利用BERT预训练模型的击中返回值
最新推荐文章于 2023-08-01 19:58:08 发布

 3212
3212











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











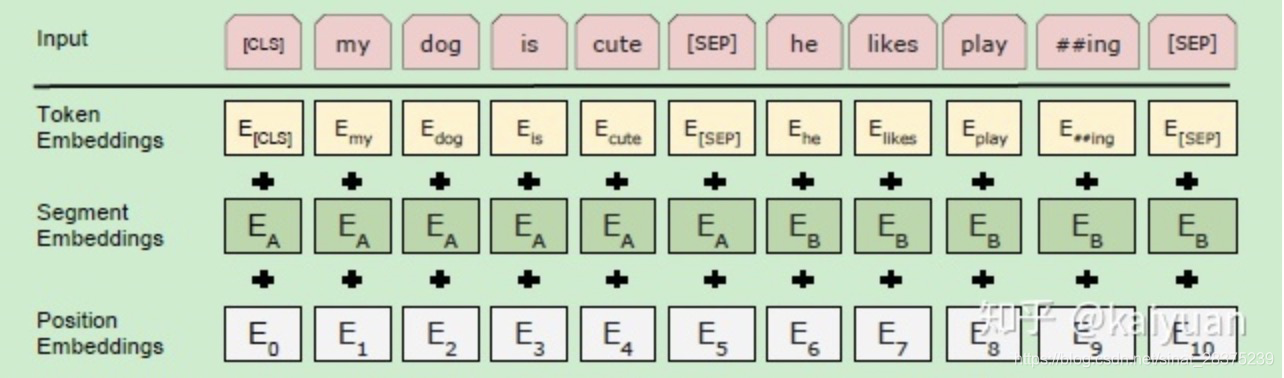 - get_sequence_output
- get_sequence_output


















