







本章主要介绍 复制的三种方式 单领导者(single leader)、多领导者(multi leader)、无领导者(leaderless) 复制。
以及对复制过程中对性能和数据一致性的权衡,同步还是异步等。同时也列举了很多复制中可能出现的问题以及解决办法。但这远远不够,现实世界的复杂性在数据系统中体现的淋漓尽致。
数据复制的目的在于可扩展性,容错,高可用性,延迟等等。这些有助于我们理解为何要将数据库设计成这样。
数据复制本质上来说是将数据分布在多台机器上,这通常有两种方式:
- 复制:在不同的节点保存数据的相同副本,提供冗余、改善性能
- 分区:将一个大型数据库拆分成较小的子集,不同的分区指派给不同的节点。
分区和复制是不同的机制,但常常同时使用。
目录
单主复制
领导者和追随者
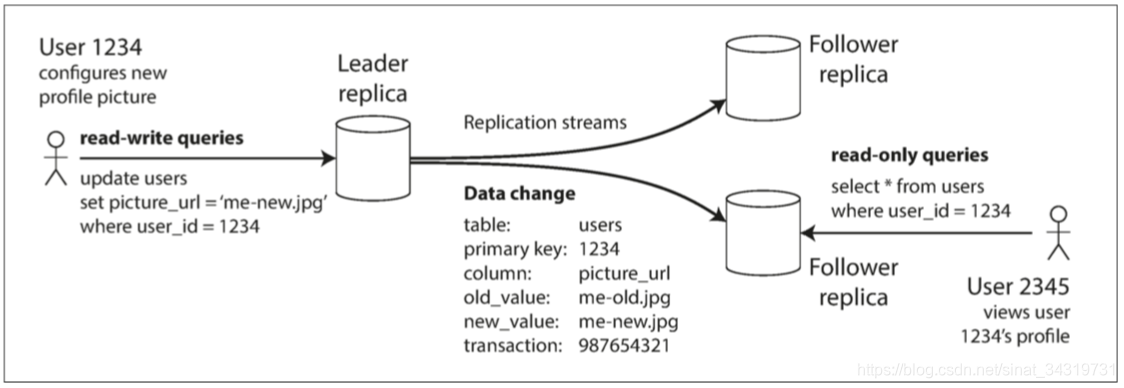
副本之一被指定为主库,或领导者,客户端的所有写入请求必须发送给主库,主库会将新数据写入存储。
其他副本称为从库,或者追随者;当主库的写入存储后,它也会将数据变更发送所有从库,这称为复制日志,或变更流;
每个追随者从领导者那里拉取日志,并相应的更新本地数据库副本,为了保证数据和领导者一致,则必须使用和领导者处理的相同顺序应用所有变更
客户端想要读取数据时,可以从领导者或者追随者那里读取。但是只有领导者才能接受写入。如下图所示
同步复制和异步复制
复制的发生是**同步(synchronize)的还是异步(asynchronously)**的。
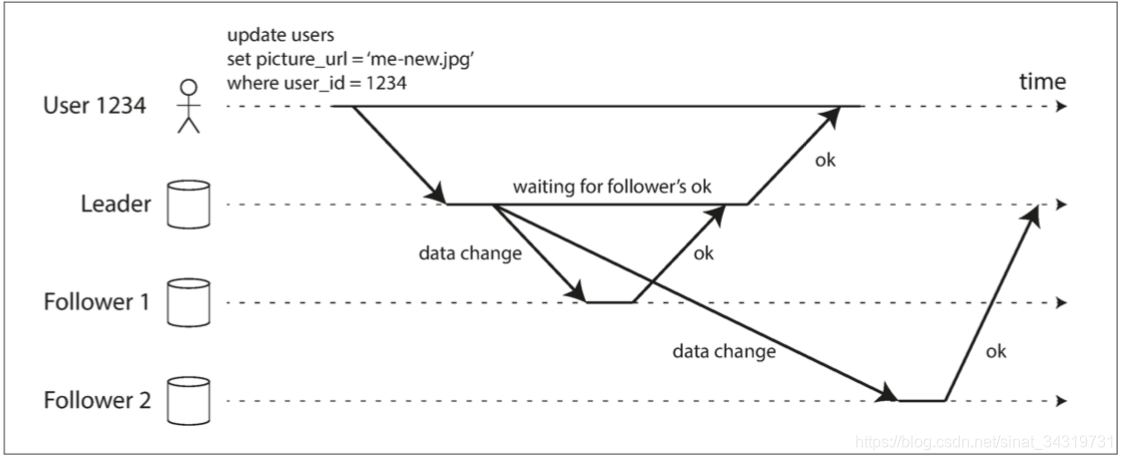
假如我们有如下例子,网站用户试图更新他们的个人头像。
基于领导者的复制
从库 1 的复制是同步的,Leader 等待 follow1 复制完成,才向用户报告写入完成,并且其写入是对用户可见的
从库 2 的复制是异步的,follow2 的复制有明显延迟,并且 Leader 不等待follow2 的响应。
通常情况下复制的速度相当快,但是对于复制所需要的时间没有保证。有些情况下从库可能会显著落后于从库:(1)从库从故障中恢复;(2)系统资源耗尽;(3)节点之间存在网络问题
同步复制的优点,从库保证有与主库一致的最新数据副本,主库即使突然失效,从库依然能提供完整的数据。缺点是,如果从库没有响应(网络问题,系统崩溃,),主库就无法写入,必须要等到同步副本可用时才能写入。
因此将所有副本设置为同步是不现实的,通常设置一个副本是同步的,其他副本是异步的。如果同步从库不可用,则使一个异步从库同步。保证至少两个节点上拥有最新的数据副本,这种方式通常称为半同步复制(semi-synchronous)
通常情况下基于领导者的复制会配置为完全异步的。这种情况下,如果主库失效并且不可恢复,则所有尚未复制到从库的写入都会丢失,这意味着即使已经向客户端确认成功,写入也不能保证持久。如果主库可以恢复,则可以根据主库恢复的结果再向从库复制。无论如何,完全异步的复制也有好处,即使所有的从库都落后了,主库也可以继续处理写入。
补充
异步复制已经被广泛应用,异步复制还有一个重要的问题-异步复制延迟。
同步复制的变种,链式复制。
同时复制的一致性和共识(使几个节点就某个值达成一致)之间有着密切的联系,不过那是另外一个领域了。
复制的几个常见问题
新增从库
如何使从库用户主库的精确副本?
