







- NLTK 在NLP上的经典应用: 情感分析、文本相似度、文本分类
- 【转载】NLTK 基本功能介绍:python的nltk中文使用和学习资料汇总帮你入门提高 - 作者:糊糊
- 文本处理的流程
- TF-IDF 的学习
1) 自带语料库的使用:
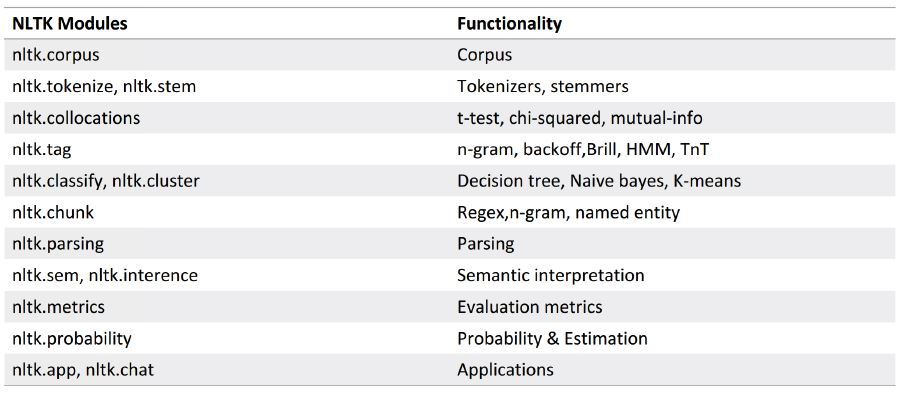
#自带语料库使用
from nltk.corpus import brown
brown.categories()
['adventure',
'belles_lettres',
'editorial',
'fiction',
'government',
'hobbies',
'humor',
'learned',
'lore',
'mystery',
'news',
'religion',
'reviews',
'romance',
'science_fiction']2) 文本处理的流程:
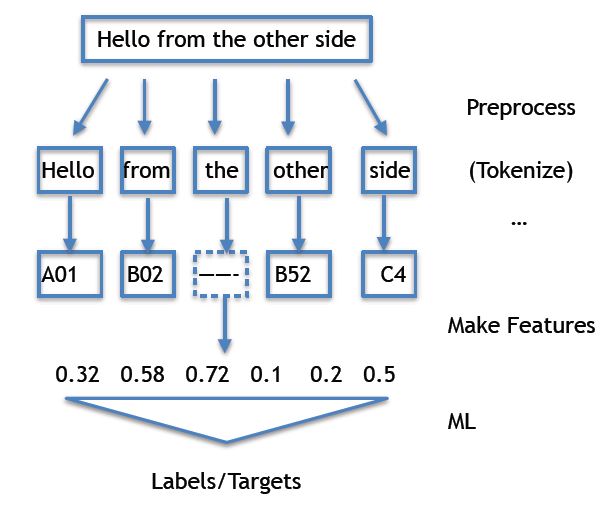
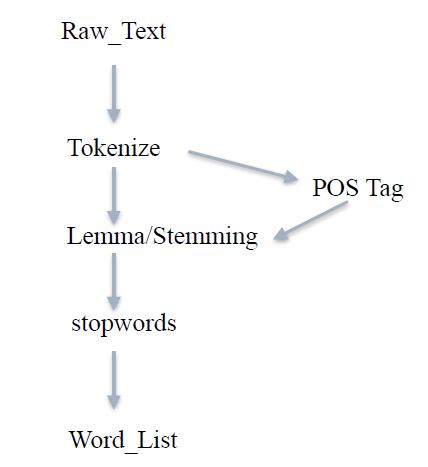
#0, Raw_Text 最初始的文本
#1, Tokenize 分词或分句
#2, POS Tag 词形标注
#3, Lemma/Stemming 提取词干、词形归一
#4, stopwords 去停词表中的词语
#5, Word_List
#6, ML模型:神经网络、SVM、LR、RF、LSTM等等#### 2.1 Tokenize :断词 - 把长句子拆分为有“意义”的小部件
#https://blog.csdn.net/bentley2010/article/details/79340827#Python数据挖掘-NLTK文本分析+jieba中文文本挖掘
import nltk
sentence = " hello, world"
tokens = nltk.word_tokenize(sentence)
tokens
#中文分词
#import jieba# 输出:['hello', ',', 'world']
#举例,有时候需要处理一些符号, 表情
from nltk.tokenize import word_tokenize
tweet = 'RT @angelababy: love you baby! :D http://ah.love #168#'
print(word_tokenize(tweet))
#输出:['RT', '@', 'angelababy', ':', 'love', 'you', 'baby', '!', ':', 'D', 'http', ':', '//ah.love', '#', '168', '#']
#### 2.2 正则表达式学习:http://www.regexlab.com/zh/regref.htm 需要研究一下
#### 2.3 词形归一化处理: Stemming 词干提取; Lemmatization词形归一
##### NLTK 实现 Stemming
#Stemming java代码解析:http://qinxuye.me/article/porter-stemmer/
from nltk.stem.porter import PorterStemmer #后缀剥离的词干提取算法:波特词干器
porter_stemmer = PorterStemmer()
print(porter_stemmer.stem('multiply'))
print(porter_stemmer.stem('provision'))
print("***************分割线*************")
from nltk.stem.lancaster import LancasterStemmer
lancaster_stemmer = LancasterStemmer()
print(lancaster_stemmer.stem('multiply'))
print(lancaster_stemmer.stem('provision'))
print("***************分割线*************")
from nltk.stem import SnowballStemmer
snowball_stemmer = SnowballStemmer("english")
print(snowball_stemmer.stem('multiply'))
print(snowball_stemmer.stem('presumably'))
print("***************分割线*************")
from nltk.stem.porter import PorterStemmer
