







林炳文Evankaka原创作品。转载请注明出处http://blog.csdn.net/evankaka
写在前面的话:此文只能说是java多线程的一个入门,其实Java里头线程完全可以写一本书了,但是如果最基本的你都学掌握好,又怎么能更上一个台阶呢?如果你觉得此文很简单,那推荐你看看Java并发包的的线程池(Java并发编程与技术内幕:线程池深入理解),或者看这个专栏:Java并发编程与技术内幕。你将会对Java里头的高并发场景下的线程有更加深刻的理解。
本文主要讲了java中多线程的使用方法、线程同步、线程数据传递、线程状态及相应的一些线程函数用法、概述等。在这之前,首先让我们来了解下在操作系统中进程和线程的区别:
进程:每个进程都有独立的代码和数据空间(进程上下文),进程间的切换会有较大的开销,一个进程包含1--n个线程。(进程是资源分配的最小单位)
线程:同一类线程共享代码和数据空间,每个线程有独立的运行栈和程序计数器(PC),线程切换开销小。(线程是cpu调度的最小单位)
线程和进程一样分为五个阶段:创建、就绪、运行、阻塞、终止。
多进程是指操作系统能同时运行多个任务(程序)。
多线程是指在同一程序中有多个顺序流在执行。
在java中要想实现多线程,有两种手段,一种是继续Thread类,另外一种是实现Runable接口.(其实准确来讲,应该有三种,还有一种是实现Callable接口,并与Future、线程池结合使用,此文这里不讲这个,有兴趣看这里Java并发编程与技术内幕:Callable、Future、FutureTask、CompletionService )
一、扩展java.lang.Thread类
这里继承Thread类的方法是比较常用的一种,如果说你只是想起一条线程。没有什么其它特殊的要求,那么可以使用Thread.(笔者推荐使用Runable,后头会说明为什么)。下面来看一个简单的实例
- package com.multithread.learning;
- /**
- *@functon 多线程学习
- *@author 林炳文
- *@time 2015.3.9
- */
- class Thread1 extends Thread{
- private String name;
- public Thread1(String name) {
- this.name=name;
- }
- public void run() {
- for (int i = 0; i < 5; i++) {
- System.out.println(name + "运行 : " + i);
- try {
- sleep((int) Math.random() * 10);
- } catch (InterruptedException e) {
- e.printStackTrace();
- }
- }
- }
- }
- public class Main {
- public static void main(String[] args) {
- Thread1 mTh1=new Thread1("A");
- Thread1 mTh2=new Thread1("B");
- mTh1.start();
- mTh2.start();
- }
- }
输出:
A运行 : 0
B运行 : 0
A运行 : 1
A运行 : 2
A运行 : 3
A运行 : 4
B运行 : 1
B运行 : 2
B运行 : 3
B运行 : 4
再运行一下:
A运行 : 0
B运行 : 0
B运行 : 1
B运行 : 2
B运行 : 3
B运行 : 4
A运行 : 1
A运行 : 2
A运行 : 3
A运行 : 4
但是start方法重复调用的话,会出现java.lang.IllegalThreadStateException异常。
- Thread1 mTh1=new Thread1("A");
- Thread1 mTh2=mTh1;
- mTh1.start();
- mTh2.start();
输出:
Exception in thread "main" java.lang.IllegalThreadStateException
at java.lang.Thread.start(Unknown Source)
at com.multithread.learning.Main.main(Main.java:31)
A运行 : 0
A运行 : 1
A运行 : 2
A运行 : 3
A运行 : 4
二、实现java.lang.Runnable接口
采用Runnable也是非常常见的一种,我们只需要重写run方法即可。下面也来看个实例。
- /**
- *@functon 多线程学习
- *@author 林炳文
- *@time 2015.3.9
- */
- package com.multithread.runnable;
- class Thread2 implements Runnable{
- private String name;
- public Thread2(String name) {
- this.name=name;
- }
- @Override
- public void run() {
- for (int i = 0; i < 5; i++) {
- System.out.println(name + "运行 : " + i);
- try {
- Thread.sleep((int) Math.random() * 10);
- } catch (InterruptedException e) {
- e.printStackTrace();
- }
- }
- }
- }
- public class Main {
- public static void main(String[] args) {
- new Thread(new Thread2("C")).start();
- new Thread(new Thread2("D")).start();
- }
- }
输出:
C运行 : 0
D运行 : 0
D运行 : 1
