










! ! 更新:增加了网页过滤判断,只允许域名包含blog,jianshu的网站通过
小技巧
- Java中InputStream和String之间的转换方法
String result = new BufferedReader(new InputStreamReader(inputStream))
.lines().collect(Collectors.joining(System.lineSeparator()));
运行效果
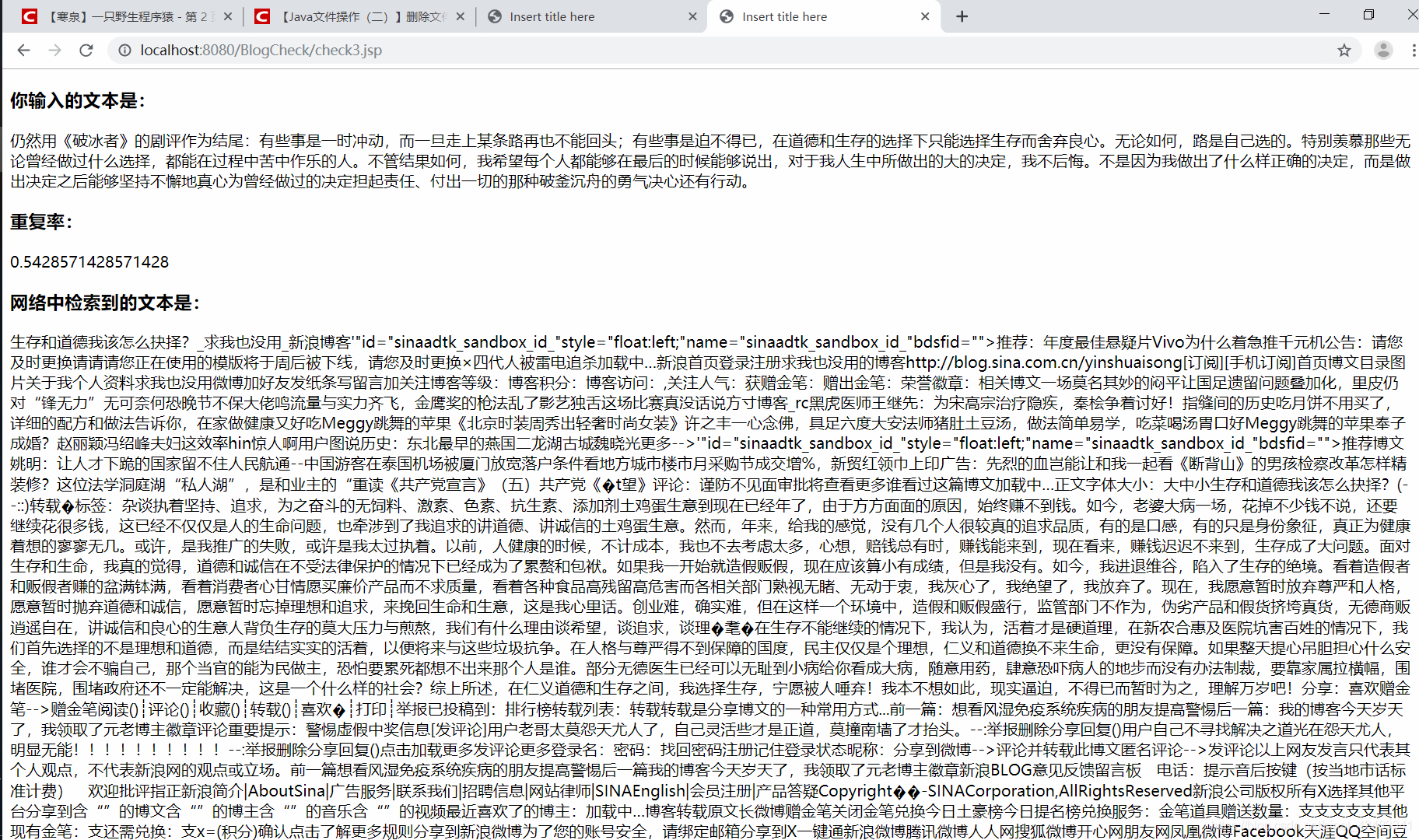
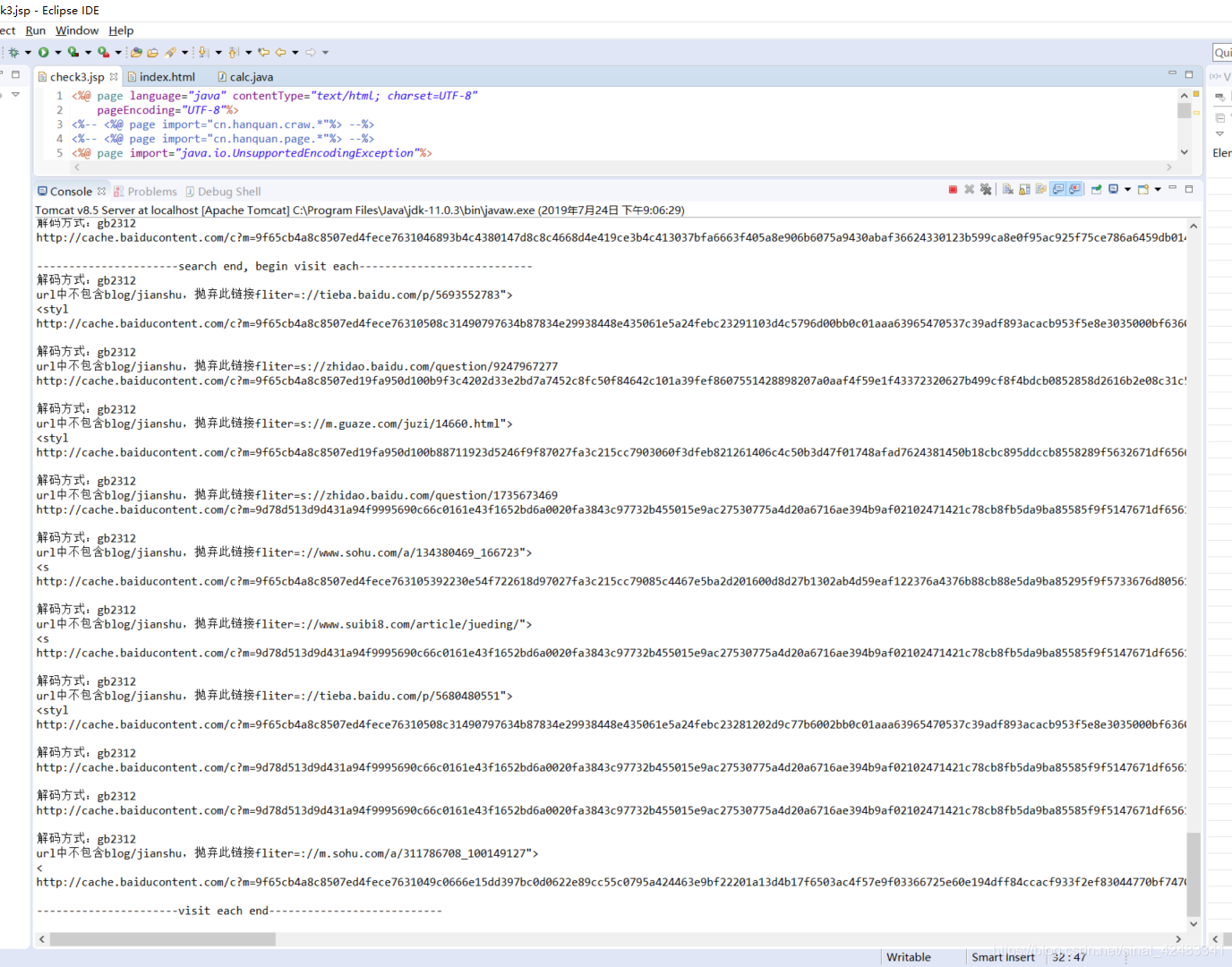
index.html
<!DOCTYPE html>
<html>
<head>
<meta charset="UTF-8">
<title>Insert title here</title>
</head>
<body>
<h3>请输入文本,点击“提交”查重</h3>
<form action="check2.jsp" method="post">
<textarea name="utext" rows="10" cols="50"></textarea>
<br>
<button>提交</button>
</form>
</body>
</html>
JSP代码
版本一:包含文件操作版本(数据通过txt传递)
check.jsp
<%@ page language="java" contentType="text/html; charset=UTF-8"
pageEncoding="UTF-8"%>
<%-- <%@ page import="cn.hanquan.craw.*"%> --%>
<%-- <%@ page import="cn.hanquan.page.*"%> --%>
<%@ page import="java.io.UnsupportedEncodingException"%>
<%@ page import="java.io.IOException"%>
<%@ page import="java.io.InputStream"%>
<%@ page import="java.io.UnsupportedEncodingException"%>
<%@ page import="java.net.HttpURLConnection"%>
<%@ page import="java.net.URL"%>
<%@ page import="java.io.BufferedReader"%>
<%@ page import="java.io.InputStreamReader"%>
<%@ page import="java.io.File"%>
<%@ page import="java.io.FileInputStream"%>
<%@ page import="java.io.FileOutputStream"%>
<%@ page import="java.io.FileWriter"%>
<%@ page import="java.io.IOException"%>
<%@ page import="java.io.InputStream"%>
<%@ page import="java.io.InputStreamReader"%>
<%@ page import="java.net.HttpURLConnection"%>
<%@ page import="java.net.MalformedURLException"%>
<%@ page import="java.net.URL"%>
<%@ page import="java.net.URLEncoder"%>
<%@ page import="java.util.Scanner"%>
<%@ page import="java.util.regex.Matcher"%>
<%@ page import="java.util.regex.Pattern"%>
<%@ page import="java.io.BufferedWriter"%>
<%@ page import="java.io.File"%>
<%@ page import="java.io.FileOutputStream"%>
<%@ page import="java.io.IOException"%>
<%@ page import="java.io.OutputStreamWriter"%>
<%@ page import="java.text.NumberFormat"%>
<%@ page import="java.util.Locale"%>
<!DOCTYPE html>
<html>
<head>
<meta charset="UTF-8">
<title>Insert title here</title>
</head>
<body>
<h3>你输入的文本是:</h3>
<%!public static String PATH = "C:/picture/";
//public static String PATH = "/home/pan/tomcat/webapps/BlogCheck/txtfile/";
/*--------------------------------------------craw.java--------------------------------------------*/
public static void craw(String mess) throws IOException {
try {
String smess = URLEncoder.encode(mess, "UTF-8");
String urll = "http://www.baidu.com/s?wd=" + smess;
URL url = new URL(urll);
InputStream input = url.openStream();
FileOutputStream fout = new FileOutputStream(new File(PATH + "FirstPage.html")); // 爬取百度搜索并保存成文件
int a = 0;
while (a > -1) {
a = input.read();
fout.write(a);
}
fout.close();
File file = new File(PATH + "FirstPage.html");
String pattern = "href=\"(http://cache.baiducontent.com/c\\?m=.+?)\".+$";// 正则匹配百度快照
String h3_pattern = "(a data-click)"; // 通过爬取的网页源码可以发现每个链接之前都有一个a data-click标签
Pattern pat = Pattern.compile(pattern);
Pattern h3_pat = Pattern.compile(h3_pattern);
InputStreamReader input1;
input1 = new InputStreamReader(new FileInputStream(file), "UTF-8");
Scanner scan = new Scanner(input1);
String str = null;
Matcher mach;
Matcher machh3;
int count = 0;
FileWriter fw = new FileWriter(PATH + "Result.txt"); // 提取其中的地址并保存成文件
boolean in = false;
while (scan.hasNextLine()) {
str = scan.nextLine();
machh3 = h3_pat.matcher(str); // 先看能不能匹配到h3 class标签,如果可以则进行匹配链接
while (machh3.find()) {
if (machh3.groupCount() > 0) {
in = true;
}
}
if (in) {
mach = pat.matcher(str); // 匹配链接
while (mach.find()) {
count++;
in = false;
// System.out.println(count + " " + mach.group(1));
fw.write(mach.group(1) + "\r\n");
}
}
}
fw.close();
System.out.println("----------------------search end, begin visit each---------------------------");
