







并查集结构可以用于:
(1)检查两个元素是否属于同一个集合:
比如对于图1这个例子来说,如果我们想要检查节点D和节点E是否属于同一个集合,可以这样操作:
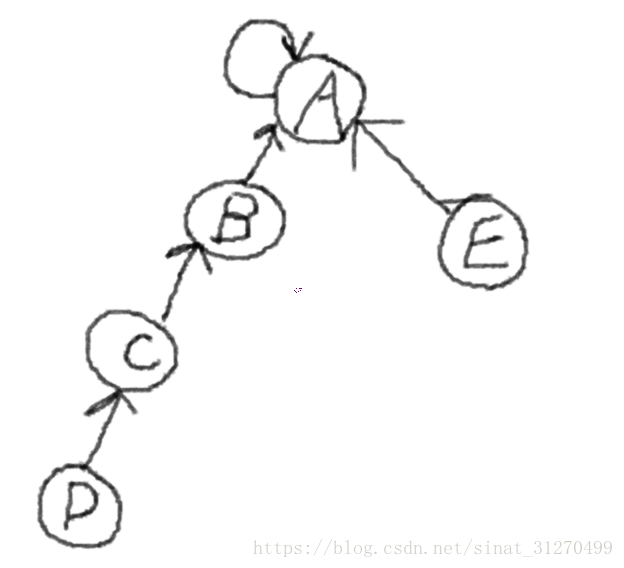
D节点往上找其父节点,一直往上找,直到某个节点的父节点是其本身,此时停止(找到了节点A);
E节点也按照相同的步骤往上找其父节点,找到节点A;
如果这两个节点往上找到的最终父节点相同,那么可以说它们是属于同一个集合的。
(2)可以把两个元素各自属于的集合合并在一起:
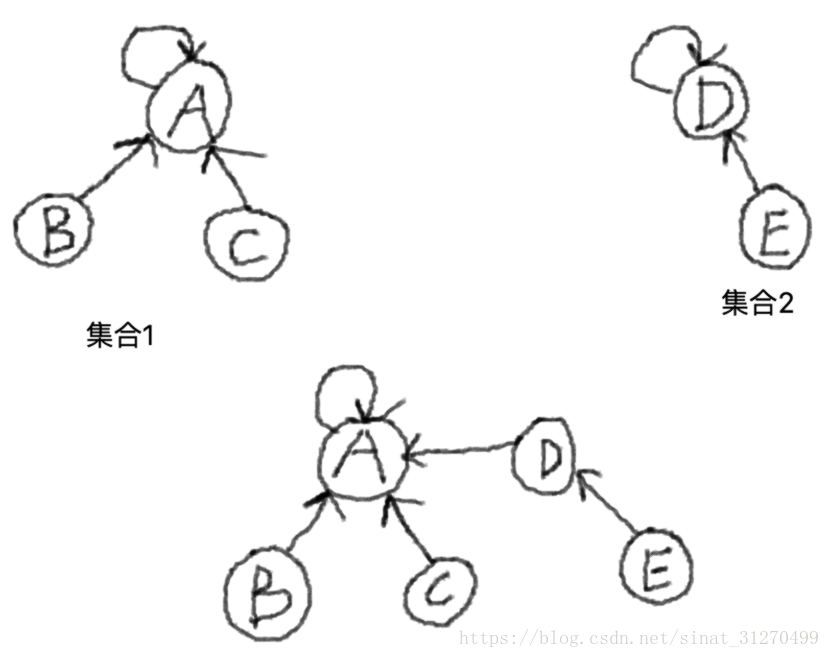
比如对于图2这个例子,怎样将两个集合合并在一起呢?