C运行 : 1
D运行 : 2
C运行 : 2
D运行 : 3
C运行 : 3
D运行 : 4
C运行 : 4
三、Thread和Runnable的区别
如果一个类继承Thread,则不适合资源共享。但是如果实现了Runable接口的话,则很容易的实现资源共享。
总结:
实现Runnable接口比继承Thread类所具有的优势:
1):适合多个相同的程序代码的线程去处理同一个资源
2):可以避免java中的单继承的限制
3):增加程序的健壮性,代码可以被多个线程共享,代码和数据独立
4):线程池只能放入实现Runable或callable类线程,不能直接放入继承Thread的类
提醒一下大家:main方法其实也是一个线程。在java中所以的线程都是同时启动的,至于什么时候,哪个先执行,完全看谁先得到CPU的资源。
在java中,每次程序运行至少启动2个线程。一个是main线程,一个是垃圾收集线程。因为每当使用java命令执行一个类的时候,实际上都会启动一个JVM,每一个jVM实习在就是在操作系统中启动了一个进程。
四、线程状态转换
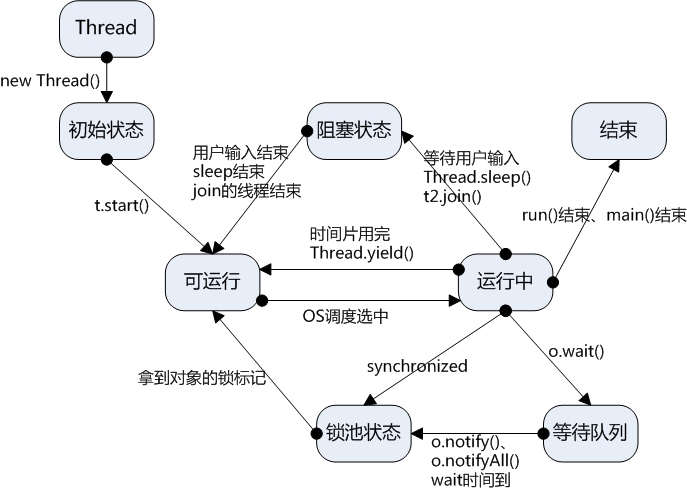
五、线程调度
线程的调度
六、常用函数说明
①sleep(long millis): 在指定的毫秒数内让当前正在执行的线程休眠(暂停执行)②join():指等待t线程终止。
使用方式。
join是Thread类的一个方法,启动线程后直接调用,即join()的作用是:“等待该线程终止”,这里需要理解的就是该线程是指的主线程等待子线程的终止。也就是在子线程调用了join()方法后面的代码,只有等到子线程结束了才能执行。
- Thread t = new AThread(); t.start(); t.join();
为什么要用join()方法
在很多情况下,主线程生成并起动了子线程,如果子线程里要进行大量的耗时的运算,主线程往往将于子线程之前结束,但是如果主线程处理完其他的事务后,需要用到子线程的处理结果,也就是主线程需要等待子线程执行完成之后再结束,这个时候就要用到join()方法了。
不加join。- /**
- *@functon 多线程学习,join
- *@author 林炳文
- *@time 2015.3.9
- */
- package com.multithread.join;
- class Thread1 extends Thread{
- private String name;
- public Thread1(String name) {
- super(name);
- this.name=name;
- }
- public void run() {
- System.out.println(Thread.currentThread().getName() + " 线程运行开始!");
- for (int i = 0; i < 5; i++) {
- System.out.println("子线程"+name + "运行 : " + i);
- try {
- sleep((int) Math.random() * 10);
- } catch (InterruptedException e) {
- e.printStackTrace();
- }
- }
- System.out.println(Thread.currentThread().getName() + " 线程运行结束!");
- }
- }
- public class Main {
- public static void main(String[] args) {
- System.out.println(Thread.currentThread().getName()+"主线程运行开始!");
- Thread1 mTh1=new Thread1("A");
- Thread1 mTh2=new Thread1("B");
- mTh1.start();
- mTh2.start();
- System.out.println(Thread.currentThread().getName()+ "主线程运行结束!");
- }
- }
main主线程运行开始!
main主线程运行结束!
B 线程运行开始!
子线程B运行 : 0
A 线程运行开始!
子线程A运行 : 0
子线程B运行 : 1
子线程A运行 : 1
子线程A运行 : 2
子线程A运行 : 3
子线程A运行 : 4
A 线程运行结束!
子线程B运行 : 2
子线程B运行 : 3
子线程B运行 : 4
B 线程运行结束!
发现主线程比子线程早结束
加join
- public class Main {
- public static void main(String[] args) {
- System.out.println(Thread.currentThread().getName()+"主线程运行开始!");
- Thread1 mTh1=new Thread1("A");
- Thread1 mTh2=new Thread1("B");
- mTh1.start();
- mTh2.start();
- try {
- mTh1.join();
- } catch (InterruptedException e) {
- e.printStackTrace();
- }
- try {
- mTh2.join();
- } catch (InterruptedException e) {
- e.printStackTrace();
- }
- System.out.println(Thread.currentThread().getName()+ "主线程运行结束!");
- }
- }
运行结果:
main主线程运行开始!
A 线程运行开始!
子线程A运行 : 0
B 线程运行开始!
子线程B运行 : 0
子线程A运行 : 1
子线程B运行 : 1
子线程A运行 : 2
子线程B运行 : 2
子线程A运行 : 3
子线程B运行 : 3
子线程A运行 : 4
子线程B运行 : 4
A 线程运行结束!
