







论文题目:Object Instance Mining for Weakly Supervised Object Detection
论文链接:https://arxiv.org/pdf/2002.01087.pdf
论文代码:https://github.com/bigvideoresearch/OIM
提出了一种端到端的物体实例挖掘(Object Instance Mining,OIM)弱监督目标检测框架。其实就是提供了一种充分挖掘proposals的方法。
从现有的多目标检测发现:
1、很容易陷入局部最优。因为这个学习机制倾向于对每一个类别学习一张图片中最明显的特征,其他被忽略的物体实例容易使学习网络陷入局部最优,进而影响弱监督目标检测的性能。在训练过程中可能会选择缺失的区域作为负样本,这可能会进一步降低CNN分类器的识别能力。
2、置信度最高的region proposal 很容易集中在目标的局部位置。这可能会导致只检测到物体的一小部分的问题。
两个 Contribution
1、提出了一个基于spatial graphs和appearance graphs模型的网络框架。(OIM)
2、提出了目标实例权重重调损失函数。(Instance Reweighted Loss)
OIM基于两个基本假设:
1、置信度最高的proposal 及其周围高度重叠的proposal 可能属于同一类 ——> spatial similarity 建立spatial graphs
2、同一类的对象应具有较高的相似度 ——>appearance similar建立appearance graphs
框架
该框架引入了基于Spatial Graph及Appearance Graph的信息传播机制,在网络迭代学习过程中,就可以只使用image-level的监督信息在每张图片中挖掘所有可能的目标实例。这样使得在基于多实例学习方法的网络学习过程中,特征不够显著的物体实例可以被检测到并加入训练,进而提升特征的表达能力和鲁棒性。
框架由两部分组成:MID + OIM
MID(多实例检测器)进行行候选区域的选择和分类。
OIM集成候选框的特征和MID的检测结果。
主要介绍OIM
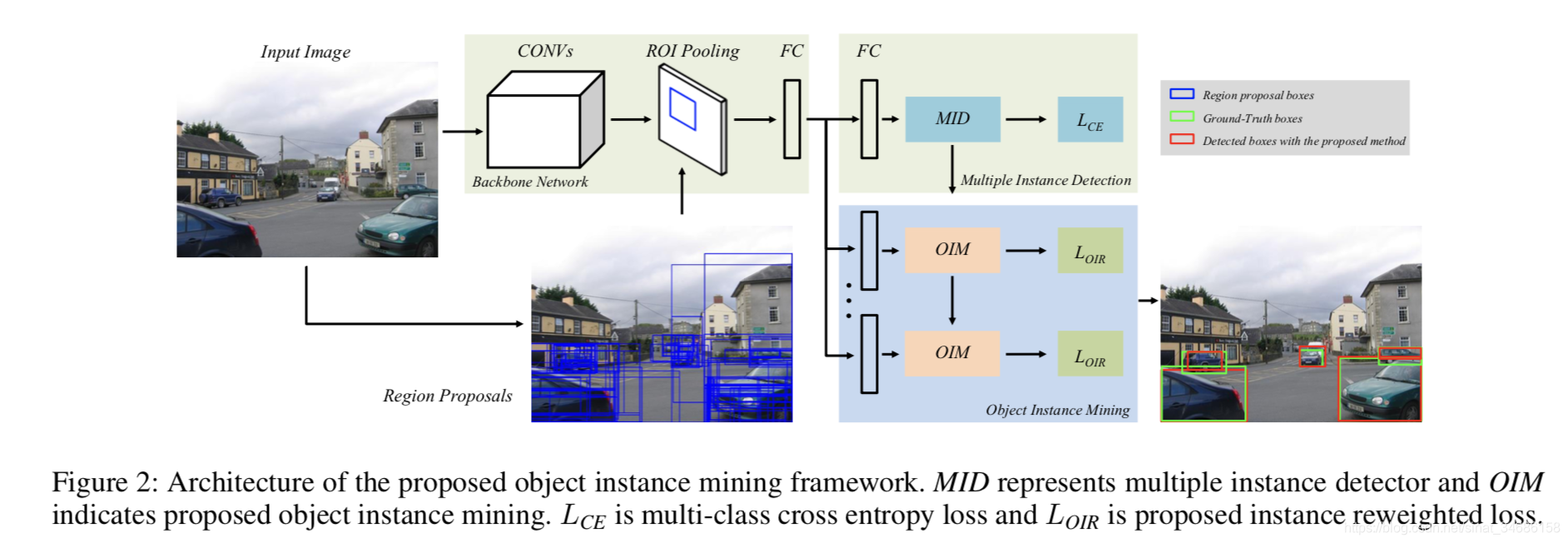
OIM
给定一张图片 I,选定置信度最高的proposal P
-
建立spatial graphs:
G i c s = ( V i c s , E i c s ) G_{i_c}^s = (V_{i_c}^s , E_{i_c}^s ) Gics=(Vics,Eics)
V i c s V_{i_c}^s Vics代表 与P的overlap大于阈值T的proposal
E i c s E_{i_c}^s Eics代表spatial similarity
所有 G i c s G_{i_c}^s Gics中的节点都被认为与P相同类别 -
建立appearance graphs
F = { f 1 , . . . , f N } F=\{f_1,...,f_N\} F={f1,...,fN}
G a = ( V a , E a ) G^a = (V^a , E^a) Ga=(Va,Ea)
V a V^a Va 代表与P有高的特征表示的相似度的proposal
E a E^a Ea表示appearance similarity
using the Euclidean distance
相似度计算: D i c , j = ∣ ∣ f i c − f j ∣ ∣ 2 D_{i_c,j} =||f_{i_c}-f_j||_2 Dic,j=∣∣fic−fj∣∣2
选取条件: D i c , j < α D a v g D_{i_c,j} <\alpha D_avg Dic,j<αDavg
p j p_j pj与之前选取的proposal没有重叠
D a v g D_{avg} Davg计算: D a v g = 1 / M ∑ k D i c , k , s . t . I o U ( p i c , p k ) > T D_{avg}= 1/M\sum_kD_{i_c,k}\space ,\space s.t. \space IoU(p_{i_c},p_k)>T Davg=1/M∑kDic,k , s.t. IoU(pic,pk)>T
spatial graphs 和 appearance graphs中所有proposals都用于训练

