






一、classification
1、应用与问题定义
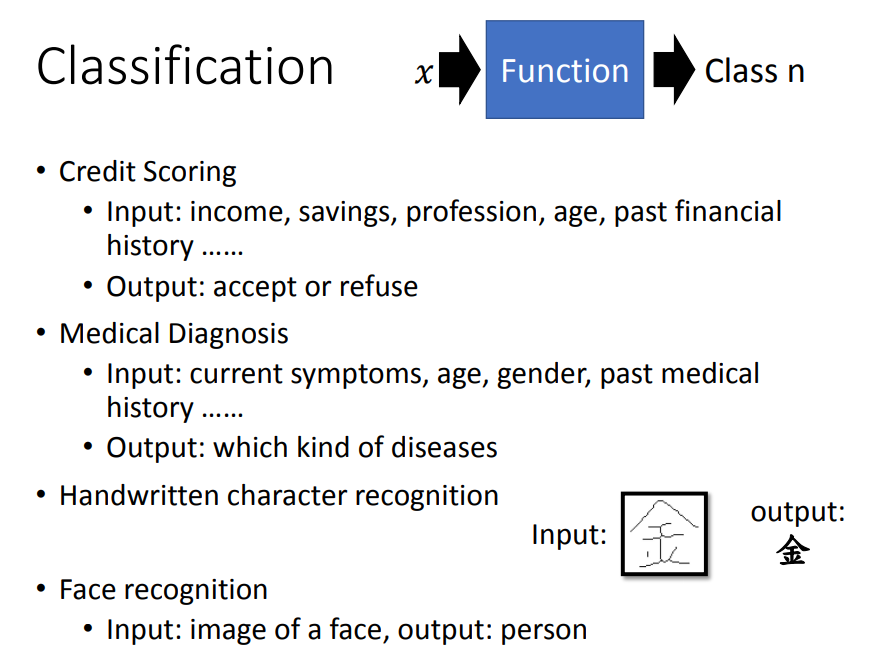

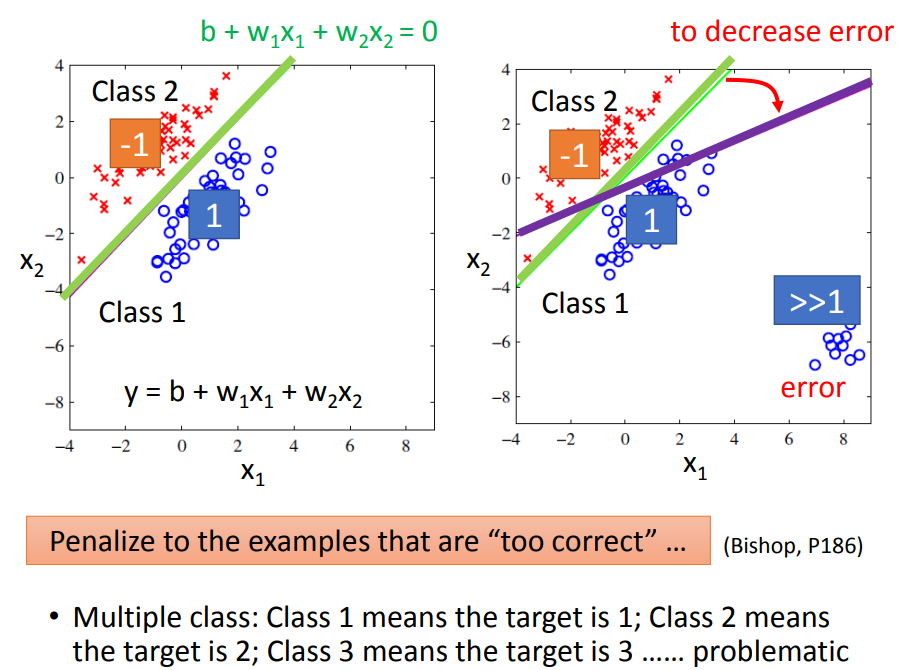
如果作为regression来处理,为了照顾较远的点会得到紫色的线。因此简单地把归为一个数是不合理的。
比如有3类,分别为123,因为12比较接近,23比较接近,但它们实际并没有关系,就不符合现实情况。

