







JVM的自动垃圾收集(Garbage Collection)使得开发人员无需关注垃圾收集的细节,不过,当内存问题成为系统瓶颈的时候,我们就需要了解一下JVM的垃圾收集机制了。
应用程序中生成的对象绝大部分都是临时对象,属于那种生的快死的快的,来也匆匆,去也匆匆,当然也有伴随应用程序的生命周期而存在的对象,鉴于对象 的生命周期的不同,JVM的内存是分代(Generation)管理的。如果把JVM看作一个战场,把各个对象看作士兵,那么大部分的士兵刚投入战场不久 就英勇就义,只有少部分的士兵能够在战场中摸爬滚打能够坚持一段时间。(史上最残忍的战场,阿弥陀佛,善哉!善哉!)。分代情况如下图所示:
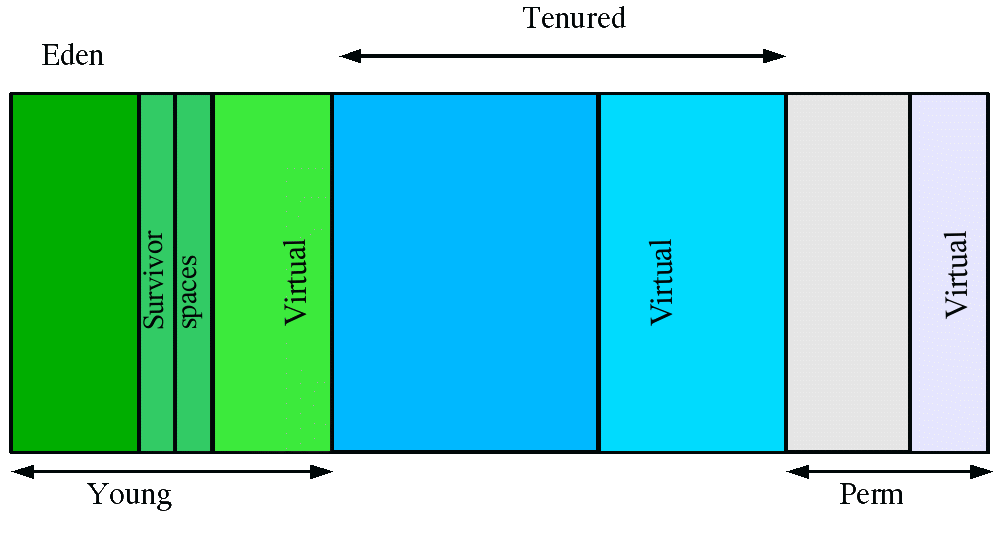
其中,年轻代(Young Generation) 包含伊甸园(Eden)和2段幸存者空间(Survivor Spaces),伊甸园当然是新生对象的乐园(只在乎曾经拥有,不在乎天长地久。也许看作前线战场更为合适:)(也有部分大对象直接分配在年老代)。而幸 存者空间是用来保存上次GC之后依然存活的对象,经过战事的洗礼,能够存活下来实属不易,说明你是一个优秀的士兵,特此晋升一下,并且分配给你一间前线作 战指挥所。2段空间保持其中一个为空,后面再详细说明缘由和作用。
年老代(Tunured Generation) 中存放的是那些从幸存者空间经过多次GC依然存活的对象,他们是由年轻的军官经过许多战事的磨砺而来,已经成为老一辈的无产阶级革命家。
永久代(Permanent Generation) 是保存VM描述对象的数据,比如类定义,方法定义的信息。这里属于战争的大后方。
当一个对象不再被引用时,该对象就是一个不可达的对象,dead的了,战死沙场了,就成为garbage了(汗一个)。GC就是通过一定的算法,判 断一个对象可达与否,通常是遍历所有可达的对象,剩下的对象就是认为是garbage,然后销毁这些garbage,释放内存。
既然内存是分代管理的,GC也就自然而然是分代收集的。
由于年轻代进进出出的人多而频繁,所以年轻代的GC也就频繁一点,但涉及范围也就年轻代这点弹丸之地内的对象,其特点就是少量,多次,但快速,称之为minor collection 。 当年轻代的内存使用达到一定的阀值时,minor collection就被触发,Eden及某一Survior space(from space)之内存活的的对象被移到另一个空的Survior space(to space)中,然后from space和to space角色对调。当一个对象在两个survivor space之间移动过一定次数(达到预设的阀值)时,它就足够old了,够资格呆在年老代了。当然,如果survivor space比较小不足以容下所有live objects时,部分live objects也会直接晋升到年老代。
Survior spaces可以看作是Eden和年老代之间的缓冲,通过该缓冲可以检验一个对象生命周期是否足够的长,因为某些对象虽然逃过了一次minor collection,并不能说明其生命周期足够长,说不定在下一次minor collection之前就挂了。给一个士兵晋升是要有一定的考察期的:)。这样一定程度上确保了进入年老代的对象是货真价实的,减少了年老代空间使用的 增长速度,也就降低年老代GC的频率。
当年老代或者永久代的内存使用达到一定阀值时,一次基于所有代的GC就触发了,其特定是涉及范围广(量大),耗费的时间相对较长(较慢),但是频率比较低(次数少),称之为major collection (full collection )。通常,首先使用针对年轻代的GC算法进行年轻代的GC,然后使用针对年老代的GC算法对年老代和永久代进行GC。
常用的garbage collectors:
- serial collector :针对young generation的串行垃圾收集器,使用stop-the-world(就是暂停整个应用程序的执行)的形式,利用单线程通过复制live objects到survivor space或tenured generation的方法来进行垃圾收集。
