







map 阶段对我们的数据进行分开计算,第二是 reduce 阶段,对 map 阶段计算产生的结果再进行汇总。
还写了一个非常经典的,类似于Java 中 HelloWorld 一样的 WordCount 代码。今天我们就根据这个代码来阐述整个 MapReduce 的运行过程。
先苦口婆心的告诉你,这个知识点是非常非常非常之重要,之前面的 5 家公司,有 3 家公司都问了这个过程,另外两家问了 Yarn 的运行机制,这是后面会去讲的内容,你必须得懂大体的流程是怎么样子,如果能去研究搞清楚每个细节,那当然最好的。
从数据进如到处理程序到处理完成后输出到存储中,整个过程我们大体分为如下 5 个阶段:
- Input Split 或 Read 数据阶段
Input Split,是从数据分片出发,把数据输入到处理程序中。Read 则是从处理程序出发反向来看,把数据从文件中读取到处理程序中来。这个阶段表达的是我们数据从哪里来。这是整个过程的开始。 - Map阶段
当数据输入进来以后,我们进行的是 map 阶段的处理。例如对一行的单词进行分割,然后每个单词进行计数为 1 进行输出。 - Shuffle 阶段
Shuffle 阶段是整个 MapReduce 的核心,介于 Map 阶段跟 Reduce 阶段之间。在 Spark 中也有这个概念,可以说你理解了这个概念,到时候再学习其他的大数据计算框架原理的时候,会给你带来非常大的帮助,因为他们大多理念是相同的,下面会重点讲解这个过程。 - Reduce 阶段
数据经过 Map 阶段处理,数据再经过 Shuffle 阶段,最后到 Reduce ,相同的 key 值的数据会到同一个 Reduce 任务中进行最后的汇总。 - Output 阶段
这个阶段的事情就是将 Reduce 阶段计算好的结果,存储到某个地方去,这是整个过程的结束。
整个执行流程图
一图胜千言:
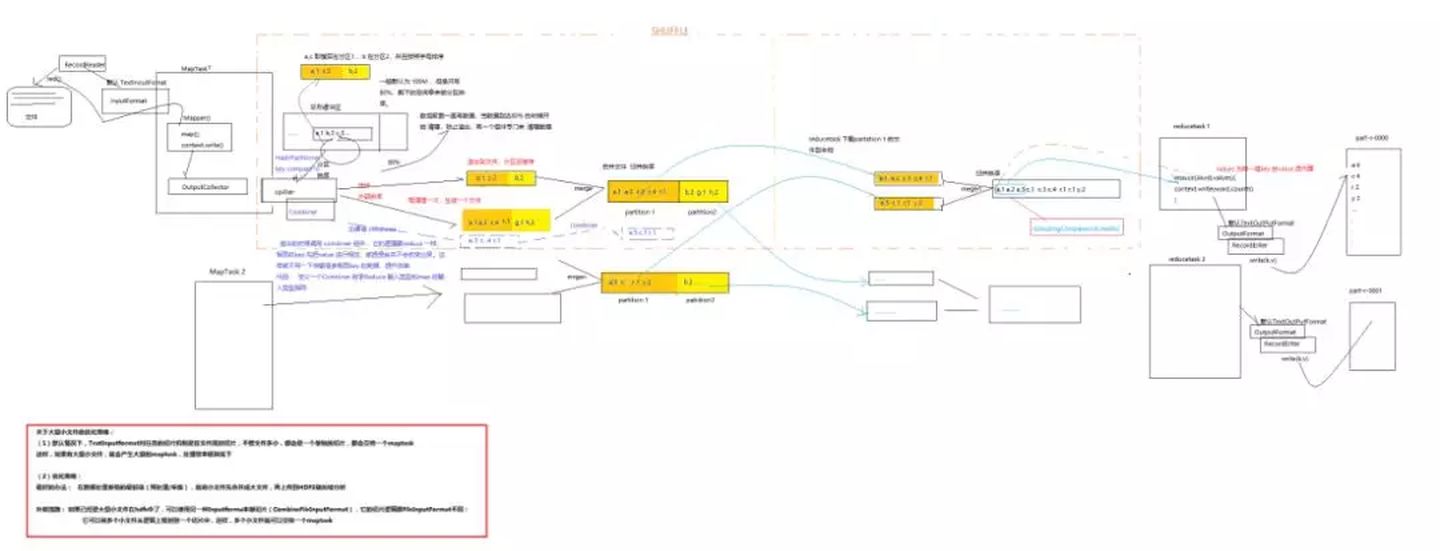
如果看不清晰,我上传了一份完整的在 gayHub 上面,地址:
当然了,不太了解或者刚接触可能一开始看比较懵逼,我刚开始也是。下面我们就一块一块的来拆分讲解,最后差不多就明白了。
Input Split 数据阶段
Input Split 顾明思议,输入分片 ,为什么我们会叫 输入分片呢?因为数据在进行 Map 计算之前,MapReduce 会根据输入文件进行切分,因为我们需要分布式的进行计算嘛,那么我得计算出来我的数据要切成多少片,然后才好去对每片数据分配任务去处理。
每个输入分片会对应一个 Map 任务,输入分片存储的并非数据本身,而是一个分片长度和一个记录数据的位置数据,它往往是和 HDFS 的 block(块) 进行关联的。
假如我们设定每个 HDFS 的块大小是 128M,如果我们现在有3个文件,大小分别是 10M,129M,200M,那么MapReduce 对把 10M 的文件分为一个分片,129M 的数据文件分为2个分片,200M 的文件也是分为两个分片。那么此时我们就有 5 个分片,就需要5个 Map 任务去处理,而且数据还是不均匀的。
如果有非常多的小文件,那么就会产生大量的 Map 任务,处理效率是非常低下的。
这个阶段使用的是 InputFormat 组件,它是一个接口 ,默认使用的是 TextInputFormat 去处理,他会调用 readRecord() 去读取数据。
这也是MapReduce 计算优化的一个非常重要的一个点,**面试被考过**。如何去优化这个小文件的问题呢?
- 最好的办法:在数据处理系统的最前端(预处理、采集),就将小文件先进行合并了,再传到 HDFS 中去。
- 补救措施:如果已经存在大量的小文件在HDFS中了,可以使用另一种 InputFormat 组件CombineFileInputFormat 去解决,它的切片方式跟 TextInputFormat 不同,它会将多个小文件从逻辑上规划到一个切片中,这样,多个小文件就可以交给一个 Map 任务去处理了。