假设是个二分类问题,loss就是错误的次数,错误一次为1,正确为0。
但是这个loss函数不能进行微分,怎么解决呢?
2、概率生成模型

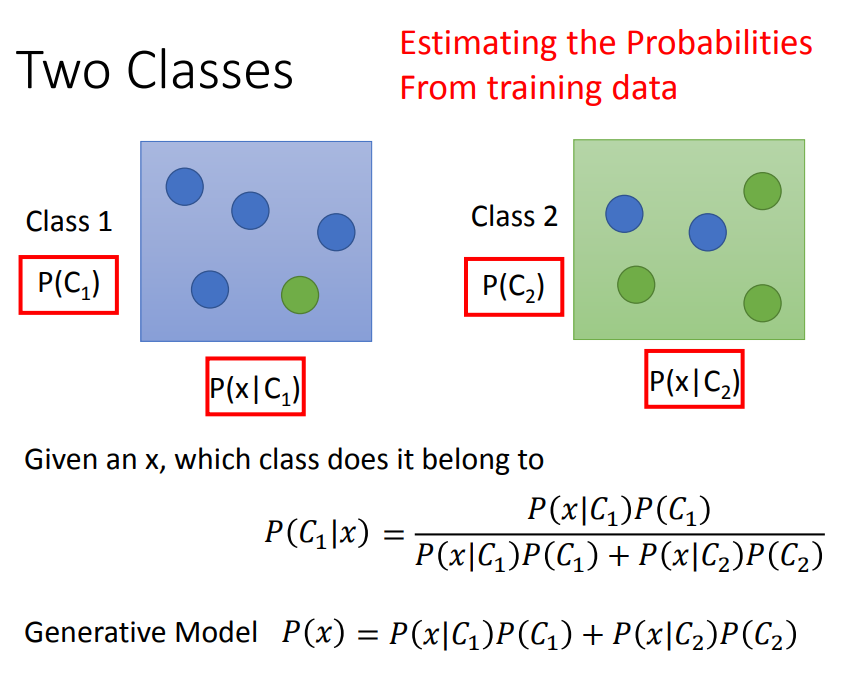
可以计算出x属于class 1的几率。

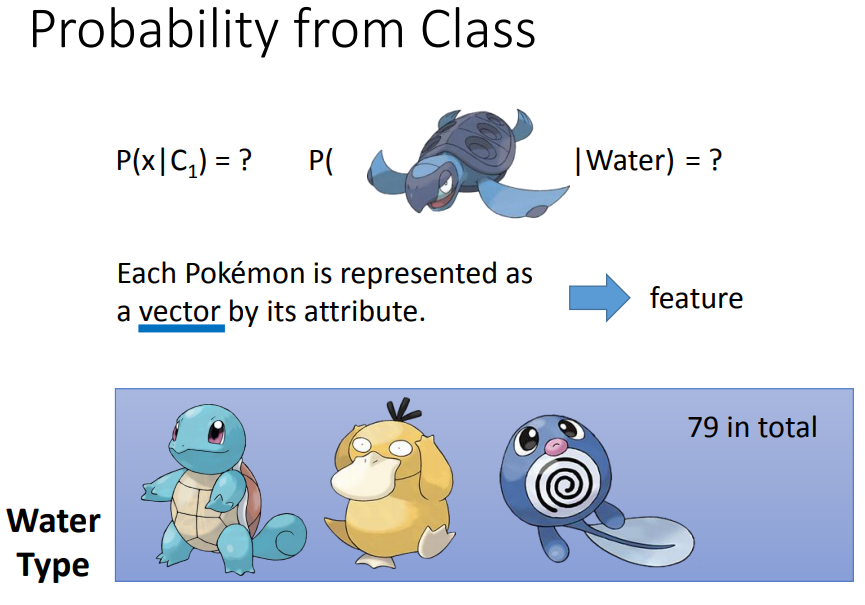
需要计算从类1中挑出x的几率。

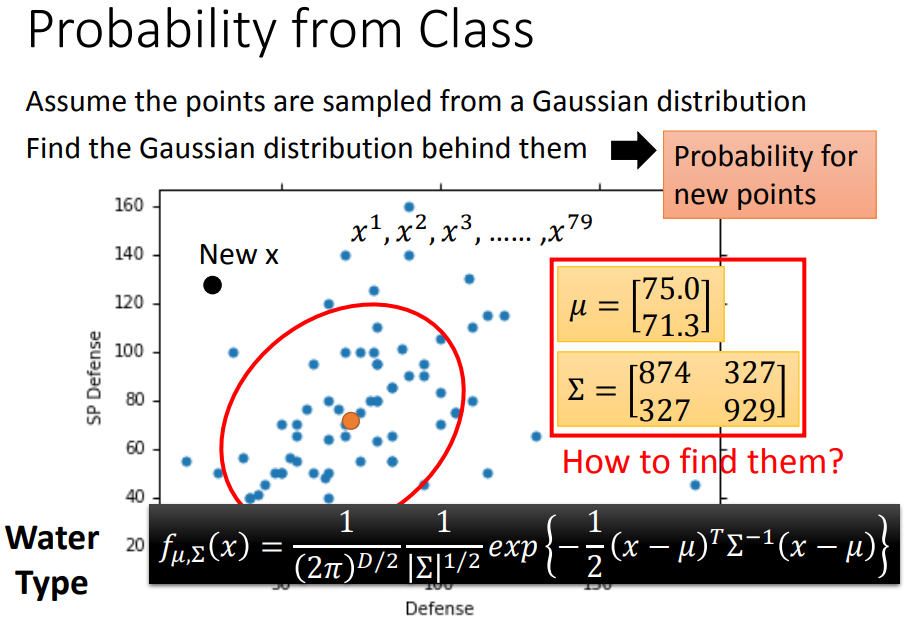
高斯分布即正态分布,如果知道𝜇,Σ的话,假设这只乌龟是新的宝可梦,就可以通过高斯函数计算新点sample(抽样)出来的几率大小。
如何找高斯分布的𝜇,Σ呢:
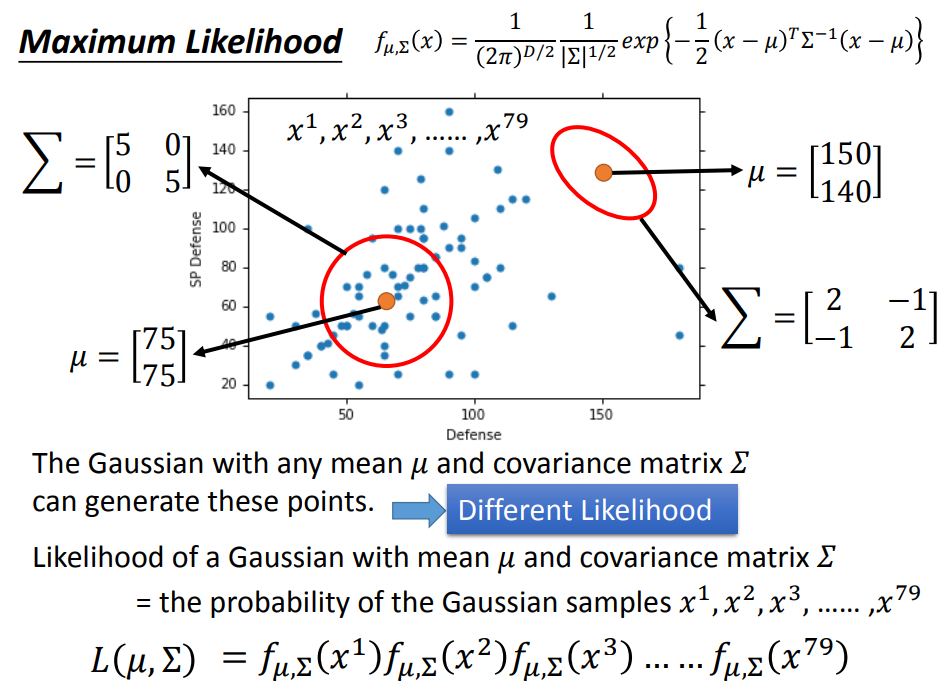
计算一个参数为𝜇,Σ的高斯分布sample出每个宝可梦的几率;
找到sample出79个宝可梦的几率最大的gaussian(比如要是靠下的黄圈sample出79个点的几率就比较高);
由于每个点是被独立sample出来的,所以高斯sample出79个点的几率是每个点被sample出的几率相乘;
我们就要找一个高斯函数,使得sample出79个点的几率最大,即L最大(这里的L是likelihood不是loss);

