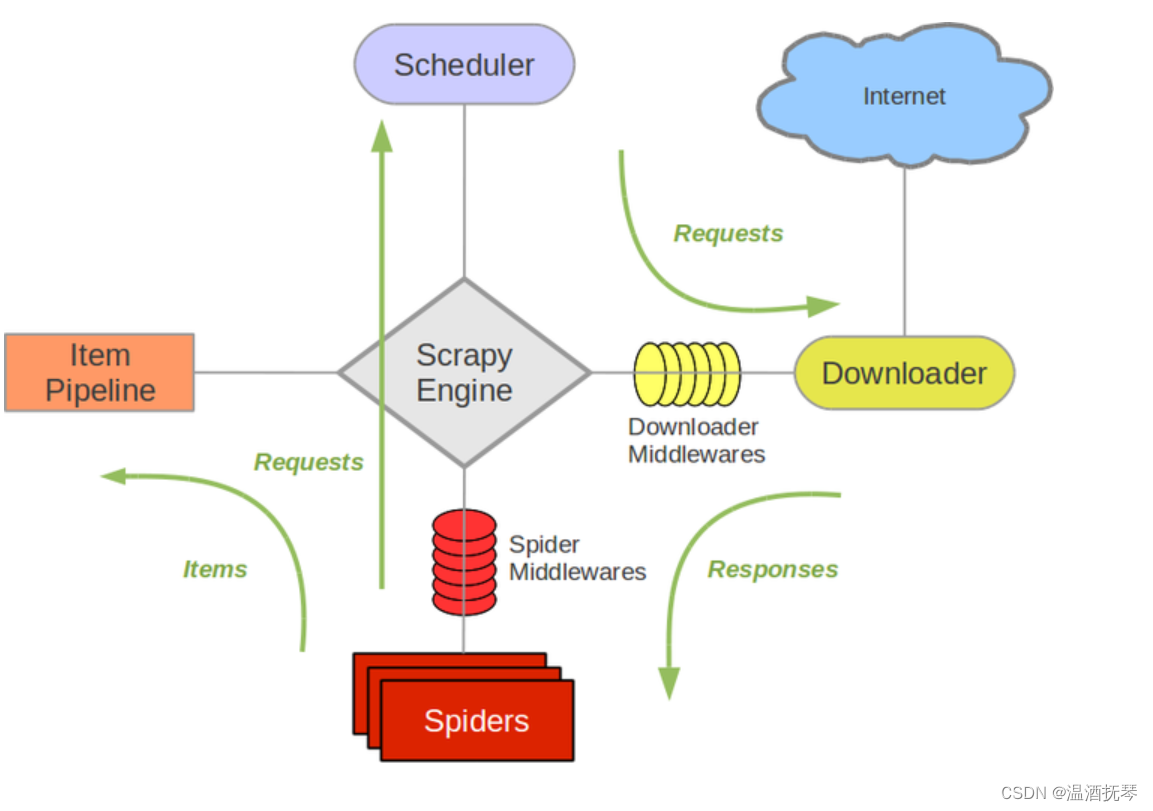
scrapy最主要的运行流程是spider -> middleware -> downloader -> spider -> item pipeline
本项目的流程是spider -> middleware -> spider -> item pipeline,其中downloader的职责被middleware中间件代替。
这个过程会一直重复,直到爬取完毕。
- 爬虫 (Spiders) 组件,它主要负责构造 Request 请求发送给引擎,然后引擎会将该 Request 请求结果交到该组件中进行处理,解析出想要的 items 结果并传给 Item Pipelines 进行后续的处理;
- 下载器 (Downloader) ,很明显它的职责是从互联网上下载网页数据;
- 最左边的 Item Pipeline,用于对生成的 Item 数据进行进一步处理。比如数据清洗、保存到数据库等;
- 中间件 (Downloaders Middlewares) ,包括爬虫中间件、下载中间件等,它们都是用于中间处理数据的。我们可以在此处选择对 item 的数据进行清洗、去重等操作,也可以在这里选择使用何种方式 (MySQL、MongoDB、Redis、甚至文件等) 保存得到的 item;
具体可参考该scrapy流程简介网页
1)bilibili_spider.py
如果每段代码都拿出来单独讲的话篇幅会十分冗长,但是将注释放在项目中的话也会影响界面美观。
所以将注释和理解放在本文中代码里,如下:
import json
import scrapy
from scrapy import Request
from scrapy import signals
# 调用项目中的类,其中.表示文件所在目录,..表示文件所在目录的父目录
# 若不加'.'或'..'则会报错模块不存在
from ..analyze import DataAnalyze
from ..items import ScrapyBilibiliUid
from .tools import play_form, date_convert, time_convert
from datetime import datetime
from bs4 import BeautifulSoup
# 这段代码用于导入settings.py文件中的属性
from scrapy.utils.project import get_project_settings
# 创建实例,读取settings.py中的属性
settings = get_project_settings()
uid = settings.get('UID')
class BilibiliSpiderSpider(scrapy.Spider):
name = "bilibili_spider" # 爬虫名
allowed_domains = ["space.bilibili.com"] # 域名
start_url = f'https://space.bilibili.com/{uid}' # 初始爬虫网址
def __init__(self): # 声明全局变量
self.user_name = None
self.page_num = None
self.home_url = None
self.count = 0
self.i = 0
super(BilibiliSpiderSpider, self).__init__() # 继承和初始化父类的属性和方法
print('spider init done.')
# 使用信号,当爬虫关闭时,会触发close_spider方法
@classmethod
def from_crawler(cls, crawler, *args, **kwargs):
s = cls()
crawler.signals.connect(s.close_spider, signal=signals.spider_closed)
return s
def close_spider(self, spider):
visual = DataAnalyze() # 创建DataAnalyze类的实例visual
df = visual.get_df(None) # 调用get_df方法,获取json文件中转化为DataFrame类型的数据
row_count = df.shape[0] # 获取爬取的数据量
print(f'total num of crawled videos: {row_count}')
print('开始执行数据可视化操作 ...')
# 爬虫结束后进行数据可视化处理
visual.data_visual_line() # 执行这些方法,获得pyechart渲染结果页面
visual.data_visual_pie()
visual.data_visual_bar()
visual.data_visual_rose()
visual.data_visual_scatter()
print('over')
def start_requests(self): # 在__init__方法完成后运行
self.home_url = self.start_url + '/video?tid=0&page=1&keyword=&order=pubdate'
# 发送请求给中间件(middleware),设置回调函数为parse(),并设置Reqeust中meta字典status=0
yield Request(url=self.home_url, callback=self.parse, dont_filter=True, meta={'status': 0})
def parse(self, response, **kwargs): # 获取该 up 主的所有基础视频信息
