







Network in Network
本文是个人阅读论文Network In Network的论文笔记,重点取舍都只依据个人需求,不免难服重口。同时本人为入门小白,难免有理解错误之处,仅供参考,欢迎诚意讨论。
文章目录
解惑
1. 大网络套小网络的思想是怎么提出的?可以解决什么问题?怎么解决的?
卷积神经网络中通常用卷积层来提取抽象特征,卷积是一种线性计算,这种提取特征的模型称为Generalized Linear Model(GLM)。这种抽取特征的缺点是默认samples of the latent concepts是线性可分的时候,当samples of the latent concepts是非线性可分的时候,需要提取特征的函数也是非线性的,显然卷积操作不满足这个要求。因此论文提出可以借助一种非线性的micro network来代替卷积层进行特征抽取,论文中选择使用多层感知机(文中称为mlpconv)来代替卷积层,因为多层感知机本身也是一种神经网络,如此嵌套在网络中,就形成了NIN结构。因此:
- 大网络套小网络的思想是在“用非线性网络替代卷积操作来提取特征”的需求下提出来的。
- 可以解决线性的卷积操作不能出优质的非线性可分样本的优质特征的问题。
- 用非线性的神经网络代替线性的卷积层来解决这一问题。
2. 全局平均池化层是个啥?怎么做到的?有啥优势?
传统的卷积神经网络中卷积操作常位于网络的较低层位置,用于特征提取。全连接层负责将提取的特征和分类层连在一起,但是全连接层有严重的过拟合风险,要缓解这一风险通常需要借助随机失活操作(Dropout)。论文提出的全局平均池化层用于替代全连接层,对于分类任务,在最后一层mlpconv中为每一种分类都生成对应的特征图,这些特征图可以直接输入到后续的softmax层中进行分类操作。因此:
- 全局平均池化层是一种全连接层的替代层,相比于全连接层,没有过拟合的风险。
- 在最后一层mlpconv中产生每个分类对应的特征图。
- 主要有三点优势:
- 没有通过全连接层,特征图直接送入分类层,因此分类层得到的信息更加native。
- 平均池化层没有参数,因此不会带来过拟合风险。
- 平均池化层总结了空间信息,对于输入的空间扰动更加鲁棒。
- 有实验证明,平均池化层还有正则化的作用,相比“全连接+dropout”有更好的效果。
文章通读笔记
摘要
1. Introduction
传统卷积神经网络中的卷积核操作实际上是一种线性计算模型(Generalized Linear Model, GLM),这种线性计算提取特征的能力是比较弱的,本文提出用一种非线性的微型网络(micro network)来代替GLM提取特征,这种微型模型就是mlpconv,是一种多层感知机。整个NIN网络就是由这种微型网络堆叠而成的。
此外,本文摒弃全连接层,用全局平均池化层。有两点优势,一方面,在传统的卷积神经网络中,全连接层像个黑盒子一样,分类层的信息是如何反向传播到前层令人费解,而全局池化层强制将特征图和分类层的信息联系在一起。另一方面,全连接层很容易过拟合因此依赖随机失活正则化,全局平均池化本身具有正则化功能,能够确保整个网络发生过拟合。
2. Convolutional Neural Networks
卷积层通过线性的卷积计算和非线性函数的组合来产生特征图。对于线性可分的数据,只用卷积运算就可以提取到不错的特征,但是对于非线性可分的数据,就需要依靠激活函数来组合完成。虽然这一缺点可以借助“训练独立的”来克服,但是这样又增加了新的工作量。
本文提出的NIN网络在每层卷积层都引入微型网络,为local pathces计算更加抽象的特征。
3. Network In Network
3.1 MLP Convolution Layers
3.2 Global Average Pooling
全连接层更易产生过拟合。本文提出了全局平均池化层来代替全连接层,在最后一个mlpconv层为每一个类别都产生一个相应的特征图,将这个结果直接传送给softmax层。这样有三个好处:
- 相比于全连接层,全局平均池化直接将特征图和分类连接在一起,使得softmax能获得更原始的特征图信息。这样,特征图可以更容易得解读为置信度特征图(confidence maps)
- 全局平均池化层不引入参数,杜绝了过拟合情况的发生。
- 全局平均池化层总结了空间信息,对于输入信息的空间变化更加鲁棒。
3.3 Network In Network Structure
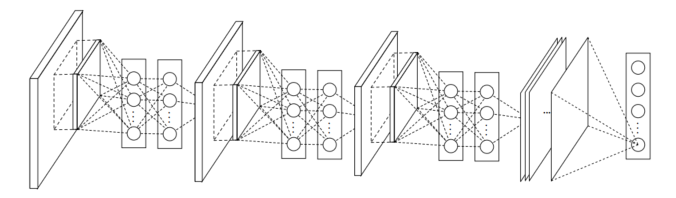
4. Experiments
新疑问
- “samples of the latent concepts是线性可分的”虾米意思?
- “全局平均池化层”的数学上的实现是什么样的?和全连接层有变换矩阵上的差别?














 501
501











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









