









从简单到高级的说起.
1.BF算法
就是我们普通回溯的匹配法

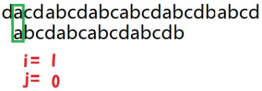







文本串 和 模式串 都从头开始匹配.
匹配成功, j+1; i+1;
匹配失败时,模式串 j=0, 文本串i=i-j+1;
时间复杂度:O(文本串长度 × 模式串长度)
int Match(char* s, char* p)
{
int sLen = strlen(s);
int pLen = strlen(p);
int i = 0;
int j = 0;
while (i < sLen && j < pLen)
{
if (s[i] == p[j]) //匹配成功
{
i++;
j++;
}
else //匹配失败
{
i = i - j + 1;
j = 0;
}
}
//匹配成功,返回模式串p在文本串s中的位置,否则返回-1
if (j == pLen)
return i - j;
else
return -1;
}
2.strstr() 函数
搜索一个字符串在另一个字符串中的第一次出现。找到所搜索的字符串,则该函数返回第一次匹配的字符串的地址;如果未找到所搜索的字符串,则返回NULL。
嘛,直接就拿来用了,总比上面自己写的好.
3.KPM算法
这个听说不好理解,我也懒得说明是什么.网上的文章各显神通.
简言之,就是一种改进的匹配法.他的速度其实也并不比strstr( )快多少.
主要通过求 模式串 的 next [ ]数组
每次匹配失败,就直接 j = next[ j ] 这样跳过去几个.
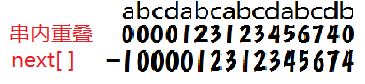
串内重叠就是跟自己的首字母开始比较,看看连着几个相匹配的.
next[ ]其实就是串内重叠向右移一位,首位初始化为-1.
当匹配成功时,i++;j++;
当匹配失败时:
①如果next[ j ] = -1 时, i++;j++;
②其他情况就是 j = next[ j ]; i保持不变

匹配失败,j= -1; 循环第二次时发现j= -1 ,所以j++,i++ ;
变成了 i=1; j =0;
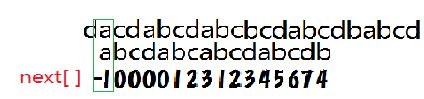
匹配成功! i++;j++;
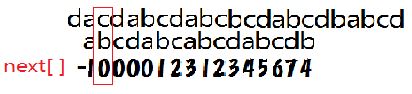
匹配失败,j= next[ j ]=0;

.......

j=next [ j ] =3;
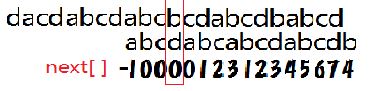
从3开始在匹配
可见KMP算法厉害在会自动跳过前面已经匹配过的字符.
KMP的移动过程代码:
void gooded(char *Mstr)
{
int Mlen=strlen(Mstr);
int ed[20];
ed[0]=0;
for(int i=1;i<Mlen;i++)
{
int k=ed[i-1];
while(Mstr[k] != Mstr[i] && k!=0) //这句用来看模式串是否有子重叠
k=ed[k-1];
if(Mstr[k] == Mstr[i])
ed[i]=k+1;
else ed[i]=0;
}
for(int j=0;j<Mlen;j++)
printf("%4d",ed[j]);
}求next [ ]:
void Getnextval(char * string ,int next [ ] )
{
int j = -1, i = 0;
next[0] = -1;
int len=strlen(string)
while(i < len)
{
if(j == -1 || string[i] == string[j])
{
i++;
j++;
if( string[i]!=string[j] ) next[i] = j;
else next[i]=next[j];
}
else
{
j = next[j];
}
}
}
int KmpSearch(char* s, char* p, int next[ ])
{
int i = 0;
int j = 0;
int sLen = strlen(s);
int pLen = strlen(p);
while (i < sLen && j < pLen)
{
if (j == -1 || s[i] == p[j])
{
i++;
j++;
}
else
{
j = next[j];
}
}
if (j == pLen)
return i - j;
else
return -1;
}
4.BM算法.
以下为引用举例,实在懒得自己画了..
从模式串的尾部开始匹配,且拥有在最坏情况下O(N)的时间复杂度。在实践中,比KMP算法的实际效能高
首先,"文本串"与"模式串"头部对齐,从尾部开始比较。"S"与"E"不匹配。这时,"S"就被称为"坏字符"(bad character),即不匹配的字符,它对应着模式串的第6位。且"S"不包含在模式串"EXAMPLE"之中(相当于最右出现位置是-1),这意味着可以把模式串后移6-(-1)=7位,从而直接移到"S"的后一位。

