









1.3 Data Storage and Segment 4
一、Druid介绍
1.1官方介绍
Druid is a system built to allow fast ("real-time") access to large sets of seldom-changing data. It was designed with the intent of being a service and maintaining 100% uptime in the face of code deployments, machine failures and other eventualities of a production system. It can be useful for back-office use cases as well, but design decisions were made explicitly targeting an always-up service.
(1)Druid是一个允许对大批量的静态数据进行快速实时查询的系统。
(2)高可用,水平扩展、分布式数据
(3)最主要的目的是对于实时数据的查询分析
1.2架构:
下图显示了查询的过程和数据如何流经此体系结构,以及涉及哪些节点。
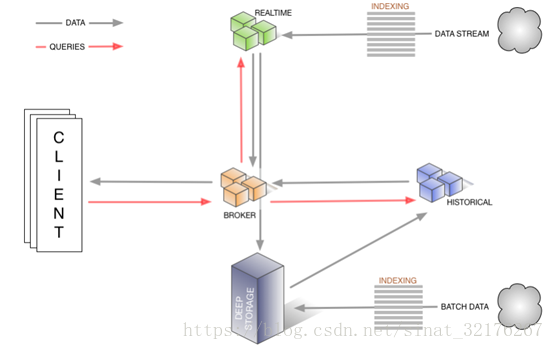
图1.1 Druid架构原理图
数据摄入:数据摄取有两种,pull和push
- 静态数据通过实时节点摄入(pull),也可以通过索引服务启动一个任务进行摄取(push)。
- 流数据也是如此。最后都会经过历史节点,汇聚到查询节点。
查询过程:
- 查询请求先进入查询节点,查询节点将已知存在的segment进行匹配查询。
- 查询节点选择一组可以提供所需要的Segment的历史节点和实时节点,将查询请求分发到这些机器上。
- 历史节点和实时节点都会进行查询处理,然后返回结果
- 查询节点将历史节点和实时节点返回的结果进行合并,返回给查询请求方。
· 实时节点(Realtime Mode):即时摄入实时数据,及生成Segment数据文件;
· 历史节点(Historical Mode):负责处理历史数据存储和查询历史数据(非实时),历史节点从“deep storage”下载segments,将结果数据返回给查询节点,历史节点加载完segment通知Zookeeper,历史节点使用Zookeeper监控需要加载或者删除哪些新的;
· 查询节点(Broker Mode):对外提供数据查询服务,并同时从实时节点与历史节点查询数据,合并后返回给调用方;
· 协调节点(Coordinator Mode):负责劣势节点的数据负载均衡,以及通过规则(Rule)管理数据的生命周期;
· 索引服务(Indexing Service): 索引服务节点由多个worker组成的集群,负责为加载批量的和实时的数据创建索引,并且允许对已经存在的数据进行修改。
所有的节点都是高可用的,并且除了这些节点外,还有其他的三个额外的依赖。Zk,metadata,deep Storage
1.3 Data Storage and Segment
概述:
Getting data into the Druid system requires an indexing process, as shown in the diagrams above. This gives the system a chance to analyze the data, add indexing structures, compress and adjust the layout in an attempt to optimize query speed. A quick list of what happens to the data follows.
将数据导入Druid系统需要一个索引过程,如上图所示。这使系统有机会分析数据,添加索引结构,压缩和调整布局以尝试优化查询速度。下面是数据发生的快速列表。
- 转换为柱状格式
- 使用位图索引编制索引
- 使用各种算法压缩
索引过程的输出就是Segment,他是Druid中存储数据的基本结构,细分起来包含数据集中的各种维度列(Dimension)和指标(Metric),以列方向存储,以及这些列的索引。
Segment存储LOB存储/文件系统中(有关潜在选项的信息,请参阅Deep Storage)。
数据结构:
DataSource:
Druid数据包括三个不同的组件,时间戳列(Timestamp column),维度列(Dimension columns),计算列(Metric columns)
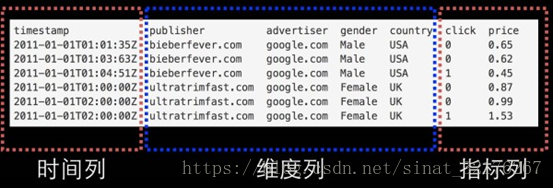
- 时间列(TimeStamp):表明每行数据的时间值,默认使用UTC时间且精确到毫秒;
- 维度列(Dimension):用于标识数据行的各个类别信息;
- 指标列(Metric):用于聚合和计算的列。
按时间范围查询数据时,仅需要访问对应时间段内的这些 Segment数据块,而不需要进行全表数据范围查询,这使效率得到了极大的提高。
Segment
DataSource是一个逻辑概念,Segment是数据的实际物理存储格式。
Druid正是通过 Segment实现了对数据的横纵向切割( Slice and Dice)操作。从数据按时间分布的角度来看,通过参数 segmentGranularity的设置, Druid将不同时间范围内的数据存储在不同的 Segment数据块中,这便是所谓的数据横向切割。这种设计为 Druid带来一个显而易见的优点:按时间范围查询数据时,仅需要访问对应时间段内的这些 Segment数据块,而不需要进行全表数据范围查询,这使效率得到了极大的提高。
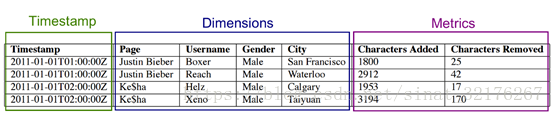
Segment存储
同时,在 Segment中也面向列进行数据压缩存储,这便是所谓的数据纵向切割。而且在 Segment中使用了 Bitmap等技术对数据的访问进行了优化
1.4数据
Druid是一个专门针对事件数据的OLAP查询而设计的开源数据存储系统
我们从一个在线广告的示例数据集开始讨论:
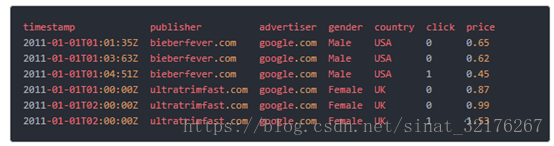
熟悉OLAP的同学应该对这些概念肯定不会陌生,Druid也把数据集分为三个部分:
- Timestamp column(时间字段):将时间字段单独处理,是因为Druid的所有查询都是围绕时间轴进行的。
- Dimension columns(维度字段): 维度字段是数据的属性,一般被用来做数据的过滤。在示例数据集中有四个维度:publisher、advertiser、gender和 country。它们各自代表了我们用来分割数据的轴。
- Metric columns(度量字段):度量字段是用来做数据的聚合计算的。在示例中, click和price是俩个度量。度量是可以衡量的数据,一般可以做count、sum等操作。在OLAP术语中也叫measures。
Roll-up
在海量数据处理中,一般对于单条的细分数据并不感兴趣,因为存在数万亿计这样的事件。然而这类数据的统计汇总是很有用的,Druid通过roll-up过程的处理,使数据在摄取加载阶段就做了汇总处理。Roll-up(汇总)是在维度过滤之前就做的第一级聚合操作。相等于如下伪代码:
GROUP BY timestamp, publisher, advertiser, gender, country :: impressions = COUNT(1), clicks = SUM(click), revenue = SUM(price)数据压缩聚合后就是
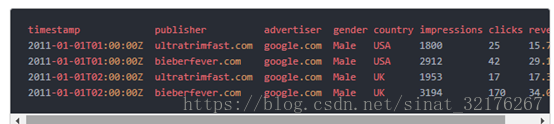