- parallel scavenge collector :针对young generation的并行垃圾收集器,利用多个GC线程来进行垃圾收集,每个线程的GC方法和serial collector一样。
- parallel new collector :针对young generation的增强的并行垃圾收集器,以便可以和CMS一起使用。
- serial old collector :针对tenured generation的串行垃圾收集器,使用stop-the-world形式,利用单线程通过mark-sweep-compact的方法进行垃圾收集。
- parallel old collector :针对tenured generation的并行垃圾收集器,利用多线程进行垃圾收集,方法和serial old collector一样。
- parallel compacting collector :对于young generation使用和parallel new collector一样的算法,对于tenured generation使用了新的算法(mark-summary-compact),该收集器用来替代parallel new collector和parallel old collector。
- concurrent mark-sweep collector :对于young generation使用和parallel new collector一样的算法,对于tenured generation使用跟应用程序并发的方式,收集期间也有引起stop-the-world的暂停Mark阶段,也有伴随着应用程序运行的并发 Mark和并发Sweep阶段,降低了应用程序暂停的时间。
可以看出这些垃圾收集器分为3种类型:串行,并行,并发;串行的就是单线程的,并行的就是多线程的,串行并行都是stop-the-world的,而并发是多线程的,但不完全是stop-the-world。
算法:
纵观垃圾收集器的算法思想,不外乎标记(Mark)、清扫(Sweep)、复制(Copy)、压缩(Compact)等几个基本的步骤。通过这篇文章总结一下目前所了解到的GC的一些基本算法。
引用计数(Reference Counting)
每个对象都有一个计数器,记录了指向该对象的引用数目。当创建了一个指向该对象的引用时,该对象的引用计数+1,反之,当该对象的某一个引用销毁时,引用计数-1。当对象的引用计数为0时,回收该对象占用的内存。
但是当存在循环引用时,就会出现漏网之鱼。因为循环引用内的对象的引用计数都不为0,如果从循环外面不可达,那么他们应该也是dead objects。
标记(Marking)
标记所有live objects(没标记的就是dead objects),标记过后就可以清扫heap,回收dead objects。
初始化一个root set作为开始标记的集合,root set包含全局变量,当前被调用方法的局部变量和参数等等;
对root set内的每一个对象进行标记。
标记时先检查该对象是否已经标记为live,如果已标记则返回;如果没有标记则标记为live。
然后对该对象所引用的所有对象递归调用上述标记过程。
伪代码如下:
foreach object in rootSet{
mark(object);
}
void mark(obj) {
if(isLive(obj)) {
return;
}
setLive(obj);
foreach object in referencesFrom(obj){
mark(object);
}
}
清扫(Sweep)
遍历堆中的对象,如果标记为live的,则清除标记,否则回收该对象占用的内存。
foreach object in heap{
if(isLive(object)) {
unmark(object);
} else {
free(object);
}
}
三色标记(Tri-colour marking)
三色标记算法分为四步:
1.创建三种集合,表示不同类型的对象集合,分别称为white set,grey set,black set。white set是进行内存回收的候选对象集
合,black set是没有引用white set中对象的对象集合,剩下的对象属于grey set,它们可能引用了white set中的对象,也可能没有引用white set中的对象。