} catch (MalformedURLException e) {
e.printStackTrace();
}
}%>
<%!/*
* 读取链接对应的网页,返回字符串
*
* @param url the URL you want to get
* @return the HTML Script of your URL
* @throws IOException
*/
public static String get(String url) throws IOException {
// 解决编码问题
InputStream is = doGet(url);
String pageStr = inputStreamToString(is, "gb2312");// 百度快照 固定gb2312
System.out.println("解码方式:gb2312");
is.close();
return pageStr;
}
public static InputStream doGet(String urlstr) throws IOException {
URL url = new URL(urlstr);
HttpURLConnection conn = (HttpURLConnection) url.openConnection();
conn.setConnectTimeout(30000);// 设置相应超时时间
conn.setRequestProperty("User-Agent",
"Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/56.0.2924.87 Safari/537.36");
InputStream inputStream = conn.getInputStream();
return inputStream;
}
public static String inputStreamToString(InputStream is, String charset) throws IOException {
byte[] bytes = new byte[1024];
int byteLength = 0;
StringBuffer sb = new StringBuffer();
while ((byteLength = is.read(bytes)) != -1) {
sb.append(new String(bytes, 0, byteLength, charset));
}
return sb.toString();
}%>
<%!/**
* ReadFile 读取txt文件,返回字符串
*
* @param f txt完整文件名称路径
* @return txt中的内容
* @throws IOException
*/
public static String read(File f) throws IOException {
Long filelength = f.length();
byte[] filecontent = new byte[filelength.intValue()];
FileInputStream in = new FileInputStream(f);
in.read(filecontent);
in.close();
return new String(filecontent); // 这里可以设置编码,第二个参数
}
public static String readHTML(File f) throws IOException {
StringBuilder sb = new StringBuilder();
FileInputStream fis = new FileInputStream(f);
InputStreamReader reader = new InputStreamReader(fis, "UTF-8"); // 最后的"GBK"根据文件属性而定,如果不行,改成"UTF-8"试试
BufferedReader br = new BufferedReader(reader);
String line;
while ((line = br.readLine()) != null) {
sb.append(line);
}
br.close();
reader.close();
return sb.toString();
}%>
<%!//正则筛选字符串
public static String regEx(String str) {
if (str.length() == 0)
return "";
String htmlStr = str; // 含html标签的字符串
//获取真实地址 过滤博客
String fliter;
int i1 = str.indexOf("href") > 0 ? str.indexOf("href") : 100000;
int i2 = str.indexOf("HREF") > 0 ? str.indexOf("HREF") : 100000;
int index = i1 <= i2 ? i1 : i2;
if (index > 0 && index < 200) {
fliter = str.substring(index + 10, index + 50);
if (fliter.indexOf("blog") < 0 && fliter.indexOf("jianshu") < 0) {
System.out.println("url中不包含blog/jianshu,抛弃此链接" + "fliter=" + fliter);
return "";
}
} else {
System.out.println("找不到源链接,无法判断是否过滤" + str.substring(0, 200));
return "";
}
String textStr = "";
java.util.regex.Pattern p_script;
java.util.regex.Matcher m_script;
java.util.regex.Pattern p_style;
java.util.regex.Matcher m_style;
java.util.regex.Pattern p_html;
java.util.regex.Matcher m_html;
try {
String regEx_script = "<[\\s]*?script[^>]*?>[\\s\\S]*?<[\\s]*?\\/[\\s]*?script[\\s]*?>"; // 定义script的正则表达式{或<script[^>]*?>[\\s\\S]*?<\\/script>
String regEx_style = "<[\\s]*?style[^>]*?>[\\s\\S]*?<[\\s]*?\\/[\\s]*?style[\\s]*?>"; // 定义style的正则表达式{或<style[^>]*?>[\\s\\S]*?<\\/style>
String regEx_html = "<[^>]+>"; // 定义HTML标签的正则表达式
p_script = Pattern.compile(regEx_script, Pattern.CASE_INSENSITIVE);
m_script = p_script.matcher(htmlStr);
htmlStr = m_script.replaceAll(""); // 过滤script标签
p_style = Pattern.compile(regEx_style, Pattern.CASE_INSENSITIVE);
m_style = p_style.matcher(htmlStr);
htmlStr = m_style.replaceAll(""); // 过滤style标签
p_html = Pattern.compile(regEx_html, Pattern.CASE_INSENSITIVE);
m_html = p_html.matcher(htmlStr);
htmlStr = m_html.replaceAll(""); // 过滤html标签
textStr = htmlStr;
} catch (Exception e) {
System.err.println("Html2Text: " + e.getMessage());
}
// 剔除空格行
textStr = textStr.replaceAll("[ ]+", "");
textStr = textStr.replaceAll("1", "").replaceAll("2", "").replaceAll("3", "").replaceAll("4", "")
