






当你想读取文本文件的全部内容时,却发现容易出现奇怪的现象或者最后一行重复读取?细心看完这篇你就知道为什么了。
1.简单的例子:
文本文件"test.txt"内容如下:
123
只有"123"三个字符。现在我们用一个简单的程序把他输出。
#include <stdio.h>
#define TEST_FILE "test.txt"
int main(){
FILE *fp;
char ch;
fp=fopen(TEST_FILE,"r");
//重点
while(!feof(fp)){
ch=fgetc(fp); //当fgetc读取失败时,则ch=EOF
printf("%c ASCII: %d\n",ch,ch);
}
fclose(fp);
return 0;
}
输出结果为
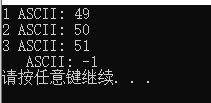
可以看到明明只有三个字符的文件却输出了四行!第四行ASCII码为-1的输出是什么呢?
而把ch=fgetc(fp)改为fscanf(fp,"%c",&ch)或fread(&ch,1,1,fp),此时第四次循环遇到EOF时不能读入有效字符,就会重复输出最后一个字符。(注意,fscanf和fread返回值为int类型,读不到有效字符并不会改变ch,所以和上述fgetc不同,ch不会发生变化)
2.feof介绍
函数feof可以测出文件位置标记是否已经指到文件末尾。文件结束:返回非0值,文件未结束,返回0值。
EOF又是什么呢
EOF是文本文件结束的标志。EOF 不是一个字符,也不是文件中实际存在的内容。当读取文件到字节为EOF时,读取文件才结束。
EOF16进制为0xFF(十进制为-1),即上文所问的-1输出就是EOF,文本文件中(即ASCII码文件)字符的ASCII码范围为32~127,与EOF不冲突;但是在二进制文件中,数据有可能出现0xFF(-1),因此不能用EOF作为二进制文件的结束标志,需通过feof来判断。
说EOF只能用于文本文件,其实不然,这点不是特别的准确,还要看定义的变量的类型。详细请见
在C语言中,feof()函数的使用是根据指针内容判断的,而非指针位置,无论指针是否到头,甚至超出了,它都需要先读取指针的内容,看一看内容是否是EOF,然后才知道文件到头了。 看到这里你应该能够知道上文例子中为什么会出现这个问题了,因为feof需要在第四次循环读出EOF之后,才知道文件结束了。
3.解决方法
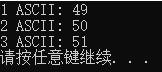
一个原则:先读再判断是否文件结束,即
ch=fgetc(fp);
while(!feof(fp)){
printf("%c ASCII: %d\n",ch,ch);
ch=fgetc(fp);
}
先读入,然后判断此时的指针位置是否合法,在合法的情况下输出上一次读入的值,然后在读取下一个。此次输出结果正常。
参考文章:
https://blog.csdn.net/lhyer/article/details/45012233














 3503
3503











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