可以看到,通过roll-up汇总数据后可以大大减少需要存储的数据量(高达100倍)。Druid在接收数据的时候汇总数据,以最小化需要存储的原始数据量。但是这种存储减少是有代价的,当我们roll up数据后,就没办法再查询详细数据了。换句话说roll-up后的粒度就是你能够探索数据的最小粒度,事件被分配到这个粒度。因此,Druid摄取规范将此粒度定义为数据的queryGranularity, 支持的最低queryGranularity是毫秒。
索引数据
Druid能够取得这样的查询速度,主要取决于数据的存储方式。借鉴google等搜索引擎的思路,Druid生成不可变的数据快照,存储在针对分析查询高度优化的数据结构中。
Druid是列式存储也就意味着每一个列都是单独存储的。Druid查询时只会使用到与查询相关的列,而且Druid很好的支持了在查询时只扫描其需要的。不同的列可以采用不同的压缩方法,也能够建立与它们相关的不同索引。
Druid在每一个分片级别(segment)建立索引。
加载数据
Druid有实时和批量两种方式进行数据摄取。Druid中实时数据摄取方式是尽力而为。Druid暂时实时摄取暂时无法支持正好一次(Exactly once),当然在后续版本计划中会尽量去支持。通过批量创建能够准确映射到摄取数据的段,批量摄取提供了正好一次的保证。使用Druid的通用方式是用实时管道获取实时数据,用批量管道处理副本数据。
查询数据
Druid的本地查询语言是JSON通过HTTP,虽然社区在众多的语言中提供了查询库,包括SQL查询贡献库。
Druid设计用于单表操作,目前不支持join操作。因为加载到Druid中的数据需要规范化,许多产品准备在数据ETL(Extract-Transform-Load)阶段进行join。
1.4查询过程
查询首先进入Broker,Broker将查询与已知存在的数据段匹配。然后,它将选择一组为这些段提供服务的计算机,并为每个服务器重写查询以指定目标段。历史/实时进程将接受查询,处理它们并返回结果。然后Broker获取结果并将它们合并在一起以获得它返回的最终答案。通过这种方式,代理可以在查看单行数据之前修剪与查询不匹配的所有数据。
对于比Broker可以修剪的更精细级别的过滤器,每个段内的索引结构允许历史节点在查看任何数据行之前确定哪些(如果有)行与过滤器集匹配。它可以在位图索引上完成滤镜的所有布尔代数,并且实际上从不直接查看一行数据
一旦它知道与当前查询匹配的行,它就可以直接访问它关心的列,而无需加载它将要丢弃的数据。














 2250
2250











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