.replaceAll("5", "").replaceAll("6", "").replaceAll("7", "").replaceAll("8", "").replaceAll("9", "")
.replaceAll("0", "");
textStr = textStr.replaceAll("(?m)^\\s*$(\\n|\\r\\n)", "");
textStr = textStr.replaceAll("\t", "");
textStr = textStr.replaceAll(" ", "").replace(">", "").replace("—", "").replace("<", "")
.replace(""", "");
textStr = textStr.replaceAll("\\\\", "");// 正则表达式中匹配一个反斜杠要用四个反斜杠
textStr = textStr.replaceAll("\r\n", "");
textStr = textStr.replaceAll("\n", "");
textStr = textStr.substring(textStr.indexOf("不代表被搜索网站的即时页面") + 14, textStr.length() - 1);
return textStr;// 返回文本字符串
}%>
<%!//保存到文件
public static void save(File f, String str) throws IOException {
BufferedWriter w = new BufferedWriter(new OutputStreamWriter(new FileOutputStream(f, false), "UTF-8"));
w.write(str);
w.close();
}%>
<%!public static String getRatio(String utextout) throws IOException {
StringBuilder allStr = new StringBuilder();
if (utextout.length() < 60) {// 输入过少的情况
utextout = utextout.substring(0, utextout.length() > 20 ? 20 : utextout.length());
craw(utextout);// 搜索字符串
String allUrl = read(new File(PATH + "Result.txt"));// 结果页链接
String[] urls = allUrl.split("\r\n");// 跨平台的时候注意一下\r\n
for (String u : urls) {
String htmlStr = get(u);// 获取html代码
String str = regEx(htmlStr);// 正则
System.out.println(u + "\n");
//System.out.println(str);
allStr.append(str + "\n\n\n\n\n");// 追加
}
save(new File(PATH + "2.txt"), allStr.toString());// 存储
} else {
// 20个字查一次 全部结果保存
for (int i = 0; i + 51 < utextout.length(); i += 50) {
String split = utextout.substring(i, i + 20);
craw(split);// 搜索字符串
String allUrl = read(new File(PATH + "Result.txt"));// 结果页链接
String[] urls = allUrl.split("\r\n");// 跨平台的时候注意一下\r\n
for (String u : urls) {
String htmlStr = get(u);// 获取html代码
String str = regEx(htmlStr);// 正则
System.out.println(u + "\n");
//System.out.println(str);
allStr.append(str + "\n");// 追加
}
save(new File(PATH + "2.txt"), allStr.toString());// 存储
}
}
System.out.println("----------------------visit each end---------------------------");
return allStr.toString();
}%>
<%!//计算查重率
public static double calcSame(String AA, String BB) {
String temp_strA = AA;
String temp_strB = BB;
String strA, strB;
// 如果两个textarea都不为空且都不全为符号,则进行相似度计算,否则提示用户进行输入数据或选择文件
if (!(behind.removeSign(temp_strA).length() == 0 && behind.removeSign(temp_strB).length() == 0)) {
if (temp_strA.length() >= temp_strB.length()) {
strA = temp_strA;
strB = temp_strB;
} else {
strA = temp_strB;
strB = temp_strA;
}
double result = behind.SimilarDegree(strA, strB);
return result;
}
return -1;
}
static class behind {
/*
* 计算相似度
*/
public static double SimilarDegree(String strA, String strB) {
String newStrA = removeSign(strA);
String newStrB = removeSign(strB);
// 用较大的字符串长度作为分母,相似子串作为分子计算出字串相似度
int temp = newStrB.length();
int temp2 = longestCommonSubstring(newStrA, newStrB).length();
return temp2 * 1.0 / temp;
}
/*
* 将字符串的所有数据依次写成一行
*/
public static String removeSign(String str) {
StringBuffer sb = new StringBuffer();
// 遍历字符串str,如果是汉字数字或字母,则追加到ab上面
for (char item : str.toCharArray())
if (charReg(item)) {
sb.append(item);
}
return sb.toString();
}
/*
* 判断字符是否为汉字,数字和字母, 因为对符号进行相似度比较没有实际意义,故符号不加入考虑范围。
*/
public static boolean charReg(char charValue) {
return (charValue >= 0x4E00 && charValue <= 0X9FA5) || (charValue >= 'a' && charValue <= 'z')
|| (charValue >= 'A' && charValue <= 'Z') || (charValue >= '0' && charValue <= '9');
}
/*
* 求公共子串,采用动态规划算法。 其不要求所求得的字符在所给的字符串中是连续的。
*/
public static String longestCommonSubstring(String strA, String strB) {
char[] chars_strA = strA.toCharArray();
char[] chars_strB = strB.toCharArray();
int m = chars_strA.length;
int n = chars_strB.length;
/*
* 初始化矩阵数据,matrix[0][0]的值为0,
* 如果字符数组chars_strA和chars_strB的对应位相同,则matrix[i][j]的值为左上角的值加1,
* 否则,matrix[i][j]的值等于左上方最近两个位置的较大值, 矩阵中其余各点的值为0.
