







1. 基础
1.1 向量空间
如果 V 满足向量的加法和乘法封闭性,我们就称 V 是 F 上的向量空间。
1.2 向量间的距离
- 曼哈顿距离
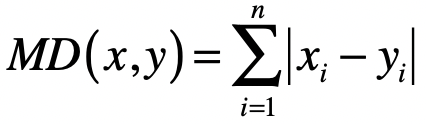
- 欧氏距离
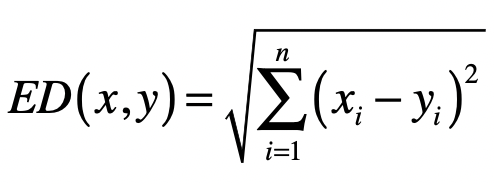
- 切比雪夫距离
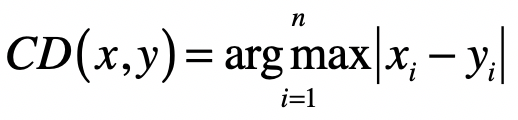
- 闵氏距离
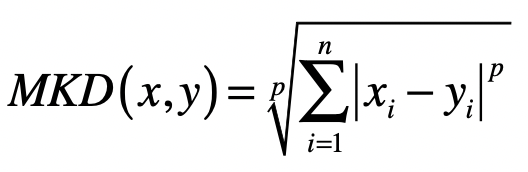
1.3 向量长度
L1 范数 ∣∣x∣∣ ,它是为 x 向量各个元素绝对值之和,对应于向量 x 和原点之间的曼哈顿距离。
L2 范数 ∣∣x∣∣2 ,它是 x 向量各个元素平方和的 1/2 次方,对应于向量 x 和原点之间的欧氏距离。
Lp 范数 ∣∣x∣∣p ,为 x 向量各个元素绝对值 p 次方和的 1/p 次方,对应于向量 x 和原点之间的闵氏距离。
L∞ 范数 ∣∣x∣∣∞,为 x 向量各个元素绝对值最大那个元素的绝对值,对应于向量 x 和原点之间的切比雪夫距离。
1.4 向量夹角的余弦
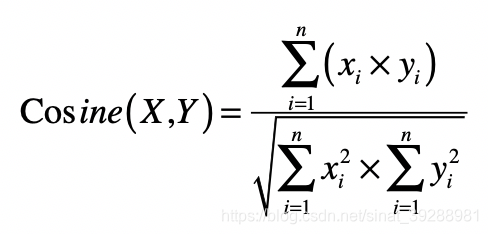
1.5 向量空间模型
向量空间模型假设所有的对象都可以转化为向量,然后使用向量间的距离(通常是欧氏距离)或者是向量间的夹角余弦来表示两个对象之间的相似程度。
2. 文本检索
(1) 文档转化为特征向量
首先,基于 BOW 方式对文档进行预处理,以获得文档的单词和词组。
①分词:
②停用词:
③同义词和扩展词:
然后,对所有文档的单词和词组去重,将唯一的单词或词组作为向量的一个维度。
最后,基于 tf-idf 方法为每个维度取值。
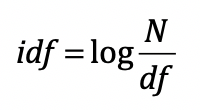
N 表示文档数量。文档频率 df 表示存在某个单词的文档数量。
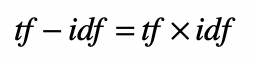
词频 tf 表示单词在文档中出现的次数。
(2) 用户查询转化为向量
(3) 基于向量空间模型计算查询向量与文档向量的相似度
(4) 排序














 1977
1977











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