print('Start ... \n')
self.parse_home(response) # 调用parse_home函数,赋值user_name和page_num
# 断言语句,当page_num=0时结束程序,此时未登陆或网络差
assert self.page_num != 0 and self.page_num is not None, ('Failed to get user page num, poor network '
'condition, retrying ... 重新启动爬虫扫码登陆')
print('Pages Num {}, User Name: {}'.format(self.page_num, self.user_name))
# 创建或打开user_name.json文件,将已赋值的user_name写入其中,为之后的数据可视化做准备
with open('spiders/user_name.json', 'w', encoding='utf-8') as f:
json.dump(self.user_name, f, indent=4, separators=(',', ': '), ensure_ascii=False)
for idx in range(self.page_num): # 遍历主页的视频页数
print('>>>> page {}/{}'.format(idx + 1, self.page_num))
page_url = self.start_url + '/video?tid=0&pn={}&keyword=&order=pubdate'.format(idx + 1)
print('now idx is {}'.format(idx + 1)) # 追踪index页数
print('网页追踪:', page_url) # 追踪网页,查看此时爬取的网站,便于调式
self.i = self.i + 1 #
# 根据page_url发送请求,使用中间件解析网页源码,并设置回调函数为parse_by_page,meta字典status=1
yield Request(url=page_url, callback=self.parse_by_page, dont_filter=True, meta={'status': 1})
def parse_home(self, response):
# 本文使用BeautifulSoup解析网页,相对简单,方便理解
html = BeautifulSoup(response.body, features="html.parser")
print(html.find('span', attrs={'class': 'be-pager-total'})) # 方便调试
page_number = html.find('span', attrs={'class': 'be-pager-total'}).text # 总页数
user_name = html.find('span', id='h-name').text # up主用户名
self.page_num = int(page_number.split(' ')[1]) # 提取数字
self.user_name = user_name
def parse_by_page(self, response):
# 获取单页的视频信息
html = BeautifulSoup(response.body, features="html.parser") # 解析源码
ul_data = html.find('div', id='submit-video-list').find('ul', attrs={'class': 'clearfix cube-list'})
# 筛选、遍历所有li标签的信息(视频列表)
for li in ul_data.find_all('li'):
self.count = self.count + 1
# url & title
a = li.find('a', attrs={'target': '_blank', 'class': 'title'})
a_url = 'https:{}'.format(a['href']) # 视频网址
a_title = a.text # 视频标题
# pub_date & play
date_str = li.find('span', attrs={'class': 'time'}).text.strip()
pub_date = date_convert(date_str) # 视频创建时间
now = datetime.now().strftime('%Y-%m-%d %H:%M:%S') # 爬取时间
# 处理播放量数据格式
play = li.find('span', attrs={'class': 'play'}).text.strip()
play = play_form(play)
# duration
time_str = li.find('span', attrs={'class': 'length'}).text
duration = time_convert(time_str) # 播放时长(s)
# 若url列表的长度为0,则表明爬取信息失败,重新爬取
while a_url is None:
print('failed, try again page {}/{}'.format(self.i + 1, self.page_num))
self.parse_by_page(response)
# 爬取、处理视频BV号
bv = a_url.split('/')[-2]
bili_up = ScrapyBilibiliUid() # 创建item类的实例
