









 本文介绍了Hadoop-2.4.1中YARN的ResourceManager实现高可用性的方法,通过Active/Standby架构,利用ZooKeeper进行故障转移。在启用HA模式下,ResourceManager支持手动或自动故障转移,确保系统的稳定性。配置包括在yarn-site.xml中设置多个RMs,并可以选择使用FileSystemRMStateStore或ZKRMStateStore作为状态存储。同时,提供了CLI工具进行RM状态查看和故障转移操作。
本文介绍了Hadoop-2.4.1中YARN的ResourceManager实现高可用性的方法,通过Active/Standby架构,利用ZooKeeper进行故障转移。在启用HA模式下,ResourceManager支持手动或自动故障转移,确保系统的稳定性。配置包括在yarn-site.xml中设置多个RMs,并可以选择使用FileSystemRMStateStore或ZKRMStateStore作为状态存储。同时,提供了CLI工具进行RM状态查看和故障转移操作。
在Hadoop-2.4之前,Yarn中的ResourceManager也是单点故障中的,就像Hadoop-1.x中的NameNode,由于Hadoop-2.X已经支持NameNode的HA(高可用性),那么自然也要在hadoop的某个版本中实现ResourceManager的HA,否则又会招致一些事后诸葛亮的诟病。本文将介绍RM的高可用性,并详细学习如何配置和使用该特性。就像NameNode的HA一样,ResourceManager的HA也是通过冗余的Active/Standby ResourceManagers消除单点故障所存在的问题。
RM的HA架构如下(引自官方图片),该图所展示的架构与NameNode有很多相似之处,比如支持自动或手动的故障转移,使用ZooKeeper保存Active RM的状态等。
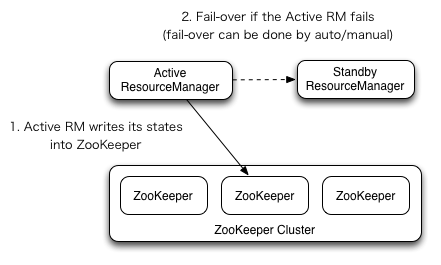
ResourceManager的HA是通过Active/Standby架构实现的,在任何时间点只有一个RM处于active状态,而剩余的RM(一个或多个)则处于standby状态,时刻准备着接管active的工作。可以通过在CLI输入命令或者在自动故障转移启动的前提下通过集成的故障转移控制器实现standby到active的转换,也就是手动故障转移和自动故障转移。
在没启用自动故障转移的情况下,管理员必须手动地将处于

 订阅专栏 解锁全文
订阅专栏 解锁全文


















 5937
5937

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