主线程一定会等子线程都结束了才结束
③yield():暂停当前正在执行的线程对象,并执行其他线程。
- /**
- *@functon 多线程学习 yield
- *@author 林炳文
- *@time 2015.3.9
- */
- package com.multithread.yield;
- class ThreadYield extends Thread{
- public ThreadYield(String name) {
- super(name);
- }
- @Override
- public void run() {
- for (int i = 1; i <= 50; i++) {
- System.out.println("" + this.getName() + "-----" + i);
- // 当i为30时,该线程就会把CPU时间让掉,让其他或者自己的线程执行(也就是谁先抢到谁执行)
- if (i ==30) {
- this.yield();
- }
- }
- }
- }
- public class Main {
- public static void main(String[] args) {
- ThreadYield yt1 = new ThreadYield("张三");
- ThreadYield yt2 = new ThreadYield("李四");
- yt1.start();
- yt2.start();
- }
- }
运行结果:
第一种情况:李四(线程)当执行到30时会CPU时间让掉,这时张三(线程)抢到CPU时间并执行。
第二种情况:李四(线程)当执行到30时会CPU时间让掉,这时李四(线程)抢到CPU时间并执行。
sleep()和yield()的区别sleep()和yield()的区别):sleep()使当前线程进入停滞状态,所以执行sleep()的线程在指定的时间内肯定不会被执行;yield()只是使当前线程重新回到可执行状态,所以执行yield()的线程有可能在进入到可执行状态后马上又被执行。
sleep 方法使当前运行中的线程睡眼一段时间,进入不可运行状态,这段时间的长短是由程序设定的,yield 方法使当前线程让出 CPU 占有权,但让出的时间是不可设定的。实际上,yield()方法对应了如下操作:先检测当前是否有相同优先级的线程处于同可运行状态,如有,则把 CPU 的占有权交给此线程,否则,继续运行原来的线程。所以yield()方法称为“退让”,它把运行机会让给了同等优先级的其他线程
另外,sleep 方法允许较低优先级的线程获得运行机会,但 yield() 方法执行时,当前线程仍处在可运行状态,所以,不可能让出较低优先级的线程些时获得 CPU 占有权。在一个运行系统中,如果较高优先级的线程没有调用 sleep 方法,又没有受到 I\O 阻塞,那么,较低优先级线程只能等待所有较高优先级的线程运行结束,才有机会运行。
④setPriority(): 更改线程的优先级。
MIN_PRIORITY = 1
NORM_PRIORITY = 5
MAX_PRIORITY = 10
Thread4 t1 = new Thread4("t1");
Thread4 t2 = new Thread4("t2");
t1.setPriority(Thread.MAX_PRIORITY);
t2.setPriority(Thread.MIN_PRIORITY);
⑤interrupt():不要以为它是中断某个线程!它只是线线程发送一个中断信号,让线程在无限等待时(如死锁时)能抛出抛出,从而结束线程,但是如果你吃掉了这个异常,那么这个线程还是不会中断的!
⑥wait()
Obj.wait(),与Obj.notify()必须要与synchronized(Obj)一起使用,也就是wait,与notify是针对已经获取了Obj锁进行操作,从语法角度来说就是Obj.wait(),Obj.notify必须在synchronized(Obj){...}语句块内。从功能上来说wait就是说线程在获取对象锁后,主动释放对象锁,同时本线程休眠。直到有其它线程调用对象的notify()唤醒该线程,才能继续获取对象锁,并继续执行。相应的notify()就是对对象锁的唤醒操作。但有一点需要注意的是notify()调用后,并不是马上就释放对象锁的,而是在相应的synchronized(){}语句块执行结束,自动释放锁后,JVM会在wait()对象锁的线程中随机选取一线程,赋予其对象锁,唤醒线程,继续执行。这样就提供了在线程间同步、唤醒的操作。Thread.sleep()与Object.wait()二者都可以暂停当前线程,释放CPU控制权,主要的区别在于Object.wait()在释放CPU同时,释放了对象锁的控制。
单单在概念上理解清楚了还不够,需要在实际的例子中进行测试才能更好的理解。对Object.wait(),Object.notify()的应用最经典的例子,应该是三线程打印ABC的问题了吧,这是一道比较经典的面试题,题目要求如下:
建立三个线程,A线程打印10次A,B线程打印10次B,C线程打印10次C,要求线程同时运行,交替打印10次ABC。这个问题用Object的wait(),notify()就可以很方便的解决。代码如下:
- /**
- * wait用法
- * @author DreamSea
- * @time 2015.3.9
- */
- package com.multithread.wait;
- public class MyThreadPrinter2 implements Runnable {
- private String name;
- private Object prev;
- private Object self;
- private MyThreadPrinter2(String name, Object prev, Object self) {
- this.name = name;
- this.prev = prev;
- this.self = self;
- }
- @Override
- public void run() {
- int count = 10;
- while (count > 0) {
- synchronized (prev) {
- synchronized (self) {
- System.out.print(name);
- count--;
- self.notify();
- }
- try {
- prev.wait();
- } catch (InterruptedException e) {
- e.printStackTrace();
- }
- }
- }
- }
- public static void main(String[] args) throws Exception {
- Object a = new Object();
- Object b = new Object();
- Object c = new Object();
- MyThreadPrinter2 pa = new MyThreadPrinter2("A", c, a);
- MyThreadPrinter2 pb = new MyThreadPrinter2("B", a, b);
- MyThreadPrinter2 pc = new MyThreadPrinter2("C", b, c);
- new Thread(pa).start();
- Thread.sleep(100); //确保按顺序A、B、C执行
- new Thread(pb).start();
- Thread.sleep(100);
- new Thread(pc).start();
- Thread.sleep(100);
- }
- }
输出结果:
ABCABCABCABCABCABCABCABCABCABC