bili_up['user_name'] = self.user_name # 将item的字段全部赋值
bili_up['bv'] = bv
bili_up['url'] = a_url
bili_up['title'] = a_title
bili_up['play'] = play
bili_up['duration'] = duration
bili_up['pub_date'] = pub_date
bili_up['now'] = now
bili_up['count'] = self.count
yield bili_up # 提交表单,这些字段被包裹成一个item,传到pipeline中
bilibili_spider.py十分重要,主要流程是先解析up主主页网址,扫码登陆后爬取page_num的值,若为零则说明用户未登录或网络差,让用户重新登陆,登陆后根据page_num遍历所有的视频页网址,遍历爬取每一页,然后将当前页的数据都放进item中提交给pipeline。其中parse_by_page方法中使用了很多tools.py中的方法对爬取到的数据进行清洗。在爬虫运行结束后,会调用spider_closed方法,其调用了analyze.py中的方法,对已经保存的数据进行可视化处理。
在有些情况下即使不登陆账号,page_num也不会为零,但最好登陆较好,因为在后面的页面跳转中浏览器可能会突然弹出登陆界面,导致爬取失败。
其中yield Reqeust()的用法极为需要注意,尤其是在自己写一些scrapy项目时需要注意,yield Reqeust()最好是在一个方法的末尾,而不是在方法的中间位置,因为scrapy框架对请求的处理是异步的,它会先将你的请求挂起,然后继续运行yield语句之后的语句,这样极易造成你期望在请求之后获得的变量为None,因为请求根本没被执行,它只是被挂起了。
2)middlewares.py
# Define here the models for your spider middleware
#
# See documentation in:
# https://docs.scrapy.org/en/latest/topics/spider-middleware.html
from bs4 import BeautifulSoup
from scrapy.http import HtmlResponse
from selenium import webdriver
import time
import random
# useful for handling different item types with a single interface
from itemadapter import is_item, ItemAdapter
class SeleniumMiddleware:
@classmethod
def __init__(self):
options = webdriver.ChromeOptions()
options.add_argument('log-level=2') # 关于ChromeDriver方面只输出错误信息,而不会输出其他类型的日志信息
options.add_argument('--no-sandbox') # 禁用沙盒模式,可以开放进程间的通信和资源共享,建议在安全系数高的网站(如b站、知乎等)中才使用,防止恶意软件攻击
options.add_experimental_option("detach", True) # chrome窗口保持开启状态,直到手动关闭,用于展示
self.browser = webdriver.Chrome(options=options)
def spider_closed(self, spider):
self.browser.quit()
print('browser驱动已关闭')
def process_request(self, request, spider):
# 使用meta字典来传递状态
meta = request.meta
print('status:', meta['status'])
print('使用 selenium 请求页面:{}'.format(request.url))
if meta['status'] == 0:
self.browser.get(request.url)
print('请在20秒内扫码登陆!')
# 等待扫码登陆
time.sleep(20 + 2 * random.random())
self.browser.execute_script("window.scrollTo(0, document.body.scrollHeight);") # 将浏览器滑到底页
print('middlewares init done.')
print('此时的地址为:', request.url)
# 将最后渲染得到的页面源码作为响应返回
return HtmlResponse(url=request.url, body=self.browser.page_source, request=request, encoding='utf-8',
status=200)
if meta['status'] == 1:
self.browser.get(request.url)
time.sleep(2 + 2 * random.random()) # 休眠等待网页加载(在获取网页后仍需时间加载,因为selenium是实时渲染网页的)
self.browser.execute_script("window.scrollTo(0, document.body.scrollHeight);") # 将该浏览器页面滚动到最底部,用于展示爬取过程时使用
print('此时的地址为:', request.url)