从概念上讲,过程如下:
- 在某个时刻获取主库的一致性快照(如果可能),而不必锁定整个数据库。大多数数据库都具有这个功能,因为它是备份必需的。对于某些场景,可能需要第三方工具,例如MySQL的innobackupex 【12】。
- 将快照复制到新的从库节点。
- 从库连接到主库,并拉取快照之后发生的所有数据变更。这要求快照与主库复制日志中的位置精确关联。该位置有不同的名称:例如,PostgreSQL将其称为 日志序列号(log sequence number, LSN),MySQL将其称为 二进制日志坐标(binlog coordinates)。
- 当从库处理完快照之后积压的数据变更,我们说它**赶上(caught up)**了主库。现在它可以继续处理主库产生的数据变化了。
节点宕机
从库宕机:追赶恢复
从库记录从主库收到的数据变更。如果从库从崩溃中开始恢复,则从库可以从日志中知道自己处理的最后一个事务。此时从库重新连接到主库,并应用断开连接时发生的所有数据变更。当应用完成后,从库赶上了主库,就可以继续接收数据变更流了。
主库失效:故障切换
主库失效处理起来比较棘手,主要流程如下:其中一个从库需要被提升为新的主库;需要重新配置客户端连接,将其连接到新的主库,并将客户端的写入发送到新的主库,其他从库也需要从新的主库拉取所有的数据变更流。这个过程称为故障切换。
故障切换通常由如下步骤组成:
- 确认主库失效。主库失效可能由很多种原因造成:停电,故障,网络问题等等,没有万无一失的方式来检测出了什么问题。大部分系统只是使用超时(timeout),节点直接通过心跳机制传递消息,如果一个节点在一段时间内(30 秒)没有响应,就认为这个节点出现故障了。
- 选择一个新的主库。这通常使用选举过程来完成,主库的最佳候选人通常是拥有最新的数据副本的从库。让所有节点同意一个新的领导者这是一个共识问题。
- 重新配置系统启用新的主库。客户端需要将请求发往新的主库,如果老的主库恢复,可能会依旧认为自己是主库,这需要一些机制来确保老的主库认可新的主库,成为一个从库。
我们再来列举一些故障切换时可能忽略的麻烦:
-
如果使用的是异步复制。老主库宕机时部分写入操作并未同步到从库。新主库在选出后,如果老主库重新加入系统,新主库在此期间可能会收到冲突的写入,这些冲突的写入如何解决?方案 1:丢弃未复制的写入
-
如果数据库需要外部存储协调,那么丢弃写入内容是非常危险的。GitHub-故障
-
发生故障时出现了两个节点都认为自己是主库的情况。即发生了脑裂的情况,两个主库都可以接收写入,但却没有冲突解决的机制,那么数据就有可能会被损坏
复制日志的实现
基于语句的复制
主库记录下它执行的每一个写入请求,并将该语句日志发往从库,每个从库解析并执行该语句,就像是客户端执行。
但是有些情况下却不适用:
- 调用的非确定性函数,时间函数 now() ,rand()等等
- 使用了自增列。自增列依赖于数据库中现有的数据,则要求副本中执行顺序和主库中完全相同
- 有副作用的语句。例如触发器,存储过程,用户定义的函数。
绕开这些限制的方式,将不确定性变为确定性,这样从库就可以获取到相同的值。但是边缘 case 实在太多,MySQL 发现如果语句中有任何不确定性,就会切换为基于行的复制。
逻辑复制日志
数据库为了保证事务安全,通常每次修改都会先写入预写式日志(Write ahead log)WAL,日志包含了所有数据库写入,则完全可以用相同的日志在另外一个节点上构建副本。即主库将日志发送给从库,从库就可以建立和主库一模一样的数据副本了。
以行的方式描述对数据库的写入记录序列:
- 对于插入的行,日志包含所有列的新值
- 对于删除的行,日志需要足够的信息标识唯一的行。通常是主键。
- 对于更新的行,日志包含足够的信息标识唯一更新的行,以及所有列的新值
复制延迟问题
复制可以解决如下问题:
- 单个节点故障
- 可扩展性(处理更多的请求)
- 延迟(将副本放到离用户更近的地方)
常见的 web 模式,都是读多写少的场景,写入都是有主库完成,但是只读查询可以由任意一个从库完成。
这种扩展体系通常由异步复制实现,因为同步复制时,单个节点故障或者网络中断则会导致整体服务不可用。
用户从一个从库读取刚刚写入的数据时,如果从库落后,则会读取到过时的信息。如果从主库和从库分别读取,则可能会出现明显不一致的场景。当从库最终赶上了主库,并保持一致。这种效应称为最终一致性
读己之写
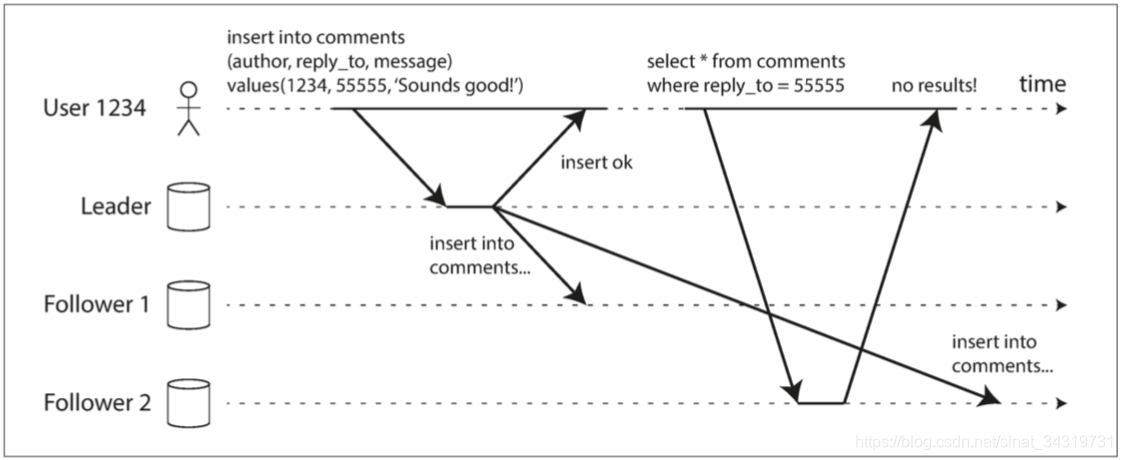
上图显示,用户提交了一个评论到主库。然后立即查看自己提交的评论。如果新数据未达到副本,则在用户看起来是刚提交的数据丢失了
这需要读写一致性来保证,用户总会看见自己提交的任何更新。但是不保证其他用户的写入。
如何实现?