首先我们算一下集合1中节点的个数,是3。然后我们再计算集合2中的节点个数,是2。哪一个集合的元素个数少,就把那个集合挂接在集合元素个数多的集合上面。
现在我们可以列出部分代码来增加大家的理解:
首先我们先定义一个节点的类:
public static class Node {
public int value;
public Node(int data) {
this.value = data;
}
}然后开始定义并查集结构:
public static class UnionFindSet {
// 第一个Node表示自己本身,第二个Node表示node的父节点
public HashMap<Node, Node> fatherMap;
// 一个集合的元素个数
public HashMap<Node, Integer> sizeMap;
// 构造函数
public UnionFindSet(List<Node> nodes) {
makeSet(nodes);
}
// 这里给出的节点是存储在List里面的
public void makeSet(List<Node> nodes) {
// 初始化两个哈希Map
fatherMap = new HashMap<Node, Node>();
sizeMap = new HashMap<Node, Integer>();
// 首先将每一个节点取出,各自成为独立的集合,把自己的父节点设为自己
for (Node node : nodes) {
fatherMap.put(node, node);
sizeMap.put(node, 1);
}
}
// 这个函数用于寻找某个节点的最终节点(递归版本)
public Node findHeadRecur(Node node) {
if (node == null) {
return null;
}
Node father = fatherMap.get(node);
if (father != node) {
father = findHeadRecur(node);
}
fatherMap.put(node, father);
return father;
}
// 非递归版本findHead函数,这个很清晰,就是模拟了递归过程入栈和出栈的过程
public Node findHeadNonRecur(Node node) {
if (node == null) {
return null;
}
Stack<Node> stack = new Stack<Node>();
Node cur = node;
Node father = null;
father = fatherMap.get(cur);
while (cur != father) {
stack.push(cur);
cur = father;
father = fatherMap.get(cur);
}
fatherMap.put(cur, father);
while (!stack.isEmpty()) {
fatherMap.put(stack.pop(), father);
}
return father;
}
// 看两个元素是否属于同一个集合,只需要看它们的父节点是否为同一个节点
public boolean isSameSet(Node a, Node b) {
return findHeadRecur(a) == findHeadRecur(b);
}
// 合并两个集合,看集合的元素个数
public void union(Node a, Node b) {
if (a == null || b == null) {
return;
}
Node aFather = findHeadRecur(a);
Node bFather = findHeadRecur(b);
if (aFather != bFather) {
int sizeHeadA = sizeMap.get(aFather);