Map阶段
将 Map 阶段的输出作为 Reduce 阶段的输入的过程就是 Shuffle 。 这也是整个 MapReduce 中最重要的一个环节。
一般MapReduce 处理的都是海量数据,Map 输出的数据不可能把所有的数据都放在内存中,当我们在map 函数中调用 context.write() 方法的时候,就会调用 OutputCollector 组件把数据写入到处于内存中的一个叫环形缓冲区的东西。
环形缓冲区默认大小是 100M ,但是只写80%,同时map还会为输出操作启动一个守护线程,当到数据达到80%的时候,守护线程开始清理数据,把数据写到磁盘上,这个过程叫 spill 。
数据在写入环形缓冲区的时候,数据会默认根据key 进行排序,每个分区的数据是有顺序的,默认是 HashPartitioner。当然了,我们也可以去自定义这个分区器。
每次执行清理都产生一个文件,当 map 执行完成以后,还会有一个合并文件文件的过程,其实他这里跟 Map 阶段的输入分片(Input split)比较相似,一个 Partitioner 对应一个 Reduce 作业,如果只有一个 reduce 操作,那么 Partitioner 就只有一个,如果有多个 reduce 操作,那么 Partitioner 就有多个。Partitioner 的数量是根据 key 的值和 Reduce 的数量来决定的。可以通过 job.setNumReduceTasks() 来设置。
这里还有一个可选的组件 Combiner ,溢出数据的时候如果调用 Combiner 组件,它的逻辑跟 reduce 一样,相同的key 先把 value 进行相加,前提是合并并不会改变业务,这样就不糊一下传输很多相同的key 的数据,从而提升效率。
举个例子,在溢出数据的时候,默认不使用 Combiner,数据是长这样子: <a,1>,<a,2>,<c,4>。 当使用 Combiner 组件时,数据则是: <a,3>,<c,4> 。把 a 的数据进行了合并。
Reduce 阶段
在执行 Reduce 之前,Reduce 任务会去把自己负责分区的数据拉取到本地,还会进行一次归并排序并进行合并。
Reduce 阶段中的 reduce 方法,也是我们自己实现的逻辑,跟Map 阶段的 map 方法一样,只是在执行 reduce 函数的时候,values 为 同一组 key 的value 迭代器。在 wordCount 的例子中,我们迭代这些数据进行叠加。最后调用 context.write 函数,把单词和总数进行输出。
Output 阶段
在 reduce 函数中调用 context.write 函数时,会调用 OutPutFomart 组件,默认实现是 TextOutPutFormat ,把数据输出到目标存储中,一般是 HDFS。
扩展
上面我们只是讲解了大体的流程,这里给大家抛几个问题?也是面试中经常被问到的。
1. 文件切分是怎么切的?一个文件到底会切成几分?算法是怎么样的?
2. Map 任务的个数是怎么确定的?
上面的问题,给大家贴两个链接:
MapReduce Input Split(输入分/切片)详解:
https://blog.csdn.net/dr_guo/article/details/51150278blog.csdn.net
源码解析 MapReduce作业切片(Split)过程:
https://blog.csdn.net/u010010428/article/details/51469994















 4359
4359











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










{kind=link}