- 读取用户可能修改的内容时,都从主库读。比如说用户的个人资料。
- 客户端记住最近一次写入的时间戳,系统需要保证给用户提供查询时,该时间戳的所有变更都已经同步到本地库。时间戳可以是逻辑时间戳
- 或者如果一个查询在从库未查询到数据时,则将请求路由到主库中。
单调读
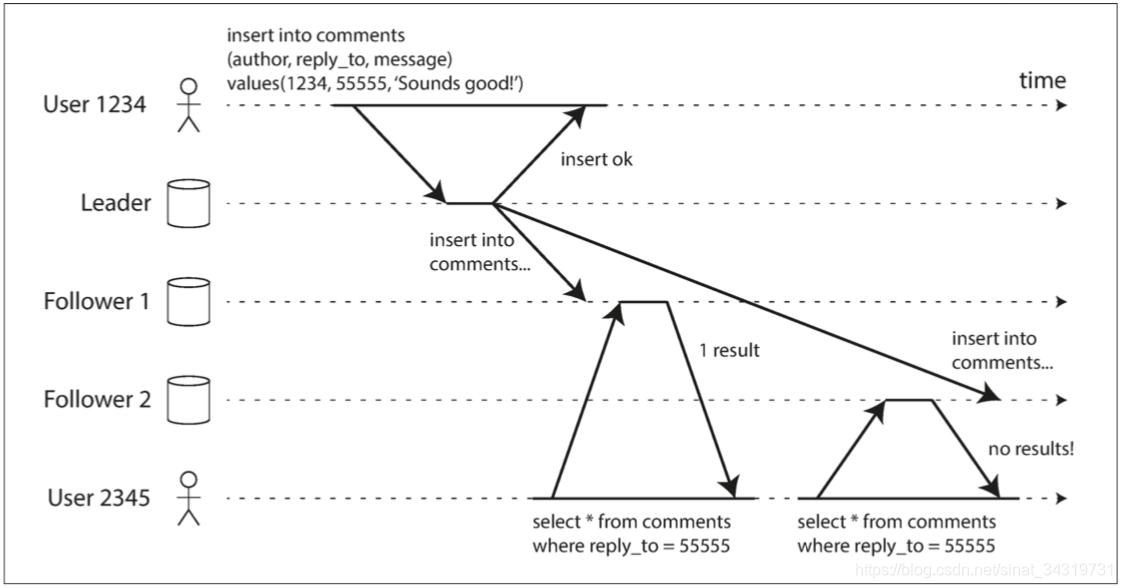
上图显示了另一种情况,用户 2345先看见了 用户1234的评论,然后再次刷新,发现评论又没有了。
这种情况是由于用户首先查询了一个延迟较小的从库,然后是一个延迟较大的从库。然后用户发现出现了时光倒流的情况。
解决这种情况,需要单调读的保证。单调读仅意味着一个用户顺序的进行读取,则他们不会看到时间倒退。即如果读取了较新的值,则不会读取到较旧的值。
实现方式:确保每个用户总是从同一个副本读取。
一致前缀读
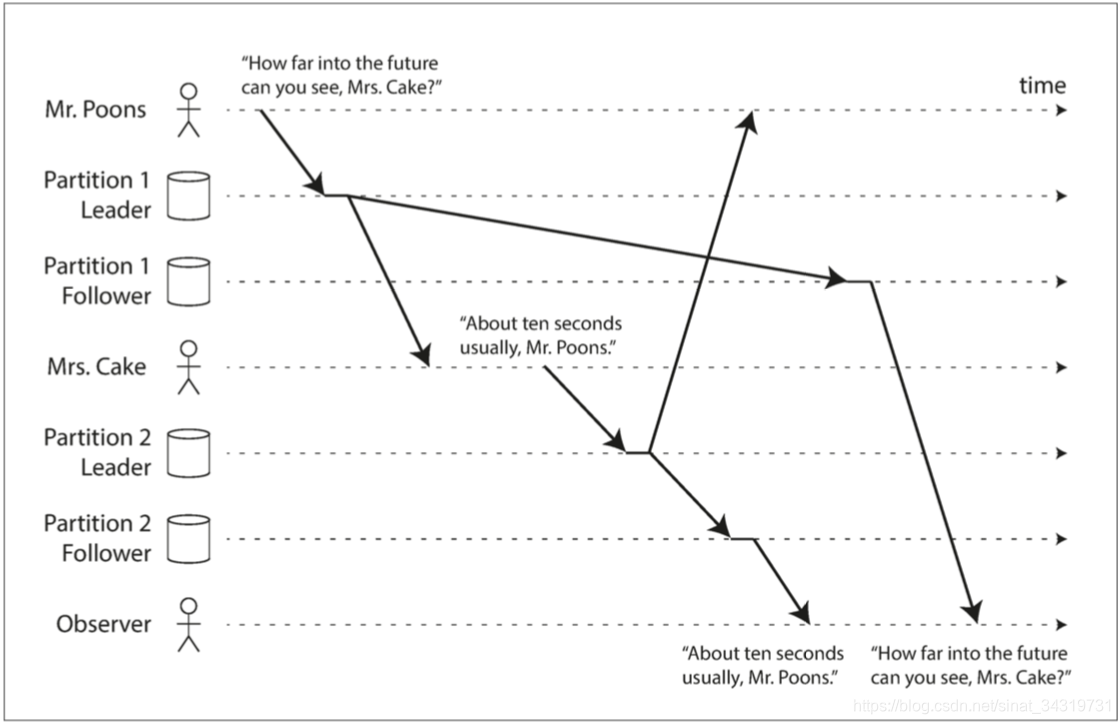
p 说了A,接着 C 回复了 B,但是在第三个观察者看来是C 先说的 B,接着 P 回复了 A。
这个问题出现的原因是,某些分区的复制慢于其他的分区,则观察者就有可能先看见答案,再看见问题。
解决办法:一致前缀读的保证,如果一系列的写入按照某种顺序发生,那么任何人读取这些写入时,也是以相同的顺序出现。
这是分片数据中的问题,不同的分片独立运行,因此不存在全局的时序,用户读取时,则可能看见部分数据是新的部分数据是旧的可能。
一种解决方案是:确保任何因果相关的写入都写入相同的分区。
复制延迟的解决方案
在使用最终一致的系统里面,如果延迟大于 10 秒钟,则应该考虑系统的行为。如果对于用户来说是不好的体验,那提供更强的保证是重要的,例如写后读。如果系统明明是异步复制却假设是同步的,会造成很多不必要的麻烦。
事务提供了强大的保证,应用程序就不必担心这些微妙的问题。单节点的事务已经存在很长时间了,分布式事务虽然有一些方案,但在性能或者可用性上代价太高,很多分布式系统放弃了分布式事务。后面的章节会重新回到这问题。
想起之前的业务场景,一个页面是在用户支付完后前端直接重定向过去的,但是重定向过去之后,异步处理过程可能未开始、未完成、或者异常,每种情况下必须给用户响应,所以会提示用户刷新重试。
多主复制