2. 依然从尾部开始比较,发现"P"与"E"不匹配,所以"P"是"坏字符"。但是,"P"包含在模式串"EXAMPLE"之中。因为“P”这个“坏字符”对应着模式串的第6位(从0开始编号),且在模式串中的最右出现位置为4,所以,将模式串后移6-4=2位,两个"P"对齐。

3 . 依次比较,得到 “MPLE”匹配,称为"好后缀"(good suffix),即所有尾部匹配的字符串。注意,"MPLE"、"PLE"、"LE"、"E"都是好后缀。
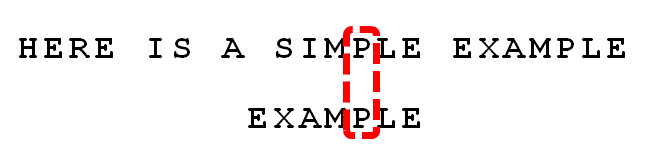
4 . 发现“I”与“A”不匹配:“I”是坏字符。如果是根据坏字符规则,此时模式串应该后移2-(-1)=3位。问题是,有没有更优的移法?

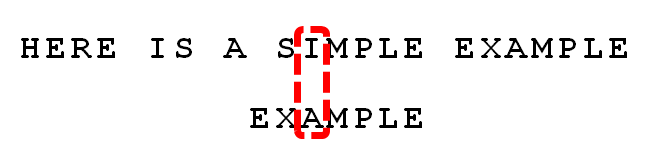
5 . 更优的移法是利用好后缀规则:当字符失配时,后移位数 = 好后缀在模式串中的位置 - 好后缀在模式串中上一次出现的位置,且如果好后缀在模式串中没有再次出现,则为-1。
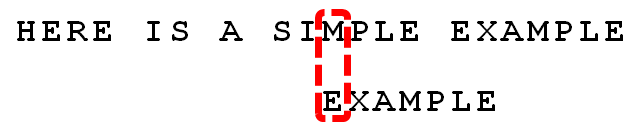
所有的“好后缀”(MPLE、PLE、LE、E)之中,只有“E”在“EXAMPLE”的头部出现,所以后移6-0=6位。
可以看出,“坏字符规则”只能移3位,“好后缀规则”可以移6位。每次后移这两个规则之中的较大值。这两个规则的移动位数,只与模式串有关,与原文本串无关。
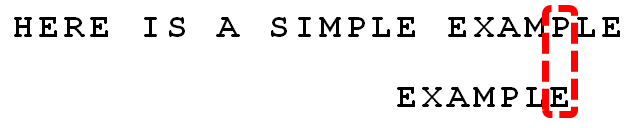
6. 继续从尾部开始比较,“P”与“E”不匹配,因此“P”是“坏字符”,根据“坏字符规则”,后移 6 - 4 = 2位。因为是最后一位就失配,尚未获得好后缀。
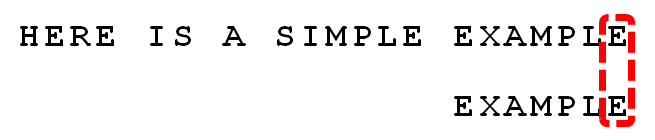
总结以上两个特点, 坏字符 和 好后缀
结尾匹配成功时,列入"好后缀"的集合,直到整个模式串匹配完.当这个"好后续"貌似可以跟KMP的next一起看
匹配失败时,:
①先向左找找有没有出现好后续,有的话返回找到所在位 - 上一次的后续位,右移动.没有后续则②方法
②与当前在文本串中匹配的对象成为"坏字符",在模式串中从当前位置开始向头开始查找与该坏字符相同的,
找不到返回-1.找到返回向右走了多少个字符.通过这个数字可以使得坏字符在文本串和模式串都对齐.如上图
求好后续的序列:
void gooded(char *Mstr,int ed[])
{
int Mlen=strlen(Mstr);
int i=Mlen-1;
int j=i-1;
for(;i>0;i--)
{
while(Mstr[j] != Mstr[i] && j>=0)j--;
if(j<0)return ;
else
{
if(ed[i-1]!=i-j)
{
int k=1;
while(Mstr[i+k] == Mstr[j+k] && (i+k)<Mlen) k++;
if(i+k != Mlen) return;
}
ed[i]=i-j;
}
}
}BM算法
int BM(char *Tstr,char *Mstr,int ed[ ])
{
int Mlen=strlen(Mstr);
int Tlen=strlen(Tstr);
int i=Mlen-1;