int sizeHeadB = sizeMap.get(bFather);
if (sizeHeadA < sizeHeadB) {
fatherMap.put(aFather, bFather);
sizeMap.put(bFather, sizeHeadB + sizeHeadA);
} else {
fatherMap.put(bFather, aFather);
sizeMap.put(aFather, sizeHeadB + sizeHeadA);
}
}
}
}并查集可以延伸至岛问题的求解
什么是岛问题?下面先介绍一下岛问题的基本解法,之后会延伸出使用并查集来解决分块矩阵的岛问题
比如,一个矩阵只有0和1两种值,每个位置都可以和自己的上下左右四个位置相连。如果有一片1连在一起,则这个部分称为一个岛。问,给定一个矩阵,求这个矩阵中有多少个岛?
比如给定的矩阵是这样的:
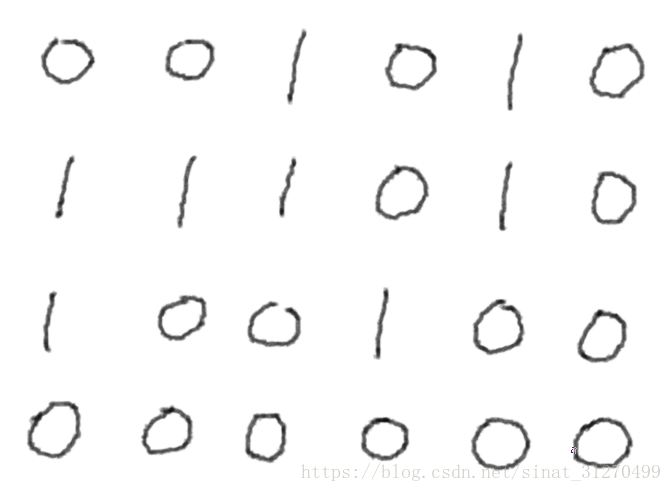
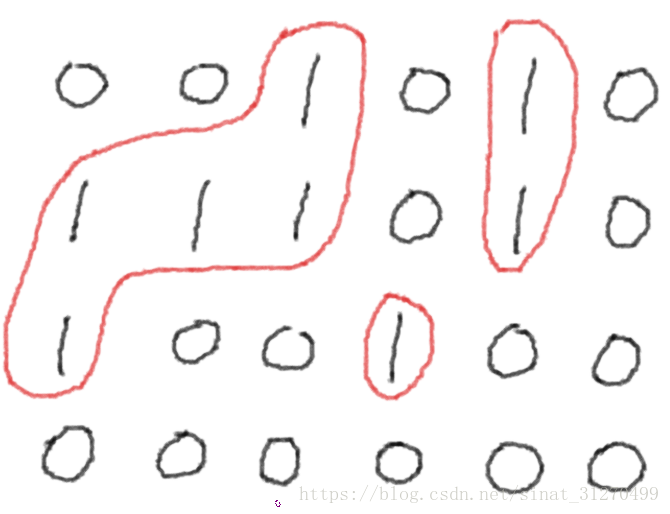
可以看到,这个矩阵的岛的数量是3个。
可以使用一个感染函数递归地求解,感染函数每次遇到一个1,都将其变成2,然后在看这个1的上下左右有没有1,有的话也标记为2,这样就不会重复地计算已经统计过的1了。
列出代码:
public static int containsIsland(int[][] matrix) {
int m = matrix.length;
int n = matrix[0].length;
int res = 0;
for (int i = 0; i < m; i++) {
for (int j = 0; j < n; j++) {
res++;
infect(matrix, m, n, i, j);
}
}
return res;
}
// 感染函数
public static void infect(int[][] matrix, int m, int n, int i, int j) {
if (i < 0 || i >= m || j < 0 || j >= n || matrix[i][j] != 1) {
return;
}
matrix[i][j] = 2;
// 递归
infect(matrix, m, n, i + 1, j);
infect(matrix, m, n, i, j + 1);
infect(matrix, m, n, i - 1, j);
infect(matrix, m, n, i, j - 1);
}这个解法适用于矩阵不是很大的情况。
如果矩阵很大,我们可以将矩阵分块,先分别计算每一个分块儿矩阵中岛的数量,以及需要留意它们的边界信息。
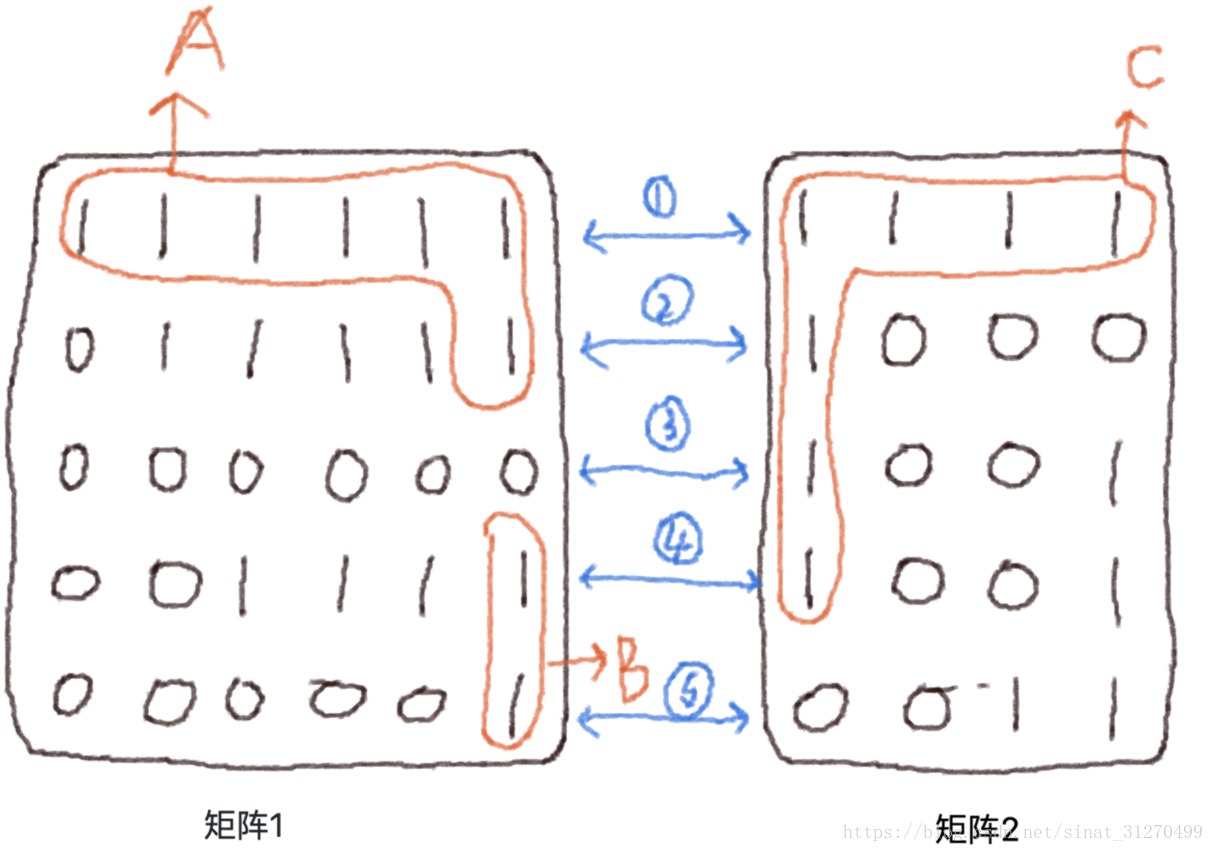
对于矩阵1,它有2两个岛;对于矩阵2,它也有两个岛。所以岛的数量暂时先为4个。
然后,比较两个矩阵相邻边界的信息,如图5中蓝色部分。
对于过程1:相邻部分都为1,且A与C之前并没有合并过(并查集),可以合并(使用并查集中的union方法),此时岛的数量 = 4 - 1 = 3。
对于过程2:相邻部分都为1,但是A与C之前合并过(并查集中的isSameSet方法),此时岛的数量不变。
对于过程3:相邻部分有0,跳过。
对于过程4,相邻部分都为1,且B与C之前并没有合并过(并查集),可以合并(使用并查集中的union方法),此时岛的数量 = 3 - 1 = 2。
过程5与过程3相同。
所以最终岛的总数为2。
以上是我对算法学习的一个归纳与总结,水平有限望理解,如有错误请指出。
参考:
左程云《程序员面试代码指南》
左程云《算法班课程》














 273
273











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