场景:假设有一个数据库,其副本分散在好几个数据中心,常规的做法是,领导者位于其中一个数据中心,所有写入都经过这个数据中心
多领导复制配置则在每个数据中心配置主库,数据中心内使用常规的主从复制。在数据中心之间,每个数据中心的变更都会被复制到其他数据中心的主库中。
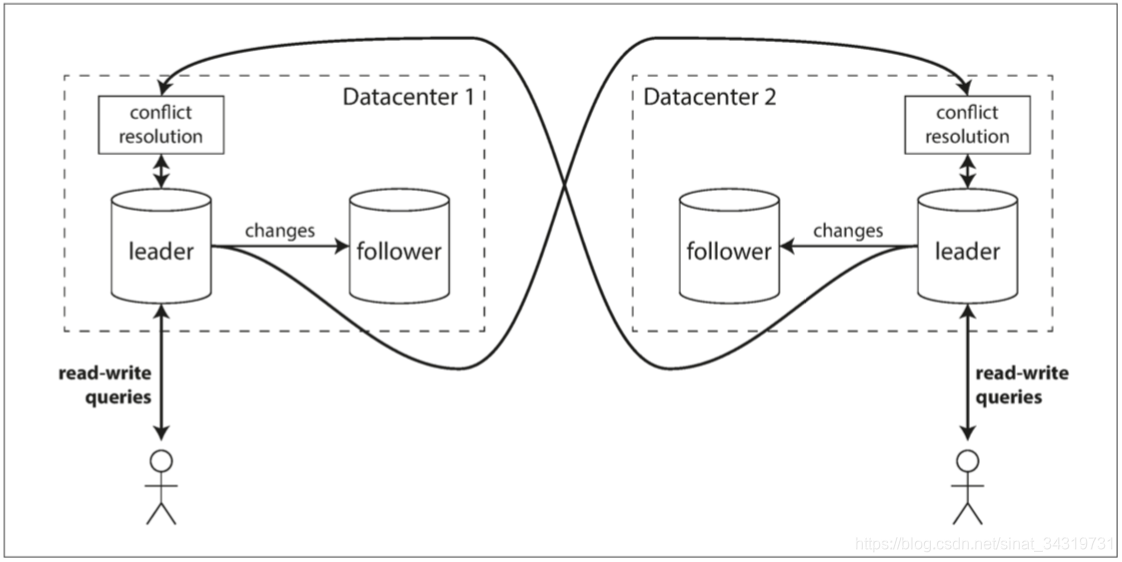
比较单主复制和多主复制
- 性能 :单主情况下,所有写入都会到唯一一个数据中心。多主情况下,每个写入都可以在本地数据中心处理,并与其他数据中心异步复制。性能相对于单主可能会更好。
- 容忍数据中心停机:单主配置下,主库所在数据中心发生故障,故障切换使另一个数据中心的从库升级为主库。
多主配置下,每个数据中心独立运行, 当故障发生的数据中心归队时,复制会自动赶上。 - 容忍网络延迟:单主配置对数据中心之间的连接非常敏感。采用异步复制功能的多活配置能更好的承受网络问题。
多主复制的缺点
不同的数据中心修改相同的数据,写冲突必须要解决。
多主复制虽然在多个数据库都有支持,例如MySQL的Tungsten Replicator ,用于PostgreSQL的BDR。但是都是属于改装的功能,所以常常会有微妙的错误发生,如自增主键、触发器、完整性约束等场景。
适用场景
需要离线操作的客户端
考虑手机、笔记本和其他设备的备忘录应用。你可以随时查看和更改其内容,则设备再次上线时,需要与服务器和其他设备同步。
这种情况下,每个设备都临时充当了领导者的本地数据库,所有设备再次上线时,存在异步的多主复制的过程。
协同编辑
多个用户在 web 浏览器或者应用中编辑协同编辑的文档,所做的更改立即同步到本地的文档副本中,然后异步复制到服务器和同时编辑此文档的其他用户。
如果锁定的范围是整篇文档,则实际上就是单领导复制的模式。
如果为了加锁协作,那么锁定范围必须要小,同时允许多个用户编辑,这就带来了多领导复制的缺点,解决冲突。
处理写入冲突
考虑两个用户同时编辑维基百科的一个条目,引起的冲突。
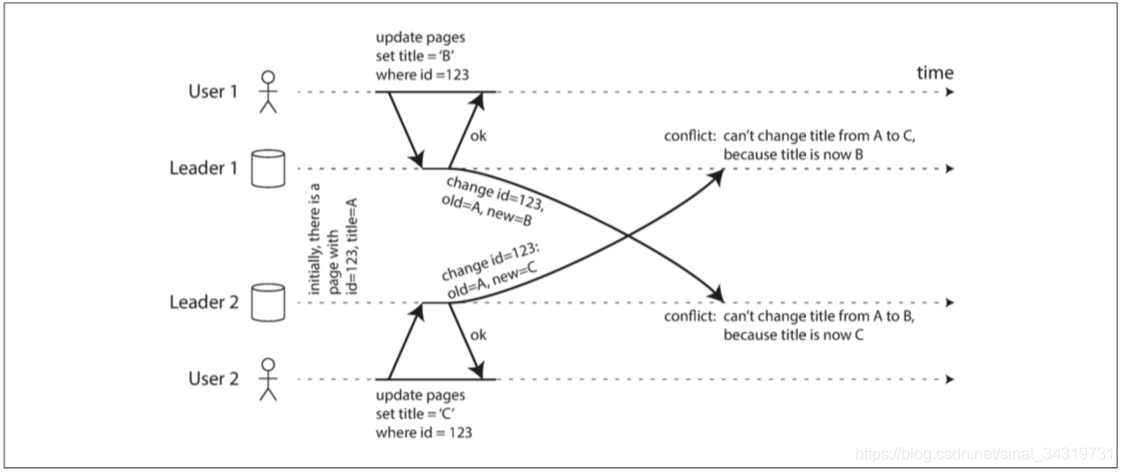
同步/异步冲突检测
单主数据库中,第二个写入将会被阻塞,等待第一个写入完成,或者第二个写入被终止,让用户重试。
多主数据库中,两个数据写入都是成功的,只是在稍后异步检测到冲突,那时要求用户解决冲突就有点晚了。