通过化简发现,最好的μ为mean,再计算出最好的Σ;


3、修正概率生成模型
上面的例子里,每个function都有自己的mean和variance,但是常见的做法是,不同的class可以share同一个从convariance的matrix,否则model参数太多,variance大,容易过拟合。

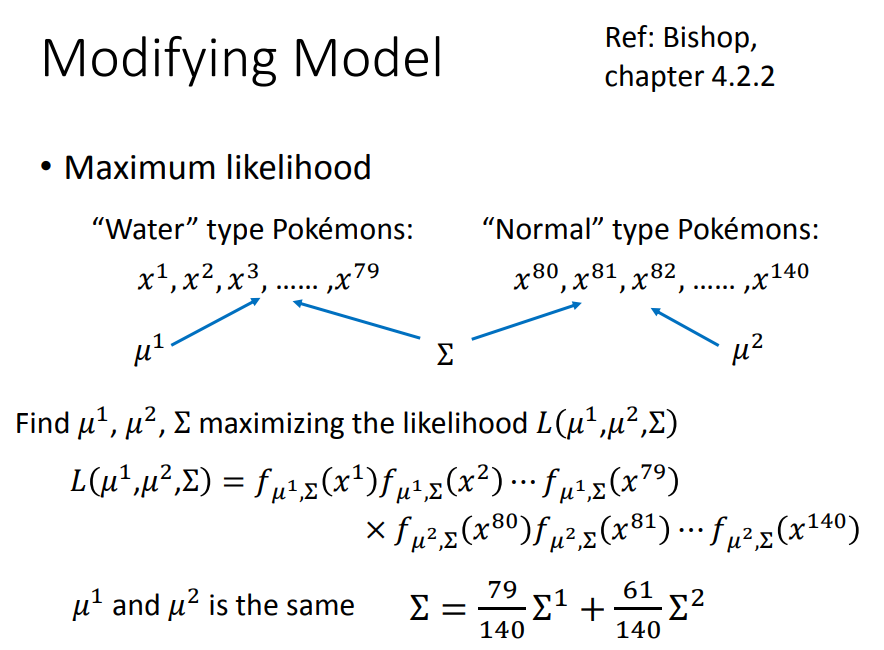
根据之前的Σ1和Σ2乘上比例得到新的Σ。计算likelihood还是将每一个sample的几率相乘。
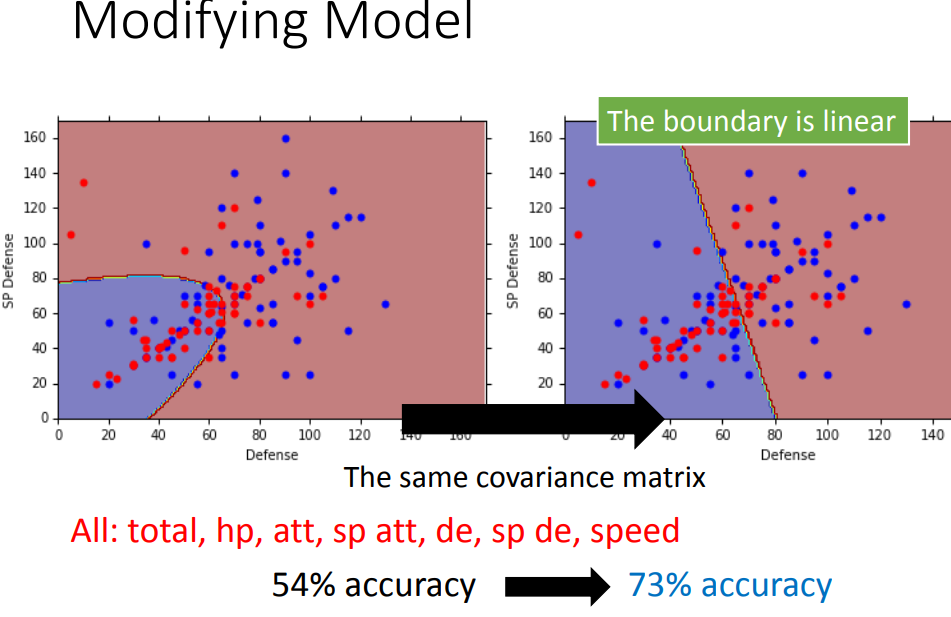
这样得到的二分类的高斯模型是线性的model。
4、小结


不一定选高斯分布作为概率分布,如二维问题可以采用伯努利分布;
假设所有的feature是independent的,不model feature间的covariance,叫做朴素贝叶斯分类;

