




 本文介绍XML文件的基础知识,包括格式特点及其在数据交互中的作用。详细讲解使用Python的ElementTree和DOM方式解析、写入及更新XML文件的方法,并演示如何在Python中实现XML与JSON文件的相互转换。
本文介绍XML文件的基础知识,包括格式特点及其在数据交互中的作用。详细讲解使用Python的ElementTree和DOM方式解析、写入及更新XML文件的方法,并演示如何在Python中实现XML与JSON文件的相互转换。
目录
2.2.2 使用DOM方式更新xml文件,向xml中插入子元素
活动地址:CSDN21天学习挑战赛
**
学习日记 Day5
**
1. XML文件简单介绍
XML,Extensible Markup Language,翻译为可扩展标记语言。
XML是互联网数据传输的重要工具,它可以跨越互联网任何的平台,不受编程语言和系统的限制。
XML处理结构化文档信息很方便,有助于在服务器之间穿梭结构化数据,开发人员可以更加方便的控制数据的存储和传输。
XML用于标记电子文件使其具有结构性的标记语言,可以用来标记数据、定义数据类型,是一种允许用户对自己的标记语言进行定义的源语言。XML是标准通用标记语言(SGML)的子集,非常事合Web传输。XML提供统一的方法来描述和交换独立于应用程序或供应商的结构化数据。
XML的特点:
- XML与编程语言的开发平台无关
- 实现不同系统之间的数据交互
XML的作用
- 配置应用程序和网站
- 数据交互
- Ajax基石
1.1 XML文件的格式
XML的具体规则如下:
- 区分大小写;
- 有且只有一个根元素;
- 属性值使用引号,i安逸使用双引号;
- 所有的标记必须有相应的结束标记;
- 所有的空标记也必须被关闭;
XML文件中包含声明、根元素、子元素、属性、命名空间、限定名六个部分。
XML可以有声明,也可以没有声明,如果有声明,那么它必须是XML文件的第一行,如下:
<?xml version="1.0" encoding=' "UTF-8" standalone=" no"?>如上声明有三部分:版本、编码和独立性。
版本指明了正在使用的XML标准的版本;
Encoding表示在该文件中使用的字符编码类型;
Standalone表示解析器是否要外部信息来解释XML文件的内容。
XML文件可以表示为XML树,XML树从根元素开始,根元素进一步分支到子元素。XML文件的每个元素都是XML树种的一个节点,那些没有子节点的元素是叶节点。
示例,有如下XML文档
<bookstore>
<book category="COOKING">
<title lang="en">Everyday Italian</title>
<author>Giada De Laurentiis</author>
<year>2005</year>
<price>30.00</price>
</book>
<book category="CHILDERN">
<title lang="en">Harry Potter</title>
<author>J K. Rowling</author>
<year>2005</year>
<price>29.99</price>
</book>
<book category="WEB">
<title lang="en">Learning XML</title>
<author>Erik T. Ray</author>
<year>2003</year>
<price>39.99</price>
</book>