原则上可以使冲突检测同步,等待写入被复制到每个数据副本后再通知用户成功。但是这失去了多主复制的优势。
避免冲突
如果所有特定记录的写入都会被路由到同一个数据中心。那么就没有冲突了。
但是当某个数据中心出现故障时,请求被路由到另一个数据中心,这种情况下就必须要处理冲突了。
收敛至一致的状态
单主数据库中:单个字段如果有多个更新,则以最后一次写入为该字段的最终值。
多主配置中,写入是没有顺序的,如果每个副本数据库按照它看见的顺序写入,则数据库最终会处于不一致的状态。
这是不能被接受的,数据库的所有副本最终必须是一致的,这就要求副本在复制完成时收敛到一致的状态,也就是一个相同的最终值。
实现冲突合并解决的途径:
- 给每个写入一个唯一的 Id,以 Id 最大的写入为最终值,丢弃其他写入。容易造成数据丢失。
- 给每个副本分配一个唯一的 Id,ID 更大的副本具有更高的优先级。容易造成数据丢失。
- 以某种方式将这些值合并在一起,类似于 B/C ,然后将数据连接在一起
- 在保留所有信息的显式数据结构中记录冲突,并编写解决冲突的应用程序代码,或者提示用户的方式。
自定义冲突解决逻辑
最适合解决冲突的可能是应用程序本身
- 写时执行:只要系统检测到复制时存在冲突,就会调用冲突处理程序。但是这个通知通常不能提示用户
- 读时执行:检测到冲突时,所有冲突都会写入存储,读取时会将多个版本同时返回给用户,应用程序可能自动处理冲突或者用户手动处理冲突,然后写回数据库
自动解决冲突
- 无冲突复制数据类型(Conflict-free replicated datatypes)
- 可合并的持久数据结构(Mergeable persistent data structures),类似于 Git 的版本控制系统,使用三项合并
- 可执行的转换(operational transformation),Google docs
多主复制拓扑
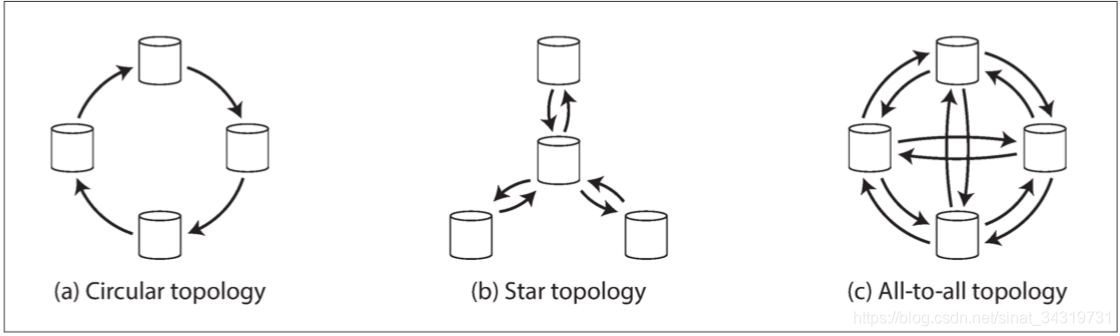
最普遍的形式是(c)全部到全部的领导者节点的复制。接下来是受限的几种形式,星型拓扑,几个指定的主节点将所有写入转发给其他所有节点;最受限是环形拓扑。
写入在复制到副本时会通过多个主节点,节点需要转发来自于其他节点的变更,为了防止无限复制循环,每个节点都需要赋予一个唯一的标识。并且在复制日志中,每个写入都会标记哪些节点已经被复制过了。
