







笔者:王草
日期:2018年7月29日
1 背景知识
在讲述论文之前,笔者为大家简单地讲解一下论文要解决的核心问题。对跨语言词嵌入有了解的朋友可以直接跳过这一节。
2013年Mikolov等提出了分布式的词向量表征word2vec,即将一个词用一个低维向量来表示,词与词之间的相似性可以通过向量之间的相关性表示。随后word2vec在众多自然语言处理(NLP)的任务中大放光彩,备受青睐。
学者们发现不同语言中训练出来的词向量虽然是独立的,但是其分布形态却非常相似。如下图,左边红色的是英文,右边蓝色的是西班牙文,两种语言中意义一样的词在坐标上的分布非常相近
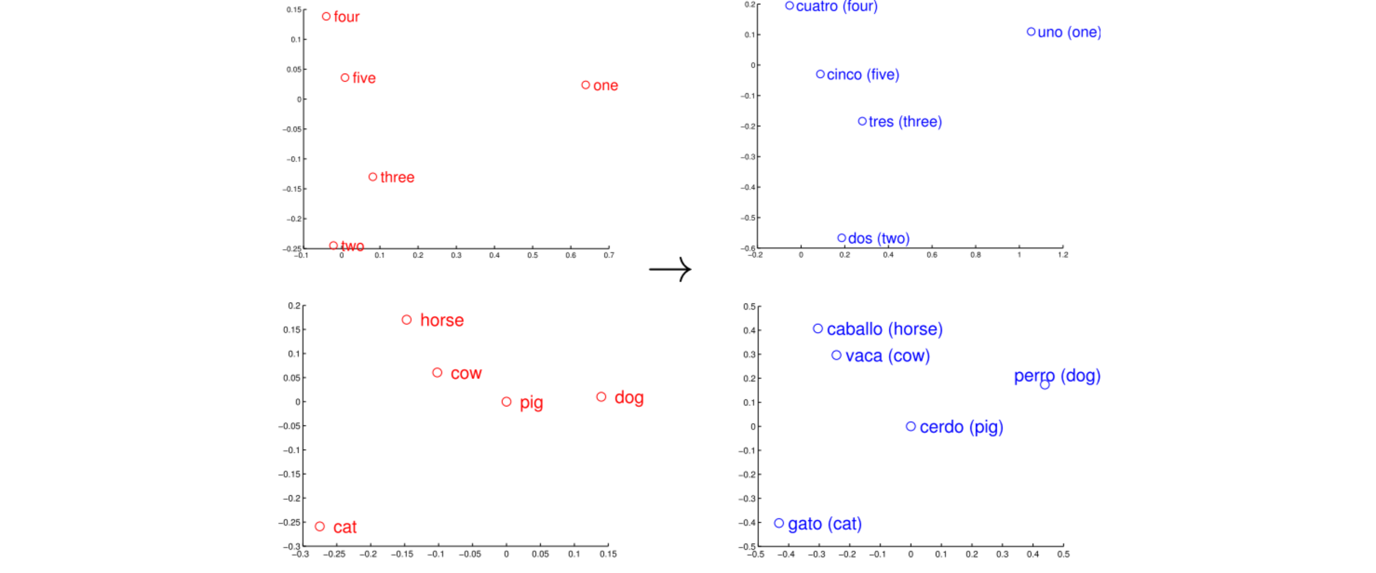
如此一来,可否通过某种线性或非线性的转换,将不同语言的词向量映射到同一个共享的空间中,打通语言与语言之间的隔阂,实现美美与共,天下大同。在研究与工作中,往往会发现英文的数据集都比较丰富,而其他语言比如中文的数据总是少之又少,而实现语言表征之大同:
1)可以将在训练数据丰富的语言上训练得到的模型,应用到数据集缺乏的语言上。
2)所有语言只需要训练一个模型,就能在各个国家各个语言的应用场景中使用。
我们称这种语言表征上的统一为cross-lingual embedding,即跨语言词嵌入。
那么问题来了:
1)如何去构建这样一种词嵌入?
2)如何去评估嵌入到共享空间后的词向量的效果?
针对这两点目前有很多研究,笔者也专门针对该领域的研究与近期的文献综述写了一篇系统的介绍文章(链接:),欢迎阅读与指正。
2 论文摘要
论文主要做了两个工作:
1)将前人的跨语言词嵌入研究方法做了归类与整合,提出一个线性转化的multi-step框架
2)对multi-step框架中的每一个step进行实验与比较,分析它们的有效性与贡献度
3)针对各个step的评估,提出了一个新的方案,实现了state of the art效果
我们按照作者的思路,以下章节依次介绍multi-step框架的构成,每一个step进行实验与比较,新的方案以及其实现的效果。
3 multi-step框架的介绍
首先约定一下下文符号的表示:
X X 与
分别表示两类语言中独立训练好的词嵌入矩阵。
Xi∗ X i ∗ 与 Zi∗ Z i ∗ 表示在相应的词嵌入矩阵中的第i个词的词嵌入向量。
我们的目标是要学习 WX W X 和 WZ W Z 这两个转换矩阵(transformation metrices),从而使得 XWX X W X 和 ZWZ Z W Z 在同一个跨语言空间中。
X(i) X ( i ) 表示在第 i i 步输出的词嵌入,
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 2640
2640











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