后验概率:sigmoid function
经过一番化简:
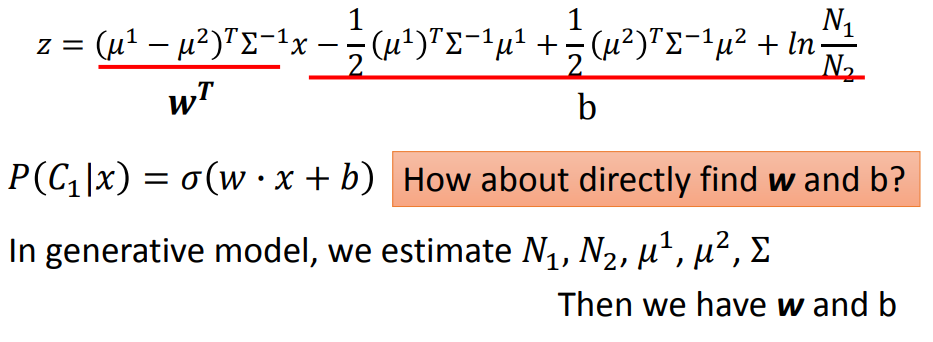
可以看成wx+b,在套上一个sigmoid函数;
我们发现既然可以直接推导出w和b,就不需要用概率的方法去估计𝜇,Σ,这种改进后的就是逻辑回归;
5、逻辑回归
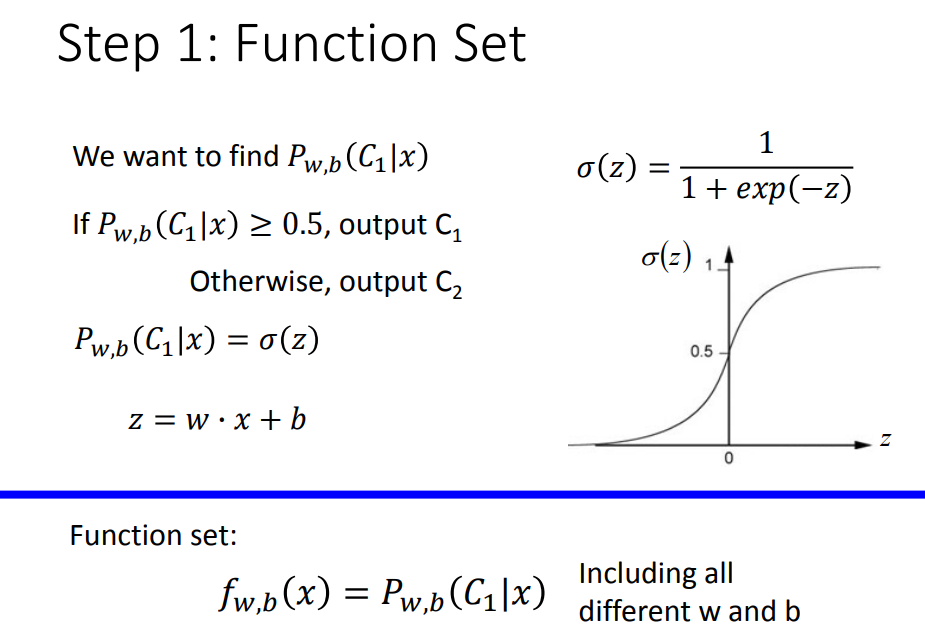
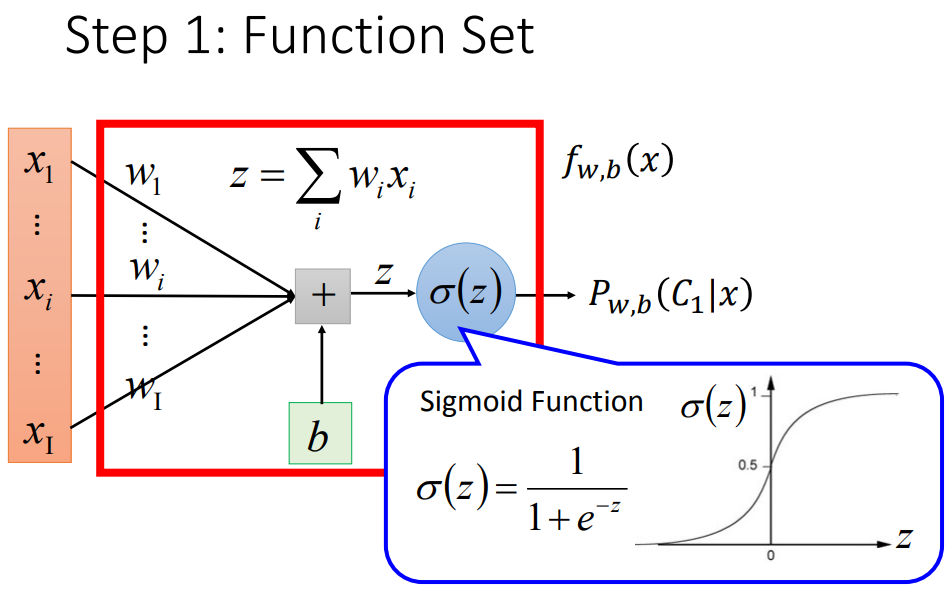
如果概率分布可以化简成sigmoid函数,并且可以把z表示成z=wx+b,把这个叫做逻辑回归;


要找到能够产生N个训练数据的几率L(w,b)最大的w和b;

将argmaxL(w,b)写成argmin[-lnL(w,b)]的形式(找最小),这样可以拆分成左下-lnf()相加的形式;
将两个类别分别表示为右上的0和1,进一步可以表示为右下的统一的形式;

这个计算公式相当于两个伯努利分布的交叉熵;
1,1-->-1; 1,0-->0; 0,0-->-1; 0,1-->0;

交叉熵的总和作为损失函数。
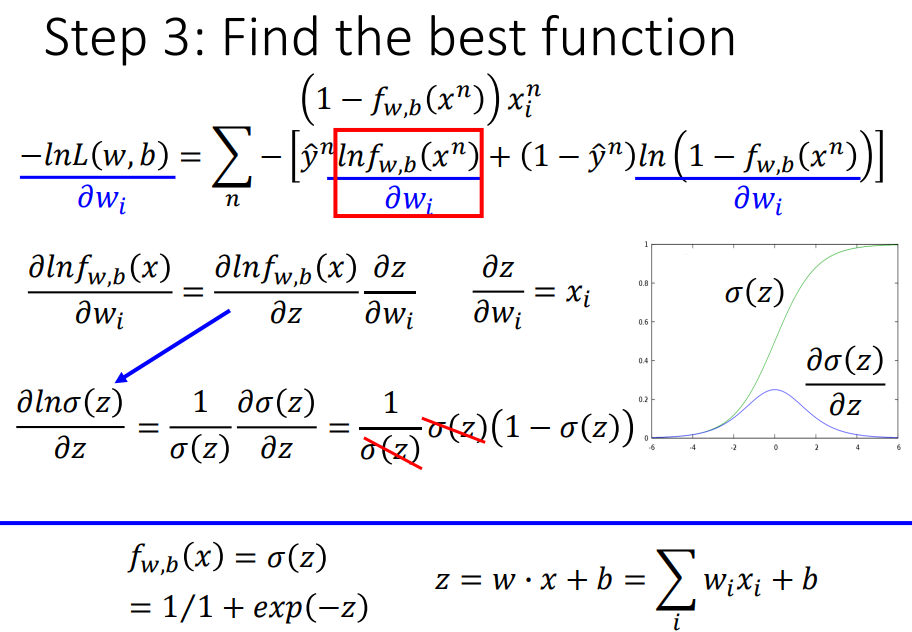

分别计算两项对w的偏微分。

带入化简,得到下方w参数更新的公式。
w的update取决于三件事:来自于data的xi、学习率、预测值与目标值之差(预测值和真实值的差距越大,update的量就应该越大)。