环形拓扑和星型拓扑结构,在某个节点发生故障时,则可能会中断其他节点之间的复制通道。
全部到全部的复制虽然容错性更好,但是也可能会出现下面的问题。
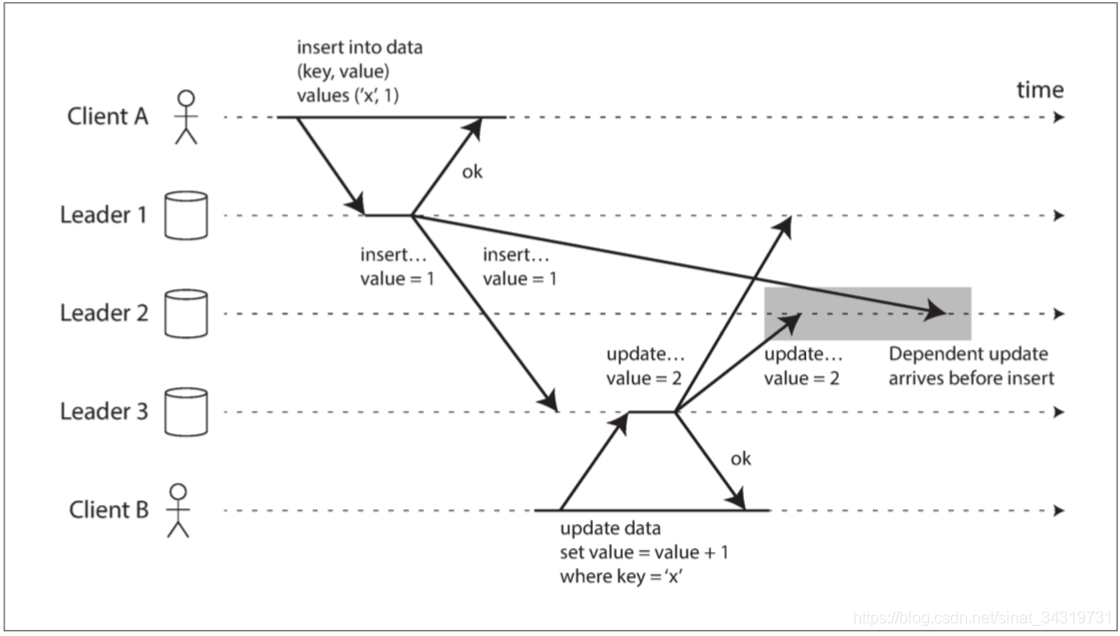
客户端 A 先插入数据到 Leader1 ,然后复制到Leader2,Leader3 上,由于某些原因 Leader3 先完成,然后客户端B更新的刚插入的数据,然后复制到 Leader1,Leader2 上,由于 Leader收到的写入消息顺序也是不固定的,就有可能出现,更新写入先于插入写入到达,要解决这种冲突,需要对写入进行正确排序,见 检测并发写入
无主复制
常见的数据库充,通常是客户端向主库发送写请求,数据库系统负责将写入复制到其他副本,主库决定写入的顺序,从库按照相同的顺序应用写入。
一些存储系统放弃主库的概念,允许任何副本直接接受来自客户端的写入。例如 亚马逊的Dynamo系统
具体的实现上,客户端将写入直接发送到几个副本中,另一些情况下一个协调者代表客户端进行写入,但是协调者不执行任何特定的写入顺序。如下图所示
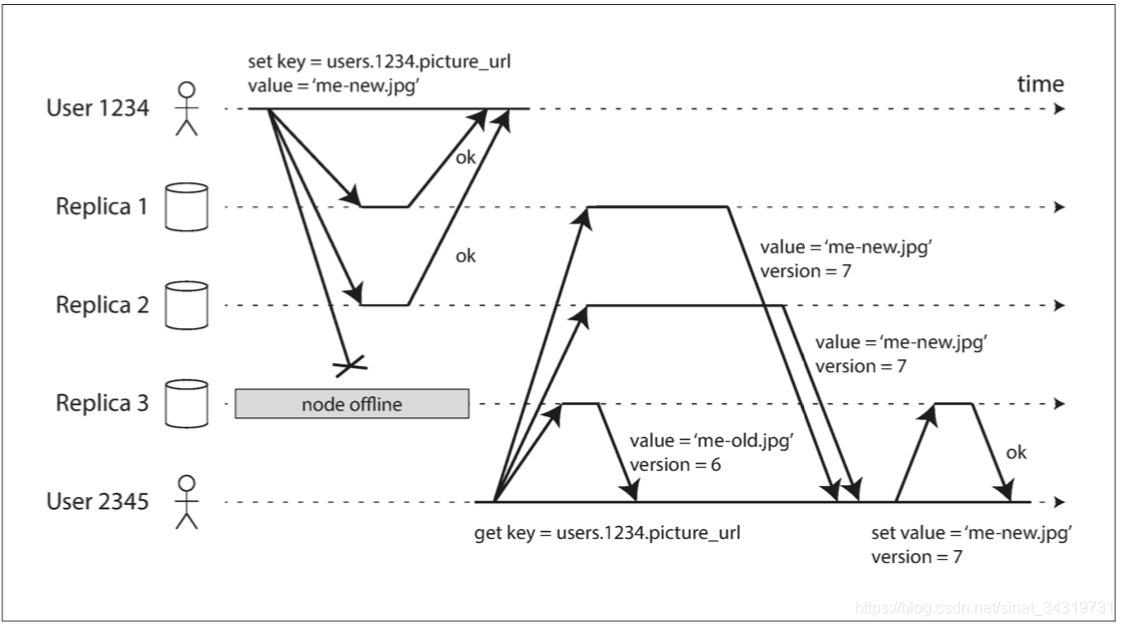
客户端并行发送写入到三个副本,其中两个副本接受了写入,另外一个副本不在线,同时假设两个副本的写入是足够的,客户端收到两个确认后认为写入是成功的。并且忽略了失败的副本。
当副本 3 再次上线时,客户端开始从副本 3 读取数据,但是副本 3 的数据是陈旧的,为了解决这个问题,客户端从数据库中读取数据时,会将请求发送给多个副本,不同的副本可能返回不同的响应,根据数据的版本号来确认哪个值更新。
如何让落后的副本赶上错过的写入?
有如下机制:
- 读修复:客户端并行读取多个副本,如果有陈旧的数据副本,客户端将新值写回到副本中,适用于频繁读的场景
- 反熵过程:一些数据存储具有后台进程,该进程不断的查找副本之间的数据差异,并将任何缺少的数据从一个副本复制到另一个副本。这个过程与基于领导者的复制不同。该进程不会以特定的顺序写入。
读取的法定人数
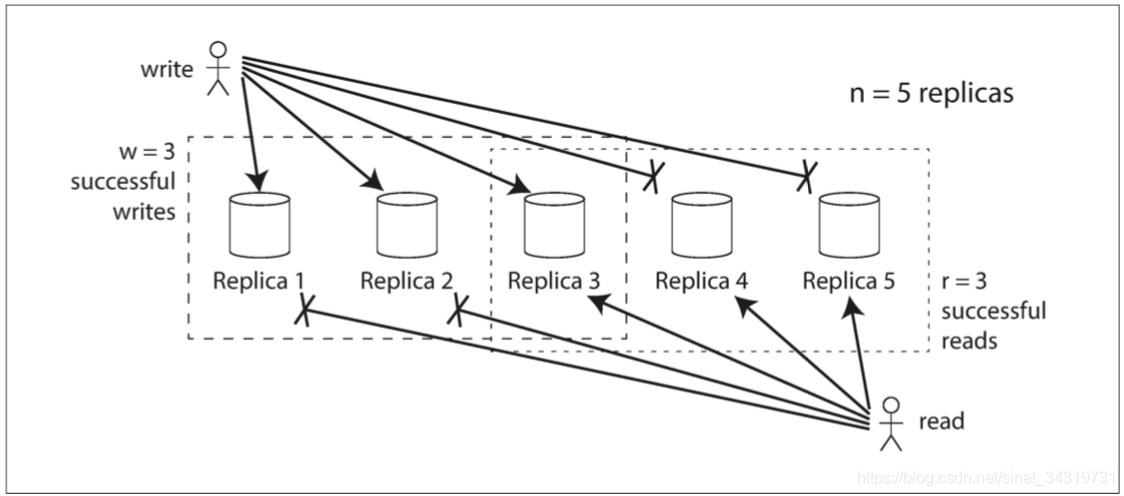