</bookstore>在这个示例中,根元素是<bookstore>,<book>是根元素的子元素,<book>又有四个子元素:<title>、<author>、<year>、<price>。
2. python解析XML文件
2.1 ElementTree方式
ElementTree模块提供了一个轻量级、Python分割的API,同时还有一个高效的C语言实现,即xml.etree.cElementTree。与DOM相比,ET的速度更快,API使用更直接、方便,与SAX相比,ET.iterparse函数同样提供了按需解析的功能,不会一次性在内存中读入整个文档。ET的性能与SAX模块大致相仿,但是API更加高层次,用户使用起来更加便捷。
Element对象提供了如下方法:
| 类方法 | 说明 |
| Element.iter(tag=None) | 遍历该Element所有后代,也可以指定tag进行遍历寻找 |
| Element.iterfind(path,namespaces=None) | 根据tag或path查找所有后代 |
| Element.itertext() | 遍历所有后代并返回text值 |
| Element.findall(path) | 查找当前元素下tag或path能够匹配的直系节点 |
| Element.findtext(path,default=None, namespace=None) | 寻找第一个匹配子元素,返回其text值,匹配对象可以为tag或path |
| Element.find(path) | 查找当前元素下tag或path能够匹配的首个直系节点 |
| Element.text | 获取当前元素的text值 |
| Element.get(key,default=None) | 获取元素指定key对应的属性值,如果没有该属性,则返回default值 |
| Element.keys() | 返回元素属性名称列表 |
| Element.items() | 返回(name,value)列表 |
| Element.getchildren() | 获取当前元素的所有子元素,建议使用iter()代替,后续版本可能会移除该函数 |
| Element.getiterator(tag=None) | 同iter(),2.7和3.2版本之前没有iter(0,使用getiterator(),后续版本可能会移除 |
属性方法
- Element.tag 节点名 tag str
- Element.attrib 属性 attributes dict
- Element.text 文本 text str
- Element.tail 附加文本 tail str
- Element[:] 子节点列表 list
示例:有一个xml文档1.xml,使用ElementTree模块解析该文档
1.xml文档
<collection shelf="New Arrivals">
<class className="1班">
<code>2022001</code>
<number>10</number>
<teacher>小白</teacher>
</class>
<class className="2班">
<code>2022002</code>
<number>20</number>
<teacher>小红</teacher>
</class>
<class className="3班">
<code>2022003</code>
<number>30</number>
<teacher>小黑</teacher>
</class>
</collection>
python的ElementTree模块解析该文件
import xml.etree.ElementTree as ET