*/
int[][] matrix = new int[m + 1][n + 1];
for (int i = 1; i <= m; i++) {
for (int j = 1; j <= n; j++) {
if (chars_strA[i - 1] == chars_strB[j - 1])
matrix[i][j] = matrix[i - 1][j - 1] + 1;
else
matrix[i][j] = Math.max(matrix[i][j - 1], matrix[i - 1][j]);
}
}
/*
* 矩阵中,如果matrix[m][n]的值不等于matrix[m-1][n]的值也不等于matrix[m][n-1]的值,
* 则matrix[m][n]对应的字符为相似字符元,并将其存入result数组中。
*
*/
char[] result = new char[matrix[m][n]];
int currentIndex = result.length - 1;
while (matrix[m][n] != 0) {
if (matrix[n] == matrix[n - 1])
n--;
else if (matrix[m][n] == matrix[m - 1][n])
m--;
else {
result[currentIndex] = chars_strA[m - 1];
currentIndex--;
n--;
m--;
}
}
return new String(result);
}
/*
* 结果转换成百分比形式
*/
public static String similarityResult(double resule) {
return NumberFormat.getPercentInstance(new Locale("en ", "US ")).format(resule);
}
}%>
<%
String utext = request.getParameter("utext");
String utextout = new String(utext.getBytes("iso-8859-1"), "utf-8");//解决乱码
out.print(utextout);
String allStr = getRatio(utextout);
double sameRatio = calcSame(utextout, allStr);
out.print("<h3>重复率:</h3>" + sameRatio);
out.print("<h3>网络中检索到的文本是:</h3>" + allStr);
%>
</body>
</html>
版本二:不包含文件操作,数据全部存在内存中
<%@ page language="java" contentType="text/html; charset=UTF-8"
pageEncoding="UTF-8"%>
<%-- <%@ page import="cn.hanquan.craw.*"%> --%>
<%-- <%@ page import="cn.hanquan.page.*"%> --%>
<%@ page import="java.io.UnsupportedEncodingException"%>
<%@ page import="java.io.IOException"%>
<%@ page import="java.io.InputStream"%>
<%@ page import="java.io.UnsupportedEncodingException"%>
<%@ page import="java.net.HttpURLConnection"%>
<%@ page import="java.net.URL"%>
<%@ page import="java.io.BufferedReader"%>
<%@ page import="java.io.InputStreamReader"%>
<%@ page import="java.io.File"%>
<%@ page import="java.io.FileInputStream"%>
<%@ page import="java.io.FileOutputStream"%>
<%@ page import="java.io.FileWriter"%>
<%@ page import="java.io.IOException"%>
<%@ page import="java.io.InputStream"%>
<%@ page import="java.io.InputStreamReader"%>
<%@ page import="java.net.HttpURLConnection"%>
<%@ page import="java.net.MalformedURLException"%>
<%@ page import="java.net.URL"%>
<%@ page import="java.net.URLEncoder"%>
<%@ page import="java.util.Scanner"%>
<%@ page import="java.util.regex.Matcher"%>
<%@ page import="java.util.regex.Pattern"%>
<%@ page import="java.io.BufferedWriter"%>
<%@ page import="java.io.File"%>
<%@ page import="java.io.FileOutputStream"%>
<%@ page import="java.io.IOException"%>
<%@ page import="java.io.OutputStreamWriter"%>
<%@ page import="java.text.NumberFormat"%>
<%@ page import="java.util.Locale"%>
<%@ page import="java.util.stream.Collectors"%>
<!DOCTYPE html>
<html>
<head>
<meta charset="UTF-8">
<title>Insert title here</title>
</head>
<body>
<h3>你输入的文本是:</h3>
<%!//public static String PATH = "C:/picture/";
//public static String PATH = "/home/pan/tomcat/webapps/BlogCheck/txtfile/";
/*--------------------------------------------craw.java--------------------------------------------*/
public static String craw(String mess) throws IOException {
String smess = URLEncoder.encode(mess, "UTF-8");
String urll = "http://www.baidu.com/s?wd=" + smess;
URL url = new URL(urll);
InputStream input = url.openStream();
//InputStream转化为String
String sb = new BufferedReader(new InputStreamReader(input)).lines()
.collect(Collectors.joining(System.lineSeparator()));
System.out.println("strhtml" + sb.toString());
String pattern = "href=\"(http://cache.baiducontent.com/c\\?m=.+?)\".+$";// 正则匹配百度快照
String h3_pattern = "(a data-click)"; // 每个链接之前都有一个a data-click标签
Pattern pat = Pattern.compile(pattern);
Pattern h3_pat = Pattern.compile(h3_pattern);
InputStreamReader input1;
String[] sbArr = sb.toString().split("\n");
Matcher mach;
Matcher machh3;
StringBuilder result = new StringBuilder();
boolean in = false;
for (String str : sbArr) {
machh3 = h3_pat.matcher(str); // 先看能不能匹配到h3 class标签,如果可以则进行匹配链接
while (machh3.find()) {
if (machh3.groupCount() > 0) {
in = true;
}
}
if (in) {
mach = pat.matcher(str); // 匹配链接
while (mach.find()) {
in = false;
System.out.println("结果" + mach.group(1));
result.append(mach.group(1) + "\n");
}
}
}
System.out.println("----------------------search end, begin visit each---------------------------");
return result.toString();
}%>
<%!/*
* 读取链接对应的网页,返回字符串
*
* @param url the URL you want to get
* @return the HTML Script of your URL
* @throws IOException
*/
public static String get(String url) throws IOException {
// 解决编码问题
InputStream is = doGet(url);
String pageStr = inputStreamToString(is, "gb2312");// 百度快照 固定gb2312
System.out.println("解码方式:gb2312");
is.close();
return pageStr;
}
public static InputStream doGet(String urlstr) throws IOException {
URL url = new URL(urlstr);
HttpURLConnection conn = (HttpURLConnection) url.openConnection();
conn.setConnectTimeout(30000);// 设置相应超时时间
conn.setRequestProperty("User-Agent",
"Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/56.0.2924.87 Safari/537.36");
InputStream inputStream = conn.getInputStream();
return inputStream;
}
public static String inputStreamToString(InputStream is, String charset) throws IOException {
byte[] bytes = new byte[1024];
int byteLength = 0;
StringBuffer sb = new StringBuffer();
while ((byteLength = is.read(bytes)) != -1) {
sb.append(new String(bytes, 0, byteLength, charset));
}
return sb.toString();
}%>
<%!/**
* ReadFile 读取txt文件,返回字符串
*
* @param f txt完整文件名称路径
* @return txt中的内容
* @throws IOException
*/
public static String read(File f) throws IOException {
Long filelength = f.length();
byte[] filecontent = new byte[filelength.intValue()];
FileInputStream in = new FileInputStream(f);
in.read(filecontent);
in.close();
return new String(filecontent); // 这里可以设置编码,第二个参数
}
public static String readHTML(File f) throws IOException {
StringBuilder sb = new StringBuilder();