p = PorterStemmer()
print(p.stem('went'))
print(p.stem('wenting'))输出
multipli
provis
***************分割线*************
multiply
provid
***************分割线*************
multipli
presum
***************分割线*************
went
went##### NLTK 实现 Lemma
from nltk.stem import WordNetLemmatizer
wordnet_lemmatizer = WordNetLemmatizer()
print("***************分割线*************")
print(wordnet_lemmatizer.lemmatize('dogs'))
print(wordnet_lemmatizer.lemmatize('chhurches'))输出
***************分割线*************
dog
chhurches
Went# Lemma小问题: Went -> 它动词可以表示go的过去式, 名词可以表示英文名:温特
# 没有POS Tag, 默认是NN 名词
print(wordnet_lemmatizer.lemmatize('are'))
print(wordnet_lemmatizer.lemmatize('is'))
print("***************分割线*************")
print(wordnet_lemmatizer.lemmatize('are', pos = 'v')) #加上了动词的属性
print(wordnet_lemmatizer.lemmatize('is', pos = 'v'))输出:
are
is
***************分割线*************
be
be#### 2.4 通过POS_Tag词性标注
text = nltk.word_tokenize('what does the cat say')
print(text)
print(nltk.pos_tag(text))['what', 'does', 'the', 'cat', 'say']
[('what', 'WDT'), ('does', 'VBZ'), ('the', 'DT'), ('cat', 'NNS'), ('say', 'VBP')]
from nltk.corpus import stopwords
from nltk.tokenize import sent_tokenize,word_tokenize
example_text = 'In 2008, Facebook set up its international headquarters in Ireland to take advantage of the country\'s low corporate tax rates but it also meant all users outside the US and Canada were protected by European regulations.'
#导入英文停止词,set()集合函数消除重复词
list_stopWords = list(set(stopwords.words('english')))
#分句
list_sentences = sent_tokenize(example_text)
#分词
list_words = word_tokenize(example_text)
#过滤停止词语
filtered_words = [w for w in list_words if not w in list_stopWords]
filtered_words['In',
'2008',
',',
'Facebook',
'set',
'international',
'headquarters',
'Ireland',
'take',
'advantage',
'country',
"'s",
'low',
'corporate',
'tax',
'rates',
'also',
'meant',
'users',
'outside',
'US',
'Canada',
'protected',
'European',
'regulations',
'.']## 3)TF-IDF
【转】 TF-IDF算法解析与Python实现(基于sklearn)













 527
527











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