return HtmlResponse(url=request.url, body=self.browser.page_source, request=request, encoding='utf-8',
status=200)
SeleniumMiddleware中的process_request方法非常重要,关于webdriver的用法请自行学习。
其中根据请求的meta字典中status的值来决定处理的是登录请求(status==0)还是平常爬取请求(status==1),需要注意的是在browser.get(url)后,需要time.sleep(time)让等待一段时间,让网页加载完毕后再browser.page_source获取网页源码后返回Response响应。
在process_reqeuest中有'self.browser.execute_script("window.scrollTo(0, document.body.scrollHeight);") ',该语句将浏览器页面滑到最底部,使爬取过程更明了。
该中间件的作用是拦截从spider发出的请求,然后根据该请求去获取目标网页的源码。
3)pipelines.py
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://docs.scrapy.org/en/latest/topics/item-pipeline.html
# useful for handling different item types with a single interface
import pymysql
import os.path as osp
from scrapy.utils.project import get_project_settings
from .spiders.tools import mkdir_if_missing, write_json, read_json
settings = get_project_settings()
uid = settings.get('UID')
save_dir_json = settings.get('SAVE_DIR_JSON')
user_name = read_json('spiders/user_name.json')
host = settings['MYSQL_HOST']
user = settings['MYSQL_USER']
psd = settings['MYSQL_PASSWORD']
db = settings['MYSQL_DB']
c = settings['CHARSET']
port = settings['MYSQL_PORT']
use_unicode = settings['use_unicode']
class MySQLPipeline:
def __init__(self):
con = pymysql.connect(host=host, user=user, passwd=psd, db=db, charset=c, port=port, use_unicode=use_unicode)
cue = con.cursor()
cue.execute("USE bilibili_scrapy")
cue.execute("SET NAMES utf8mb4;")
cue.execute("SET FOREIGN_KEY_CHECKS = 0;")
cue.execute(f"DROP TABLE IF EXISTS `{user_name}_{uid}`;")
cue.execute(f"CREATE TABLE `{user_name}_{uid}` ("
"`user_name` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci NULL DEFAULT NULL,"
"`bv` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci NULL DEFAULT NULL,"
"`url` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci NULL DEFAULT NULL,"
"`title` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci NULL DEFAULT NULL,"
"`play` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci NULL DEFAULT NULL,"
"`duration` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci NULL DEFAULT NULL,"
"`pub_date` datetime NULL DEFAULT NULL,"
"`now` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci NULL DEFAULT NULL"
") ENGINE = InnoDB CHARACTER SET = utf8mb4 COLLATE = utf8mb4_0900_ai_ci ROW_FORMAT = Dynamic;")
cue.execute("SET FOREIGN_KEY_CHECKS = 1;")
print("mysql pipeline init done") # 测试语句
def process_item(self, item, spider):