对于第三步,逻辑回归和线性回归的形式是一模一样的,但是逻辑回归的真实值是0和1,预测值是01之间的数,线性回归可以是任意值;
对于第二步的问题,为什么逻辑回归不能用square error?

sigmoid函数求偏微分结果为f(x)(1-f(x))。
由偏微分得到的结果,假设真实值为1,预测值在为1和0的状况下得到的偏微分都是0,离目标(1)还很远;
也就是说即使离目标很远,算出来的结果也是0;
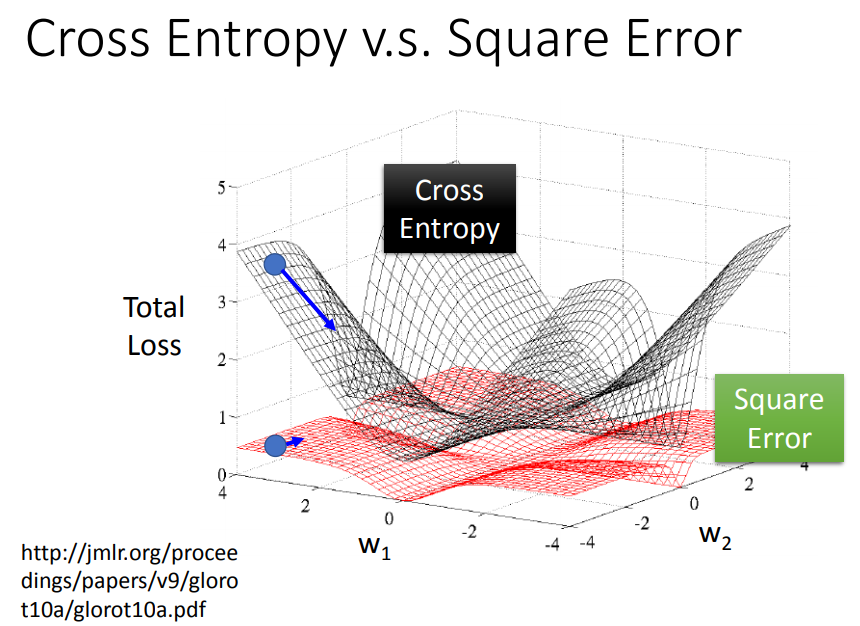
从图中可以看出,square error距离目标远的时候也太过平坦,梯度下降速度会很慢。
而且如果用square error也不能调整好学习率大小,因为微分值很小的时候有可能离目标值很远,也有可能离目标值很近。
6、Discriminative VS Generative

这两种原理相同的方法得不到相同的w和b,因为概率生成模型对概率分布有假设,比如假设是高斯分布、伯努利分布等等,而判别模型是直接找w和b。
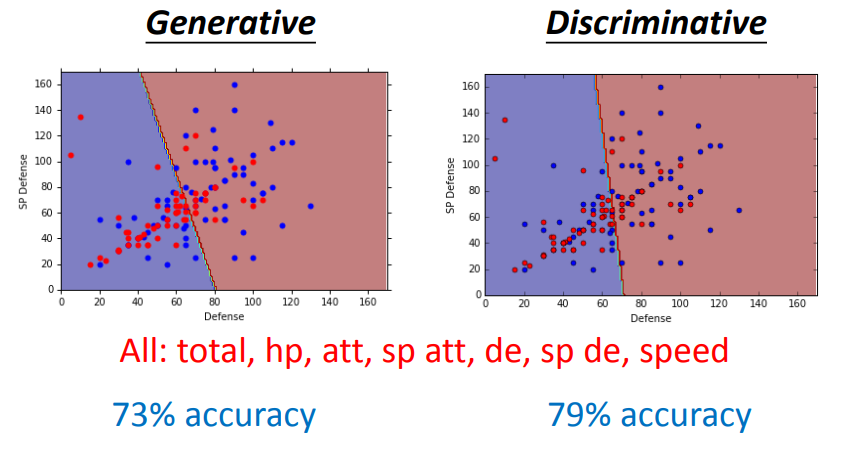
discriminative的performance往往更好一些,理由如下:
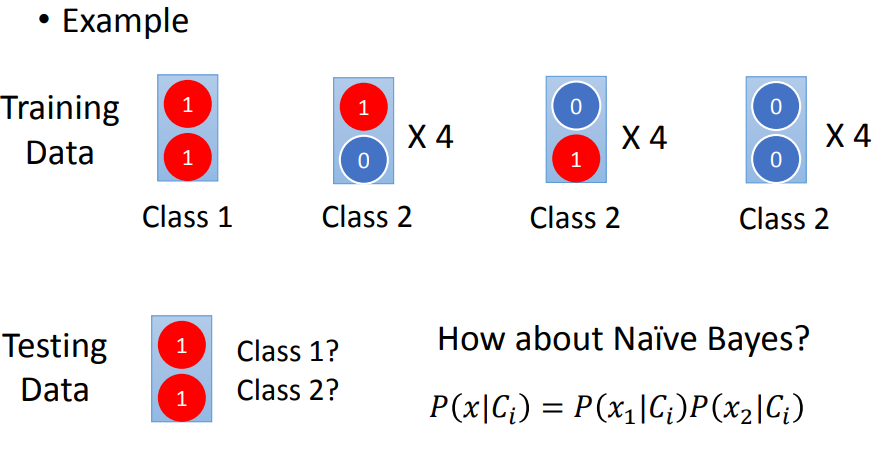