FileInputStream fis = new FileInputStream(f);
InputStreamReader reader = new InputStreamReader(fis, "UTF-8"); // 最后的"GBK"根据文件属性而定,如果不行,改成"UTF-8"试试
BufferedReader br = new BufferedReader(reader);
String line;
while ((line = br.readLine()) != null) {
sb.append(line);
}
br.close();
reader.close();
return sb.toString();
}%>
<%!//正则筛选字符串
public static String regEx(String str) {
if (str.length() == 0)
return "";
String htmlStr = str; // 含html标签的字符串
//获取真实地址 过滤博客
String fliter;
int i1 = str.indexOf("href") > 0 ? str.indexOf("href") : 100000;
int i2 = str.indexOf("HREF") > 0 ? str.indexOf("HREF") : 100000;
int index = i1 <= i2 ? i1 : i2;
if (index > 0 && index < 200) {
fliter = str.substring(index + 10, index + 50);
if (fliter.indexOf("blog") < 0 && fliter.indexOf("jianshu") < 0) {
System.out.println("url中不包含blog/jianshu,抛弃此链接" + "fliter=" + fliter);
return "";
}
} else {
System.out.println("找不到源链接,无法判断是否过滤" + str.substring(0, 200));
return "";
}
String textStr = "";
java.util.regex.Pattern p_script;
java.util.regex.Matcher m_script;
java.util.regex.Pattern p_style;
java.util.regex.Matcher m_style;
java.util.regex.Pattern p_html;
java.util.regex.Matcher m_html;
try {
String regEx_script = "<[\\s]*?script[^>]*?>[\\s\\S]*?<[\\s]*?\\/[\\s]*?script[\\s]*?>"; // 定义script的正则表达式{或<script[^>]*?>[\\s\\S]*?<\\/script>
String regEx_style = "<[\\s]*?style[^>]*?>[\\s\\S]*?<[\\s]*?\\/[\\s]*?style[\\s]*?>"; // 定义style的正则表达式{或<style[^>]*?>[\\s\\S]*?<\\/style>
String regEx_html = "<[^>]+>"; // 定义HTML标签的正则表达式
p_script = Pattern.compile(regEx_script, Pattern.CASE_INSENSITIVE);
m_script = p_script.matcher(htmlStr);
htmlStr = m_script.replaceAll(""); // 过滤script标签
p_style = Pattern.compile(regEx_style, Pattern.CASE_INSENSITIVE);
m_style = p_style.matcher(htmlStr);
htmlStr = m_style.replaceAll(""); // 过滤style标签
p_html = Pattern.compile(regEx_html, Pattern.CASE_INSENSITIVE);
m_html = p_html.matcher(htmlStr);
htmlStr = m_html.replaceAll(""); // 过滤html标签
textStr = htmlStr;
} catch (Exception e) {
System.err.println("Html2Text: " + e.getMessage());
}
// 剔除空格行
textStr = textStr.replaceAll("[ ]+", "");
textStr = textStr.replaceAll("1", "").replaceAll("2", "").replaceAll("3", "").replaceAll("4", "")
.replaceAll("5", "").replaceAll("6", "").replaceAll("7", "").replaceAll("8", "").replaceAll("9", "")
.replaceAll("0", "");
textStr = textStr.replaceAll("(?m)^\\s*$(\\n|\\r\\n)", "");
textStr = textStr.replaceAll("\t", "");
textStr = textStr.replaceAll(" ", "").replace(">", "").replace("—", "").replace("<", "")
.replace(""", "");
textStr = textStr.replaceAll("\\\\", "");// 正则表达式中匹配一个反斜杠要用四个反斜杠
textStr = textStr.replaceAll("\r\n", "");
textStr = textStr.replaceAll("\n", "");
textStr = textStr.substring(textStr.indexOf("不代表被搜索网站的即时页面") + 14, textStr.length() - 1);
return textStr;// 返回文本字符串
}%>
<%!//保存到文件
public static void save(File f, String str) throws IOException {
BufferedWriter w = new BufferedWriter(new OutputStreamWriter(new FileOutputStream(f, false), "UTF-8"));
w.write(str);
w.close();
}%>
<%!public static String getRatio(String utextout) throws IOException {
StringBuilder allStr = new StringBuilder();
String result = craw(utextout);// 搜索字符串
String[] urls = result.split("\n");// 跨平台的时候注意一下\r\n
if (utextout.length() < 60) {// 输入过少的情况
utextout = utextout.substring(0, utextout.length() > 20 ? 20 : utextout.length());
for (String u : urls) {
String htmlStr = get(u);// 获取html代码
String str = regEx(htmlStr);// 正则
System.out.println(u + "\n");
//System.out.println(str);
allStr.append(str + "\n\n\n\n\n");// 追加
}
//save(new File(PATH + "2.txt"), allStr.toString());// 存储
} else {
// 20个字查一次 全部结果保存
for (int i = 0; i + 51 < utextout.length(); i += 50) {
String split = utextout.substring(i, i + 20);
craw(split);// 搜索字符串
for (String u : urls) {
String htmlStr = get(u);// 获取html代码
String str = regEx(htmlStr);// 正则
System.out.println(u + "\n");
//System.out.println(str);
allStr.append(str + "\n");// 追加
}
//save(new File(PATH + "2.txt"), allStr.toString());// 存储
}
}
System.out.println("----------------------visit each end---------------------------");
return allStr.toString();
}%>
<%!//计算查重率
public static double calcSame(String AA, String BB) {
String temp_strA = AA;
String temp_strB = BB;
String strA, strB;
// 如果两个textarea都不为空且都不全为符号,则进行相似度计算,否则提示用户进行输入数据或选择文件
if (!(behind.removeSign(temp_strA).length() == 0 && behind.removeSign(temp_strB).length() == 0)) {
if (temp_strA.length() >= temp_strB.length()) {
strA = temp_strA;
strB = temp_strB;
} else {
strA = temp_strB;
strB = temp_strA;
}
double result = behind.SimilarDegree(strA, strB);
return result;
}
return -1;
}
static class behind {
/*
* 计算相似度
*/
public static double SimilarDegree(String strA, String strB) {
String newStrA = removeSign(strA);
String newStrB = removeSign(strB);
// 用较大的字符串长度作为分母,相似子串作为分子计算出字串相似度
int temp = newStrB.length();
int temp2 = longestCommonSubstring(newStrA, newStrB).length();
return temp2 * 1.0 / temp;
}
/*
* 将字符串的所有数据依次写成一行
*/
public static String removeSign(String str) {
StringBuffer sb = new StringBuffer();
// 遍历字符串str,如果是汉字数字或字母,则追加到ab上面
for (char item : str.toCharArray())
if (charReg(item)) {
sb.append(item);
}
return sb.toString();
}
/*
* 判断字符是否为汉字,数字和字母, 因为对符号进行相似度比较没有实际意义,故符号不加入考虑范围。
*/
public static boolean charReg(char charValue) {
return (charValue >= 0x4E00 && charValue <= 0X9FA5) || (charValue >= 'a' && charValue <= 'z')
|| (charValue >= 'A' && charValue <= 'Z') || (charValue >= '0' && charValue <= '9');
}
/*
* 求公共子串,采用动态规划算法。 其不要求所求得的字符在所给的字符串中是连续的。
*/
public static String longestCommonSubstring(String strA, String strB) {
char[] chars_strA = strA.toCharArray();
char[] chars_strB = strB.toCharArray();
int m = chars_strA.length;
int n = chars_strB.length;
/*
* 初始化矩阵数据,matrix[0][0]的值为0,
* 如果字符数组chars_strA和chars_strB的对应位相同,则matrix[i][j]的值为左上角的值加1,
* 否则,matrix[i][j]的值等于左上方最近两个位置的较大值, 矩阵中其余各点的值为0.