# 数据库连接
con = pymysql.connect(host=host, user=user, passwd=psd, db=db, charset=c, port=port, use_unicode=use_unicode)
# 数据库游标
cue = con.cursor()
print("mysql connect success") # 测试语句,这在程序执行时检查程序是否执行到这一步
cue.execute("USE bilibili_scrapy")
try:
cue.execute(f"insert into `{user_name}_{uid}` (user_name,bv,url,title,play,duration,pub_date,now) values("
f"%s,%s,%s,%s,%s,%s,%s,%s)",
[item['user_name'], item['bv'], item['url'], item['title'], item['play'],
item['duration'], item['pub_date'], item['now']])
print("insert success\n") # 测试语句
except Exception as e:
print('Insert error:', e)
con.rollback()
else:
con.commit()
con.close()
return item
class JsonPipeline:
def save(self, json_path, item):
result = {'user_name': item['user_name'],
'bv': item['bv'],
'url': item['url'],
"title": item['title'],
'play': item['play'],
'duration': item['duration'],
'pub_date': item['pub_date'],
'now': item['now']}
print('write {} to {}'.format(item['title'], json_path))
count = item['count']
dir_name = osp.dirname(json_path)
mkdir_if_missing(dir_name)
write_json(result, json_path, count)
def process_item(self, item, spider):
# 生成JSON文件的路径
json_path = osp.join(save_dir_json, '{}_{}'.format(item['user_name'], uid), 'primary', 'full.json')
# 调用save()方法将完整数据保存为JSON文件
self.save(json_path, item)
return item # 将item传递给下一个pipeline管道
在settings.py中读取MySQL的连接信息和当前up的uid和用户名以及json文件的储存目录地址。
MySQLPipeline类
在__init__方法中在bilibili_scrapy数据库中创建'user_name'_'uid'形式的表,方便后续的数据存储,且便于区分不同up的数据。
process_item方法则将item中的数据都插入刚创建的表中,存储数据。
JsonPipeline类
将item中的数据存储到json文件中,为后续数据可视化提供dataframe类型的数据源。其调用了tools.py中的工具方法,用于创建存储目录和写入json数据,请自行研读。
4)analyze.py
数据可视化处理,使用pyechart对爬取到的数据进行处理和分析,得到了五个渲染图,共四种类型(玫瑰图是饼图的一种),若有读者对大数据可视化研究颇深,可根据所爬到的数据字段自行添加新的可视化图。
import json
from pyecharts import options as opts
from pyecharts.charts import Bar, Line, Pie, Scatter
import os.path as osp
import pandas as pd
import numpy as np
from scrapy.utils.project import get_project_settings
settings = get_project_settings()
uid = settings.get('UID')
save_dir_json = settings.get('SAVE_DIR_JSON')
class DataAnalyze:
def __init__(self):
self.durations = None
def get_df(self, limit):
user_name = self.read_json('spiders/user_name.json', None)
json_path = osp.join(save_dir_json, '{}_{}'.format(user_name, uid), 'primary', 'full.json')
data = self.read_json(json_path, limit=limit)
df = pd.DataFrame(data)
return df
def read_json(self, json_path, limit):
with open(json_path, 'r', encoding='utf-8') as f:
data = json.load(f)
if limit is not None:
data = data[:limit]
return data
def data_visual_line(self):