先来解释一下其整体思路,从大的方向上来讲,该问题为三线程间的同步唤醒操作,主要的目的就是ThreadA->ThreadB->ThreadC->ThreadA循环执行三个线程。为了控制线程执行的顺序,那么就必须要确定唤醒、等待的顺序,所以每一个线程必须同时持有两个对象锁,才能继续执行。一个对象锁是prev,就是前一个线程所持有的对象锁。还有一个就是自身对象锁。主要的思想就是,为了控制执行的顺序,必须要先持有prev锁,也就前一个线程要释放自身对象锁,再去申请自身对象锁,两者兼备时打印,之后首先调用self.notify()释放自身对象锁,唤醒下一个等待线程,再调用prev.wait()释放prev对象锁,终止当前线程,等待循环结束后再次被唤醒。运行上述代码,可以发现三个线程循环打印ABC,共10次。程序运行的主要过程就是A线程最先运行,持有C,A对象锁,后释放A,C锁,唤醒B。线程B等待A锁,再申请B锁,后打印B,再释放B,A锁,唤醒C,线程C等待B锁,再申请C锁,后打印C,再释放C,B锁,唤醒A。看起来似乎没什么问题,但如果你仔细想一下,就会发现有问题,就是初始条件,三个线程按照A,B,C的顺序来启动,按照前面的思考,A唤醒B,B唤醒C,C再唤醒A。但是这种假设依赖于JVM中线程调度、执行的顺序。wait和sleep区别
共同点:
1. 他们都是在多线程的环境下,都可以在程序的调用处阻塞指定的毫秒数,并返回。
2. wait()和sleep()都可以通过interrupt()方法 打断线程的暂停状态 ,从而使线程立刻抛出InterruptedException。
如果线程A希望立即结束线程B,则可以对线程B对应的Thread实例调用interrupt方法。如果此刻线程B正在wait/sleep /join,则线程B会立刻抛出InterruptedException,在catch() {} 中直接return即可安全地结束线程。
需要注意的是,InterruptedException是线程自己从内部抛出的,并不是interrupt()方法抛出的。对某一线程调用 interrupt()时,如果该线程正在执行普通的代码,那么该线程根本就不会抛出InterruptedException。但是,一旦该线程进入到 wait()/sleep()/join()后,就会立刻抛出InterruptedException 。
不同点:
1. Thread类的方法:sleep(),yield()等
Object的方法:wait()和notify()等
2. 每个对象都有一个锁来控制同步访问。Synchronized关键字可以和对象的锁交互,来实现线程的同步。
sleep方法没有释放锁,而wait方法释放了锁,使得其他线程可以使用同步控制块或者方法。
3. wait,notify和notifyAll只能在同步控制方法或者同步控制块里面使用,而sleep可以在任何地方使用
4. sleep必须捕获异常,而wait,notify和notifyAll不需要捕获异常
所以sleep()和wait()方法的最大区别是:
sleep()睡眠时,保持对象锁,仍然占有该锁;
而wait()睡眠时,释放对象锁。
但是wait()和sleep()都可以通过interrupt()方法打断线程的暂停状态,从而使线程立刻抛出InterruptedException(但不建议使用该方法)。
sleep()方法
sleep()使当前线程进入停滞状态(阻塞当前线程),让出CUP的使用、目的是不让当前线程独自霸占该进程所获的CPU资源,以留一定时间给其他线程执行的机会;
sleep()是Thread类的Static(静态)的方法;因此他不能改变对象的机锁,所以当在一个Synchronized块中调用Sleep()方法是,线程虽然休眠了,但是对象的机锁并木有被释放,其他线程无法访问这个对象(即使睡着也持有对象锁)。
在sleep()休眠时间期满后,该线程不一定会立即执行,这是因为其它线程可能正在运行而且没有被调度为放弃执行,除非此线程具有更高的优先级。
wait()方法
wait()方法是Object类里的方法;当一个线程执行到wait()方法时,它就进入到一个和该对象相关的等待池中,同时失去(释放)了对象的机锁(暂时失去机锁,wait(long timeout)超时时间到后还需要返还对象锁);其他线程可以访问;
wait()使用notify或者notifyAlll或者指定睡眠时间来唤醒当前等待池中的线程。
wiat()必须放在synchronized block中,否则会在program runtime时扔出”java.lang.IllegalMonitorStateException“异常。
七、常见线程名词解释
线程类的一些常用方法:
sleep(): 强迫一个线程睡眠N毫秒。
isAlive(): 判断一个线程是否存活。
join(): 等待线程终止。
activeCount(): 程序中活跃的线程数。
enumerate(): 枚举程序中的线程。
currentThread(): 得到当前线程。
isDaemon(): 一个线程是否为守护线程。
setDaemon(): 设置一个线程为守护线程。(用户线程和守护线程的区别在于,是否等待主线程依赖于主线程结束而结束)
setName(): 为线程设置一个名称。
wait(): 强迫一个线程等待。
notify(): 通知一个线程继续运行。
setPriority(): 设置一个线程的优先级。
八、线程同步
1、synchronized关键字的作用域有二种:
1)是某个对象实例内,synchronized aMethod(){}可以防止多个线程同时访问这个对象的synchronized方法(如果一个对象有多个synchronized方法,只要一个线程访问了其中的一个synchronized方法,其它线程不能同时访问这个对象中任何一个synchronized方法)。这时,不同的对象实例的synchronized方法是不相干扰的。也就是说,其它线程照样可以同时访问相同类的另一个对象实例中的synchronized方法;
2)是某个类的范围,synchronized static aStaticMethod{}防止多个线程同时访问这个类中的synchronized static 方法。它可以对类的所有对象实例起作用。
2、除了方法前用synchronized关键字,synchronized关键字还可以用于方法中的某个区块中,表示只对这个区块的资源实行互斥访问。用法是: synchronized(this){/*区块*/},它的作用域是当前对象;
3、synchronized关键字是不能继承的,也就是说,基类的方法synchronized f(){} 在继承类中并不自动是synchronized f(){},而是变成了f(){}。继承类需要你显式的指定它的某个方法为synchronized方法;
Java对多线程的支持与同步机制深受大家的喜爱,似乎看起来使用了synchronized关键字就可以轻松地解决多线程共享数据同步问题。到底如何?――还得对synchronized关键字的作用进行深入了解才可定论。
总的说来,synchronized关键字可以作为函数的修饰符,也可作为函数内的语句,也就是平时说的同步方法和同步语句块。如果再细的分类,synchronized可作用于instance变量、object reference(对象引用)、static函数和class literals(类名称字面常量)身上。
在进一步阐述之前,我们需要明确几点:
A.无论synchronized关键字加在方法上还是对象上,它取得的锁都是对象,而不是把一段代码或函数当作锁――而且同步方法很可能还会被其他线程的对象访问。
B.每个对象只有一个锁(lock)与之相关联。
C.实现同步是要很大的系统开销作为代价的,甚至可能造成死锁,所以尽量避免无谓的同步控制。
接着来讨论synchronized用到不同地方对代码产生的影响:
假设P1、P2是同一个类的不同对象,这个类中定义了以下几种情况的同步块或同步方法,P1、P2就都可以调用它们。
1. 把synchronized当作函数修饰符时,示例代码如下:
Public synchronized void methodAAA()
{
//….