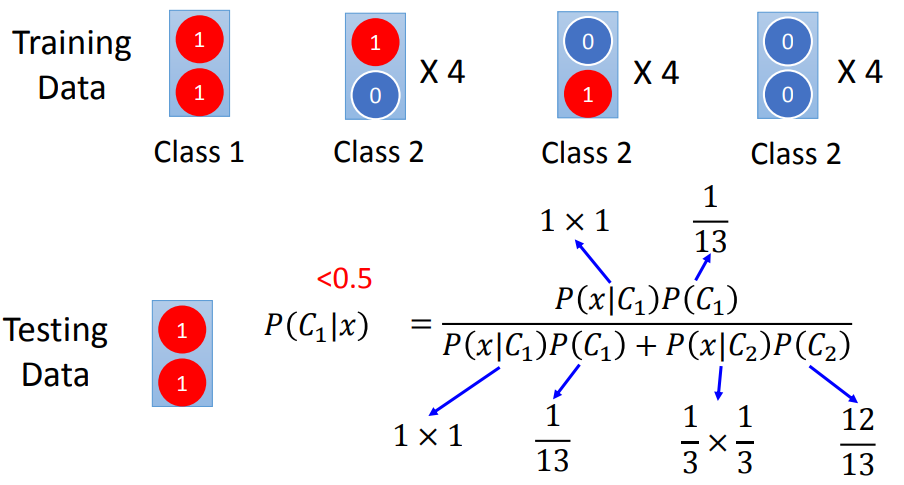
对朴素贝叶斯来说,使用这样的训练集会得到属于c2的结果而不是c1。因为朴素贝叶斯不考虑不同dimension之间的correlation。
朴素贝叶斯认为对c2采样的不够多,如果data足够多,x1=1,x2=1也是有几率被产生出来的。

discriminative model(判别模型)没有做任何概率模型的假设,所以受data影响比较大,data越多,error越小。
generative model受data影响比较小,会遵从它自己的假设(概率分布),因此在data比较多的时候,往往性能不如discriminative model。
由于是自己做的假设,对于label有问题的data,使用生成模型有可能把data中的noise忽视掉。
判别模型是假设一个后验概率,然后去找后验概率中的参数,但生成模型是将整个function拆成先验和似然,
因为先验和似然可以从不同的来源去估计(语音辨识问题中常见架构,先算先验概率,即某一句话被说出来的几率,爬文字就可以得到,不需要语音数据)
先验的部分只需要文字,class-dependent的部分才需要声音和文字的配合,这样可以更精确
7、Multi-class Classification
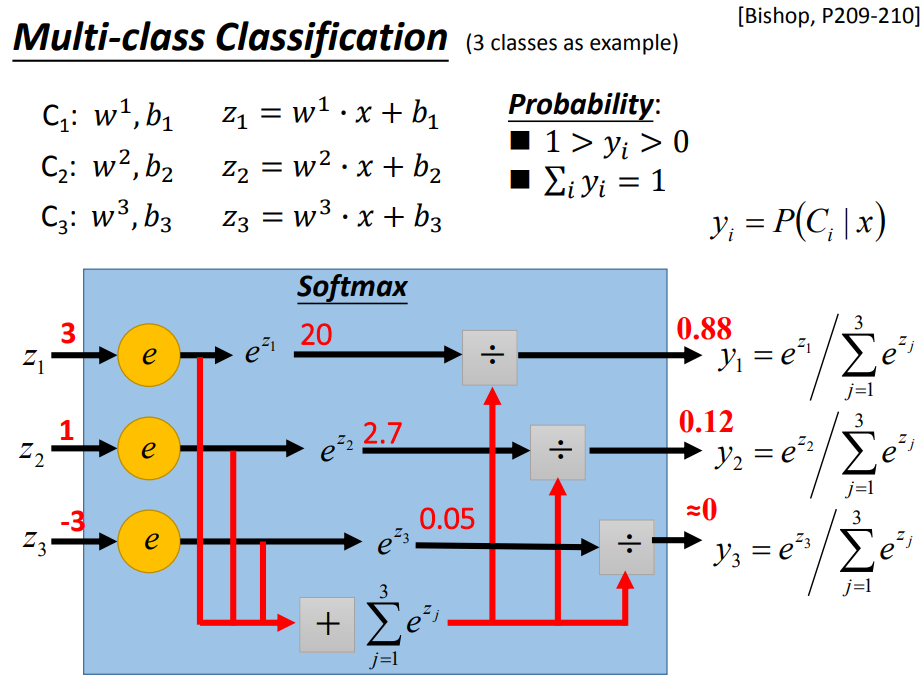