tree = ET.ElementTree(file="1.xml")
print("tree type is ",type(tree))
root = tree.getroot()
print("root type is ",type(root))
print("节点名 is ",root.tag) # 节点名
for index,child in enumerate(root):
print("第%s个%s元素,属性:%s"%(index,child.tag,child.attrib))
for i,child_child in enumerate(child):
print("\t标签:%s,内容:%s"%(child_child.tag,child_child.text))
显示结果:
tree type is <class 'xml.etree.ElementTree.ElementTree'>
root type is <class 'xml.etree.ElementTree.Element'>
节点名 is collection
第0个class元素,属性:{'className': '1班'}
标签:code,内容:2022001
标签:number,内容:10
标签:teacher,内容:小白
第1个class元素,属性:{'className': '2班'}
标签:code,内容:2022002
标签:number,内容:20
标签:teacher,内容:小红
第2个class元素,属性:{'className': '3班'}
标签:code,内容:2022003
标签:number,内容:30
标签:teacher,内容:小黑
2.2 DOM方式
DOM,Document Object Model,将XML文档作为一颗树状结构进行分析,获取节点的内容以及相关属性,或是新增、删除和修改节点的内容。XML解析器在加载XML文件以后,DQM模式将XML文件的元素视为一个树状结构的节点,一次性读入内存。
示例
# DOM方式解析XML文件
from xml.dom.minidom import parse
# 读取文件
dom = parse('1.xml')
# 获取文档元素对象
elem = dom.documentElement
# 获取class
class_list_obj = elem.getElementsByTagName('class')
print(type(class_list_obj))
for class_element in class_list_obj:
# 获取标签中的内容
code = class_element.getElementsByTagName('code')[0].childNodes[0].nodeValue
number = class_element.getElementsByTagName('number')[0].childNodes[0].nodeValue
teacher = class_element.getElementsByTagName('teacher')[0].childNodes[0].nodeValue
print("code: ",code,", number: ",number,", teacher: ",teacher)
显示结果:
<class 'xml.dom.minicompat.NodeList'>
code: 2022001 , number: 10 , teacher: 小白
code: 2022002 , number: 20 , teacher: 小红