}
这也就是同步方法,那这时synchronized锁定的是哪个对象呢?它锁定的是调用这个同步方法对象。也就是说,当一个对象P1在不同的线程中执行这个同步方法时,它们之间会形成互斥,达到同步的效果。但是这个对象所属的Class所产生的另一对象P2却可以任意调用这个被加了synchronized关键字的方法。
上边的示例代码等同于如下代码:
public void methodAAA()
{
synchronized (this) // (1)
{
//…..
}
}
(1)处的this指的是什么呢?它指的就是调用这个方法的对象,如P1。可见同步方法实质是将synchronized作用于object reference。――那个拿到了P1对象锁的线程,才可以调用P1的同步方法,而对P2而言,P1这个锁与它毫不相干,程序也可能在这种情形下摆脱同步机制的控制,造成数据混乱:(
2.同步块,示例代码如下:
public void method3(SomeObject so)
{
synchronized(so)
{
//…..
}
}
这时,锁就是so这个对象,谁拿到这个锁谁就可以运行它所控制的那段代码。当有一个明确的对象作为锁时,就可以这样写程序,但当没有明确的对象作为锁,只是想让一段代码同步时,可以创建一个特殊的instance变量(它得是一个对象)来充当锁:
class Foo implements Runnable
{
private byte[] lock = new byte[0]; // 特殊的instance变量
Public void methodA()
{
synchronized(lock) { //… }
}
//…..
}
注:零长度的byte数组对象创建起来将比任何对象都经济――查看编译后的字节码:生成零长度的byte[]对象只需3条操作码,而Object lock = new Object()则需要7行操作码。
3.将synchronized作用于static 函数,示例代码如下:
Class Foo
{
public synchronized static void methodAAA() // 同步的static 函数
{
//….
}
public void methodBBB()
{
synchronized(Foo.class) // class literal(类名称字面常量)
}
}
代码中的methodBBB()方法是把class literal作为锁的情况,它和同步的static函数产生的效果是一样的,取得的锁很特别,是当前调用这个方法的对象所属的类(Class,而不再是由这个Class产生的某个具体对象了)。
记得在《Effective Java》一书中看到过将 Foo.class和 P1.getClass()用于作同步锁还不一样,不能用P1.getClass()来达到锁这个Class的目的。P1指的是由Foo类产生的对象。
可以推断:如果一个类中定义了一个synchronized的static函数A,也定义了一个synchronized 的instance函数B,那么这个类的同一对象Obj在多线程中分别访问A和B两个方法时,不会构成同步,因为它们的锁都不一样。A方法的锁是Obj这个对象,而B的锁是Obj所属的那个Class。
九、线程数据传递
在传统的同步开发模式下,当我们调用一个函数时,通过这个函数的参数将数据传入,并通过这个函数的返回值来返回最终的计算结果。但在多线程的异步开发模式下,数据的传递和返回和同步开发模式有很大的区别。由于线程的运行和结束是不可预料的,因此,在传递和返回数据时就无法象函数一样通过函数参数和return语句来返回数据。
9.1、通过构造方法传递数据
在创建线程时,必须要建立一个Thread类的或其子类的实例。因此,我们不难想到在调用start方法之前通过线程类的构造方法将数据传入线程。并将传入的数据使用类变量保存起来,以便线程使用(其实就是在run方法中使用)。下面的代码演示了如何通过构造方法来传递数据:
- package mythread;
- public class MyThread1 extends Thread
- {
- private String name;
- public MyThread1(String name)
- {
- this.name = name;
- }
- public void run()
- {
- System.out.println("hello " + name);
- }
- public static void main(String[] args)
- {
- Thread thread = new MyThread1("world");
- thread.start();
- }
- }
由于这种方法是在创建线程对象的同时传递数据的,因此,在线程运行之前这些数据就就已经到位了,这样就不会造成数据在线程运行后才传入的现象。如果要传递更复杂的数据,可以使用集合、类等数据结构。使用构造方法来传递数据虽然比较安全,但如果要传递的数据比较多时,就会造成很多不便。由于Java没有默认参数,要想实现类似默认参数的效果,就得使用重载,这样不但使构造方法本身过于复杂,又会使构造方法在数量上大增。因此,要想避免这种情况,就得通过类方法或类变量来传递数据。
9.2、通过变量和方法传递数据
向对象中传入数据一般有两次机会,第一次机会是在建立对象时通过构造方法将数据传入,另外一次机会就是在类中定义一系列的public的方法或变量(也可称之为字段)。然后在建立完对象后,通过对象实例逐个赋值。下面的代码是对MyThread1类的改版,使用了一个setName方法来设置 name变量:
- package mythread;
- public class MyThread2 implements Runnable
- {
- private String name;
- public void setName(String name)
- {
- this.name = name;
- }
- public void run()
- {
- System.out.println("hello " + name);
- }
- public static void main(String[] args)
- {
- MyThread2 myThread = new MyThread2();
- myThread.setName("world");
- Thread thread = new Thread(myThread);
- thread.start();
- }
- }
9.3、通过回调函数传递数据
上面讨论的两种向线程中传递数据的方法是最常用的。但这两种方法都是main方法中主动将数据传入线程类的。这对于线程来说,是被动接收这些数据的。然而,在有些应用中需要在线程运行的过程中动态地获取数据,如在下面代码的run方法中产生了3个随机数,然后通过Work类的process方法求这三个随机数的和,并通过Data类的value将结果返回。从这个例子可以看出,在返回value之前,必须要得到三个随机数。也就是说,这个 value是无法事先就传入线程类的。
