





在Coursera上学习的一门课程 :
Hadoop Platform and Application Framework
by University of California, San Diego
https://www.coursera.org/learn/hadoop/home/welcome
里面讲得很好,就是我这边的网下不下来一个cloudera的软件,我也正在学习中,对于HADOOP的了解很有帮助。接下来记一些笔记。
Lesson1:
Common:libraries and utilities
Yarn :enhancesde power of a Hadoop compute cluster ,a resource-management platform,scheduling.
Mapreduce:a programming model for large scale data processing.
HDFS:Hadoop Distributed File System(Hadoop分布式文件系统):
week2:
Yarn, Tez and Spark:都是framework
HDFS2:storage layer
YARN: essentially the basic execution engine in the next generation of Hadoop
Hbase ,other apps: work though on YARN
week3:
HDFS:
1.Introduction to HDFS:
HDFS Design Concept:
• Scalable distributed filesystem
• Distribute data on local disks on several nodes
• Low cost commodity hardware
HDFS Design Factors :
• Hundreds/Thousands of nodes => • Need to handle node/disk failures
• Portability across heterogeneous hardware/software
• Handle large data sets
• High throughput
Approach to meet HDFS design goals:
• Simplified coherency model – write once read many.
• Data Replication – helps handle hardware failures
• Move computation close to data
• Relax POSIX requirements – increase throughput
2.HDFS Architecture and Configuration:
Summary of HDFS Architecture
• Single NameNode - a master server that manages the file system namespace and regulates access to files by clients.
• Multiple DataNodes – typically one per node in the cluster.
Functions:
• Manage storage
• Serving read/write requests from clients
• Block creation, deletion, replication based on instructions from NameNode
Performance Envelope of HDFS :
• Able to determine number of blocks for a given file size
• Key HDFS and system components impacted by block size
• Impact of small files on HDFS and system
Default block size is 64MB
10GB = 10 X 1024. blocks = 10 X 1024/64 =160 bolcks.
3.Read / Write process in HDFS:
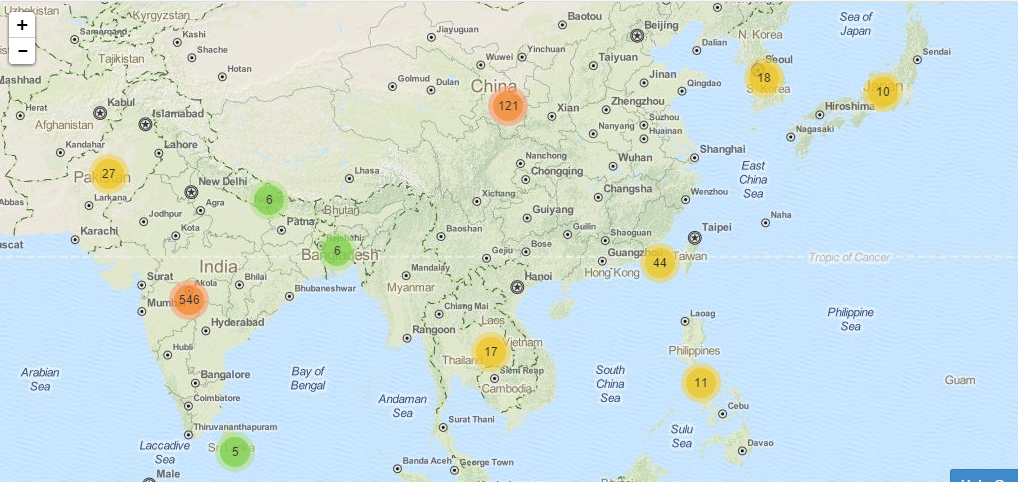
另外附上课里面一个学生区域的统计 :可以发现印度学生真的真的很多,北美的学习者也很多,我们的学习还要努力啊!















 199
199

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