int j=0;
while(j<Tlen)
{
while(Mstr[i] == Tstr[j+i] && i>=0) i--; //从尾开始匹配
if(i<0) return j;
else
{
for(int k=1;i+k<Mlen;k++) //好后缀匹配
if(ed[i+k] != 0)
{ i=Mlen-1;
j+=ed[i+k];
continue;
}
char c=Tstr[j+i];
for(int bc=1;bc<=i;bc++) //坏字符匹配
{
if(Mstr[i-bc] ==Tstr[j+i])
{
j+=bc;
continue;
}
}
if(bc>i) j+=Mlen;
}
}
return -1;
}
5.sunday算法
这个算法比岛风还快
在匹配过程中,模式串并不被要求一定要按从左向右进行比较还是从右向左进行比较,它在发现不匹配时,算法能跳过尽可能多的字符以进行下一步的匹配,从而提高了匹配效率。
1. 刚开始时,把模式串与文本串左边对齐:
substring searching algorithm
search
^
2. 结果发现在第2个字符处发现不匹配,不匹配时关注文本串中参加匹配的最末位字符的下一位字符,即标粗的字符 i,因为模式串search中并不存在i,所以模式串直接跳过一大片,向右移动位数 = 匹配串长度 + 1 = 6 + 1 = 7,从 i 之后的那个字符(即字符n)开始下一步的匹配,如下图:
substring searching algorithm
search
^
3. 结果第一个字符就不匹配,再看文本串中参加匹配的最末位字符的下一位字符,是'r',它出现在模式串中的倒数第3位,于是把模式串向右移动3位(r 到模式串末尾的距离 + 1 = 2 + 1 =3),使两个'r'对齐,如下:
substring searching algorithm
search
^
4. 匹配成功。
回顾整个过程,我们只移动了两次模式串就找到了匹配位置,缘于Sunday算法每一步的移动量都比较大,效率很高。完
这也是引用例子,自己懒得画
总结,从哪里开始找都可以
匹配成功时,匹配下一个字符
匹配失败时,马上跳到模式串后一个字符,找找模式串里面有没有.没有则直接跳到后面,有则对齐.看看其他是否相等.
int sunday(char *Tstr,char *Mstr)
{
int Tlen=strlen(Tstr);
int Mlen=strlen(Mstr);
int i=0;
int j=0;
while(i<Tlen && j <Mlen)
{
if(Mstr[j]==Tstr[i])
{
i++;
j++;
}
else
{
i+= (Mlen-j) ;
char sign=Tstr[i];
int k=Mlen-1;
while(Mstr[k] != sign && k>=0) k--;
if( k < -1 )
{
j=0;
i++;
}else
{
j=0;
i-=k;
}
}
}
if( j == Mlen ) return i-j;
else return -1;
}















 2903
2903

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