- package mythread;
- class Data
- {
- public int value = 0;
- }
- class Work
- {
- public void process(Data data, Integer numbers)
- {
- for (int n : numbers)
- {
- data.value += n;
- }
- }
- }
- public class MyThread3 extends Thread
- {
- private Work work;
- public MyThread3(Work work)
- {
- this.work = work;
- }
- public void run()
- {
- java.util.Random random = new java.util.Random();
- Data data = new Data();
- int n1 = random.nextInt(1000);
- int n2 = random.nextInt(2000);
- int n3 = random.nextInt(3000);
- work.process(data, n1, n2, n3); // 使用回调函数
- System.out.println(String.valueOf(n1) + "+" + String.valueOf(n2) + "+"
- + String.valueOf(n3) + "=" + data.value);
- }
- public static void main(String[] args)
- {
- Thread thread = new MyThread3(new Work());
- thread.start();
- }
- }
好了,Java多线程的基础知识就讲到这里了,有兴趣研究多线程的推荐直接看java的源码,你将会得到很大的提升!
林炳文Evankaka原创作品。转载请注明出处http://blog.csdn.net/evankaka
======================================================================
============================================================================================
引
用多线程只有一个目的,那就是更好的利用cpu的资源,因为所有的多线程代码都可以用单线程来实现。说这个话其实只有一半对,因为反应“多角色”的程序代码,最起码每个角色要给他一个线程吧,否则连实际场景都无法模拟,当然也没法说能用单线程来实现:比如最常见的“生产者,消费者模型”。
很多人都对其中的一些概念不够明确,如同步、并发等等,让我们先建立一个数据字典,以免产生误会。
- 多线程:指的是这个程序(一个进程)运行时产生了不止一个线程
- 并行与并发:
- 并行:多个cpu实例或者多台机器同时执行一段处理逻辑,是真正的同时。
- 并发:通过cpu调度算法,让用户看上去同时执行,实际上从cpu操作层面不是真正的同时。并发往往在场景中有公用的资源,那么针对这个公用的资源往往产生瓶颈,我们会用TPS或者QPS来反应这个系统的处理能力。

- 线程安全:经常用来描绘一段代码。指在并发的情况之下,该代码经过多线程使用,线程的调度顺序不影响任何结果。这个时候使用多线程,我们只需要关注系统的内存,cpu是不是够用即可。反过来,线程不安全就意味着线程的调度顺序会影响最终结果,如不加事务的转账代码:
void transferMoney(User from, User to, float amount){ to.setMoney(to.getBalance() + amount); from.setMoney(from.getBalance() - amount); }
- 同步:Java中的同步指的是通过人为的控制和调度,保证共享资源的多线程访问成为线程安全,来保证结果的准确。如上面的代码简单加入
@synchronized关键字。在保证结果准确的同时,提高性能,才是优秀的程序。线程安全的优先级高于性能。
好了,让我们开始吧。我准备分成几部分来总结涉及到多线程的内容:
- 扎好马步:线程的状态
- 内功心法:每个对象都有的方法(机制)
- 太祖长拳:基本线程类
- 九阴真经:高级多线程控制类
扎好马步:线程的状态
先来两张图:


各种状态一目了然,值得一提的是"blocked"这个状态:
线程在Running的过程中可能会遇到阻塞(Blocked)情况
- 调用join()和sleep()方法,sleep()时间结束或被打断,join()中断,IO完成都会回到Runnable状态,等待JVM的调度。
- 调用wait(),使该线程处于等待池(wait blocked pool),直到notify()/notifyAll(),线程被唤醒被放到锁定池(lock blocked pool ),释放同步锁使线程回到可运行状态(Runnable)
- 对Running状态的线程加同步锁(Synchronized)使其进入(lock blocked pool ),同步锁被释放进入可运行状态(Runnable)。
此外,在runnable状态的线程是处于被调度的线程,此时的调度顺序是不一定的。Thread类中的yield方法可以让一个running状态的线程转入runnable。
内功心法:每个对象都有的方法(机制)
synchronized, wait, notify 是任何对象都具有的同步工具。让我们先来了解他们

他们是应用于同步问题的人工线程调度工具。讲其本质,首先就要明确monitor的概念,Java中的每个对象都有一个监视器,来监测并发代码的重入。在非多线程编码时该监视器不发挥作用,反之如果在synchronized 范围内,监视器发挥作用。
wait/notify必须存在于synchronized块中。并且,这三个关键字针对的是同一个监视器(某对象的监视器)。这意味着wait之后,其他线程可以进入同步块执行。
当某代码并不持有监视器的使用权时(如图中5的状态,即脱离同步块)去wait或notify,会抛出java.lang.IllegalMonitorStateException。也包括在synchronized块中去调用另一个对象的wait/notify,因为不同对象的监视器不同,同样会抛出此异常。
再讲用法:
- synchronized单独使用:
- 代码块:如下,在多线程环境下,synchronized块中的方法获取了lock实例的monitor,如果实例相同,那么只有一个线程能执行该块内容