code: 2022003 , number: 30 , teacher: 小黑
2.2.1 使用DOM方式写入XML文件
doc.writexml():生成xml文档,将创建的存在于内存中的xml文档写入本地硬盘中,这时才能看到新建的xml文档。
writexml()函数语法格式:
writexml(file,indent='',addindent='',newl='', encoding=None)- file:要保存为的文件对象名
- indent:根节点的缩进方式
- allindent:子节点的缩进方式
- newl:针对新行,指明换行方式
- encoding:保存文件的编码方式
使用示例,创建xml文件
# 创建一个xml文件
import xml.dom.minidom
# 1. 在内存中创建一个空的文档
doc = xml.dom.minidom.Document()
# 2. 创建根元素
root = doc.createElement("collection")
print("添加的xml标签为:",root.tagName)
# 3. 设置根元素的属性
root.setAttribute("type","New Arrivals")
root.appendChild(doc.createComment("type表示根元素的属性,New Arrivals表示根元素的属性值"))
# 4. 将根节点添加到文档对象中
doc.appendChild(root)
# 5. 创建子元素
book = doc.createElement('book')
# 6. 添加注释
book.appendChild(doc.createComment("这是一条注释1"))
# 7. 设置子元素的属性
book.setAttribute("语言","python")
# 8. 子元素中嵌套子元素,并添加文本节点
name = doc.createElement('name')
name.appendChild(doc.createTextNode("python基础"))
price = doc.createElement("价格")
price.appendChild(doc.createTextNode("¥99"))
number = doc.createElement("数量")
number.appendChild(doc.createTextNode("剩余100本"))
# 9. 将子元素添加到book节点中
book.appendChild(name)
book.appendChild(price)
book.appendChild(number)
# 10. 将book节点添加到root根元素
root.appendChild(book)
# 重复5/7/8/9/10,添加另一个根元素的子元素
# 5. 创建子元素
book = doc.createElement('book')
# 6. 添加注释
book.appendChild(doc.createComment("这是一条注释2"))
# 7. 设置子元素的属性
book.setAttribute("语言", "C/C++")
# 8. 子元素中嵌套子元素,并添加文本节点
name = doc.createElement('name')
name.appendChild(doc.createTextNode("C/C++基础"))
price = doc.createElement("价格")
price.appendChild(doc.createTextNode("¥199"))
number = doc.createElement("数量")