Instance Reweighted Loss
目的:学习到更准确的检测框。
置信度最高的region proposal 很容易集中在目标的局部位置。这可能会导致只检测到物体的一小部分的问题.
为了缓解对于非刚性目标学习到目标实例最明显部分为不是整个目标实例,作者为各个候选框分配不同的候选框权重来平衡置信度最高的候选框的权重和区别度不是很高的候选框的权重.
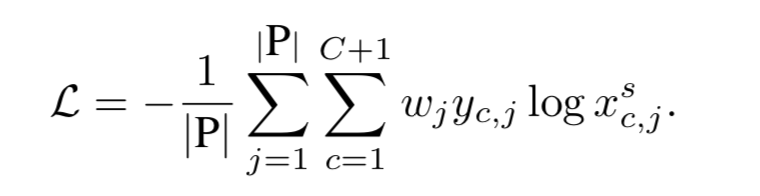
以上可以看到,空间图中的每个候选框对损失函数的贡献均等,这就导致了其他得分较低的候选框很难被学习到。所以引入了该损失函数来平衡这个情况:

还使用了标准的多类交叉熵损失进行多标签分类,并结合Instance Reweighted Loss进行训练。
实验
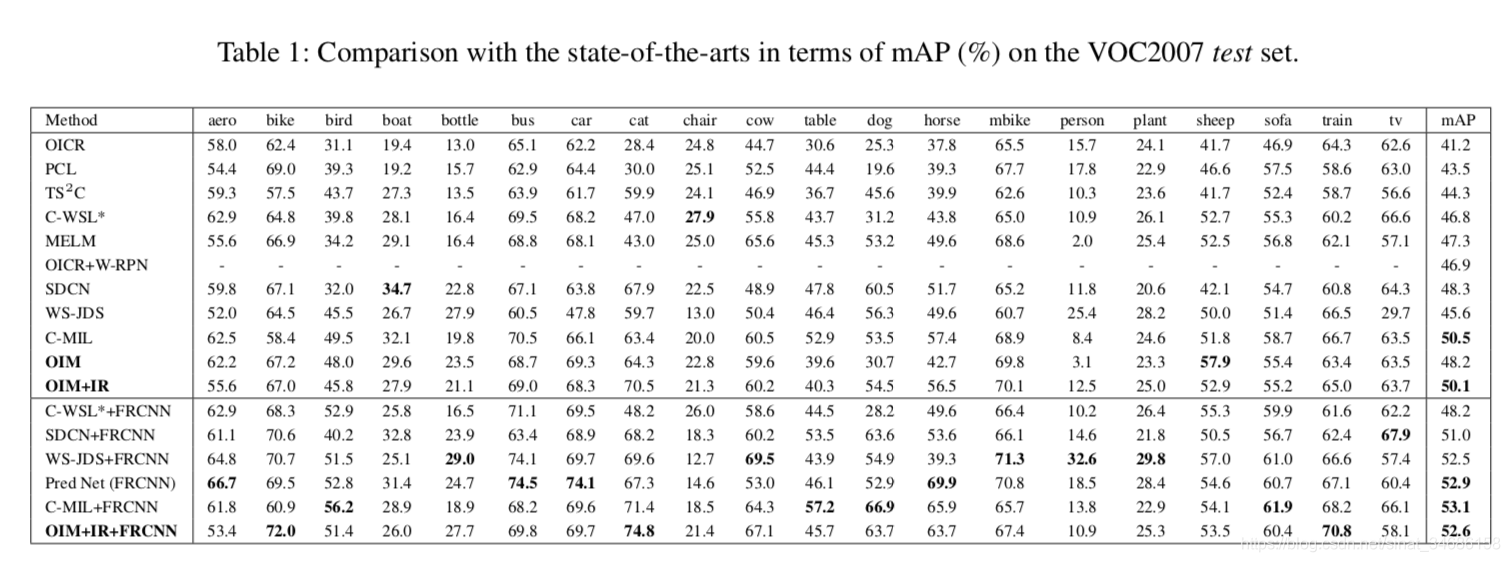
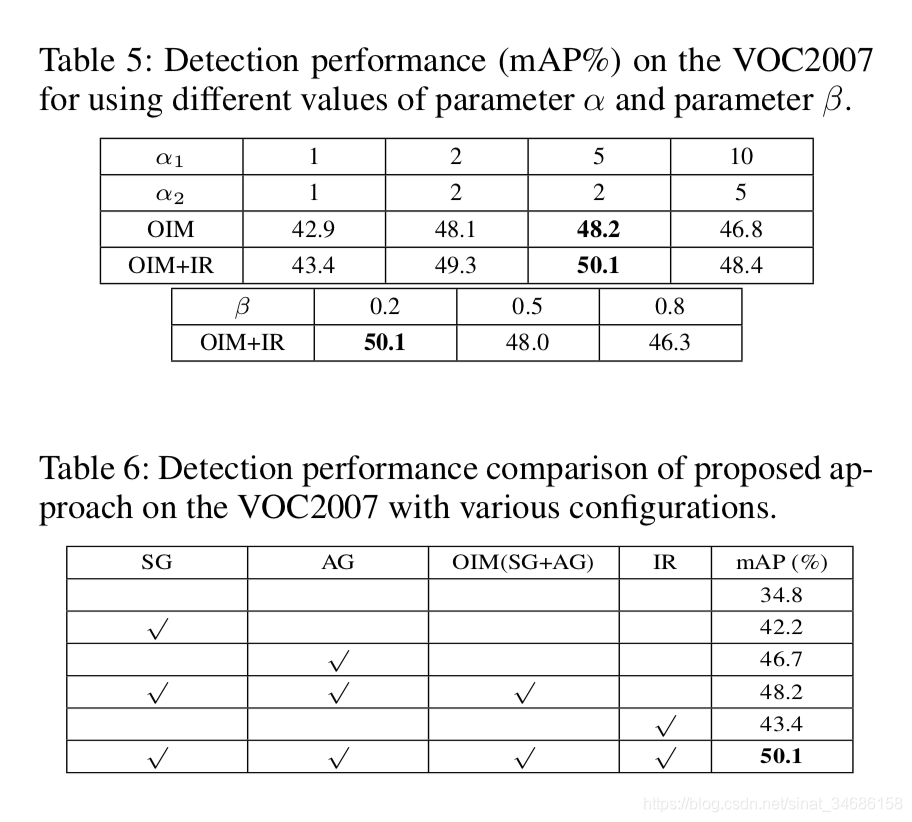














 1237
1237











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