public class Thread1 implements Runnable { Object lock; public void run() { synchronized(lock){ ..do something } } }
- 直接用于方法: 相当于上面代码中用lock来锁定的效果,实际获取的是Thread1类的monitor。更进一步,如果修饰的是static方法,则锁定该类所有实例。
public class Thread1 implements Runnable { public synchronized void run() { ..do something } }
- 代码块:如下,在多线程环境下,synchronized块中的方法获取了lock实例的monitor,如果实例相同,那么只有一个线程能执行该块内容
synchronized, wait, notify结合:典型场景生产者消费者问题
/** * 生产者生产出来的产品交给店员 */ public synchronized void produce() { if(this.product >= MAX_PRODUCT) { try { wait(); System.out.println("产品已满,请稍候再生产"); } catch(InterruptedException e) { e.printStackTrace(); } return; } this.product++; System.out.println("生产者生产第" + this.product + "个产品."); notifyAll(); //通知等待区的消费者可以取出产品了 } /** * 消费者从店员取产品 */ public synchronized void consume() { if(this.product <= MIN_PRODUCT) { try { wait(); System.out.println("缺货,稍候再取"); } catch (InterruptedException e) { e.printStackTrace(); } return; } System.out.println("消费者取走了第" + this.product + "个产品."); this.product--; notifyAll(); //通知等待去的生产者可以生产产品了 }
volatile
多线程的内存模型:main memory(主存)、working memory(线程栈),在处理数据时,线程会把值从主存load到本地栈,完成操作后再save回去(volatile关键词的作用:每次针对该变量的操作都激发一次load and save)。

针对多线程使用的变量如果不是volatile或者final修饰的,很有可能产生不可预知的结果(另一个线程修改了这个值,但是之后在某线程看到的是修改之前的值)。其实道理上讲同一实例的同一属性本身只有一个副本。但是多线程是会缓存值的,本质上,volatile就是不去缓存,直接取值。在线程安全的情况下加volatile会牺牲性能。
太祖长拳:基本线程类
基本线程类指的是Thread类,Runnable接口,Callable接口
Thread 类实现了Runnable接口,启动一个线程的方法:
MyThread my = new MyThread(); my.start();
Thread类相关方法:
//当前线程可转让cpu控制权,让别的就绪状态线程运行(切换) public static Thread.yield() //暂停一段时间 public static Thread.sleep() //在一个线程中调用other.join(),将等待other执行完后才继续本线程。 public join() //后两个函数皆可以被打断 public interrupte()
关于中断:它并不像stop方法那样会中断一个正在运行的线程。线程会不时地检测中断标识位,以判断线程是否应该被中断(中断标识值是否为true)。终端只会影响到wait状态、sleep状态和join状态。被打断的线程会抛出InterruptedException。
Thread.interrupted()检查当前线程是否发生中断,返回boolean
synchronized在获锁的过程中是不能被中断的。
中断是一个状态!interrupt()方法只是将这个状态置为true而已。所以说正常运行的程序不去检测状态,就不会终止,而wait等阻塞方法会去检查并抛出异常。如果在正常运行的程序中添加while(!Thread.interrupted()) ,则同样可以在中断后离开代码体
Thread类最佳实践:
写的时候最好要设置线程名称 Thread.name,并设置线程组 ThreadGroup,目的是方便管理。在出现问题的时候,打印线程栈 (jstack -pid) 一眼就可以看出是哪个线程出的问题,这个线程是干什么的。
如何获取线程中的异常

Runnable
与Thread类似
Callable
future模式:并发模式的一种,可以有两种形式,即无阻塞和阻塞,分别是isDone和get。其中Future对象用来存放该线程的返回值以及状态
ExecutorService e = Executors.newFixedThreadPool(3); //submit方法有多重参数版本,及支持callable也能够支持runnable接口类型. Future future = e.submit(new myCallable()); future.isDone() //return true,false 无阻塞 future.get() // return 返回值,阻塞直到该线程运行结束
九阴真经:高级多线程控制类
以上都属于内功心法,接下来是实际项目中常用到的工具了,Java1.5提供了一个非常高效实用的多线程包:java.util.concurrent, 提供了大量高级工具,可以帮助开发者编写高效、易维护、结构清晰的Java多线程程序。
1.ThreadLocal类
用处:保存线程的独立变量。对一个线程类(继承自Thread)
当使用ThreadLocal维护变量时,ThreadLocal为每个使用该变量的线程提供独立的变量副本,所以每一个线程都可以独立地改变自己的副本,而不会影响其它线程所对应的副本。常用于用户登录控制,如记录session信息。
实现:每个Thread都持有一个TreadLocalMap类型的变量(该类是一个轻量级的Map,功能与map一样,区别是桶里放的是entry而不是entry的链表。功能还是一个map。)以本身为key,以目标为value。
主要方法是get()和set(T a),set之后在map里维护一个threadLocal -> a,get时将a返回。ThreadLocal是一个特殊的容器。
2.原子类(AtomicInteger、AtomicBoolean……)
如果使用atomic wrapper class如atomicInteger,或者使用自己保证原子的操作,则等同于synchronized