2.从grey set中取出一个对象,将其直接引用的white set中的对象标记为grey(相当于移到了grey set中),将该对象标记为black(相当于移至black set中)。
3.重复2直至grey set为空。
4.当grey set为空时,所有white set中的对象就是不可达的对象,释放其占用的内存空间。
复制(Copying)
复制算法中堆分为old space和new space,对于old space中标记为live的对象,将其复制到new space,并在旧的对象中保存新对象的地址,然后遍历new space中的对象,将该对象中的引用指向其引用对象的新地址。
压缩(Compacting)
压缩算法将所有的live objects移至heap的一端,对于每一个live object,首先计算它在heap中的新地址,再将所有对该对象的引用指向新的地址,然后将该对象移至新的地址。
当然,垃圾收集器也在不断的改进中,这其中会改进现有算法,添加新的算法。
比如压缩算法中,如果在heap的底端附近有很小的dead object,按照简单的压缩算法,就可能会为了达到压缩的目的,而移动后面很多的live object,这样做显然是不值得的。所以,一个改进就是直接跳过。
再比如有些垃圾收集器运行过程中可能会进行多次对象的遍历,这就延长的垃圾收集的时间,所以如果在一两次遍历之中顺便汇总一下以后需要的信息,以避免在后续的处理中再次遍历heap。
在Java SE 6 update 14中引入了一种新的垃圾收集器G1(Garbage First),目前是体验版,据说在Java SE 7中会成为正式成员。
G1的目标是多线程并行收集,和应用程序并发进行,分代的,可压缩的,时间可预测的。
其中并行和并发,压缩都有前辈实现过。分代的实现跟以往不一样,年轻代和年老代不再明确划分,heap被分为很多区域(region),G1动态选 择垃圾多的区域作为下次GC的年轻代。对于可预测性,G1会通过预测GC时间来选测适量的区域进行GC,以便达到预期的GC时间设置。
性能调整:
GC的性能调整实在是一个很高深的问题,不仅需要对GC技术广度的了解,更需要深度的理解。我本人也仅仅实践过屈指可数的几次,如果要我来说一些指 导性的方案的话,也只怕是误人子弟。作此文章,权当是对自己所了解到的GC性能调整的总结,一方面做备忘之用,一方面作为需要之人的参考。
首先要说的是大部分情况下并不需要去做GC调整,除非出现内存溢出导致应用程序崩溃,或者应用程序由于GC暂停时间太长导致不好的用户体验,或者有其他的性能要求。
要进行性能调整,不妨先了解一下几个衡量GC性能的标准:
- Throughput:吞吐量,非GC时间(近似于应用程序执行时间)占总时间的比例,吞吐量越高说明花费在GC上的时间越少,系统的使用的效率越高;
- Garbage collection overahead:GC开销,GC时间占总时间比例,和吞吐量互补;
- Pause time:暂停时间,在GC时应用程序暂停执行的时间;
- Frequency of collection:GC频率;
- Footprint:这个概念我还没完全理解,官方说是“a measure of size, such as heap size.” 我的理解是,GC时所要遍历的内存空间的大小。footprint越小一定程度上说明GC性能越高;
- Promptness:灵敏度,表示从对象成为垃圾到该对象占用的内存被释放之间的时间,灵敏度越高(时间间隔越小)说明垃圾能够尽早的被收集,但同时也可能GC频率越高,需要权衡考虑。
满足一定的标准是我们做GC调整的最终目标,可以看出前3个测量标准是一致的,都属于GC暂停时间一类,这也是大部分GC调整所关心的测量标准。
为了能够观察到GC的执行情况,可以使用下面Java options
- -Xloggc:log/gc.log 打印GC信息到指定文件
- -XX:+PrintGCDetails 打印更详细的GC信息
- -XX:+PrintGCTimeStamps 打印GC时间戳,相对于应用程序启动的时间。
我觉得GC性能调整可以分为三个阶段:堆和代大小的调整、垃圾收集器的选择、进阶调整。
堆和代大小的调整