df = self.get_df(40)
self.durations = df['duration']
self.durations = self.durations.astype(int)
mean_value = np.mean(self.durations)
# 创建一个Line对象
line = Line()
# 添加数据
line.add_xaxis(list(range(len(self.durations))))
line.add_yaxis("时长统计", self.durations)
# 添加平均值线
line.add_yaxis("展示平均时长", [mean_value], is_smooth=True,
linestyle_opts=opts.LineStyleOpts(color='red', width=2, type_='dashed'))
line.set_series_opts(
markpoint_opts=opts.MarkPointOpts(data=[opts.MarkPointItem(type_='max', name='最大值')]))
# 设置全局配置项
line.set_global_opts(
title_opts=opts.TitleOpts(title="视频时长统计图"),
xaxis_opts=opts.AxisOpts(name="编号"),
yaxis_opts=opts.AxisOpts(name="时长(秒)"),
)
# 渲染图表
line.render("时长统计-折线图.html")
def data_visual_pie(self):
df = self.get_df(None)
df['year'] = df['pub_date'].apply(lambda x: x[:4])
pie = Pie()
# 添加数据
pie.add("", [list(z) for z in zip(df['year'].unique(), df['year'].value_counts().tolist())])
# 设置全局配置项
pie.set_global_opts(
title_opts=opts.TitleOpts(title="视频创作年份"),
legend_opts=opts.LegendOpts(orient="vertical", pos_top="5%", pos_left="2%")
)
# 渲染图表
pie.render("创作年份分布-饼图.html")
def data_visual_bar(self):
df = self.get_df(30)
# 创建一个Bar对象
bar = Bar()
# 添加数据
bar.add_xaxis(list(range(1, len(df) + 1)))
bar.add_yaxis("播放量", df['play'].tolist())
# 设置全局配置项
bar.set_global_opts(
title_opts=opts.TitleOpts(title="前十视频播放数据展示"),
xaxis_opts=opts.AxisOpts(name="标题"),
yaxis_opts=opts.AxisOpts(name="播放量")
)
# 渲染图表
bar.render("视频播放量-柱状图.html")
def data_visual_rose(self):
df = self.get_df(10)
play = df['play']
duration = df['duration']
# 创建 Pie 图表(玫瑰图)
pie = Pie()
pie.add("", [list(z) for z in zip(map(str, duration), play)], radius=["30%", "75%"],
center=["30%", "70%"], rosetype="area")
pie.set_global_opts(title_opts=opts.TitleOpts(title="播放时长分布"))
# 生成 HTML 文件(可选)
pie.render("播放时长分布-玫瑰图.html")
def data_visual_scatter(self):
df = self.get_df(60)
duration = df['duration']
durations = duration.astype(int)
play = df['play'].astype(int)
axis = [list(x) for x in zip(list(durations), list(play))]
# 对X数据排序
axis.sort(key=lambda x: x[0])
x_data = [d[0] for d in axis] # x数据
y_data = [d[1] for d in axis] # y数据
c = (
# 散点图
# 初始化
Scatter(init_opts=opts.InitOpts(width="900px", height="600px"))
.add_xaxis(xaxis_data=x_data)
.add_yaxis(
# 系列名称
series_name="播放次数与视频时长关系",
# 系列数据
y_axis=y_data,
# 标记的大小
symbol_size=20,
# 标记的图形
symbol=None,
# 系列 label 颜色
color='#00CCFF',
# 标签配置项
label_opts=opts.LabelOpts(is_show=False), # 不显示标签
)
# 系统配置项
.set_series_opts()
# 全局配置项
.set_global_opts(
# x轴配置
xaxis_opts=opts.AxisOpts(