number.appendChild(doc.createTextNode("剩余110本"))
# 9. 将子元素添加到book节点中
book.appendChild(name)
book.appendChild(price)
book.appendChild(number)
# 10. 将book节点添加到root根元素
root.appendChild(book)
# 打印要写入的信息
print(root.toxml())
# 保存到xml文件
fp = open("books.xml", "w", encoding="utf-8")
doc.writexml(fp,indent='',addindent='\t',newl='\n',encoding='utf-8')
fp.close()运行后,在同目录下生成了books.xml文件,文件内容如下:
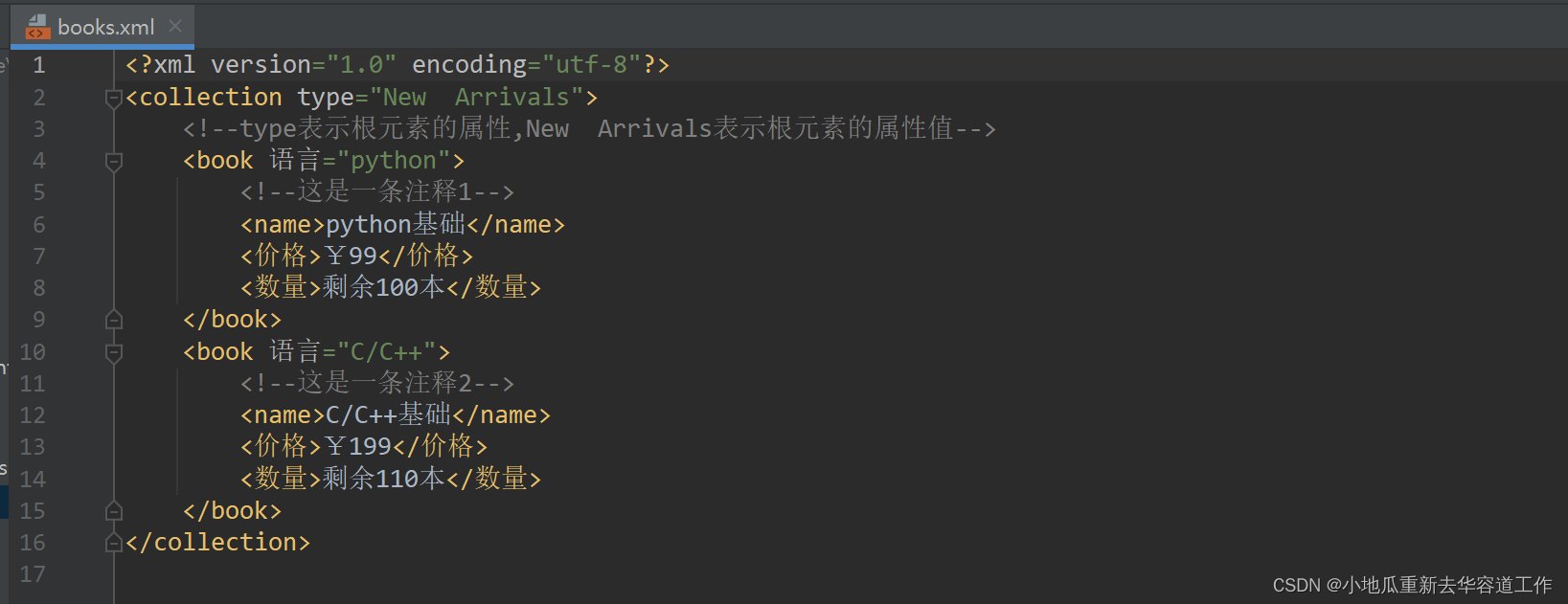
2.2.2 使用DOM方式更新xml文件,向xml中插入子元素
示例:
# 更新xml文件,向xml中添加新的子元素
import xml.dom.minidom
from xml.dom.minidom import parse
xml_file = "books.xml"
# 获取根节点
domTree = parse(xml_file) # 使用parse解析xml文件,获取到xml文件树
rootNode = domTree.documentElement # 获取到根节点的元素的迭代器
print(rootNode)
# rootNode.removeChild(rootNode.getElementsByTagName("book")[0]) # 移除第一个book子元素
# print(rootNode.toxml()) # 显示移除第一个book子元素的xml数据
# 在内存中创建空的文档
doc = xml.dom.minidom.Document()
# 创建元素 book
book = doc.createElement("book")
book.setAttribute("语言","JAVA")
# 元素book中嵌套子元素,并添加文本节点
name = doc.createElement("name")
name.appendChild(doc.createTextNode("JAVA基础"))
price = doc.createElement("价格")
price.appendChild(doc.createTextNode("¥200"))
number = doc.createElement("数量")
number.appendChild(doc.createTextNode("剩余300本"))
# 将元素添加到book
book.appendChild(name)
book.appendChild(price)
book.appendChild(number)
first_book = rootNode.getElementsByTagName("book")[0] # getElementsByTagName()按子元素的名字获取数据,
# insertBefore()使用方法: 父节点.insertBefore(新节点,父节点 中的子节点)
rootNode.insertBefore(book,first_book) # 将新节点插入到first_book前面
rootNode.appendChild(book) # 将新的元素在最后插入
print(rootNode.toxml())