8、逻辑回归的局限
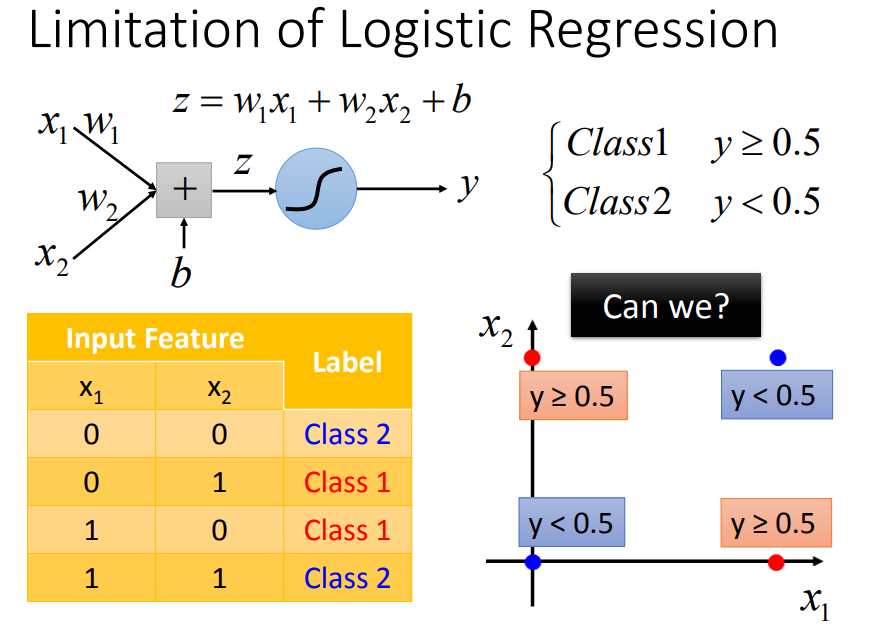
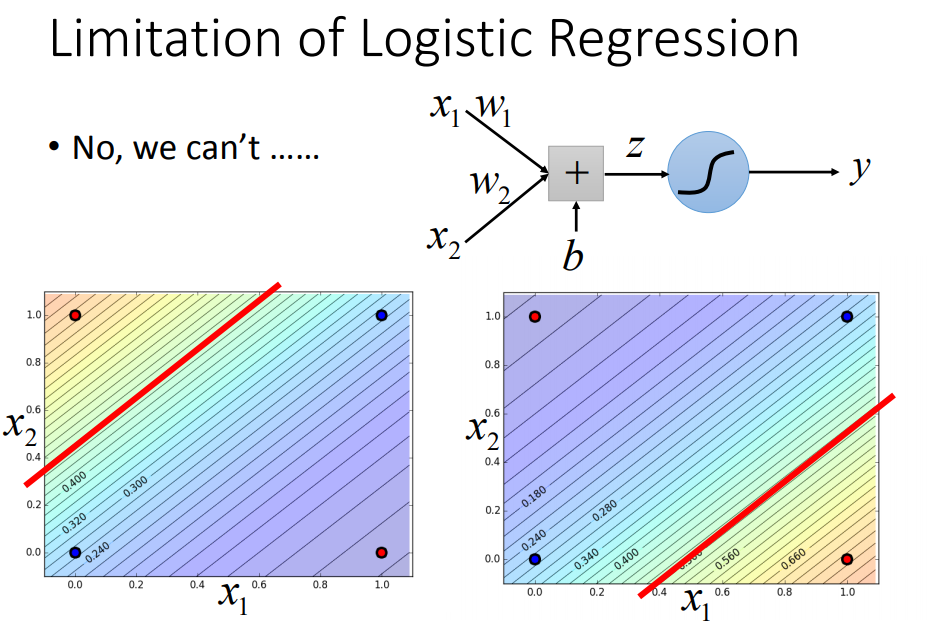
可以通过特征转化来解决:(但是不容易做特征转换)
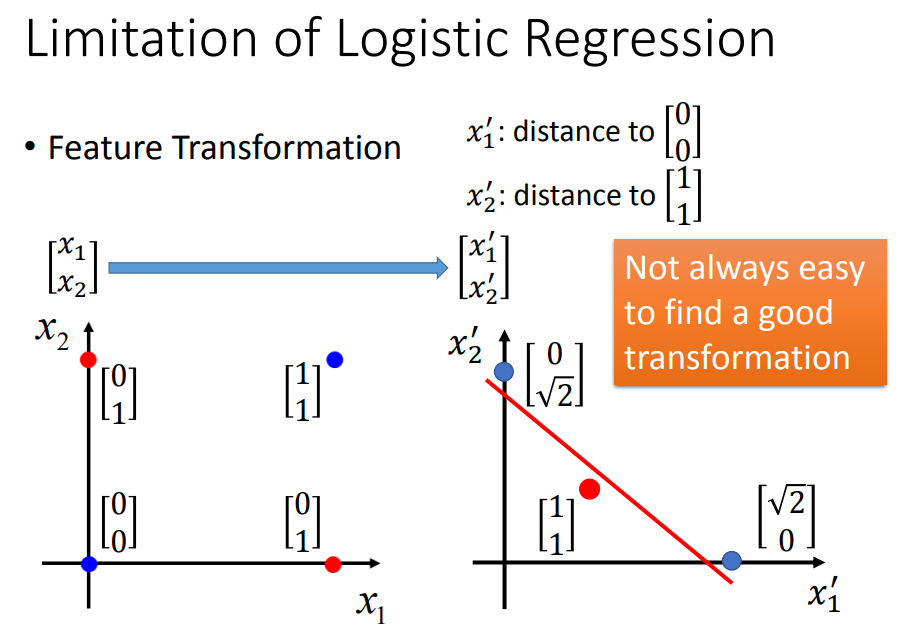
我们希望这个转换是由机器自己产生的,怎么让机器自己产生这样的transformation呢?可以把多个逻辑回归cascade到一起:
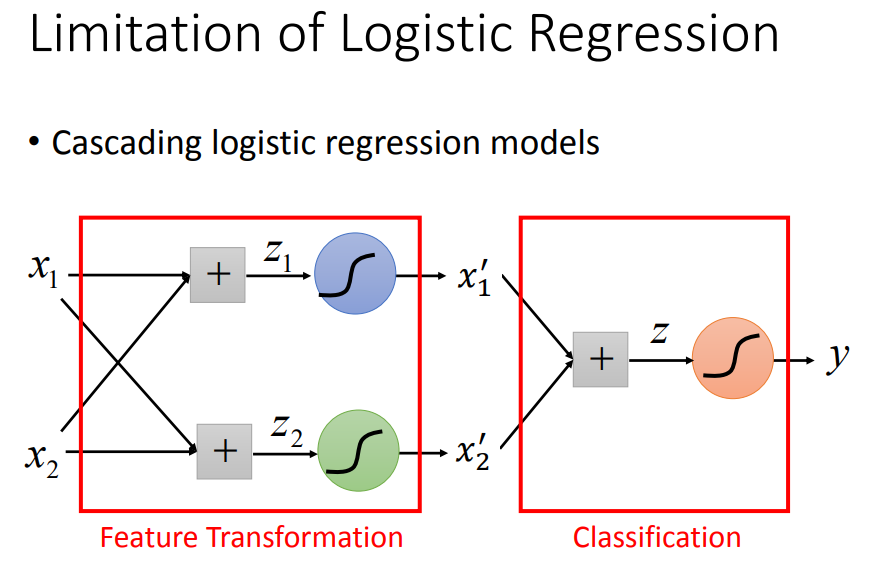