name='\n时长',
name_location='center',
name_gap=15,
# 坐标轴类型 'value': 数值轴
type_="value",
# 分割线配置项
splitline_opts=opts.SplitLineOpts(is_show=True) # 显示分割线
),
# y轴配置
yaxis_opts=opts.AxisOpts(
name='播放量',
# 坐标轴类型 'value': 数值轴
type_="value",
# 坐标轴刻度配置项
axistick_opts=opts.AxisTickOpts(is_show=True), # 显示刻度
# 分割线配置项
splitline_opts=opts.SplitLineOpts(is_show=True), # 显示分割线
),
# 提示框配置项
tooltip_opts=opts.TooltipOpts(formatter='({c})'), # 显示提示框组件
)
.render("播放次数与视频时长关系-散点图.html")
)
这里比较简单,主要是从json文件中读取数据并转化为dataframe类型的数据,再使用pandas相关知识获取指定字段的数据,再进行可视化分析,由于篇幅关系就不多赘叙了。
5)settings.py
为了使代码更简洁明了,现将注释清除
BOT_NAME = "scrapy_bilibili_uid"
SPIDER_MODULES = ["scrapy_bilibili_uid.spiders"]
NEWSPIDER_MODULE = "scrapy_bilibili_uid.spiders"
DOWNLOADER_MIDDLEWARES = {
'scrapy_bilibili_uid.middlewares.SeleniumMiddleware': 200, # 添加自定义的SeleniumMiddleware
}
# Obey robots.txt rules
ROBOTSTXT_OBEY = False
# Set settings whose default value is deprecated to a future-proof value
REQUEST_FINGERPRINTER_IMPLEMENTATION = "2.7"
TWISTED_REACTOR = "twisted.internet.asyncioreactor.AsyncioSelectorReactor"
FEED_EXPORT_ENCODING = "utf-8"
# 设置日志文件存储位置,若log目录不存在则必须手动创建
LOG_FILE = 'log/scrapy.log'
# 设置USER_AGENT
USER_AGENT = ('Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.106 '
'Safari/537.36')
# 取消浏览器检查SSL
DOWNLOADER_CLIENT_TLS_METHOD = 'TLS'
DOWNLOADER_CLIENTCONTEXTFACTORY = 'scrapy.core.downloader.contextfactory.ScrapyClientContextFactory'
DOWNLOADER_CLIENT_TLS_VERIFY = False
# 解决爬取遗漏问题
AUTOTHROTTLE_ENABLED = True
# 设置数据库连接信息
MYSQL_HOST = '127.0.0.1'
MYSQL_USER = 'root'
MYSQL_PASSWORD = '123456'
MYSQL_PORT = 3306
MYSQL_DB = 'bilibili_scrapy'
CHARSET = 'utf8'
use_unicode = False
UID = '18706318'
SAVE_DIR_JSON = 'spiders/json'
ITEM_PIPELINES = {
'scrapy_bilibili_uid.pipelines.JsonPipeline': 200,
'scrapy_bilibili_uid.pipelines.MySQLPipeline': 300
}
DOWNLOADER_MIDDLEWARES = {
'scrapy_bilibili_uid.middlewares.SeleniumMiddleware': 200
}
这里启用自定义的中间件SeleniumMiddleware类
LOG_FILE = 'log/scrapy.log',设置日志文件存储位置,若log目录不存在则必须手动创建
ROBOTSTXT_OBEY = False
这里最好取消遵循robot规则,否则项目开始时会对start_url进行两次访问,极为不便。
ITEM_PIPELINES = {
'scrapy_bilibili_uid.pipelines.JsonPipeline': 200,
'scrapy_bilibili_uid.pipelines.MySQLPipeline': 300
}
这里启用指定管道并设置这两个管道的优先级关系,即先调用JsonPipeline再调用MySQLPipeline
UID = '18706318'
SAVE_DIR_JSON = 'spiders/json'
若想要更改要爬取的目标up主和json文件存储目录,则可更改UID和SAVE_DIR_JSON的值
6)tools.py
import os
import os.path as osp
import errno
import json
import warnings
import re
from datetime import datetime, timedelta
def play_form(play):