*/
int[][] matrix = new int[m + 1][n + 1];
for (int i = 1; i <= m; i++) {
for (int j = 1; j <= n; j++) {
if (chars_strA[i - 1] == chars_strB[j - 1])
matrix[i][j] = matrix[i - 1][j - 1] + 1;
else
matrix[i][j] = Math.max(matrix[i][j - 1], matrix[i - 1][j]);
}
}
/*
* 矩阵中,如果matrix[m][n]的值不等于matrix[m-1][n]的值也不等于matrix[m][n-1]的值,
* 则matrix[m][n]对应的字符为相似字符元,并将其存入result数组中。
*
*/
char[] result = new char[matrix[m][n]];
int currentIndex = result.length - 1;
while (matrix[m][n] != 0) {
if (matrix[n] == matrix[n - 1])
n--;
else if (matrix[m][n] == matrix[m - 1][n])
m--;
else {
result[currentIndex] = chars_strA[m - 1];
currentIndex--;
n--;
m--;
}
}
return new String(result);
}
/*
* 结果转换成百分比形式
*/
public static String similarityResult(double resule) {
return NumberFormat.getPercentInstance(new Locale("en ", "US ")).format(resule);
}
}%>
<%
String utext = request.getParameter("utext");
String utextout = new String(utext.getBytes("iso-8859-1"), "utf-8");//解决乱码
out.print(utextout);
String allStr = getRatio(utextout);
double sameRatio = calcSame(utextout, allStr);
out.print("<h3>重复率:</h3>" + sameRatio);
out.print("<h3>网络中检索到的文本是:</h3>" + allStr);
%>
</body>
</html>
JAVA工具类
以下是分别定义的Java工具类
但是在过程中,为了方便debug,我把所有的逻辑全放在jsp页面了,下面这些就没有用到
不过下面这些耦合性比较低,以后可能会用到,也放上来,方便查找
Craw.java
package cn.hanquan.craw;
import java.io.File;
import java.io.FileInputStream;
import java.io.FileOutputStream;
import java.io.FileWriter;
import java.io.IOException;
import java.io.InputStream;
import java.io.InputStreamReader;
import java.net.HttpURLConnection;
import java.net.MalformedURLException;
import java.net.URL;
import java.net.URLEncoder;
import java.util.Scanner;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class Craw {
// public static void main(String[] args) throws IOException {
// craw("如何爬取网页中的内容");
// }
/**
* 百度在线搜索 得到搜索结果页链接
*
* @param smess 你要搜索的字符串
* @throws IOException
*/
public static void craw(String mess) throws IOException {
try {
String PATH = "./";
// String PATH = "/home/pan/tomcat/webapps/BlogCheck/txtfile/";
String smess = URLEncoder.encode(mess, "UTF-8");
String urll = "http://www.baidu.com/s?wd=" + smess;
URL url = new URL(urll);
InputStream input = url.openStream();
FileOutputStream fout = new FileOutputStream(new File(PATH + "FirstPage.html")); // 爬取百度搜索并保存成文件
int a = 0;
while (a > -1) {
a = input.read();
fout.write(a);
}
fout.close();
File file = new File(PATH + "FirstPage.html");
String pattern = "href=\"(http://cache.baiducontent.com/c\\?m=.+?)\".+$";// 正则匹配其中的地址
String h3_pattern = "(a data-click)"; // 通过爬取的网页源码可以发现每个链接之前都有一个h3 class标签
Pattern pat = Pattern.compile(pattern);
Pattern h3_pat = Pattern.compile(h3_pattern);
InputStreamReader input1;
input1 = new InputStreamReader(new FileInputStream(file), "UTF-8");
Scanner scan = new Scanner(input1);
String str = null;
Matcher mach;
Matcher machh3;
int count = 0;
FileWriter fw = new FileWriter(PATH + "Result.txt"); // 提取其中的地址并保存成文件
boolean in = false;
while (scan.hasNextLine()) {
str = scan.nextLine();
machh3 = h3_pat.matcher(str); // 先看能不能匹配到h3 class标签,如果可以则进行匹配链接
while (machh3.find()) {
if (machh3.groupCount() > 0) {
in = true;
}
}
if (in) {
mach = pat.matcher(str); // 匹配链接
while (mach.find()) {
count++;
in = false;
// System.out.println(count + " " + mach.group(1));
fw.write(mach.group(1) + "\r\n");
}
}
}
fw.close();
// file = new File(PATH + "Result.txt"); // 读取要解析的链接文件
// InputStreamReader input2 = new InputStreamReader(new FileInputStream(file), "UTF-8");
// Scanner sca = new Scanner(input2);
// String st = null;
// count = 0;
// FileWriter fww = new FileWriter(PATH + "ResultPro.txt"); // 将解析后的链接保存成文件
// while (sca.hasNext()) {
// count++;
// st = sca.nextLine();
// URL uurl = new URL(st);
// HttpURLConnection connect = (HttpURLConnection) uurl.openConnection();
// connect.setInstanceFollowRedirects(false); // 设置是否自动重定向
// fww.write(connect.getHeaderField("Location") + "\r\n"); // 获取真实的地址
// System.out.println(count + " " + connect.getHeaderField("Location"));
// }
// fww.close();
System.out.println("has end");
} catch (MalformedURLException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
}
Main.java
package cn.hanquan.page;
import java.io.File;
import java.io.IOException;
import cn.hanquan.craw.Craw;
public class Main {
public static void main(String[] args) throws IOException {
getRatio("常见乱码");
}
public static String getRatio(String utextout) throws IOException {
String PATH = "./";
//String PATH = "/home/pan/tomcat/webapps/BlogCheck/txtfile/";
StringBuilder allStr = new StringBuilder();
if (utextout.length() < 20) {// 输入过少的情况
Craw.craw(utextout);// 搜索字符串
String allUrl = ReadFile.read(new File(PATH + "Result.txt"));// 结果页链接
String[] urls = allUrl.split("\r\n");// 跨平台的时候注意一下\r\n
for (String u : urls) {
String htmlStr = URLtoText.get(u);// 获取html代码
String str = RegEx.regEx(htmlStr);// 正则
System.out.println(u);
System.out.println(str);
allStr.append(str + "\n");// 追加
}
WriteFile.save(new File(PATH + "2.txt"), allStr.toString());// 存储
} else {
// 20个字查一次 全部结果保存
for (int i = 0; i + 21 < utextout.length(); i += 20) {