# 把插入的节点更新到xml文件中
with open(xml_file,"w",encoding="utf-8") as fh:
domTree.writexml(fh,indent='', addindent='\t',newl='\n',encoding='utf-8')
显示结果:
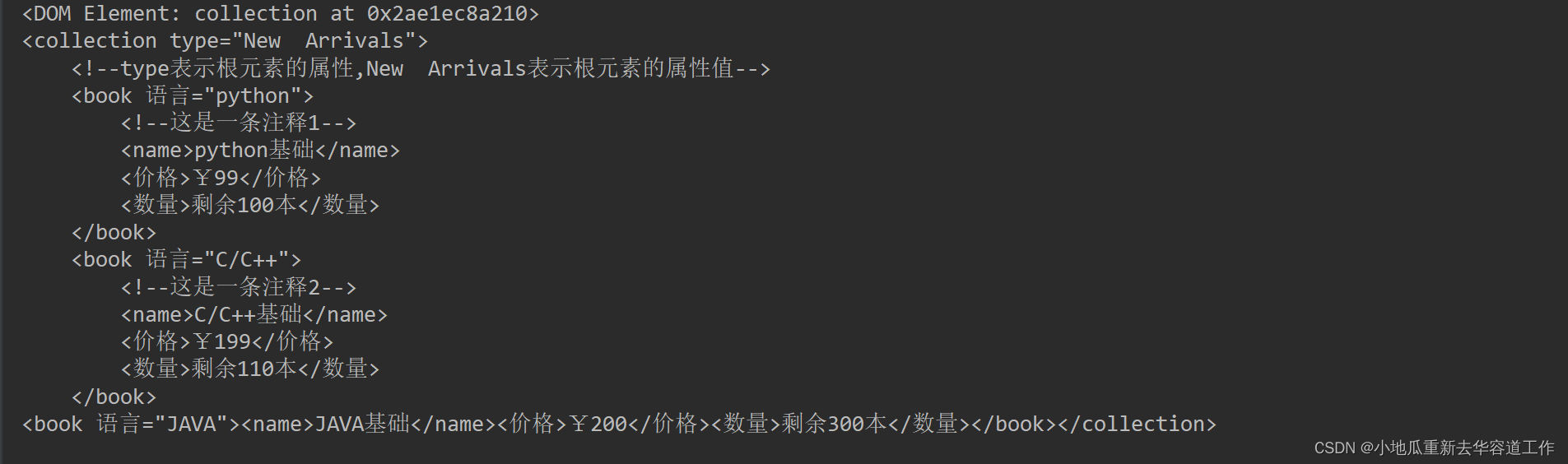
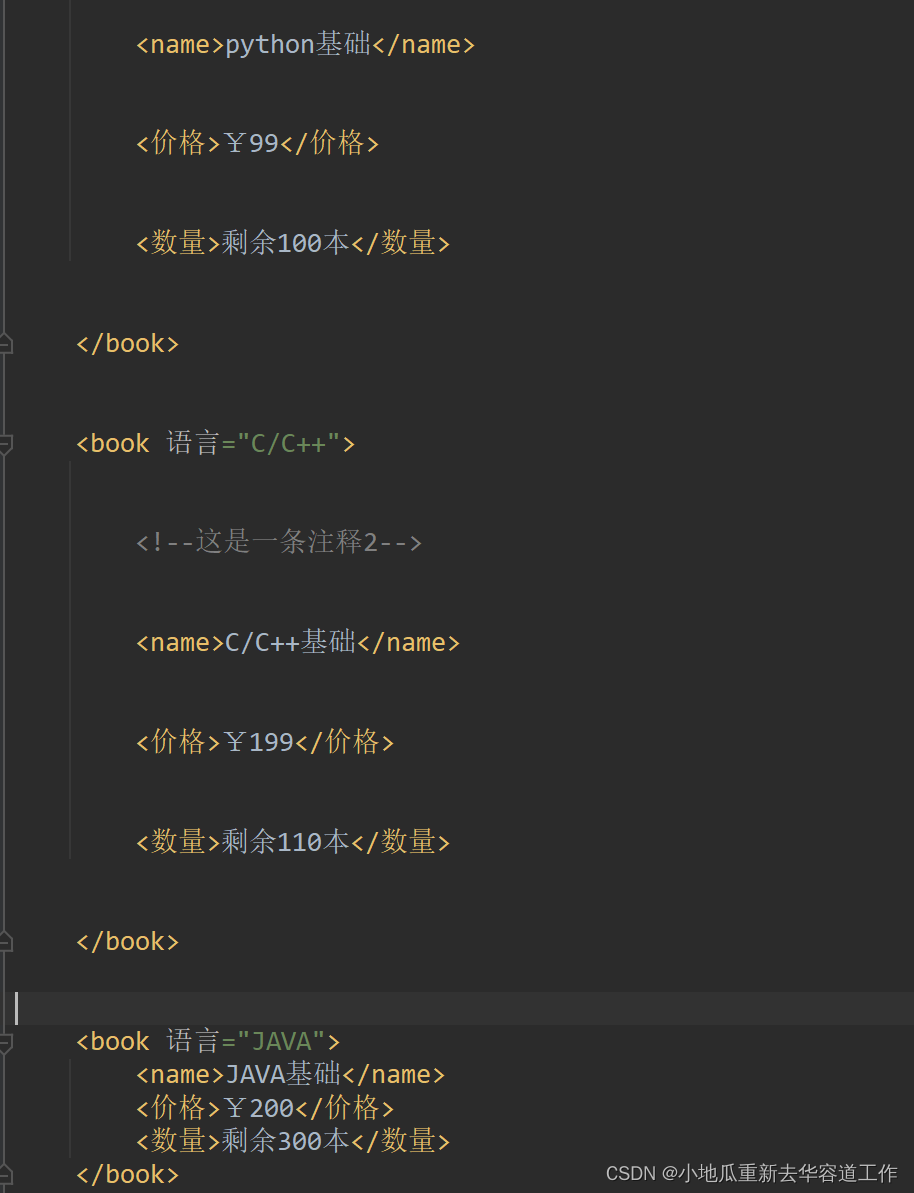
这里有一个问题,插入后生成的xml文件中,原来已经存在的内容会使用addindent,newl参数进行新的缩进,导致文件内容如下,具体原因还有待了解。
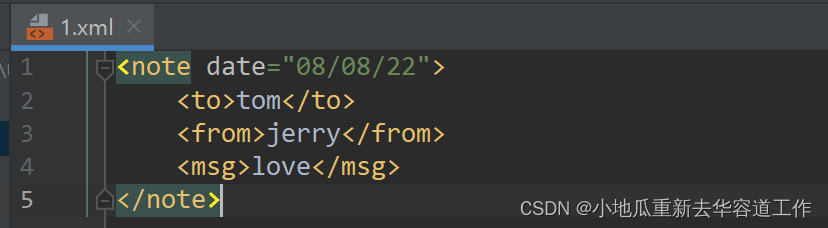
3. XML文件和JSON文件互转
3.1 XML文件转为JSON文件
xml文件如下:
代码实现XML转为JSON
# XML转为JSON
# 导入使用的模块 json模块,xmltodict模块
import json
import xmltodict
def xml_to_json(xml_str):
'''
xmltodict.parse()解析XML文件,需要参数xml字符串
:param xml_str: xml字符串
:return: json字符串
'''
xml_parse = xmltodict.parse(xml_str)
# json.dumps()把dict转换为json格式,loads()把json格式转换为dict格式
# 参数indent=1定义缩进
json_str = json.dumps(xml_parse,indent=1)
return json_str
xml_path = "./1.xml"
with open(xml_path,"r") as f:
xmlfile = f.read()
with open(xml_path[:-3]+'json','w') as newfile:
newfile.write(xml_to_json(xmlfile))
生成的json文件:
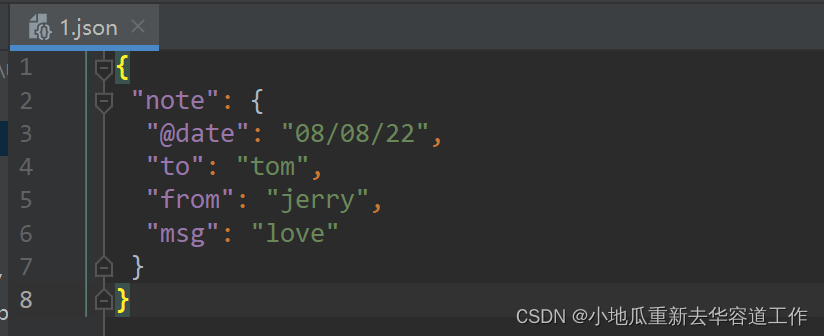
3.2 JSON文件转为XML文件
2.json文件如下: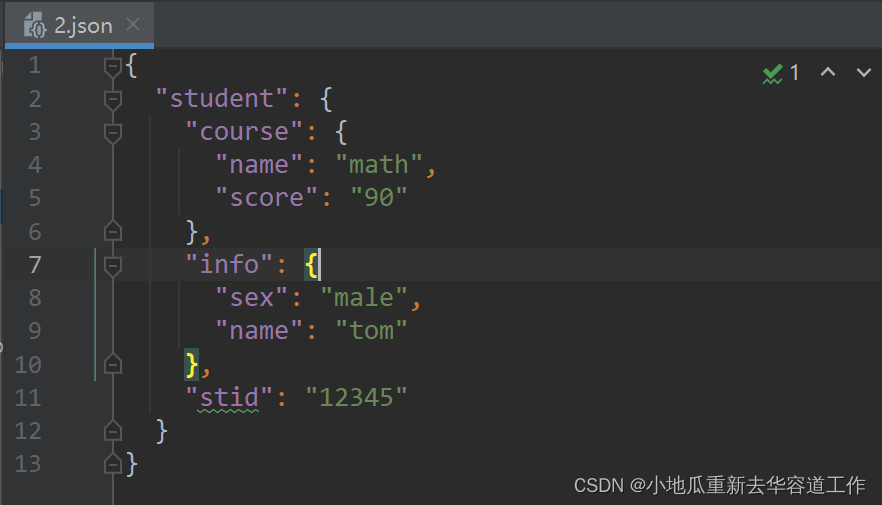
代码实现JSON转为XML
# JSON转为XML
import xmltodict
import json
def json_to_xml(python_dict):
'''
xmltodict.unparse()把json转为xml
:param python_dict: python的字典对象
:return: xml字符串
'''
xml_str = xmltodict.unparse(python_dict)
return xml_str
json_path = "./2.json"
with open(json_path,"r") as f:
jsonFile = f.read()
python_dict = json.loads(jsonFile) # 将json字符串转换为python字典对象
with open(json_path[:-4] + "xml","w") as newfile:
newfile.write(json_to_xml(python_dict))生成xml文件如下:


















 550
550

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