if '万' in play:
play = int(float(re.findall(r'\d+\.?\d*', play)[0]) * 10000)
else:
play = int(play)
return play
def date_convert(date_str): # 处理视频创建时间的格式
if '小时' in date_str:
hours = int(date_str.replace('小时前', ''))
now = datetime.now()
date_str = now - timedelta(hours=hours)
date_str = date_str.strftime('%Y-%m-%d')
return date_str
elif date_str == '昨天':
now = datetime.now()
date_str = now - timedelta(days=1)
date_str = date_str.strftime('%Y-%m-%d')
return date_str
else:
date_item = date_str.split('-')
assert len(date_item) == 2 or len(date_item) == 3, 'date format error: {}, x-x or x-x-x expected!'.format(
date_str)
if len(date_item) == 2:
year = datetime.now().strftime('%Y')
date_str = '{}-{:>02d}-{:>02d}'.format(year, int(date_item[0]), int(date_item[1]))
return date_str
else:
date_str = '{}-{:>02d}-{:>02d}'.format(date_item[0], int(date_item[1]), int(date_item[2]))
return date_str
def time_convert(time_str): # 处理视频时长的格式
time_item = time_str.split(':')
assert len(time_item) in [2, 3], 'time format error: {}, x:x or x:x:x expected!'.format(time_str)
if len(time_item) == 2:
seconds = int(time_item[0]) * 60 + int(time_item[1])
else: # 当时间为xx:xx:xx的格式时
seconds = int(time_item[0]) * 3600 + int(time_item[1]) * 60 + int(time_item[2])
return seconds
def mkdir_if_missing(dirname):
"""Creates dirname if it is missing."""
if not osp.exists(dirname):
try:
os.makedirs(dirname)
except OSError as e:
if e.errno != errno.EEXIST:
raise
def check_isfile(fpath):
"""Checks if the given path is a file.
Args:
fpath (str): file path.
Returns:
bool
"""
isfile = osp.isfile(fpath)
if not isfile:
warnings.warn('No file found at "{}"'.format(fpath))
return isfile
def read_json(fpath):
"""Reads json file from a path."""
with open(fpath, 'r', encoding='UTF-8') as f:
obj = json.load(f)
return obj
def write_json(obj, fpath, count):
"""Writes to a json file."""
mkdir_if_missing(osp.dirname(fpath))
if count == 1:
data = []
else:
data = read_json(fpath)
data.append(obj)
with open(fpath, 'w', encoding='utf-8') as f:
json.dump(data, f, indent=4, separators=(',', ': '), ensure_ascii=False)
各种处理数据和有关json文件存储的方法。
结语
整体来说本项目使用了scrapy框架爬取了b站up主的视频信息,并使用Json文件和MySQL数据库对数据进行存储,再使用pyechart对数据可视化处理。
其中spider部分参考了这篇博客,这篇博客的作者对爬虫的讲解非常详细,以及将数据存储为json文件的代码很有学习价值,不考虑MySQL存储以及数据可视化的读者可阅读之。但需要注意的是,该篇博客是在2020年发布的,selenium使用的是无头模式,但现在的b站使用无头模式爬取的网页源码会被过滤,即必须登陆才可爬取到有用的信息,读者自行改之。
作者在大数据爬虫方面有很多知识方面还很生涩,才疏学浅,难免有遗漏的地方,还请各位斧正。
有疑问的读者可私信作者,读之即回。















 2612
2612

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