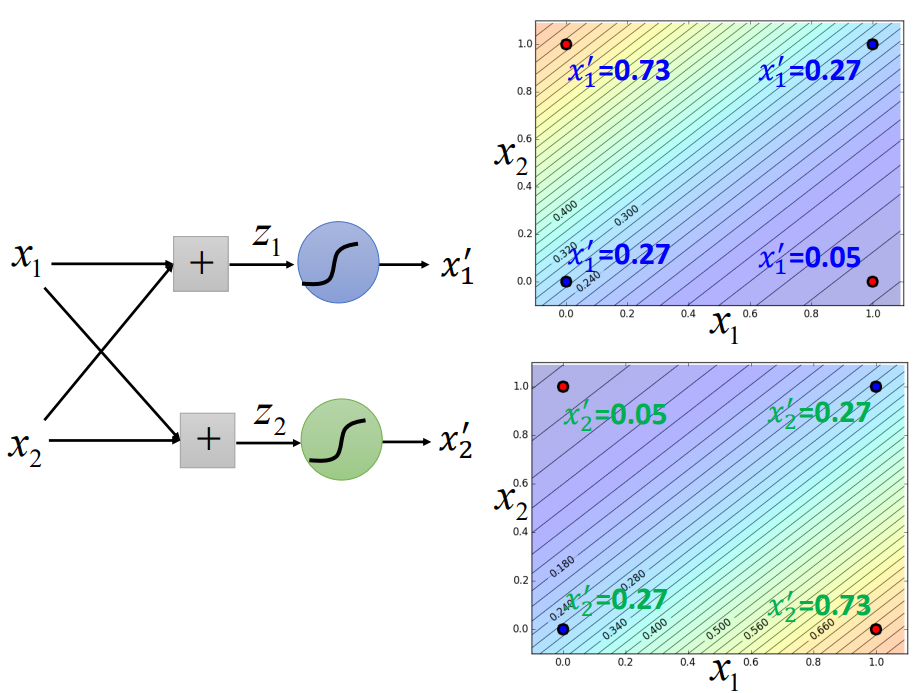
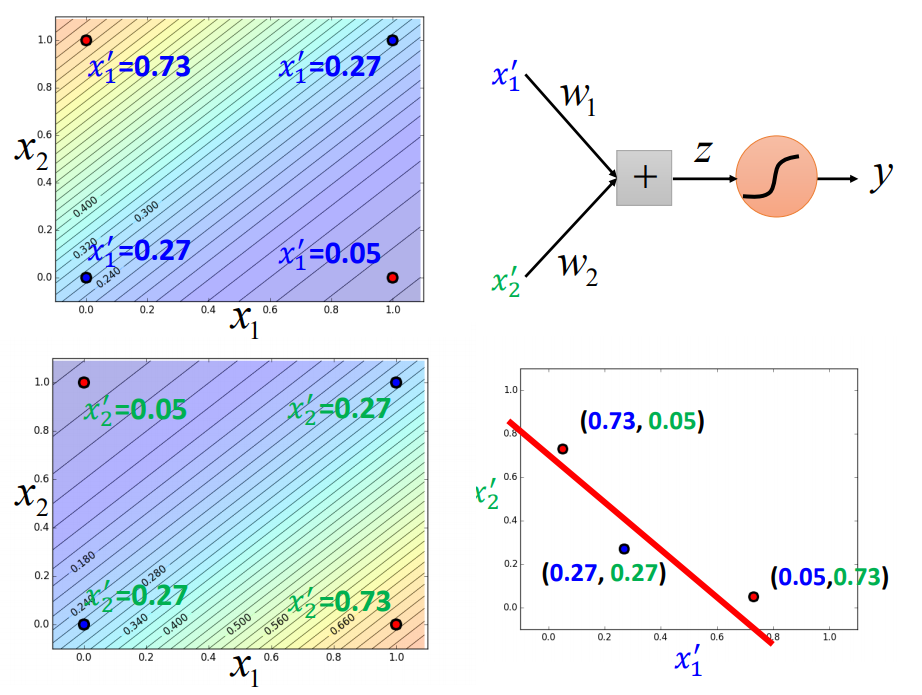
三个逻辑回归叠在一起,就能处理好这件事情
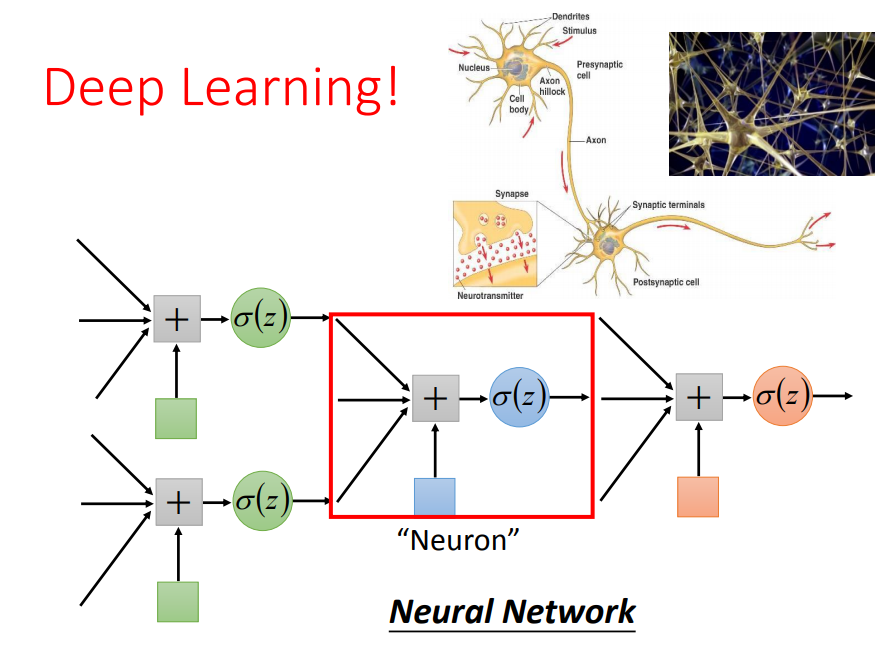
拼接起来的逻辑回归,把每一个叫做一个Neural,整体就可以看做一个神经网络。














 140
140











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