在上图的三个副本中,我们认为有2 个副本成功写入即可认为本次写入成功,因此至多只有一个副本的数据陈旧的。那么我们在读取数据的时候,至少从两个副本中读取,则可以确认至少有一个副本的数据是最新的。如果第三个副本故障,则读取仍然可以读取到最新值。
根据以上的例子,我们假定总副本数为 n,每次写入至少有w 个副本写入才算本次写入成功,而读取必须读取 r 个节点才能读取到最新值,所以只要满足 w + r > n w+ r > n w+r>n ,我们就能保证读取时至少有一个节点的值是最新的。W 的值称为法定人数(quorum)。r和 w 是进行有效读写所需的最小票数。通常情况下 n为奇数。并设置 w = r = ( n + 1 ) / 2 w = r =(n + 1)/ 2 w=r=(n+1)/2(向上取整),因为这样可以容忍更多的节点不可用,同时两者的值不同对写入或者读取的性能都有影响。
当然,如果少于w 或 r 个节点可用,则写入或者读取会返回错误。节点可能由于很多原因不可用,但是客户端只关心节点是否返回了成功的响应,而不需要区分不同的错误类型。
仲裁一致性的局限性
当 w + r > n w+r>n w+r>n 时,期望读取总能返回一个写入的最新值,因为写入的节点和读取的节点必须重叠。通常情况下 w w w 和 r r r 都是大于 n / 2 n/2 n/2的,
这样可以容忍至多 n / 2 n/2 n/2个节点故障。
法定人数 w w w 可以配置小于 n / 2 n/2 n/2,这样写入只需要少数节点返回响应即可认为是成功的。但是$ r $ 如果也配置的很小,那么就有较大可能会读取到陈旧的值,但这允许更低的延迟和更高的可用性:如果许多副本同时不可用,则可以继续处理读取和写入,只有当副本数分别小于 w 和 r 时,数据库才会不可读取或写入。
即使 w w w 和 r r r 都是大于 n / 2 n/2 n/2的,也会有很多边缘情况需要考虑:
- 如果 w 和 r 没有重叠,很有可能读取到陈旧的值。
- 如果两个写入同时发生,如何挑选出最终的写入。如果按照时间戳大小选取,则由于时钟偏差,写入可能会丢失。
- 写操作和读操作同时发生,部分副本写入了新值,部分节点还未写入,读取的值不能确定是新值还是旧值
- 写操作在某些节点上失败,导致写入成功的节点数小于 W,所以整体写入需要判定为失败,在写入成功的节点数据未回滚之前,读取的值都有可能是脏数据。