//返回值为boolean AtomicInteger.compareAndSet(int expect,int update)
该方法可用于实现乐观锁,考虑文中最初提到的如下场景:a给b付款10元,a扣了10元,b要加10元。此时c给b2元,但是b的加十元代码约为:
if(b.value.compareAndSet(old, value)){ return ; }else{ //try again // if that fails, rollback and log }
AtomicReference
对于AtomicReference 来讲,也许对象会出现,属性丢失的情况,即oldObject == current,但是oldObject.getPropertyA != current.getPropertyA。
这时候,AtomicStampedReference就派上用场了。这也是一个很常用的思路,即加上版本号
3.Lock类
lock: 在java.util.concurrent包内。共有三个实现:
ReentrantLock
ReentrantReadWriteLock.ReadLock
ReentrantReadWriteLock.WriteLock
主要目的是和synchronized一样, 两者都是为了解决同步问题,处理资源争端而产生的技术。功能类似但有一些区别。
区别如下:
lock更灵活,可以自由定义多把锁的枷锁解锁顺序(synchronized要按照先加的后解顺序)
提供多种加锁方案,lock 阻塞式, trylock 无阻塞式, lockInterruptily 可打断式, 还有trylock的带超时时间版本。
本质上和监视器锁(即synchronized是一样的)
能力越大,责任越大,必须控制好加锁和解锁,否则会导致灾难。
和Condition类的结合。
性能更高,对比如下图:

ReentrantLock
可重入的意义在于持有锁的线程可以继续持有,并且要释放对等的次数后才真正释放该锁。
使用方法是:
1.先new一个实例
static ReentrantLock r=new ReentrantLock();
2.加锁
r.lock()或r.lockInterruptibly();
此处也是个不同,后者可被打断。当a线程lock后,b线程阻塞,此时如果是lockInterruptibly,那么在调用b.interrupt()之后,b线程退出阻塞,并放弃对资源的争抢,进入catch块。(如果使用后者,必须throw interruptable exception 或catch)
3.释放锁
r.unlock()
必须做!何为必须做呢,要放在finally里面。以防止异常跳出了正常流程,导致灾难。这里补充一个小知识点,finally是可以信任的:经过测试,哪怕是发生了OutofMemoryError,finally块中的语句执行也能够得到保证。
ReentrantReadWriteLock
可重入读写锁(读写锁的一个实现)
ReentrantReadWriteLock lock = new ReentrantReadWriteLock() ReadLock r = lock.readLock(); WriteLock w = lock.writeLock();
两者都有lock,unlock方法。写写,写读互斥;读读不互斥。可以实现并发读的高效线程安全代码
4.容器类
这里就讨论比较常用的两个:
BlockingQueue
ConcurrentHashMap
BlockingQueue
阻塞队列。该类是java.util.concurrent包下的重要类,通过对Queue的学习可以得知,这个queue是单向队列,可以在队列头添加元素和在队尾删除或取出元素。类似于一个管 道,特别适用于先进先出策略的一些应用场景。普通的queue接口主要实现有PriorityQueue(优先队列),有兴趣可以研究
BlockingQueue在队列的基础上添加了多线程协作的功能:

除了传统的queue功能(表格左边的两列)之外,还提供了阻塞接口put和take,带超时功能的阻塞接口offer和poll。put会在队列满的时候阻塞,直到有空间时被唤醒;take在队 列空的时候阻塞,直到有东西拿的时候才被唤醒。用于生产者-消费者模型尤其好用,堪称神器。
常见的阻塞队列有:
ArrayListBlockingQueue
LinkedListBlockingQueue
DelayQueue
SynchronousQueue
ConcurrentHashMap
高效的线程安全哈希map。请对比hashTable , concurrentHashMap, HashMap
5.管理类
管理类的概念比较泛,用于管理线程,本身不是多线程的,但提供了一些机制来利用上述的工具做一些封装。
了解到的值得一提的管理类:ThreadPoolExecutor和 JMX框架下的系统级管理类 ThreadMXBean
ThreadPoolExecutor
如果不了解这个类,应该了解前面提到的ExecutorService,开一个自己的线程池非常方便:
ExecutorService e = Executors.newCachedThreadPool(); ExecutorService e = Executors.newSingleThreadExecutor(); ExecutorService e = Executors.newFixedThreadPool(3); // 第一种是可变大小线程池,按照任务数来分配线程, // 第二种是单线程池,相当于FixedThreadPool(1) // 第三种是固定大小线程池。 // 然后运行 e.execute(new MyRunnableImpl());
该类内部是通过ThreadPoolExecutor实现的,掌握该类有助于理解线程池的管理,本质上,他们都是ThreadPoolExecutor类的各种实现版本。请参见javadoc:

翻译一下:
corePoolSize:池内线程初始值与最小值,就算是空闲状态,也会保持该数量线程。
maximumPoolSize:线程最大值,线程的增长始终不会超过该值。
keepAliveTime:当池内线程数高于corePoolSize时,经过多少时间多余的空闲线程才会被回收。回收前处于wait状态
unit:
时间单位,可以使用TimeUnit的实例,如TimeUnit.MILLISECONDS
workQueue:待入任务(Runnable)的等待场所,该参数主要影响调度策略,如公平与否,是否产生饿死(starving)
threadFactory:线程工厂类,有默认实现,如果有自定义的需要则需要自己实现ThreadFactory接口并作为参数传入。
文/知米丶无忌(简书作者)
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