String split = utextout.substring(i, i + 20);
Craw.craw(split);// 搜索字符串
String allUrl = ReadFile.read(new File(PATH + "ResultPro.txt"));// 结果页链接
String[] urls = allUrl.split("\r\n");// 跨平台的时候注意一下\r\n
for (String u : urls) {
String htmlStr = URLtoText.get(u);// 获取html代码
String str = RegEx.regEx(htmlStr);// 正则
System.out.println(u);
System.out.println(str);
allStr.append(str + "\n");// 追加
}
WriteFile.save(new File(PATH + "2.txt"), allStr.toString());// 存储
}
}
// System.out.println(allStr);
return allStr.toString();
}
}
ReadFile.java
package cn.hanquan.page;
import java.io.File;
import java.io.IOException;
import cn.hanquan.craw.Craw;
public class Main {
public static void main(String[] args) throws IOException {
getRatio("常见乱码");
}
public static String getRatio(String utextout) throws IOException {
String PATH = "./";
//String PATH = "/home/pan/tomcat/webapps/BlogCheck/txtfile/";
StringBuilder allStr = new StringBuilder();
if (utextout.length() < 20) {// 输入过少的情况
Craw.craw(utextout);// 搜索字符串
String allUrl = ReadFile.read(new File(PATH + "Result.txt"));// 结果页链接
String[] urls = allUrl.split("\r\n");// 跨平台的时候注意一下\r\n
for (String u : urls) {
String htmlStr = URLtoText.get(u);// 获取html代码
String str = RegEx.regEx(htmlStr);// 正则
System.out.println(u);
System.out.println(str);
allStr.append(str + "\n");// 追加
}
WriteFile.save(new File(PATH + "2.txt"), allStr.toString());// 存储
} else {
// 20个字查一次 全部结果保存
for (int i = 0; i + 21 < utextout.length(); i += 20) {
String split = utextout.substring(i, i + 20);
Craw.craw(split);// 搜索字符串
String allUrl = ReadFile.read(new File(PATH + "ResultPro.txt"));// 结果页链接
String[] urls = allUrl.split("\r\n");// 跨平台的时候注意一下\r\n
for (String u : urls) {
String htmlStr = URLtoText.get(u);// 获取html代码
String str = RegEx.regEx(htmlStr);// 正则
System.out.println(u);
System.out.println(str);
allStr.append(str + "\n");// 追加
}
WriteFile.save(new File(PATH + "2.txt"), allStr.toString());// 存储
}
}
// System.out.println(allStr);
return allStr.toString();
}
}
RegEx.java
package cn.hanquan.page;
import java.util.regex.Pattern;
public class RegEx {
public static String regEx(String str) {
String htmlStr = str; // 含html标签的字符串
String textStr = "";
java.util.regex.Pattern p_script;
java.util.regex.Matcher m_script;
java.util.regex.Pattern p_style;
java.util.regex.Matcher m_style;
java.util.regex.Pattern p_html;
java.util.regex.Matcher m_html;
try {
String regEx_script = "<[\\s]*?script[^>]*?>[\\s\\S]*?<[\\s]*?\\/[\\s]*?script[\\s]*?>"; // 定义script的正则表达式{或<script[^>]*?>[\\s\\S]*?<\\/script>
String regEx_style = "<[\\s]*?style[^>]*?>[\\s\\S]*?<[\\s]*?\\/[\\s]*?style[\\s]*?>"; // 定义style的正则表达式{或<style[^>]*?>[\\s\\S]*?<\\/style>
String regEx_html = "<[^>]+>"; // 定义HTML标签的正则表达式
p_script = Pattern.compile(regEx_script, Pattern.CASE_INSENSITIVE);
m_script = p_script.matcher(htmlStr);
htmlStr = m_script.replaceAll(""); // 过滤script标签
p_style = Pattern.compile(regEx_style, Pattern.CASE_INSENSITIVE);
m_style = p_style.matcher(htmlStr);
htmlStr = m_style.replaceAll(""); // 过滤style标签
p_html = Pattern.compile(regEx_html, Pattern.CASE_INSENSITIVE);
m_html = p_html.matcher(htmlStr);
htmlStr = m_html.replaceAll(""); // 过滤html标签
textStr = htmlStr;
} catch (Exception e) {
System.err.println("Html2Text: " + e.getMessage());
}
// 剔除空格行
textStr = textStr.replaceAll("[ ]+", "");
textStr = textStr.replaceAll("1", "").replaceAll("2", "").replaceAll("3", "").replaceAll("4", "")
.replaceAll("5", "").replaceAll("6", "").replaceAll("7", "").replaceAll("8", "").replaceAll("9", "")
.replaceAll("0", "");
textStr = textStr.replaceAll("(?m)^\\s*$(\\n|\\r\\n)", "");
textStr = textStr.replaceAll("\t", "");
textStr = textStr.replaceAll(" ", "").replace(">", "").replace("—", "").replace("<", "")
.replace(""", "");
textStr = textStr.replaceAll("\\\\", "");// 正则表达式中匹配一个反斜杠要用四个反斜杠
textStr = textStr.replaceAll("\r\n", "");
textStr = textStr.replaceAll("\n", "");
return textStr;// 返回文本字符串
}
}
URLtoText.java
package cn.hanquan.page;
import java.io.IOException;
import java.io.InputStream;
import java.io.UnsupportedEncodingException;
import java.net.HttpURLConnection;
import java.net.URL;
public class URLtoText {
/**
* 读取链接对应的网页,返回字符串
*
* @param url the URL you want to get
* @return the HTML Script of your URL
* @throws IOException
*/
public static String get(String url) throws IOException {
// 解决编码问题
InputStream is = doGet(url);
String pageStr = inputStreamToString(is, "utf-8");// 先用 UTF-8 读进来(至少英文不会乱码),再判断是什么编码
String encode = getEncode(pageStr);
// 用已知编码读取
is = doGet(url);// InputStream只能读取一次,只能重新获取,办法比较蠢
System.out.println("源网页编码:" + encode);
pageStr = inputStreamToString(is, encode);
// 字符串编码转换
pageStr = changeCharset(pageStr, encode, "utf-8");// 之前忘记接收了
is.close();
return pageStr;
}
public static InputStream doGet(String urlstr) throws IOException {
URL url = new URL(urlstr);
HttpURLConnection conn = (HttpURLConnection) url.openConnection();
conn.setConnectTimeout(3000);// 设置相应超时时间
conn.setRequestProperty("User-Agent",
"Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/56.0.2924.87 Safari/537.36");