我们在调试应用程序时经常会出现OutOfMemory:PermGen space之类的错误,这就是因为服务器永久代设置太小引起的,通常通过增加永久代大小就可以减少甚至避免这类情况的出现。堆和代大小的调整可以通过下面一些参数来设置:
- –Xmsn heap的初始大小;
- –Xmxn heap的最大尺寸;
- –XX:NewSize=n 年轻代(Young Generation)的初始大小;
- –XX:NewRatio=n 表示年轻代和年老代的比率,例如n=3,表示年轻代大小和年老代大小之比是1:3;
- –XX:SurvivorRatio=n 表示survivor和eden空间的比率,如果n=8,表示每个survivor空间大小是年轻代的1/10,因为有2个survivor空间;
- -XX:PermSize=n 永久代(Permenent Generation)的初始大小;
- –XX:MaxPermSize=n 永久代的最大尺寸。
通过增加堆和代的大小可以减少GC的频率,但同时也会增加每次GC的时间及footprint。所以堆和代的大小不是越大越好(GC的性能调整会遇 到很多需要权衡利弊考虑的情况,需要找出折中方案)。具体方法可以通过模拟测试并观察gc log里的记录来设置,如果年轻代设置的太小,那么年轻代的GC就会很频繁,通过适当增加年轻代的大小,减少GC的频率。由于堆或代大小的扩展都会引起性 能的降低,所以设置一个合适的堆和代的初始大小,可以避免频繁的扩展,而这个合适的大小也可以通过gc log里的数据来推算,根据模拟测试中系统处于稳定时期的内存占用情况来设置。
垃圾收集器的选择
不同的垃圾收集器可以使用下面的参数来选择:
- –XX:+UseSerialGC
- –XX:+UseParallelGC
- –XX:+UseParallelOldGC
- –XX:+UseConcMarkSweepGC
如果程序运行在单CPU的机器上,没有多少性能要求,那就是用SerialGC;如果运行在多CPU的机器上,那就不妨使用Parallel和 ParallelOld来减少stop-the-world时间。利用多线程进行gc可以缩短gc时间,提高系统的吞吐量和相应速度。
进阶调整
除了上面的参数外,还可以通过一些参数来调整GC的行为。
- -XX:MaxTenuringThreshold=n 通过该参数可以设置存活对象在survivor spaces之间复制的次数,超过这个次数,对象就被移到tenured generation。通过这个参数可以保持tenured space的稳定性,避免一些寿命不是很长的对象占据该空间(当然,也可以适当增加young generation的大小,尽量让寿命不长的对象die在young generation);
- -XX:MaxHeapFreeRatio=70,-XX:MinHeapFreeRatio=40 设置堆的最大/最小空闲空间的比例,70%,40%是默认值,可以避免堆空间频繁的伸缩;
- -XX:+UseCMSCompactAtFullCollection,-XX:CMSFullGCsBeforeCompaction=n 在 使用–XX:+UseConcMarkSweepGC时有引起一定的内存碎片问题,可以通过UseCMSCompactAtFullCollection 在full gc之后进行压缩,CMSFullGCsBeforeCompaction=n表示,在进行n次full gc之后进行压缩,因为开始的一两次full gc引起的内存碎片可能并不是很多,这样可以减少压缩次数,提高gc效率。
当然,还有其他参数,这里只是比较常用的一部分。要想真正搞懂GC,实践是必不可少的,实践出真知,多多分析gc log,不断调整,才能理解如何进行GC性能的调整。
对于应用程序的性能来说,GC的调整是一部分,而代码的质量也是很重要的一部分,代码质量的高,就可以避免不必要的GC调整。比如减少不必要的对象 的创建,能在循环外new的对象放在循环外new,对象保存的上下文保持最小范围原则,在显示批量数据时不必要的字段信息不要获取,等等。在保证代码质量 的基础上,如果出现性能问题,再进行GC调整















 651
651

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