- 如果写入新值的副本读取失败,则需要读取其他带有旧值的副本。并且其(写入新值的副本)数据需要从写入旧值的节点进行恢复,如果存储新值的副本数小于 W,从而打破了法定人数条件
- 即使满足仲裁条件,也有可能会出现时序问题
- 没有关于复制延迟的保证,可能会出现复制延迟出现的问题
解决写入冲突
最后写入胜利
由于是不同的客户端同时操作同一个 key,这些写入是并发的,因此并不知道哪个操作在前,哪个在后。所以我们可以对写入进行排序,比如按照时间戳排序,那么时间戳大的,就会被认为是后写入的,就会覆盖之前写的值。但是有丢数据的可能性。
还有一种方式是,只写入一次,然后视为不可变。
“此前发生”的关系和并发
作者试图向我们解释 “此前发生”和 并发
如果有 A 和 B 两个操作,B 的操作是依赖 A 的结果的,我们说 B因果依赖于 A
如果A 和 B 同时执行,A 不知道 B 的发生,B 也不知道 A 的发生,我们称 A 和 B 是并发的
作者用一个购物车的例子捕获**“此前发生”关系**
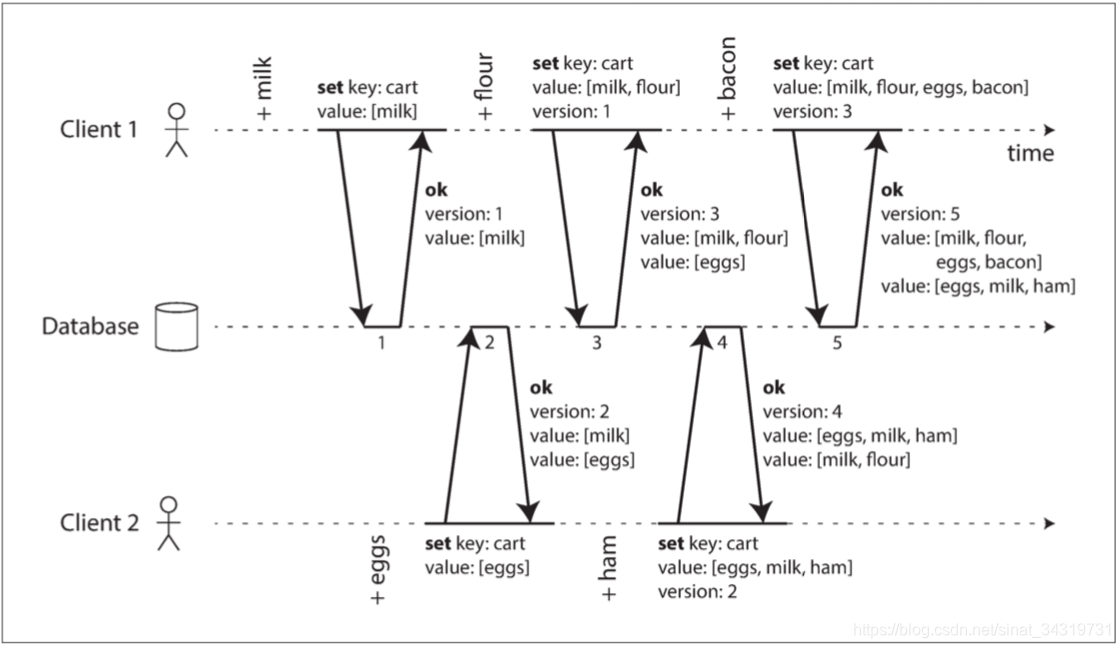
购物车从空的开始,两个客户端并发的操作购物车。
每次写入到服务器后都会给当前的数据分配一个版本号,此后无论是读取还是写入都需要把当前数据的版本号带上,这样保证了可以合并相同的值,而不会出现重复添加的问题。同时基于版本号,添加的不同项也可以被很好的合并起来。
但是注意删除购物车的其中一项,并不是一件容易的事情,例如client2 在 版本 4 中删除了 鸡蛋,但是 client1 在版本5的写入中会继续带上 鸡蛋(版本 5 是基于版本 3的 ),那么在服务端合并的时候并不知道鸡蛋是新加的还是删除的。所以删除的时候,只能将数据项标记为删除。
版本向量
我们可以看到购物车的读取和写入都是带有版本号的,所有副本的版本号集合称为版本向量。
版本号用来捕捉操作之间的依赖顺序。但是在多个副本的并发写入时,每个数据仅有版本号是不够的,还需要在每个副本中使用版本号。副本之间的版本号用来跟踪覆盖哪些值,以及可保留合并的值。
版本向量可以解决覆盖写入和并发写入,以及合并数据。














 572
572











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