InputStream inputStream = conn.getInputStream();
return inputStream;
}
public static String inputStreamToString(InputStream is, String charset) throws IOException {
byte[] bytes = new byte[1024];
int byteLength = 0;
StringBuffer sb = new StringBuffer();
while ((byteLength = is.read(bytes)) != -1) {
sb.append(new String(bytes, 0, byteLength, charset));
}
return sb.toString();
}
/**
* 获取网页编码
*
* @param str 网页的源代码
* @return
* @throws IOException
*/
public static String getEncode(String str) throws IOException {
int iutf1 = str.indexOf("charset=utf-8") > 0 ? str.indexOf("charset=utf-8") : Integer.MAX_VALUE;
int iutf2 = str.indexOf("charset=\"utf-8\"") > 0 ? str.indexOf("charset=\"utf-8\"") : Integer.MAX_VALUE;
int iutf3 = str.indexOf("charset = \"utf-8\"") > 0 ? str.indexOf("charset = \"utf-8\"") : Integer.MAX_VALUE;
int iutf4 = str.indexOf("charset = UTF-8") > 0 ? str.indexOf("charset = utf-8") : Integer.MAX_VALUE;
int iutf5 = str.indexOf("charset=UTF-8") > 0 ? str.indexOf("charset=UTF-8") : Integer.MAX_VALUE;
int iutf6 = str.indexOf("charset=\"UTF-8\"") > 0 ? str.indexOf("charset=\"UTF-8\"") : Integer.MAX_VALUE;
int iutf7 = str.indexOf("charset = \"UTF-8\"") > 0 ? str.indexOf("charset = \"UTF-8\"") : Integer.MAX_VALUE;
int iutf8 = str.indexOf("charset = UTF-8") > 0 ? str.indexOf("charset = UTF-8") : Integer.MAX_VALUE;
int minUTF = getMin(iutf1, iutf2, iutf3, iutf4, iutf5, iutf6, iutf7, iutf8);
int igbk1 = str.indexOf("charset=gbk") > 0 ? str.indexOf("charset=gbk") : Integer.MAX_VALUE;
int igbk2 = str.indexOf("charset=\"gbk\"") > 0 ? str.indexOf("charset=\"gbk\"") : Integer.MAX_VALUE;
int igbk3 = str.indexOf("charset = \"gbk\"") > 0 ? str.indexOf("charset = \"gbk\"") : Integer.MAX_VALUE;
int igbk4 = str.indexOf("charset = gbk") > 0 ? str.indexOf("charset = gbk") : Integer.MAX_VALUE;
int igbk5 = str.indexOf("charset=GBK") > 0 ? str.indexOf("charset=GBK") : Integer.MAX_VALUE;
int igbk6 = str.indexOf("charset=\"GBK\"") > 0 ? str.indexOf("charset=\"GBK\"") : Integer.MAX_VALUE;
int igbk7 = str.indexOf("charset = \"GBK\"") > 0 ? str.indexOf("charset = \"GBK\"") : Integer.MAX_VALUE;
int igbk8 = str.indexOf("charset = GBK") > 0 ? str.indexOf("charset = GBK") : Integer.MAX_VALUE;
int minGBK = getMin(igbk1, igbk2, igbk3, igbk4, igbk5, igbk6, igbk7, igbk8);
int igb1 = str.indexOf("charset=gb2312") > 0 ? str.indexOf("charset=gb2312") : Integer.MAX_VALUE;
int igb2 = str.indexOf("charset=\"gb2312\"") > 0 ? str.indexOf("charset=\"gb2312\"") : Integer.MAX_VALUE;
int igb3 = str.indexOf("charset = gb2312") > 0 ? str.indexOf("charset = gb2312") : Integer.MAX_VALUE;
int igb4 = str.indexOf("charset = \"gb2312\"") > 0 ? str.indexOf("charset = \"gb2312\"") : Integer.MAX_VALUE;
int igb5 = str.indexOf("charset=GB2312") > 0 ? str.indexOf("charset=GB2312") : Integer.MAX_VALUE;
int igb6 = str.indexOf("charset=\"GB2312\"") > 0 ? str.indexOf("charset=\"GB2312\"") : Integer.MAX_VALUE;
int igb7 = str.indexOf("charset = GB2312") > 0 ? str.indexOf("charset = GB2312") : Integer.MAX_VALUE;
int igb8 = str.indexOf("charset = \"GB2312\"") > 0 ? str.indexOf("charset = \"GB2312\"") : Integer.MAX_VALUE;
int minGB = getMin(igb1, igb2, igb3, igb4, igb5, igb6, igb7, igb8);
if (minUTF < minGBK && minUTF < minGB)
return "utf-8";
else if (minGBK < minUTF && minGBK < minGB)
return "gbk";
else if (minGB < minUTF && minGB < minGBK)
return "gb2312";
else {
System.out.println("!---编码异常: minGBK=" + minGBK + " minGB=" + minGB + " minUTF=" + minUTF
+ " 也可能是因为网页设置了跳转。默认返回UTF-8");
// WriteFile.save(new File("./errPage.txt"), "异常网页:"+str);
// System.out.println(str);
}
return "utf-8";
}
public static int getMin(int... values) {
int min = Integer.MAX_VALUE;
for (int d : values) {
if (d < min)
min = d;
}
return min;
}
/**
* 字符串编码转换的实现方法
*
* @param str 待转换编码的字符串
* @param newCharset 目标编码
* @return
* @throws UnsupportedEncodingException
*/
public static String changeCharset(String str, String newCharset) throws UnsupportedEncodingException {
if (str != null) {
// 用默认字符编码解码字符串。
byte[] bs = str.getBytes();
// 用新的字符编码生成字符串
return new String(bs, newCharset);
}
return null;
}
/**
* 字符串编码转换的实现方法
*
* @param str 待转换编码的字符串
* @param oldCharset 原编码
* @param newCharset 目标编码
* @return
* @throws UnsupportedEncodingException
*/
public static String changeCharset(String str, String oldCharset, String newCharset)
throws UnsupportedEncodingException {
if (str != null) {
// 用旧的字符编码解码字符串。解码可能会出现异常。
byte[] bs = str.getBytes(oldCharset);
// 用新的字符编码生成字符串
return new String(bs, newCharset);
}
return null;
}
}
WriteFile.java
package cn.hanquan.page;
import java.io.BufferedWriter;
import java.io.File;
import java.io.FileOutputStream;
import java.io.IOException;
import java.io.OutputStreamWriter;
public class WriteFile {
public static void save(File f, String str) throws IOException {
BufferedWriter w = new BufferedWriter(new OutputStreamWriter(new FileOutputStream(f, false), "UTF-8"));
w.write(str);
w.close();
}
}














 957
957











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









